大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
视觉转换器(ViT)架构已经广受欢迎,并广泛用于计算机视觉应用。然而,随着 ViT 模型规模的扩大,可训练参数直线上升,从而影响了部署和性能。因此如何进行有效的优化成为热点领域,各种的研究方向层出不穷。下图左一为基本的ViT块,左二到左五代表着紧凑架构优化法、剪枝优化法、知识蒸馏法和量化优化法。橙色虚线的部分代表每个领域重点优化的组件。

本文先来看看Compact Architecture的优化方向。Compact Architecture是指设计轻量级、高效或者紧凑的模型,同时需要在下游任务中保持高性能。它包含各种策略和方法,可在不影响性能的情况下减小模型大小、计算复杂性和内存占用。这种方法的研究集中在2021年-2022年,紧凑架构对于算力不那么充裕的终端的确是一个很好的改进。这个领域一般涉及到如下几种优化方法,要么创新整体架构,要么优化整体架构,要么进行架构搜索,要么优化注意力机制。

架构优化

2020年Reformer引入了两种技术提高Transformer的效率。利用局部敏感哈希的替换点积注意力,将其复杂度从 O(L) 更改为 O(L log L),其中 L 是序列的长度。其次使用可逆残差层而不是标准残差,允许在训练过程中只存储一次激活,而不是 N 次。
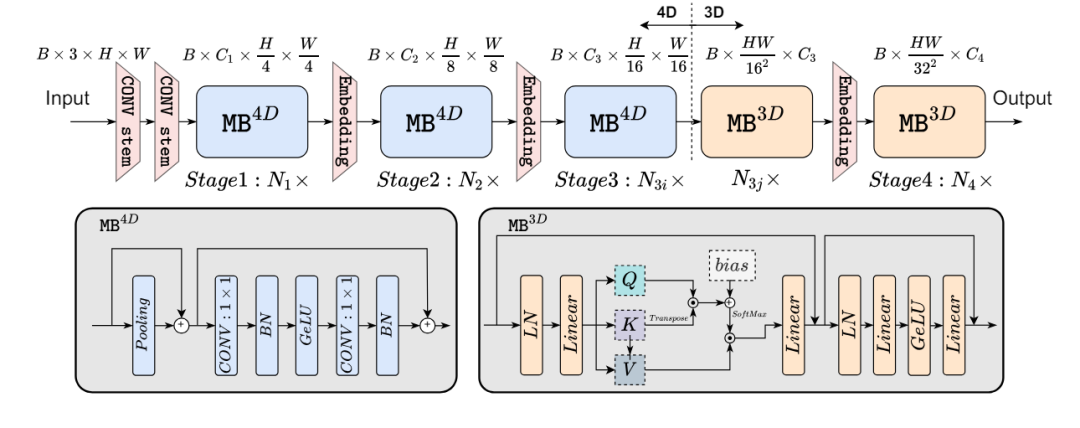
2022年EfficientFormer分析了基于ViT的模型架构和算子,没有集成MobileNet结构,是一个完全基于Transformer的模型。这个架构定义了两种元块(MetaBlock),MB4D是基于CNN,而MB3D是传统的ViT块。
