一、Introduction
传统的无人驾驶采用了区分子模块的设计,即将无人驾驶拆分为感知规划控制三个模块,这虽然能够让无人驾驶以一个很清晰的结构实现,但是感知的结果在传达到规划部分的时候,会导致部分信息丢失,这势必会让很多关键信息无法传递到规划部分,限制整体的算法运行。端到端的无人驾驶则是将感知、预测和规划整合为一个整体,并以规划为任务的核心。在这篇出名的无人驾驶论文中,作者将无人驾驶分为了五个关键的子任务,作者讨论了对于一个端到端的无人驾驶任务来说,究竟哪个模块是必须保留的,而哪些模块是可有可无的。
二、Methodology
Overview
UniAD采用的是基于Transformer的结构,整个框架基于Transformer设计了四个子模块以及一个预测模块。输入的环视图像首先使用BEVFormer转换为BEV特征,后续的所有任务都基于这个BEV视角。作者特地提到,这里并不对使用的BEV模块做限制,任何一个能够完成BEV特征提取的模型都可以用在这里,作者在UniAD中使用的框架叫BEVFormer,也是一个基于Transformer的模型。转换为BEV特征后,首先使用两个特征提取的模块TrackFormer和MapFormer分别提取场景中的agent信息和地图信息,之后使用这两个信息在MotionFormer里面进行预测,得到未来的轨迹信息,这些轨迹信息在OccFormer里面转换为未来时刻场景中占用的预测,最后在Planner的部分完成轨迹的生成和优化。
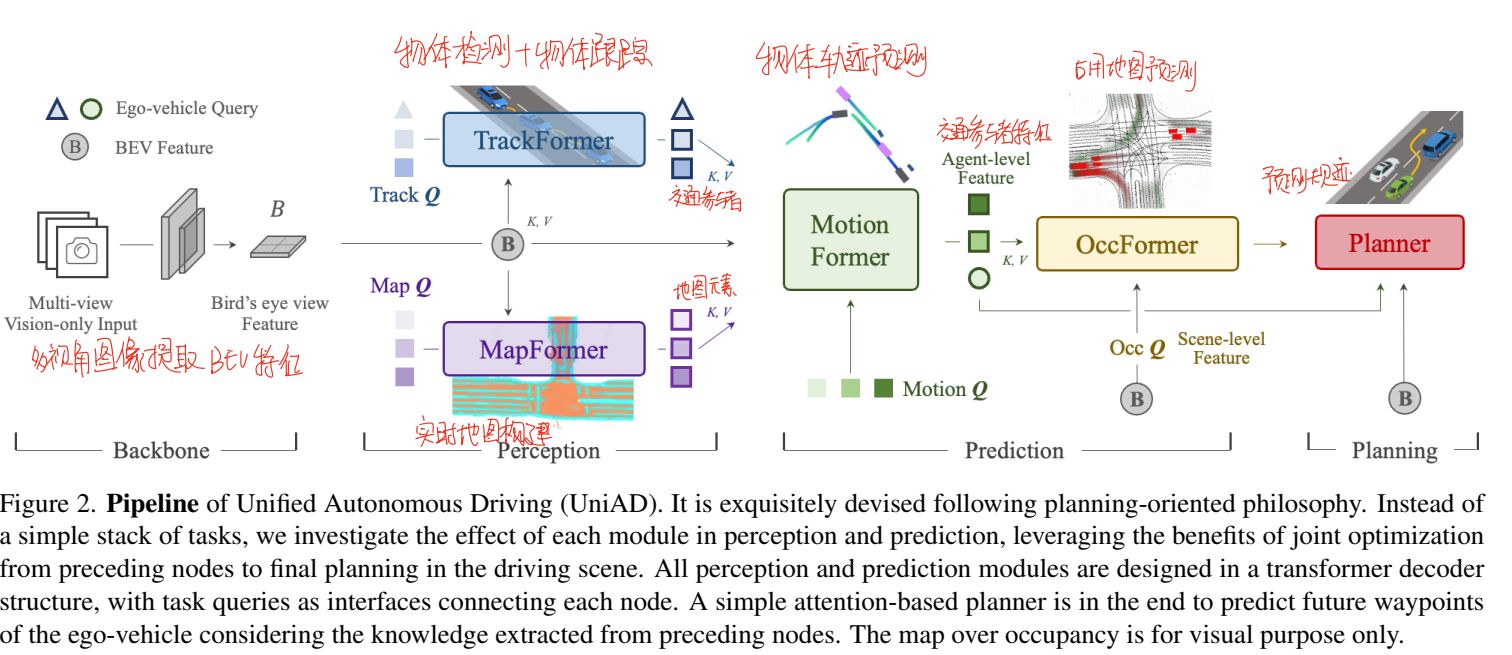
Perception: Tracking and Mapping
UniAD里面的感知模块和传统架构里面的感知模块类似,都是负责从场景中提取特征用于高层的规划任务,这一部分主要包括了两个子模块:TrackFormer和MapFormer。前者负责提取场景中的其它参与者agent,后者则负责提取场景中的地图元素。
TrackFormer
在UniAD中,TrackFormer主要负责从当前帧的BEV视角下,提取出场景中所有的agent在当前时刻的状态信息。这一部分包括了两个查询:detection query和track query。原文提到,每个时刻都有一个detection query负责检测是否出现了新的个体,同时还有一个track query负责对这些已经检测到的agent进行建模并跟踪。两个query都是基于前面的BEVFormer提取到的BEV特征。如果拿传统的框架对比,这里的detection query对应的是目标检测,而track query对应的是目标跟踪。虽然原文没有明说,但是个人推测这里的两个query和VAD中的query应该是相通的,都属于可学习的query,可以视作一种特征提取器。
在track query中,考虑到跟踪这个任务是存在时序性的,历史信息能够指导当前帧的检测。所以在这个query中作者使用了类似SLAM中恒速跟踪模型的策略,即历史的查询结果会与当前帧的track query进行自注意力计算,用于增强局部信息。TrackFormer的输入是BEV视角下的特征,输出是Na个合法的agent的状态信息QA,这些信息展示了当前时刻场景中所有agent的信息,会被用到后续的预测阶段。
