Dictionary<TKey, TValue> 是 System.Collections.Generic 命名空间下的高性能键值对集合,其核心实现基于哈希表和链地址法(Separate Chaining)。
.Net4.8 Dictionary<TKey,TValue>源码地址:
dictionary.cs (microsoft.com)![]() https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,d3599058f8d79be0
https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,d3599058f8d79be0
原理:
1.初始化:
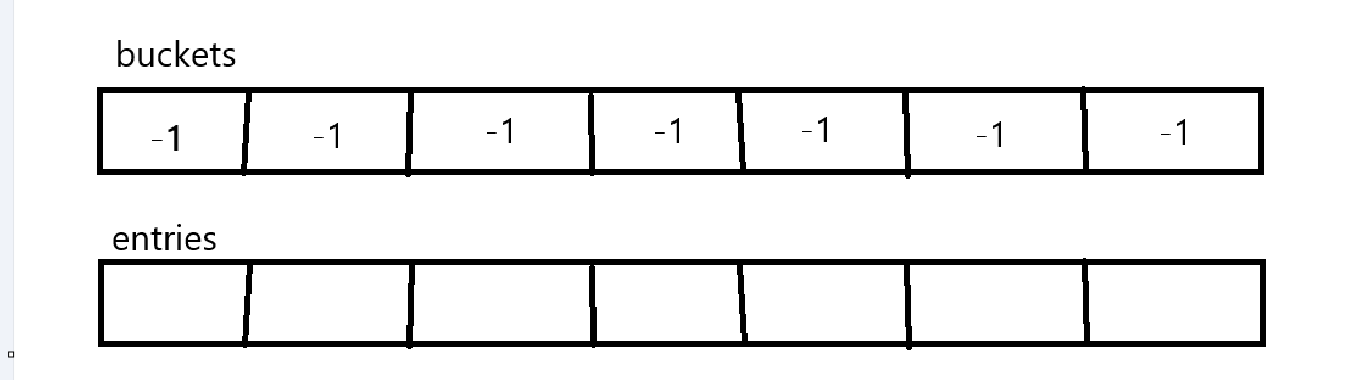
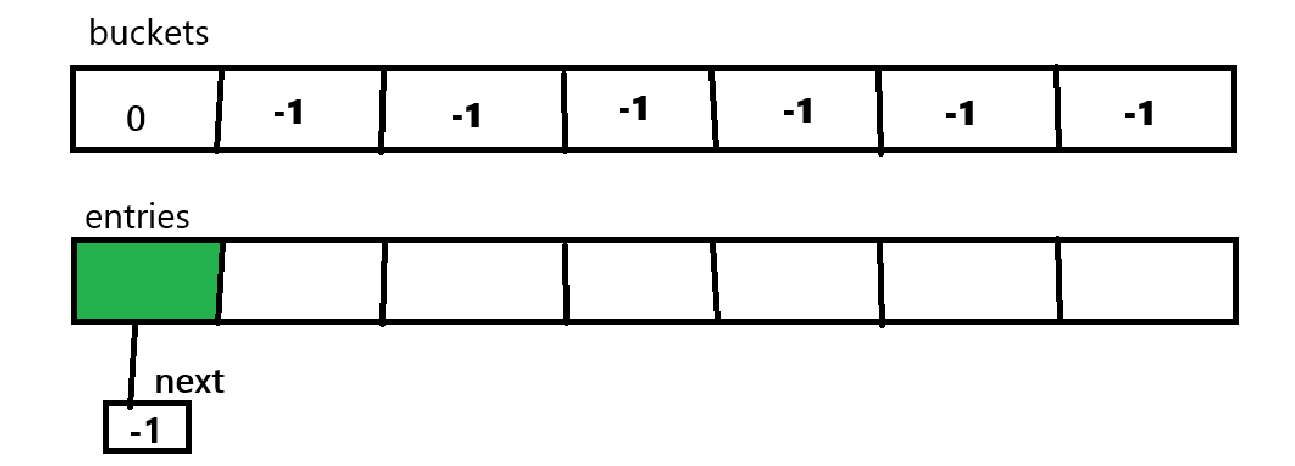
一个字典会对应一个哈希桶数组,一个键值对数组,如下图所演示的测试图:
2.存储元素:
首先用传入的key值通过比较器计算一个hashcode,再取余得到哈希桶的索引值
![]()
这时字典中没有数据,通过上述索引值得到哈希桶中值是-1,
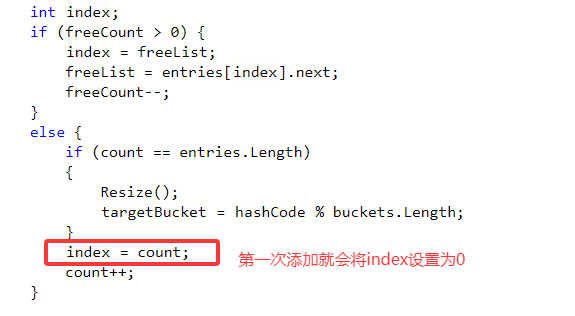