它一共有4个阶段,并且在最后两个阶段仅启用MB3D。可以这么理解,一开始先用CNN,到了最后才是使用注意力。因为一方面由于MHSA的计算相对于Token长度呈二次增长,因此在早期阶段集成它会大大增加计算成本。另一方面网络的早期阶段利用CNN捕获了低级特征,而后期阶段则学习长期的依赖关系。
它其实还构建了一个超网,采用搜索算法包括找到最优的超参数Cj(每个阶段的宽度)、Nj(每个阶段的块数,即深度)和最后N个要应用MB3D的块。实验结果证明还是挺不错的,而且在iphone12运行记过还是低延时。
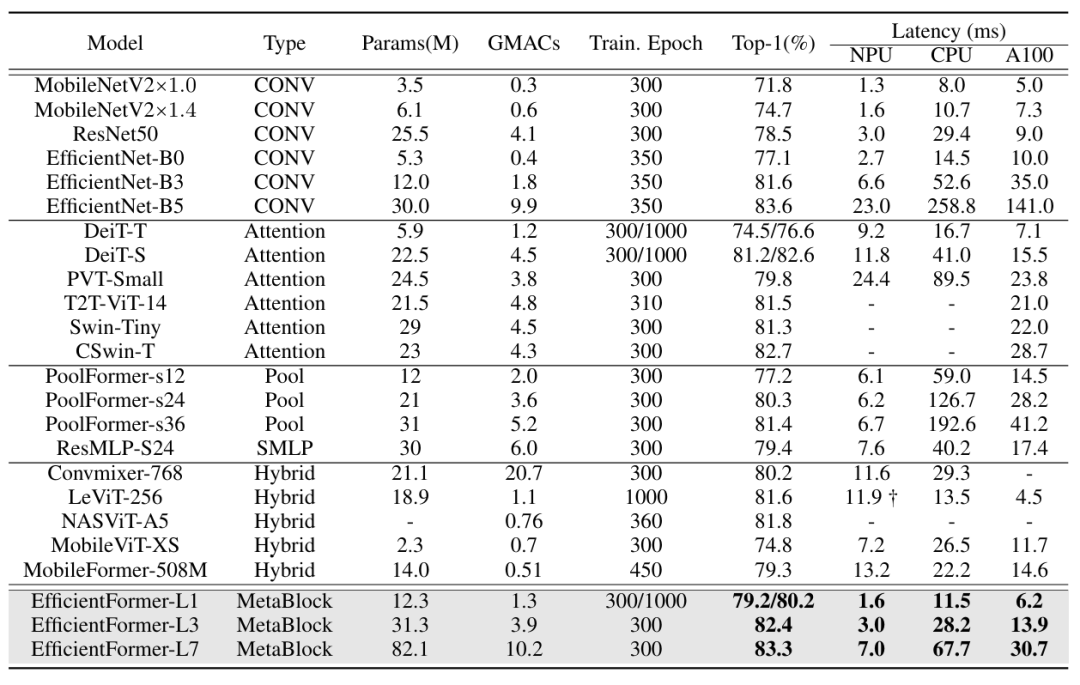
“小编任务这个表格可以琢磨一下,其中第二行的Type和第三行的参数规模!”
之后半年的EfficientFormerV2提出了一种低延迟、高参数效率的超网。
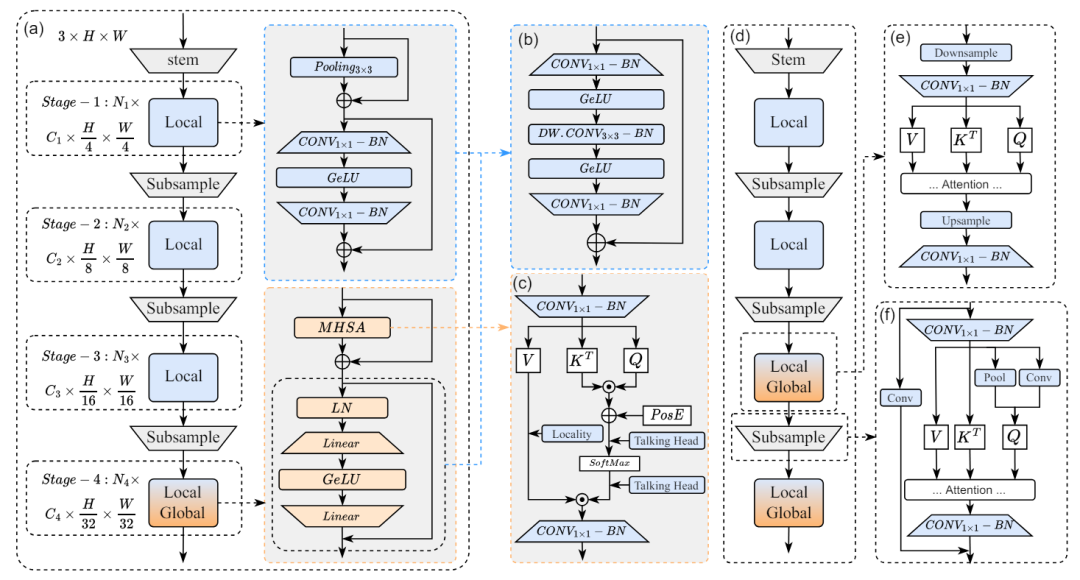
(a)为原来EfficientFormer1.0的模型,在2.0的版本中奖FFN(b)在所有的块中进行统一,同时将注意力机制块进行调整(c)。在高分辨率的场景利用下采样和上采样(插值)的办法,将整体延迟从3.5ms压缩到1.5ms,而没有任何性能的损失。
EfficientFormer2.0提出了一种新的超网络设计方法,该方法在维护较高的准确性的同时,可以在移动设备上运行。同时它提出了一种细粒度的联合搜索策略,该策略可以同时优化延迟和参数数量,从而找到高效的架构。
最后EfficientFormer2.0在ImageNet-1K 数据集上的准确性比MobileNetV2和MobileNetV2×1.4高出约 4%,同时具有相似的延迟和参数。
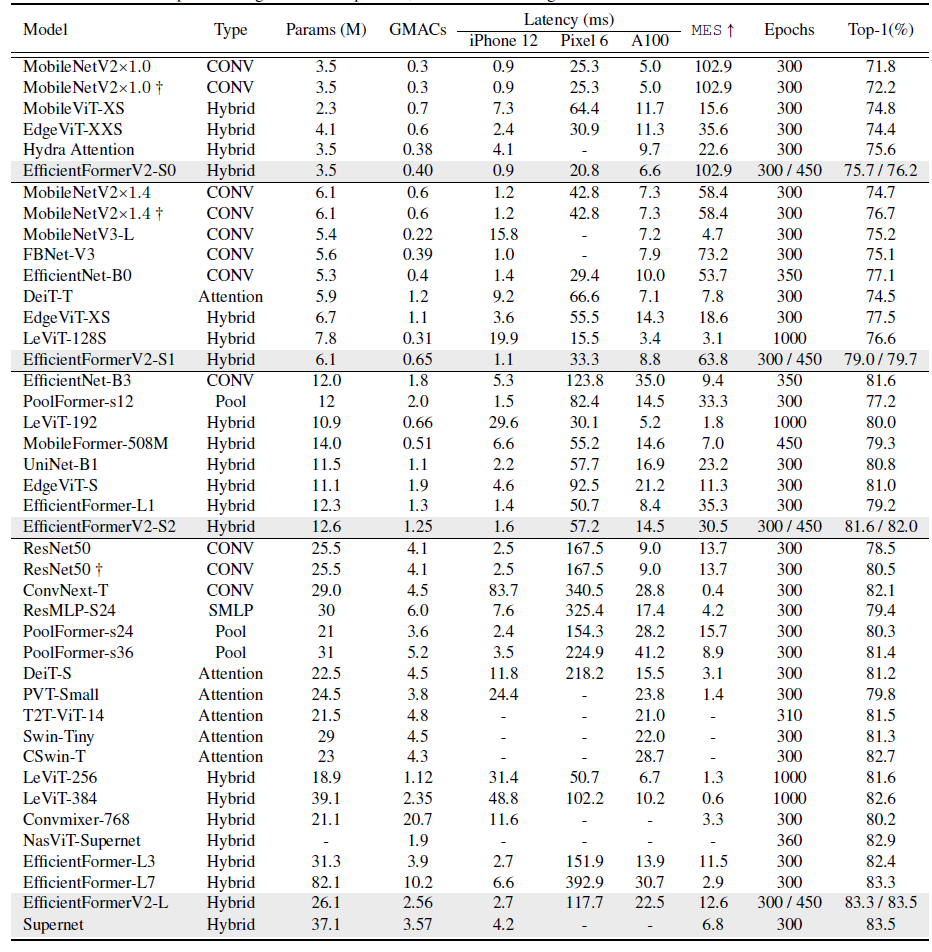
<Transformer居然还能比MobileNet快!,请细品下图>

