C++面试常青客:LRUCache最近最少使用算法
文章目录
- C++面试常青客:LRUCache最近最少使用算法
- 1.背景🏆
- 2.原理🚀
- 2.1基本原理
- 2.2核心特性
- 3.结构
- 3.1为什么需要 `list<pair<int,int>>`(双向链表)?
- 3.2 为什么需要 `unordered_map`(哈希表)?
- 3.3 二者如何协作?
- 3.4 其他替代方案的缺陷
- 4.代码实现
- 4.1 Get(int key)
- 4.2 Put(int key,int value)
- 5.总结
1.背景🏆
首先咱们的LRUCache的意思是最近最少使用缓存,是一种常见的缓存淘汰机制,常见用于在有限的缓存空间中管理数据🤓✌️。
在近几年的开发岗面试中出现的频率可谓是越来越高了,现在一些面试官动不动就会问:
“你听说过LRUCache没有?”“如果听说过你能给我介绍一下它是什么以及原理吗?”“那最后你能给我简单实现一下吗?”
甚至于在我前好几年寻找工作的旅程中LRUCache被问到的频率也是超过了三次及以上,最近无论是一些学长还是学弟也经常跟我反映,说怎么动不动就问这玩意…
站在面试者的视角我寻思之所以出现频率这么高,原因可能有以下:
1.LRUCache算法属性是拉满,可以直接检测到面试者算法能力。
2.能够在极其有限的时间内考验代码手撕能力以及逻辑思维能力。
3.覆盖高级容器用法综合,例如:unordered_map、pair<int, int>>::iterator等等
4.实际工作中类似“最近最少”应用场景确实很多。
那既然是这种现状,我们就来看一下怎么通过一种最简洁的方式把LRUCache拿下!无论是询问原理还是手撕我们都胸有成竹!
2.原理🚀
2.1基本原理
首先应该先理解我们LRUCache的原理,就LRU应该呈现什么样的一种状态:
1.LRUCache里面应该存放的是键值对pair:
因为我要获取到键对应的值,这个很好理解
2.LRUCache是最近最少使用原则:
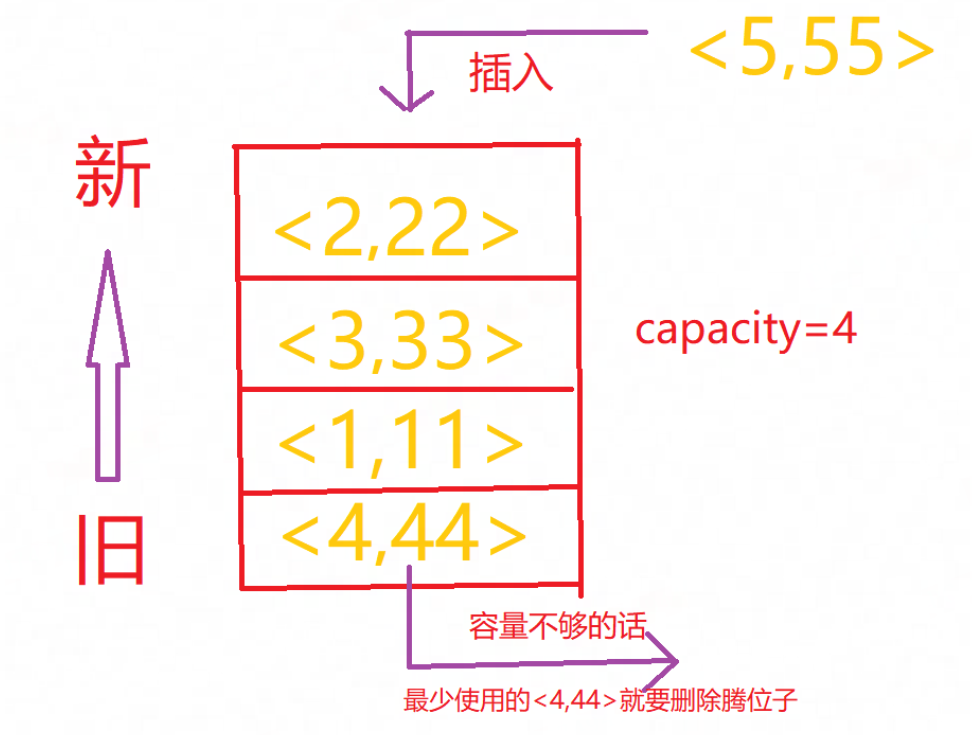
比如按照从新到旧的插入顺序我LRU有:
<2,22><3,33><1,11><4,44>
这个时候我一旦访问了1的值11,那我们的相对位置就应该更新成:
<1,11><2,22><3,33><4,44>
因为<1,11>这个位置使用了所以要更新到最新位置去,很好理解。
3.LRUCache应该有容量,且超过容量后会删除最少使用的:
比如我容量就为4,按照上述最初例子如果再加一个<5,55>之后容量不够的话就要删除最少使用的<4,44>,然后把最新的<5,55>放到最前面后会变成:
<5,55><2,22><3,33><1,11>
为了大家更好的了解过程,我有丑图一张供大家欣赏🤣✌️:
2.2核心特性
知道我们LRU长什么样子了,现在来看看一些核心的东西,也就是关键是什么:
