一、实时数仓的演进方案
传统意义上我们通常将数据处理分为离线的和实时的。对于实时处理场景,我们一般又可以分为两类:
- 诸如监控报警类、大屏展示类场景要求秒级甚至毫秒级;也可以叫做指标类点查数据。
- 诸如大部分实时报表的需求通常没有非常高的时效性要求,一般分钟级别,比如10分钟甚至30分钟以内都可接受。
目前市场上解决此类需求的方案大致有以下几类: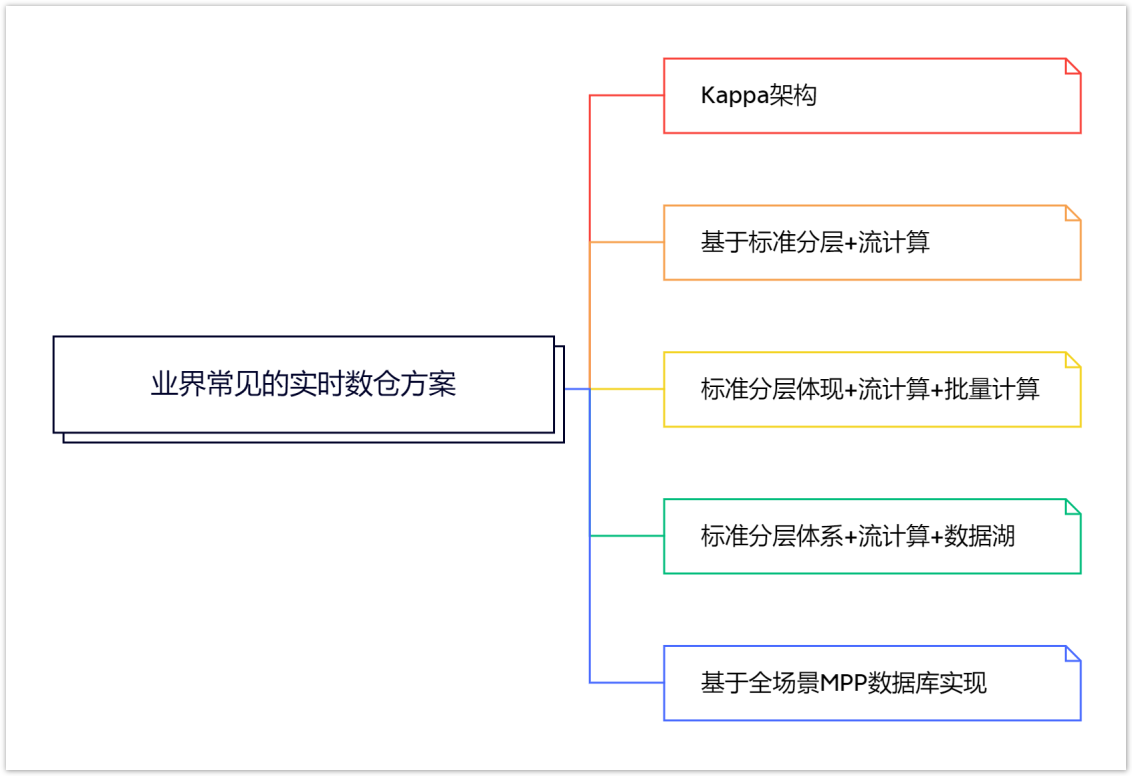
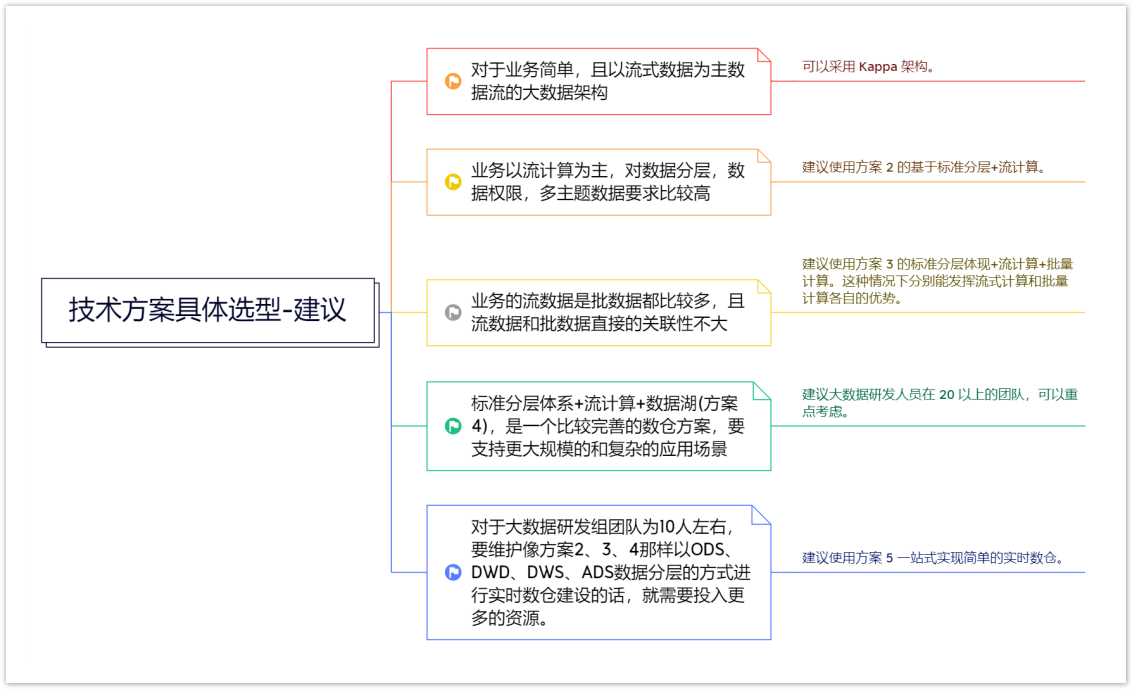
方案 1:Kappa 架构
Kappa架构将多源数据(用户日志,系统日志,BinLog日志)实时地发送到Kafka中。然后通过Flink集群,按照不同的业务构建不同的流式计算任务,对数据进行数据分析和处理,
并将计算结果输出到MySQL/ElasticSearch/HBase/Druid/KUDU等对应的数据源中,最终提供应用进行数据查询或者多维分析。
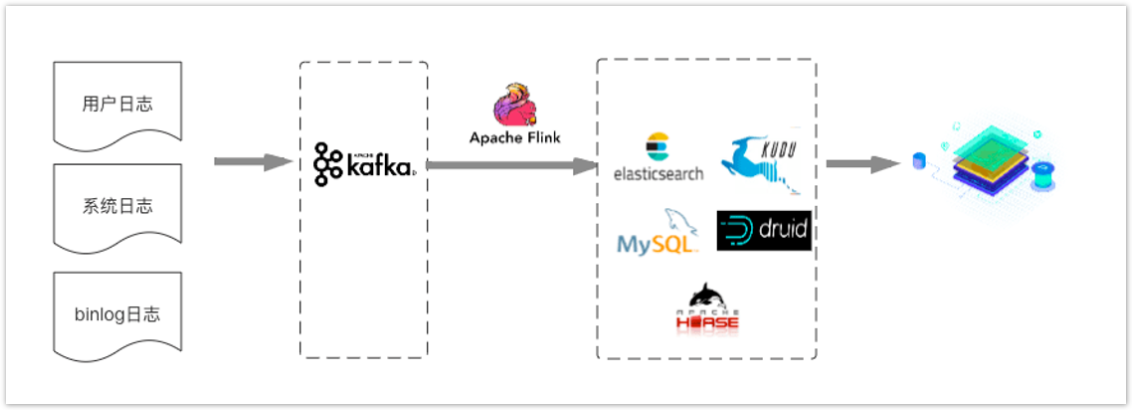
这种方案就是典型的早期开发模式:直桶式开发,特点:方案简单;数据实时。
不过有两个缺点:
- 用户每产生一个新的报表需求,都需要开发一个Flink流式计算任务,数据开发的人力成本和时间成本都较高。
- 对于每天需要接入近百亿的数据平台,如果要分析近一个月的数据,则需要的Flink集群规模要求很大,且需要将很多计算的中间数据存储在内存中以便多流Join。
方案 2:基于标准分层 + 流计算
为了解决方案1中将所有数据放在一个层出现的开发维护成本高等问题,于是出现了基于标准分层+流计算的方案。早期趣头条广告部门使用这种方案完搭建一套广告实时数仓,满足当时的需求。