架构搜索优化
架构搜索一般会采用特定的搜索算法来找寻最优的网络参数,进而构建超网框架。比如2022年的Vision Transformer Slimming来探索和发现针对特定任务或某些约束下量身定制的紧凑架构。
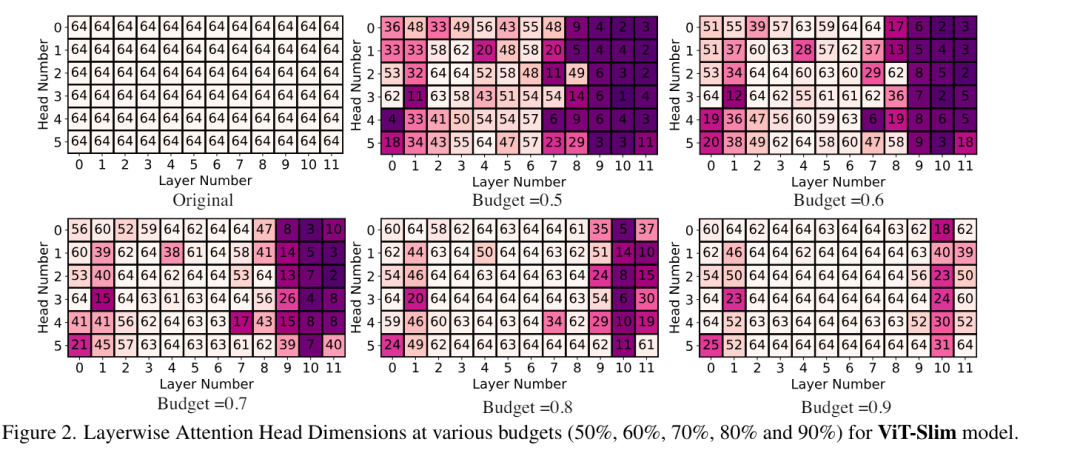
随着budget的收缩,每层头数目不断地被优化降低。下图为它和其他几种瘦身算法的对比。DeiT-S 上,ViT-Slim的搜索过程只需要约43个 GPU 小时,并且搜索的结构灵活,不同模块的维度多样。根据运行设备的accuracy-FLOPs权衡的要求采用预算阈值,并执行重新训练过程以获得最终模型。大量实验表明,ViT-Slim可以在各种视觉转换器上压缩高达 40% 的参数和 40% 的 FLOP,同时在 ImageNet 上将准确度提高约 0.6%。