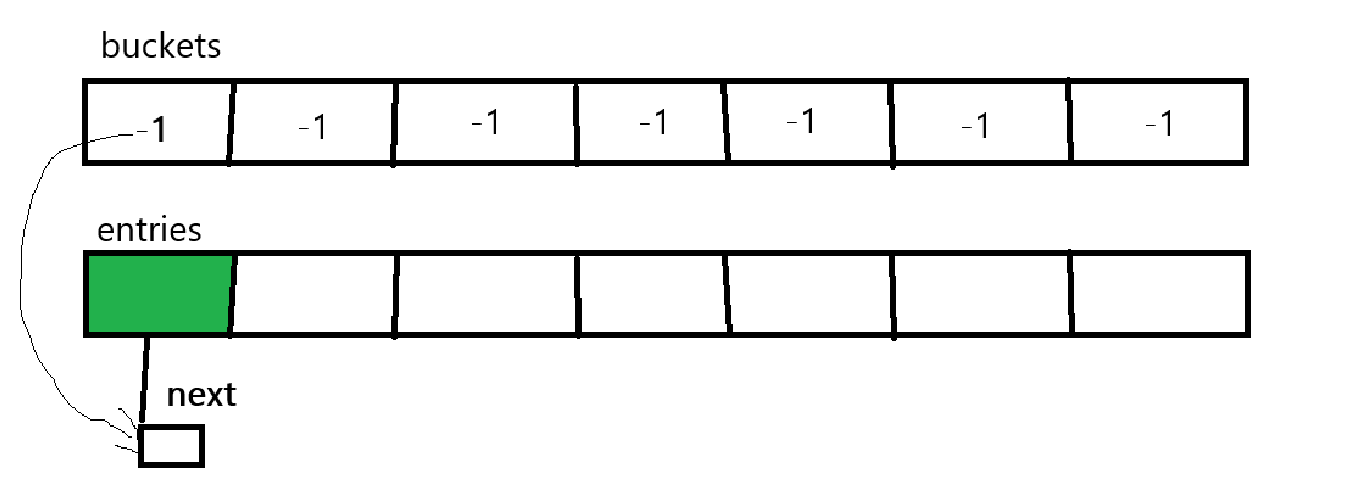
然后在键值对数组的索引为0处存储值,并将当前的取得哈希桶中的数据赋值给键值对当前数据的next指针,再将index赋值给哈希桶当前的数据。

------------------------------------------->
如果得到已经存储的哈希桶的索引值,就会存储到这个数据或者链地址上的数据的next指针为-1的位置。比如在现有的情况下,再次存储元素时,恰好计算出的哈希桶的索引值为0,这时就选择entries中的一个空位置或者是当前count对应的索引位置存储,
按例子的情况是存储在count对应的索引位置也就是1的位置,针对空闲的位置的存放也同理。
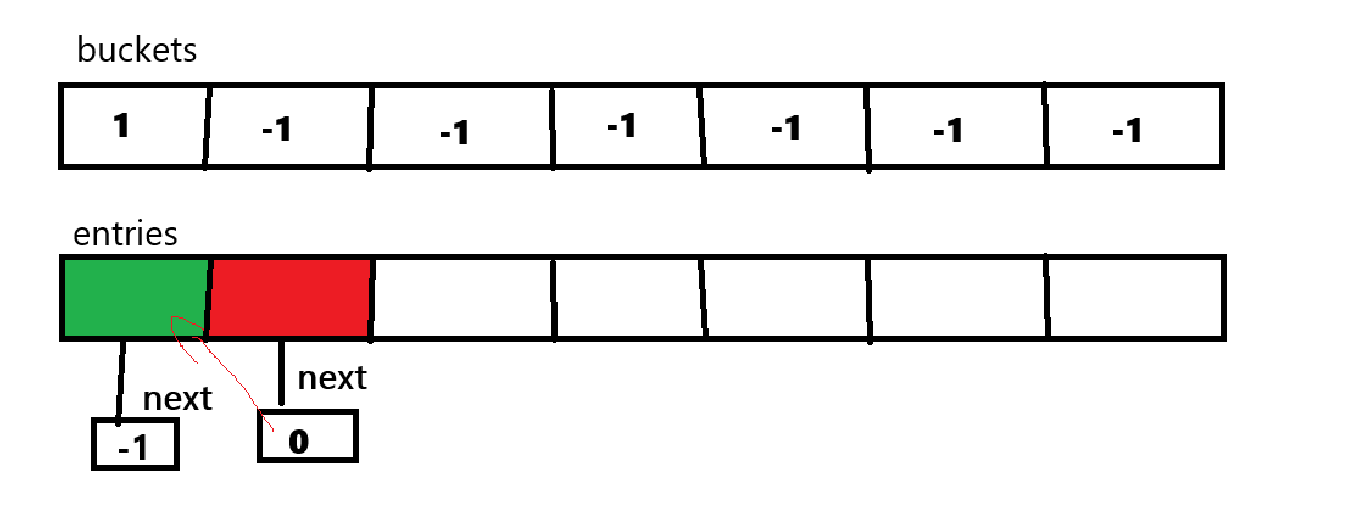
也就是将entries中索引为1的位置填充新存储的元素,将其next指针指向entries中索引为0的位置,最后将哈希桶中索引为0的位置设置为1。
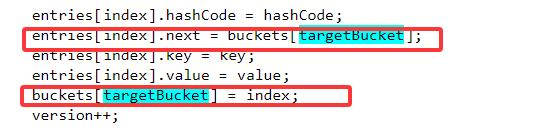
这样就完成了在哈希值取余之后发生冲突的链地址法解决方案。
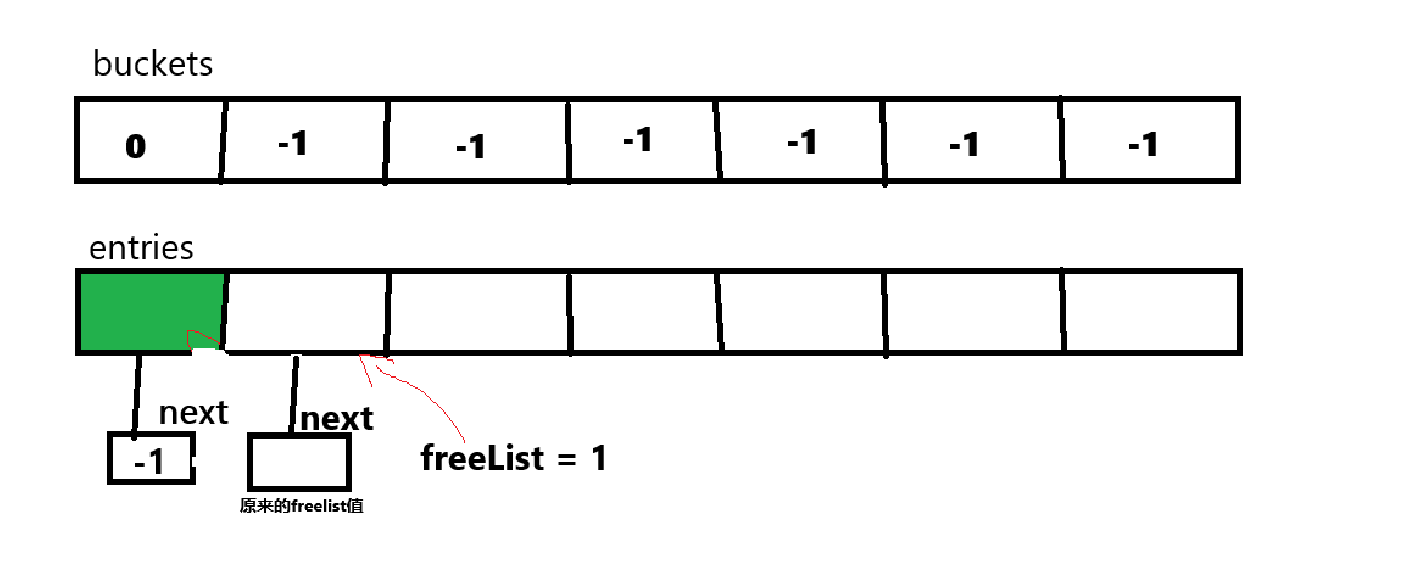