在传统数仓的分层标准上构建实时数仓,将数据分为ODS、DWD、DWS、ADS层。首先将各种来源的数据接入ODS贴源数据层,再对ODS层的数据使用Flink的实时计算进行过滤、清洗、转化、关联等操作,形成针对不同业务主题的DWD数据明细层,并将数据发送到Kafka集群。
之后在DWD基础上,再使用Flink实时计算进行轻度的汇总操作,形成一定程度上方便查询的DWS轻度汇总层。最后再面向业务需求,在DWS层基础上进一步对数据进行组织进入ADS数据应用层,业务在数据应用层的基础上支持用户画像、用户报表等业务场景。
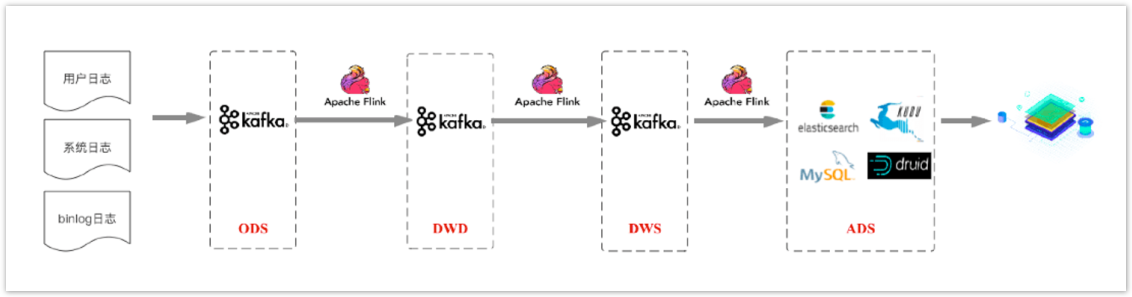
这种方案的优点:各层数据职责清晰,数据实时性也高。
缺点:是多个Flink任务维护起来复杂,并且过多的数据驻留在Flink任务内保持状态也会增大集群的负载,不支持upset操作,同时Schema维护麻烦。 对集群的稳定性要求高。
方案 3:标准分层体现+流计算+批量计算(Lambda架构)
为了解决方案2不支持upset和schema维护复杂等问题。我们在方案2的基础上加入基于HDFS加Spark离线的方案。也就是离线数仓和实时数仓并行流转的方案。
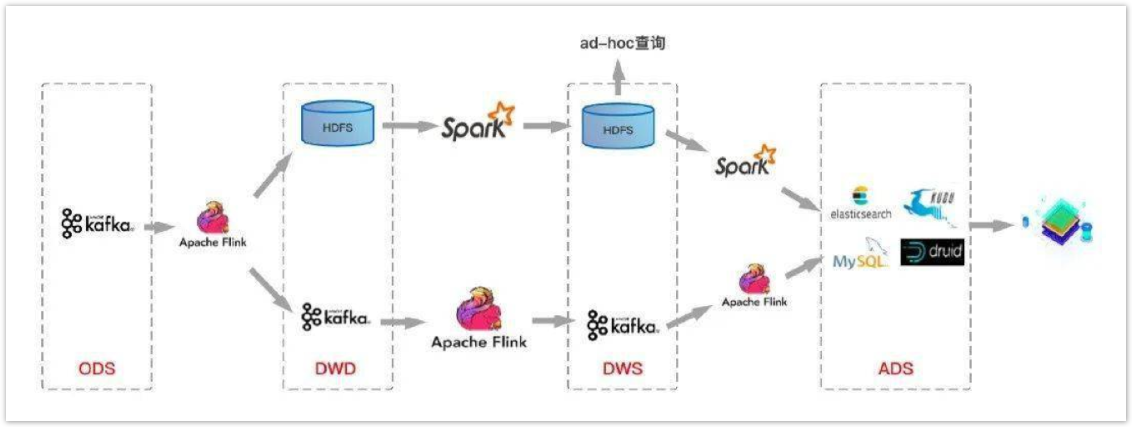
这种方案带来的优点:既支持实时的OLAP查询,也支持离线的大规模数据分析。
缺点:数据质量管理复杂,需要构建一套兼容离线数据和实时数据血缘关系的数据管理体系,本身就是一个复杂的工程问题。离线数据和实时数据Schema统一困难,架构不支持upset。
- 数据口径不一致
- 数据重跑问题
方案 4:标准分层体系+流计算+数据湖
