目录
1. 过拟合与欠拟合
1.1 Preliminary concept
1.2 过拟合 over-fitting
1.3 欠拟合 under-fitting
1.4 案例解析:黑天鹅
1. 过拟合与欠拟合
1.1 Preliminary concept
误差
- 经验误差:模型对训练集数据的误差。
- 泛化误差:模型对测试集数据的误差。
模型泛化能力
模型对训练集以外的预测能力称为模型的泛化能力,追求这种泛化能力是机器学习的目标。
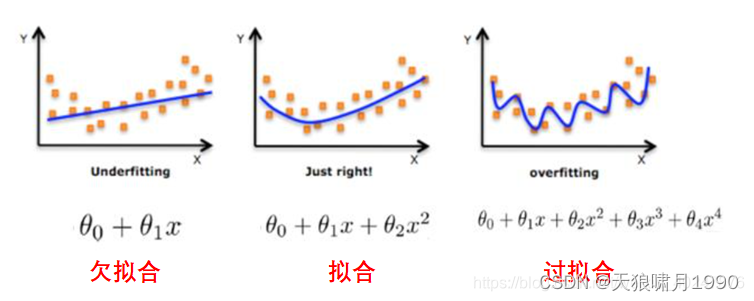
1.2 过拟合 over-fitting
过拟合over-fitting: 是指模型在训练数据上表现非常好,但在测试数据或实际表现中表现较差。
原因:过拟合通常(对,就是还有少数情况是数据不足~学错了)在模型过于复杂、学习的太多了-》将个体特征/局部特征作为整体特征的情况下出现。此时模型学习能力太强,以致于将训练集单个样本自身的特点都能捕捉到,并将其认为是“一般规律”,同样这种情况也会导致模型泛化能力下降。
- 模型复杂度高(使用了过多的参数)
- 训练数据不足,导致模型学到数据中的噪声noise。
- 训练数据中的局部特征对模型产生了过大影响。
图像:过拟合表现为输出结果的高方差。
解决方法:增加training dataset;简化模型。
- 增加数据:获取更多的训练数据,有助于模型学习到更一般化的模式。
- 正则化:通过L1或L2正则化减少模型复杂度。
- 简化模型:减少模型的参数或使用更简单的模型。
- 比如2021 LoRA,通过限制LLM模型复杂度,防止过拟合 -》提高model范化性能。
- 交叉验证:使用交叉验证方法选择最合适的模型超参数。
- early stop:在training过程中监控验证集误差,当误差开始增加时停止!
1.3 欠拟合 under-fitting
欠拟合under-fitting: 是指模型在训练集和测试集上都表现不佳。
原因:欠拟合通常因为模型过于简单、学习能力太弱!-》无法捕捉到数据的复杂性 此时由于模型学习能力不足,无法学习到数据集中的“一般规律”,因而导致模型泛化能力弱。
- 模型复杂度太低 ~学不进去
- 特征不充分或特征选择不当。
- 训练时间不足,模型未能充分学习。
图像:欠拟合主要表现为输出结果的高偏差。
解决方法: 复杂化模型,增强学习能力
- 增加模型复杂度:使用更复杂的模型(如增加神经网络层数或节点数)。
- 特征工程:生成更多有用的特征或使用特征选择技术选择更重要的特征。
- 增加训练时间:延长训练时间,使模型有足够的时间学习数据模式。
- 调整超参数:优化模型的超参数设置,使其更好地拟合数据。
1.4 案例解析:黑天鹅
案例1: 现在有一组天鹅的特征数据,然后对模型进行训练。模型通过学习后得知:有翅膀、嘴巴长的就是天鹅。然后,该模型对新数据进行预测。
结果:该模型将所有符合这两个特征的动物都预测为天鹅,比如鹦鹉、山鸡等,这就导致了误差的产生。
=》这就是过拟合情况,没学到。模型学习到的天鹅特征太少了,导致区分标准过于粗糙,从而导致模型不能准确地识别出天鹅。
案例2: 有了案例1的经验之后,我们又增加了一些用于训练的特征,然后对模型进行训练。模型这次学到的内容是:有翅膀、嘴巴长、脖子形状像2的就是天鹅。然后,该模型对新数据进行预测。
结果:当该模型再遇到鹦鹉、山鸡等会被案例1误判的动物时,案例2模型能正确区分它们。
=》这就是拟合状态。模型正确的学习到了足够的天鹅特征。
案例3: 这时模型学嗨了,不肯停止,一直持续学习,学到了很多内容:有翅膀、嘴巴长、脖子形状像2、白色等特征的就是天鹅。然后,该模型再对新数据进行预测。
结果:这时飞过来的黑天鹅被误判为不是天鹅,因为黑色从来没有出现过,这使得模型把颜色这种局部特征过度学习成了全局特征,从而产生了识别误差。
=》这就是过拟合,过犹不及,学多了。 模型学到的特征太过于依赖或太符合训练数据了。
参考:
https://www.cnblogs.com/taoziTTW/p/15213790.html
机器学习之欠拟合、过拟合详解(附实例和对应解决办法)_过拟合 demo-CSDN博客