除了这两个query,作者还引入了一个用于查询自车状态的query,称为ego query,这个查询也归属于TrackFormer中,主要用于得到自车的状态信息,比如自车当前的位置变化、与周围其它agent的交互等,相当于传统框架中odometry的部分,这些也会被用在后面的预测模块中。
MapFormer
原文关于MapFormer的介绍十分简短。这部分的MapFormer主要依赖于一个2d的全景分割SegFormer。在这个模块中一共使用了车道、隔离带、路口以及可行驶区域四种query,利用可学习query从BEV视角下提取这四种特征。这个模块的输入也是BEV视角下的特征,输出的地图元素QM被送到预测模块用于产生规划信息。
这里补充一下全景分割。全景分割不同于语义分割,语义分割告诉你“这是什么”,而全景分割还能告诉你“它是哪个”。相当于直接输出场景中的带有语义的个体信息。利用这个技术得到的场景信息是更加复杂的场景信息。

Prediction: Motion Forecasting
预测模块主要负责利用感知模块提取的状态信息,预测未来一段时间内场景中所有的agent的状态变化,也就是基于QA和QM预测未来的状态。原文提到的是会输出Na个交通参与者在未来T时刻的k个模态下的状态信息。
MotionFormer
预测的第一个模块是MotionFormer,它本质上属于一个经典的多层transformer的解码器。这个模块负责预测agent的未来状态。为了充分体现场景中不同元素之间的相互影响关系,这个模块内部设计了三种注意力机制。
对于每个motion query,它首先与感知模块的感知结果QA和QM进行多头交叉注意力和多头自注意力计算,这样得到自车与其它agent、地图元素之间的交互结果:
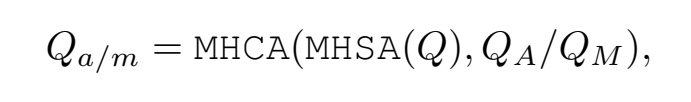
除了这两个交互,作者还引入了第三个交互,老实说第三个交互没太看懂,我的理解是目标点与自车状态的交互。在MotionFormer中目标点是逐层动态更新的,这里在每一层中,都会使用上一层预测的终点作为参考点,利用Deformable Attention让Motion query与目标点、BEV特征产生联系。

这个模块的输出包括三部分:Qa、Qm和Qg,这三个输出会通过多层感知机进行结合,对齐之后得到一个包括了各个agent状态信息的query,原文叫做上下文query Qctx,这个东西会用于后续的轨迹预测。
MotionQueries
MotionFormer里面使用的MotionQuery是一个很复杂的query,它实际上是由两个内容叠加出来的:上一层的Qctx与当前层的位置信息query Qpos。上一层的Qctx就是上一部分的输出,对于第一层,Qctx就变成了QA。
Qpos则形容了当前这一层的位置信息,其本身包括四个部分:场景级的位置状态、agent级的位置状态、agent的当前位置以及预测的目标点。
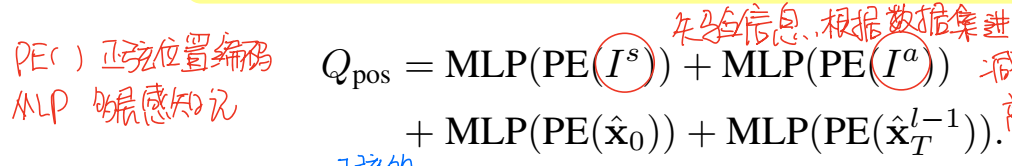