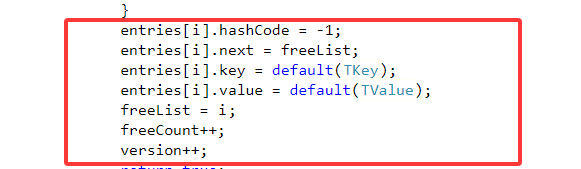
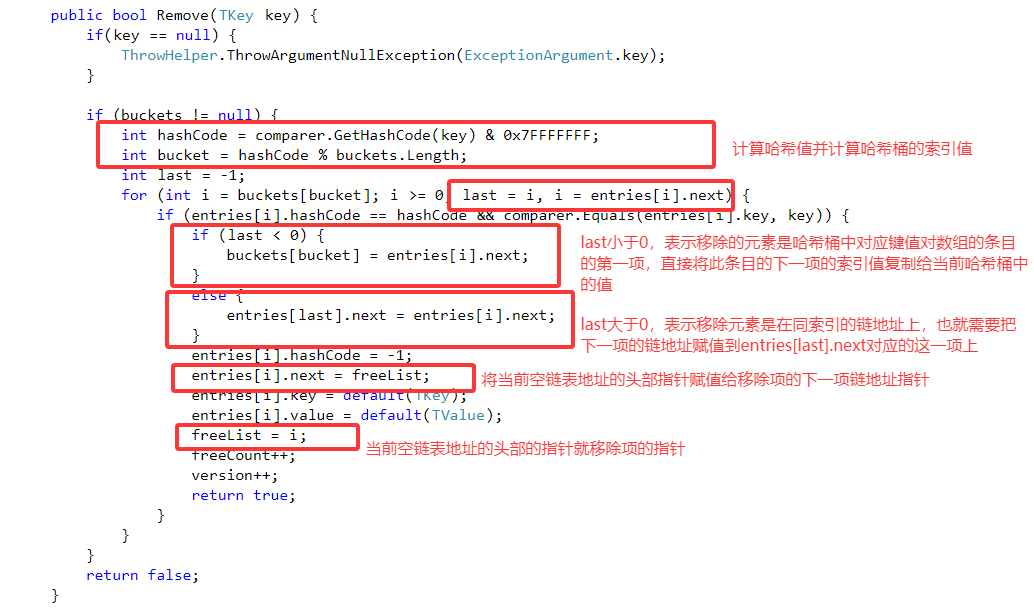
3.移除元素:
移除元素也分为两部分,一部分是移除不在链地址上的元素,另一部分就是移除在链地址上的元素,按照上面的例子,就是分别移除entries索引0和1的处理方式:

移除不在链地址上的元素时,也就是移除索引1的元素时
移除在链地址上的元素时,也就是移除索引为0的元素时 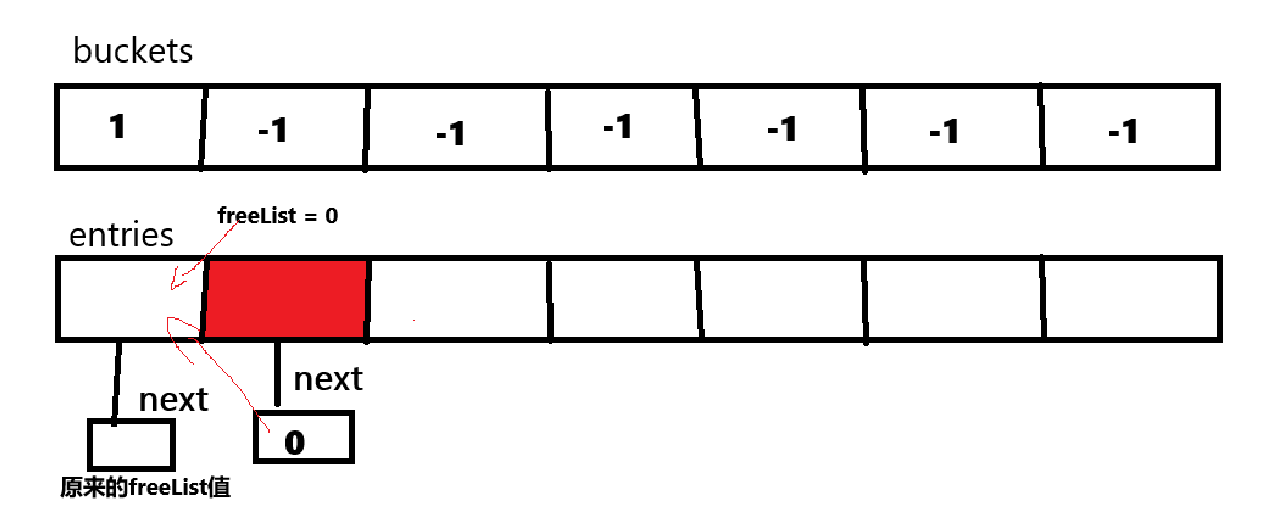
内部结构:
1.主要字段和属性: 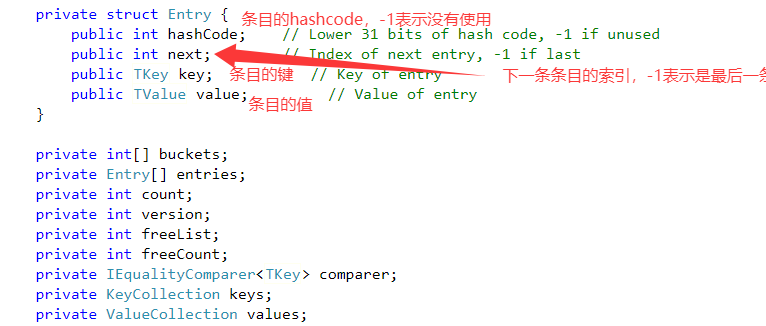
1.buckets:这是一个整型数组,用作哈希桶。每个元素都代表一个桶的索引,而桶是用于存放键值对的链表的头节点(即entries中的元素索引)。
2.entries:这是一个 Entry 结构体数组,Entry 结构体包含键、值、哈希码以及指向下一个 Entry 的索引。
3.count:该字段表示 Dictionary 中当前键值对的数量。
4.version:这是版本号,在对 Dictionary 进行修改操作时,版本号会更新,主要用于在迭代期间检测集合是否被修改。