固定容量:创建时指定最大容量
快速访问:通常使用哈希表实现 O(1) 的查找
顺序维护:使用双向链表维护访问顺序
自动淘汰:当容量满时自动移除最久未使用的项
并且LRUCache的优势就是我们的时间复杂度了,基本增删查的复杂度都很低:
插入操作:O(1)
查找操作:O(1)
删除操作:O(1)
好,那在介绍完原理之后我们就知道它基本是什么了,这个时候我们来看看怎么具体实现。
3.结构
首先世面上有很多种实现LRU的方式,那我这里选择一种比较简单也是比较经典的一种实现结构:
首先我们只需要提供两个接口就好:
关键操作:
get(key):获取键对应的值,并将该键标记为最近使用
put(key, value):插入或更新值,如果超出容量则移除最久未使用的项
这个大家应该都好理解
那在底层我们选择两种数据结构的结合来构成LRUCache:
哈希表:提供快速的键值查找
双向链表:维护键的访问顺序
也就是:
list<pair<int, int>>:双向链表,存储键值对,维护访问顺序
unordered_map<int, list<pair<int, int>>::iterator>:哈希表,快速定位链表中的节点
🤔✌️这时候就有同学要问为什么要使用俩看起来很复杂的数据结构?
首先,我们要存键值对肯定需要一个容器对吧,那我选用list没毛病吧?😎
其次,我要知道访问位置的话,肯定需要迭代器对吧?那我用list<pair<int, int>>::iterator没毛病吧?😎
最后,我要动态频繁拿到这个迭代器的位置,那我使用O(1)复杂度的哈希表没毛病吧?😎
以上就简单论证了这俩配套使用的必要性,那为了更具说服力我将详细论证结构必要性:
3.1为什么需要 list<pair<int,int>>(双向链表)?
维护访问顺序
-
LRU 的核心是 “最近最少使用”,需要严格维护元素的访问顺序
-
双向链表能高效地在 O(1) 时间 完成以下操作:
-
插入新节点到头部(
push_front) -
移动某个节点到头部(先
erase再push_front) -
删除尾部节点(
pop_back)
-
为什么不用 vector 或 deque?
-
vector:中间插入/删除是 O(n),无法高效移动节点 -
deque:虽然头尾操作是 O(1),但中间删除是 O(n),且迭代器易失效 -
双向链表 的节点插入/删除 不会影响其他节点的迭代器,安全性更高
3.2 为什么需要 unordered_map(哈希表)?
实现 O(1) 快速查找
-
单纯用链表查找需要 O(n) 时间遍历,无法满足高效缓存的需求
-
哈希表通过
key直接映射到链表节点的 迭代器,实现 O(1) 访问
为什么不用其他数据结构?
-
map(红黑树):查找是 O(log n),比哈希表慢 -
单纯用哈希表:无法维护 LRU 的访问顺序
3.3 二者如何协作?