这里原文讲的比较抽象,简单来说,这一步是在缩小搜索空间。Is和Ia属于是先验信息,直接从训练用的数据集中进行提取。Is是所谓的场景级,可以将其理解为“对于某个场景下常出现的行为”,比如说十字路口常出现的是直行和转弯,利用这个先验信息我们可以减小参数的搜索空间,不必遍历大量的不太容易出现的行为。Ia指的是agent级,我们可以将其理解为“某个agent常出现的行为”,也是利用数据集提取到的先验信息。
Non-linear Optimization
上一步得到的轨迹,在最后经过一个非线性优化。这一步主要是对预测的轨迹进行修正,让模型预测出的轨迹符合运动学,同时保持轨迹光滑。优化的部分包括三部分:轨迹与真值相近、终点与目标点相近、轨迹符合车辆动力学。
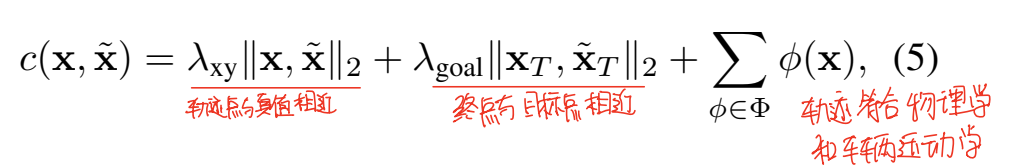
Prediction: Occupancy Prediction
不同于VAD向量化的表示方法,UniAD中需要将Motion Forecasting的预测结果转换为占用地图的预测,这一部分是在预测模块的最后OccFormer部分实现的。原文写的是,这部分具有To个时序块,每个块对应一个未来的时间戳。每一块都需要处理两类信息:场景信息和agent信息。
首先,MotionFormer输出的motion query Qx会被最大池化,之后与Track部分的agent query及其位置嵌入PA进行结合,得到t时刻的agent级别的表征。
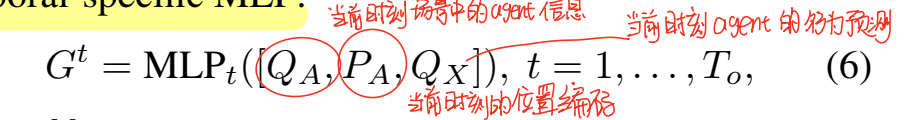
对于场景级的表征,BEV特征首先被下采样,之后使用两种交互来进一步提高特征表征能力。首先是像素-agent交互,这一部分是为了让场景的像素知道哪一个agent会占用它。
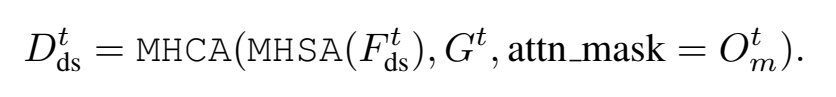
另一个交互是实例级占用地图生成,不同于传统的聚类的方法,OccFormer直接用矩阵乘法得到占用信息。
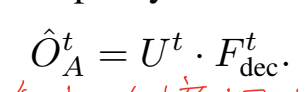
Planning
在上一步栅格地图预测的基础上,Planning模块最后会用于计算轨迹,这部分其实就是一个具体化的head,在不改变驾驶意图的前提下,避开场景中所有未来可能占用的区域。
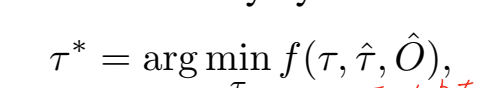
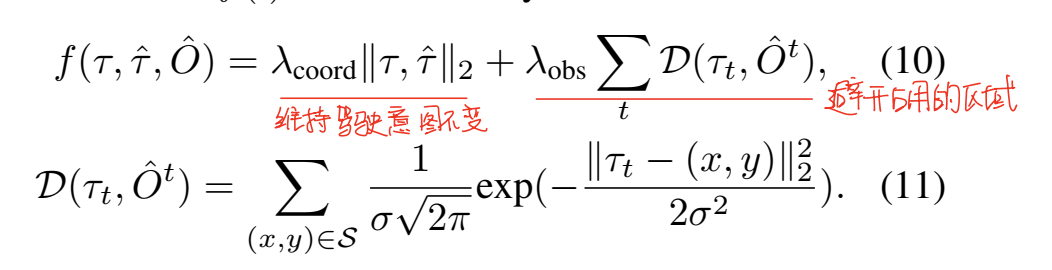
三、总结
UniAD是一个十分庞大的系统,后面Planning和OccFormer的部分看的不是很细。整体来说,整个模型以车辆的环视图为输入,首先用BEVFormer进行特征提取,得到的BEV特征首先送到Perception部分利用TrackFormer和MapFormer提取当前的环境信息,得到当前时刻静态的agent信息和地图信息。在Predicition的部分,MotionFormer会将静态的信息转换为对未来的轨迹预测,预测未来T时刻内场景中每个agent可能的行进轨迹,之后再有OccFormer将这个行进轨迹转换为未来的道路空间占用情况。最后在Planning的部分,将所有的信息归纳并在不改变驾驶意向和不与占用空间产生碰撞的情况下规划出一个最好的自车轨迹。