5.freeList:此为空闲列表的头索引,用于管理已删除的 Entry 槽位,方便后续复用。
6.freeCount:该字段表示空闲列表中 Entry 的数量。
7.comparer:这是一个 IEqualityComparer<TKey> 类型的比较器,用于比较键的相等性。
8.keys:这是一个 KeyCollection 类型的对象,用于表示 Dictionary 中的所有键。
9.values:这是一个 ValueCollection 类型的对象,用于表示 Dictionary 中的所有值。

表示当前字典中含有的键值对数量。
注:因为在字典中移除元素时,字典的count并没有改变,count只在freeCount(字典中空闲的数量)为0时,才进行增加的操作,所以在获取字典中有效的键值对数量时,需要用count - freeCount来计算。
2.构造函数:
1.无参构造函数、指定初始容量的构造函数、指定比较器的构造函数、指定初始容量和比较器的构造函数:
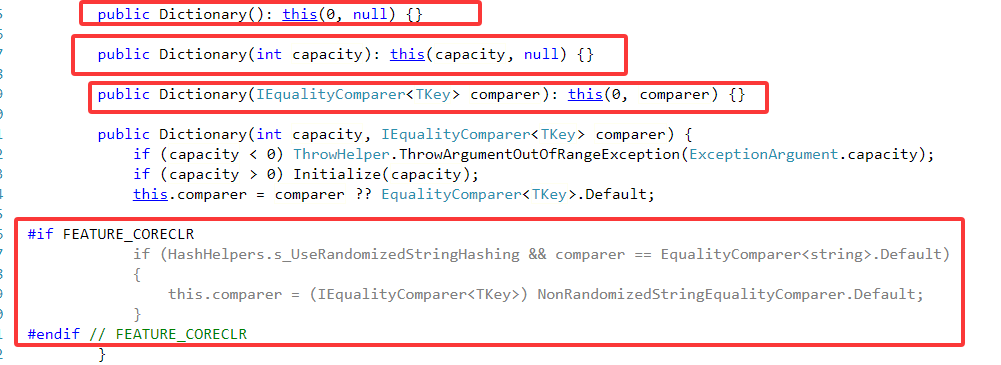
最终都调用了指定容量和比较器的构造函数。
1.CoreCLR 平台的特殊处理:

HashHelpers.s_UseRandomizedStringHashing:
作用:标志位,指示是否启用随机化字符串哈希(防御哈希碰撞攻击)。
默认值:在 .NET Core 中通常为 true。
comparer == EqualityComparer<string>.Default:
条件:检测用户是否显式使用了默认的字符串比较器。
替换比较器:
this.comparer = (IEqualityComparer<TKey>) NonRandomizedStringEqualityComparer.Default;
目的:
在启用随机化哈希的平台上,若用户未指定自定义比较器,强制使用非随机化比较器。
兼容性:确保与旧版本 .NET Framework 行为一致,避免因随机化哈希导致的跨版本不一致问题。
2.初始化容量:
如果指定了容量就会调用到Initialize函数,如下:
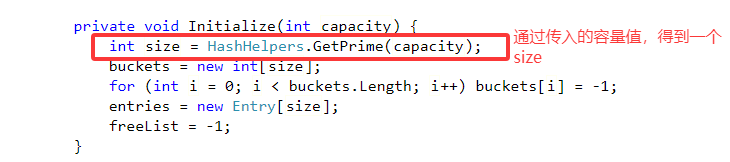
通过HashHelpers.GetPrime得到一个新的值,作为哈希桶和键值对数组的容量,代码如下:
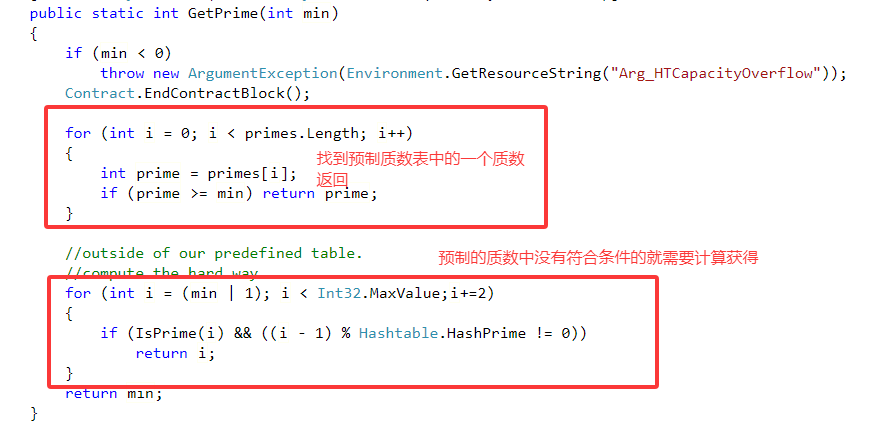 解释:
解释:
1. min|1:确保 i 初始值为大于等于 min 的最小奇数。min | 1 将 min 的最低二进制位强制设为 1。若 min 是偶数,结果为 min + 1;若 min 是奇数,结果不变。