操作流程
-
get(key):-
通过
_hashmap在 O(1) 时间找到链表节点 -
将该节点移动到链表头部(表示最近使用)
-
-
put(key, value):-
如果
key已存在,更新值并移动节点到头部 -
如果
key不存在:-
插入新节点到链表头部
-
在
_hashmap中记录key对应的迭代器 -
如果容量超限,删除链表尾部节点,并清除
_hashmap中的对应项
-
-
为什么必须用迭代器?
-
哈希表存储的是 链表节点的迭代器,而非值本身:
-
直接通过迭代器修改链表节点(如移动位置或更新值)
-
如果哈希表存储值,则无法定位链表节点,无法维护顺序
-
3.4 其他替代方案的缺陷
方案1:仅用 unordered_map
- 无法维护访问顺序,不知道哪个键是"最近最少使用"的
方案2:仅用 list
- 查找需要 O(n) 遍历,无法满足缓存的高效需求
方案3:vector + unordered_map
vector中间删除效率低,移动元素成本高
方案4:deque + unordered_map
deque的迭代器在插入/删除时可能失效,导致哈希表中的迭代器失效
4.代码实现
那接下来 我将使用C++详细实现一下具体的代码(代码经过本人测试,真实有效😊):
首先我们要实现的类结构应该是:
class LRUCache
{
public:LRUCache(int capacity):_capacity(capacity){}int Get(int key){}void Put(int key, int value){}private:list<pair<int, int>> _list;unordered_map<int, list<pair<int, int>>::iterator> _hashmap;size_t _capacity;};
好,那有了基层结构之后我们来看看这主要的两个函数怎么实现:
4.1 Get(int key)
这个函数的逻辑很简单,获取对应键的值key,并且更新为最近访问(拿到最前面去):
代码逻辑如下:
-
查找键:通过
_hashmap查找键是否存在(O(1) 时间) -
命中缓存:
-
通过迭代器
it获取链表中的节点 -
使用
splice将该节点移动到链表头部(表示最近使用) -
返回对应的值
-
-
未命中缓存:返回
-1关键点:
-
splice操作是 O(1) 时间,直接修改链表指针,无需拷贝数据 -
移动节点到头部是为了维护 LRU 的"最近使用"顺序
int Get(int key){auto ret = _hashmap.find(key);if (ret != _hashmap.end()) //找到了{list<pair<int, int>>::iterator it = ret->second;_list.splice(_list.begin(), _list, it);return it->second;}else //没找到{return -1;}}
4.2 Put(int key,int value)
这个put的作用也挺直接明了,就是插入,然后如果满了就重新维护一下LRU顺序
逻辑如下:
-
检查容量:
-
如果缓存已满,删除链表尾部的节点(最久未使用)
-
同步删除
_hashmap中对应的键
-
-
插入新节点:
-
将新键值对插入链表头部
-
在
_hashmap中记录键和链表头迭代器
情况2:更新已有键
-
-
更新值:直接通过迭代器修改链表节点的值
-
移动节点:用
splice将节点移动到头部(表示最近使用)
关键点:
-
新增时:需处理容量满的情况,淘汰最久未使用的数据(链表尾部)
-
更新时:只需修改值和移动节点,无需处理容量
void Put(int key, int value){auto ret = _hashmap.find(key);//首先判断是不是新增,找到尾巴都没找到就是新增,还没找到尾巴说明找到了插入就是更新,因为LRU默认不允许插入重复if (ret == _hashmap.end()) //找到尾巴了都没找到相同的:新增 {if (_capacity == _hashmap.size()) //容量满了就删{pair<int, int> back = _list.back();_hashmap.erase(back.first);_list.pop_back();}//删完插入_list.push_front(make_pair(key, value));_hashmap[key] = _list.begin();}else //没找到尾巴就找到了,说明存在就:更新{list<pair<int, int>>::iterator it = ret->second;it->second = value;_list.splice(_list.begin(), _list, it);}}
好,那成功实现了以上的两个函数之后我们再把它加入到最初的那个类里面我们就成功地实现了这个任务了!!😊
5.总结
我们通过一个LRUCache的类里面的两个函数结合链表和哈希表完成了实现。🤓✌️
完整版代码可以查看我的Gitee链接:点击此处
相关挑战练习题可以查看链接:点击此处