早在2021年的Autoformer利用weight Entanglement训练超网,然后在预设置好的搜索空间进行采样到子网,紧接着更新子网的参数,冻结其余参数不使其更新,最终通过进化算法得到参数量最小且精度最高模型。

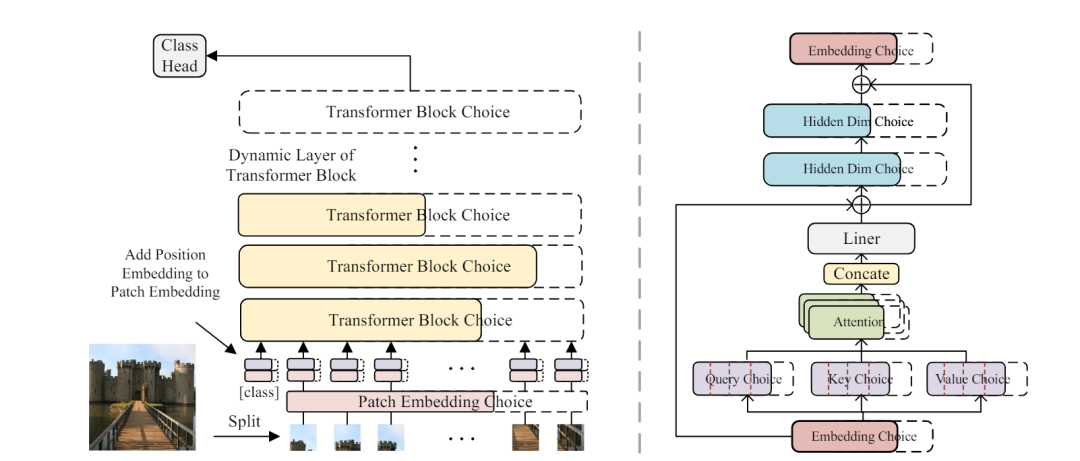
下图为AutoFormer 超网络的整体架构。请注意每个层和深度中的Transformer块都是动态的。实线部分表示它们是被选择的,而虚线部分则不是。下图右为AutoFormer中详细的Transformer块。在层中搜索最佳嵌入维度、头数、MLP比率、Q-K-V维度的最佳块。
不同子网的梯度在ViT中与超网的梯度冲突比CNN更严重,这导致训练过早饱和,收敛性较差。为了缓解这个问题,2022年的NASViT提出了一系列技术,包括梯度投影算法、可切换层缩放设计以及简化的数据增强和正则化训练配方。所提出的技术显著改善了所有子网的收敛性和性能。