2.IsPrime(i):验证 i 是否为质数。
3.(i - 1) % Hashtable.HashPrime != 0:确保 i - 1 不能被预定义的质数 HashPrime 整除。
![]()
作用:
上述代码通常用于哈希表扩容时选择新容量,其设计目标包括:
减少哈希冲突:选择质数作为容量,使哈希分布更均匀。
避免特定冲突模式:通过 (i - 1) % HashPrime != 0 排除某些可能导致冲突的值。
性能优化:跳过偶数和快速终止条件提升搜索效率。
预制的质数表数据如下:

2.指定键值对容器参数的构造函数、指定键值对容器和比较器参数的构造函数:
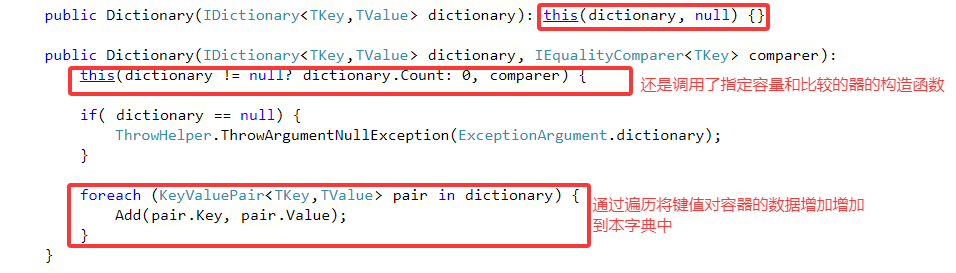
3. 反序列化构造函数:

此构造函数是 .NET 序列化机制中延迟加载模式的经典实现,确保复杂数据结构(如哈希表)在反序列化时的安全性和正确性。通过暂存 SerializationInfo 并在对象图构建完成后恢复数据,有效解决了依赖项初始化和哈希计算的时序问题。
核心原理
(1) 序列化流程
序列化时:调用 GetObjectData 方法(实现 ISerializable 接口),将字典的键值对、容量、比较器等数据写入 SerializationInfo。