随着技术的发展,为了解决数据质量管理和upset 问题。出现了流批一体架构,这种架构基于数据湖三剑客 Delta Lake / Hudi / Iceberg 实现 + Flink SQL 实现。
以Iceberg为例介绍下这种方案的架构,从下图可以看到这方案和前面的方案2很相似,只是在数据存储层将Kafka换为了Iceberg。
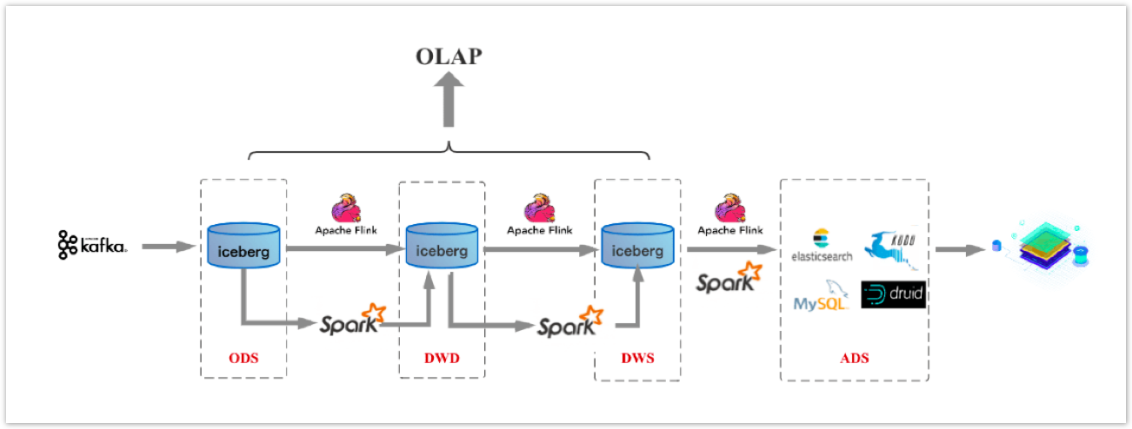
它有这样的几个特点,其中第2、3点,尤为重要,需要特别关注下,这也是这个方案和其他方案的重要差别。
- 在编程上将流计算和批计算统一到同一个SQL引擎上,基于同一个Flink SQL既可以进行流计算,也可以进行批计算。
- 将流计算和批计算的存储进行了统一,也就是统一到Iceberg/HDFS上,这样数据的血缘关系的和数据质量体系的建立也变得简单了。
- 由于存储层统一,数据的Schema也自然统一起来了,这样相对流批单独两条计算逻辑来说,处理逻辑和元数据管理的逻辑都得到了统一。
- 数据中间的各层(ODS、DWD、DWS、ADS)数据,都支持OLAP的实时查询。
那么为什么 Iceberg 能承担起实时数仓的方案呢,主要原因是它解决了长久以来流批统一时的这些难题:
- 同时支持流式写入和增量拉取。
- 解决小文件多的问题。数据湖实现了相关合并小文件的接口,Spark / Flink上层引擎可以周期性地调用接口进行小文件合并。
- 支持批量以及流式的 Upsert(Delete) 功能。批量Upsert / Delete功能主要用于离线数据修正。
- 同时 Iceberg 还支持比较完整的OLAP生态。比如支持Hive / Spark / Presto / Impala 等 OLAP 查询引擎,提供高效的多维聚合查询性能。
方案 5:基于全场景MPP数据库实现
前面的四种方案,是基于数仓方案的优化。方案仍然属于比较复杂的,如果我能提供一个数据库既能满足海量数据的存储,也能实现快速分析,那岂不是很方便。这时候便出现了以StartRocks和ClickHouse为代表的全场景MPP数据库。
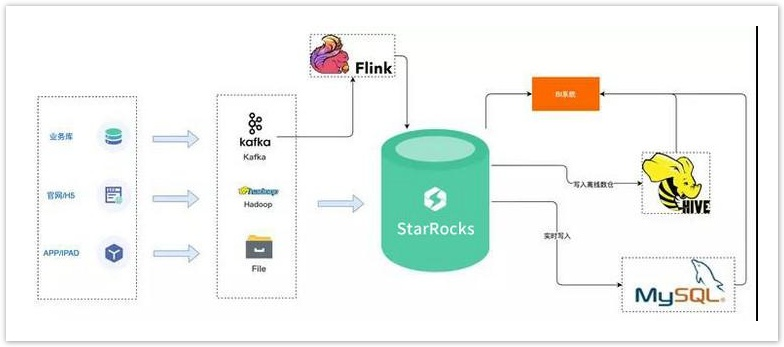
- 基于Doris或者ClickHouse构建实时数仓。来看下具体的实现方式:将数据源上的实时数据直接写入消费服务。
- 对于数据源为离线文件的情况有两种处理方式,一种是将文件转为流式数据写入Kafka,另外一种情况是直接将文件通过Sql导入ClickHouse集群。
- ClickHouse接入Kafka消息并将数据写入对应的原始表,基于原始表可以构建物化视图、Project等实现数据聚合和统计分析。
- 应用服务基于ClickHouse数据对外提供BI、统计报表、告警规则等服务。
以上方案并不需要说明是哪个更好或有问题,在当时每个公司发展阶段以及公司员工等考虑中得出的最佳解决方案。
现阶段我们使用StarRocks作为实时数仓的奠定基石,是一个最佳方案。在当前架构基础之上做到数据实时化,涵盖哪些场景,需要哪些场景实时,后面需要提升的点在哪?下面我们来探讨这个问题!
二、基于StarRocks实时数仓的使用场景
- OLAP (Online Analytical Processing) 多维分析
- 定制报表
- 实时指标数据分析
- Ad-hoc 数据分析
我们在使用StarRocks通过帆软对外提供服务,涉及到指标数据、报表数据、多维分析这三类。