上图为NASViT的整体架构,下图为NASViT的搜索空间。

另外NASViT的注意力机制块如下:

此外,还有TF-TAS研究了免训练架构搜索方法。UniNet引入了上下文感知下采样模块,改善了Transformer和MLP的适配能力。

注意力机制优化
这个领域的优化专注于通过引入自适应注意力、学习稀疏注意力模式和动态调整注意力机制来降低计算复杂性。Fayyaz等通过对重要标记进行评分和自适应采样来实现自适应注意力。PatchMerger提取区域Token之间的全局信息,并通过自注意力与区域Token之间的信息交换局部自注意力。

如上图所示DynamicViT提出的预测模块(中间部分)插入到Transformer 块之间,以根据前一层产生的特征选择性地修剪掉信息量较少的Token。

上图通过可视化展示了修剪过程,从直观上还是比较好理解。通过这样的算法,后续层中处理的Token会大幅减少。
此外还有一种高效的视觉Transformer骨干网络SepViT,它借鉴深度可分离卷积的思想,通过深度可分离自我注意力实现局部-全局信息交互。
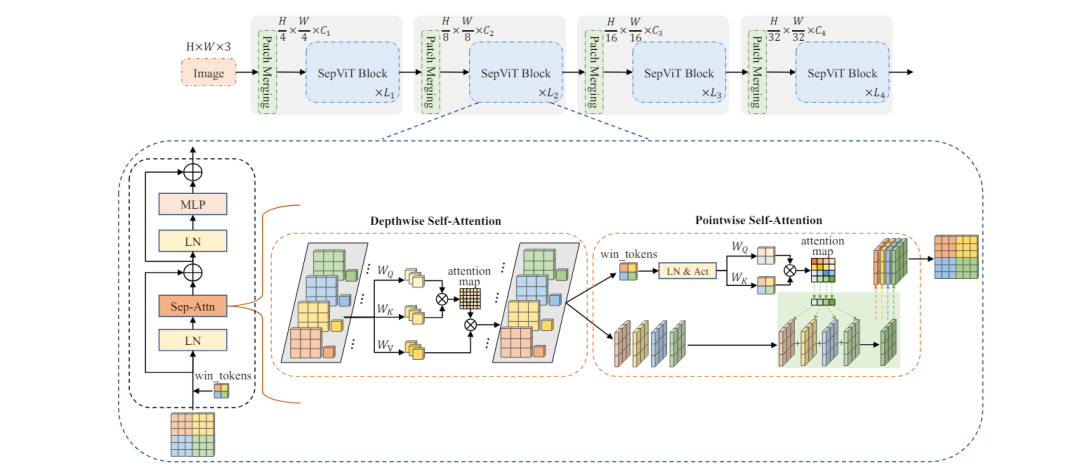
SepViT利用窗口令牌嵌入和分组自注意力,以较低的计算成本实现窗口间的注意力关系,提升远程视觉交互。实验表明,SepViT在性能与延迟之间实现了出色的权衡,相较于同类模型,在ImageNet分类上提升了精度并降低了延迟,同时在语义分割、目标检测和实例分割等任务中也表现优异。