反序列化时:
框架通过反射调用此受保护构造函数,传入 SerializationInfo 和上下文。
不立即还原哈希表,而是将 SerializationInfo 暂存到 HashHelpers.SerializationInfoTable(一个静态字典),等待后续处理。
(2) 延迟加载的原因
依赖项未就绪:反序列化时,字典可能依赖其他尚未反序列化的对象(如自定义比较器)。
哈希码计算安全:某些键的 GetHashCode() 可能在反序列化时抛出异常(例如,键对象未完全初始化)。
(3) 完成反序列化
在对象图完全构造后,框架调用 IDeserializationCallback.OnDeserialization 方法,此时从 HashHelpers.SerializationInfoTable 中取出暂存的数据,重建哈希表的 buckets 和 entries 数组。
动态扩容:
在字典中扩容的调用有两处:
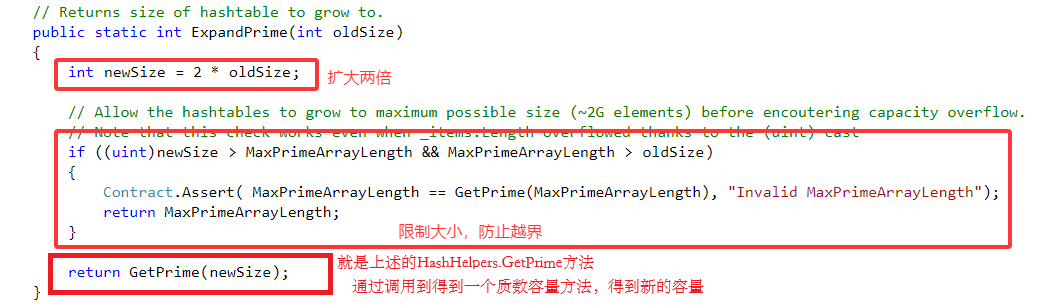
1.字典中的元素已满:会通过一个函数重新找到一个新的容量值。
![]()
ExpandPrime代码如下:

2.字典中的哈希冲突的数量已达到阈值:传入新的容量的是entries当前长度,并强制更新hashcode。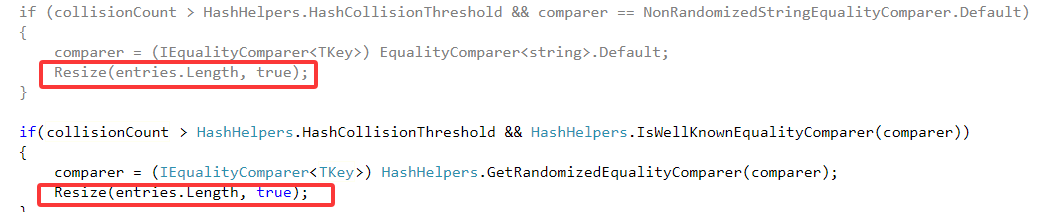
扩容的主要方法如下:
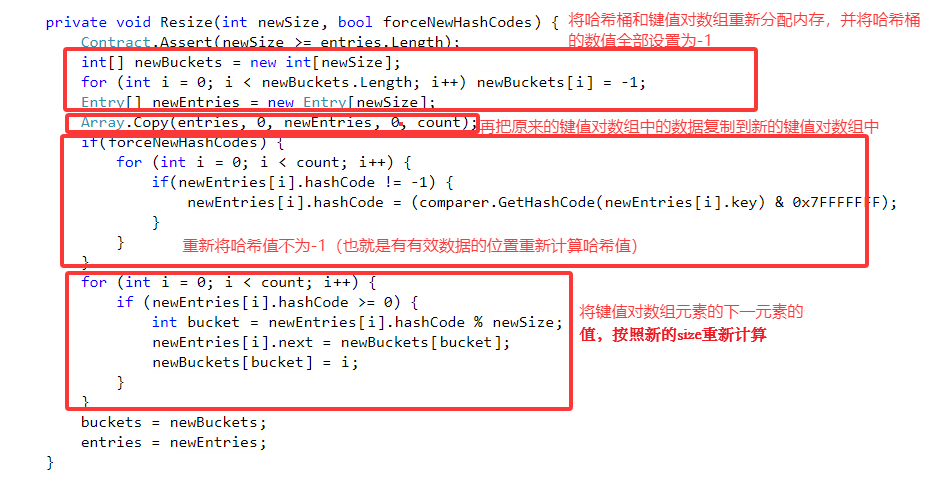
主要方法:
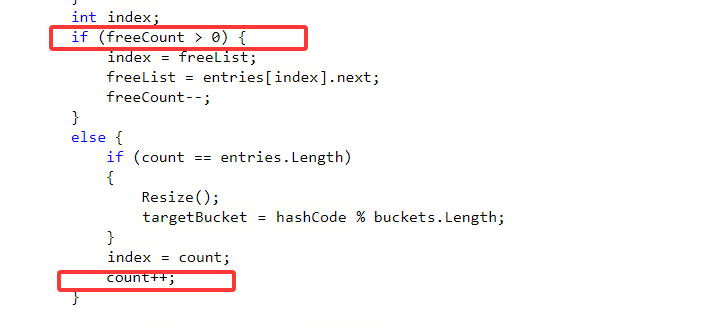
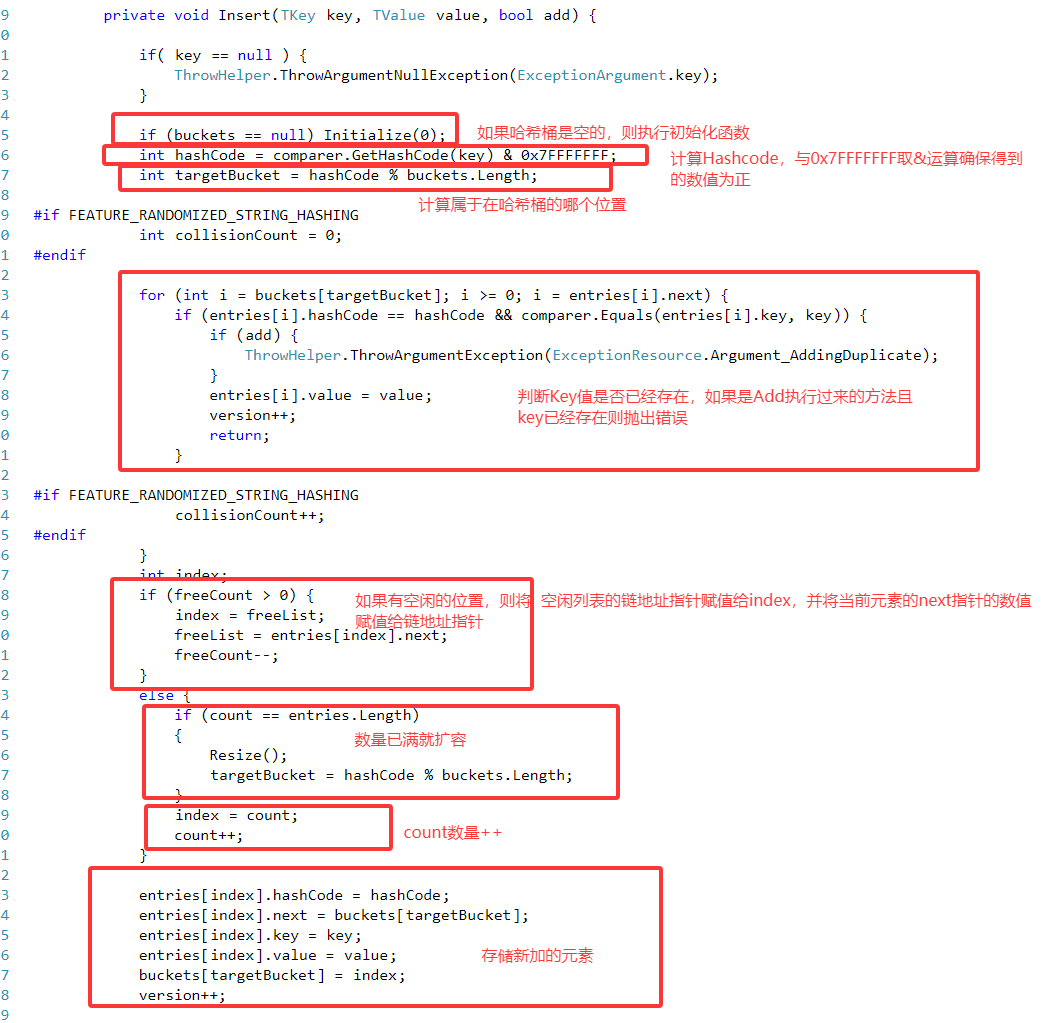
1.Add:调用字典中的Insert方法

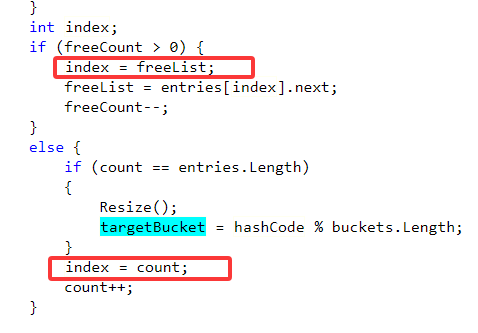
2.Insert:
3.Remove:
4.Clear:将字典中的参数重置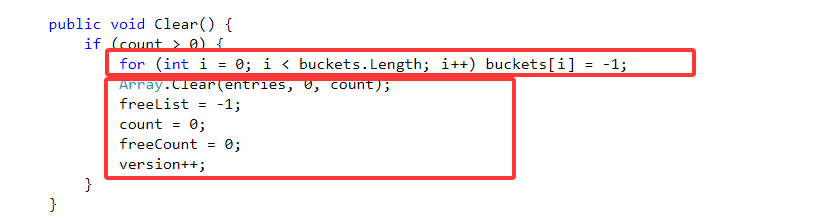
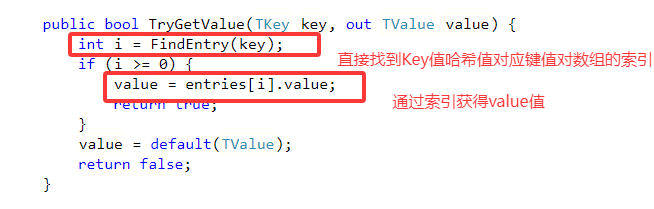
5.FindEntry:
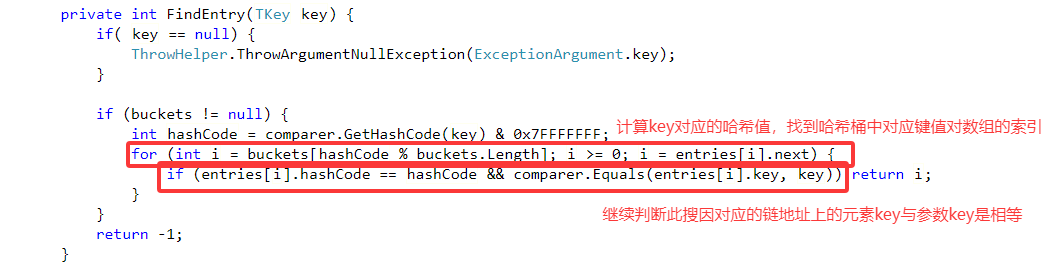
6.ContainsKey:

7.ContainsValue:需要遍历比对value是否相等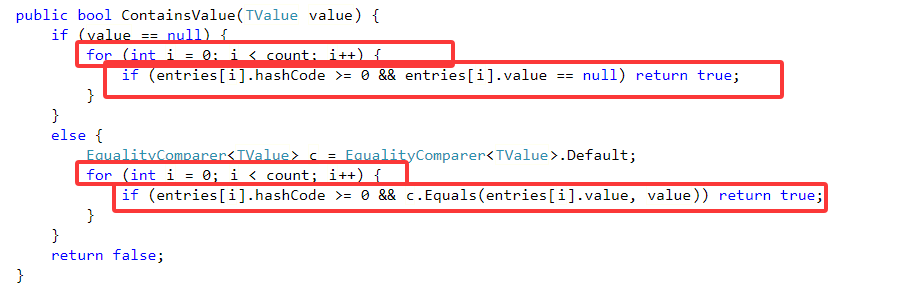
8.TryGetValue: