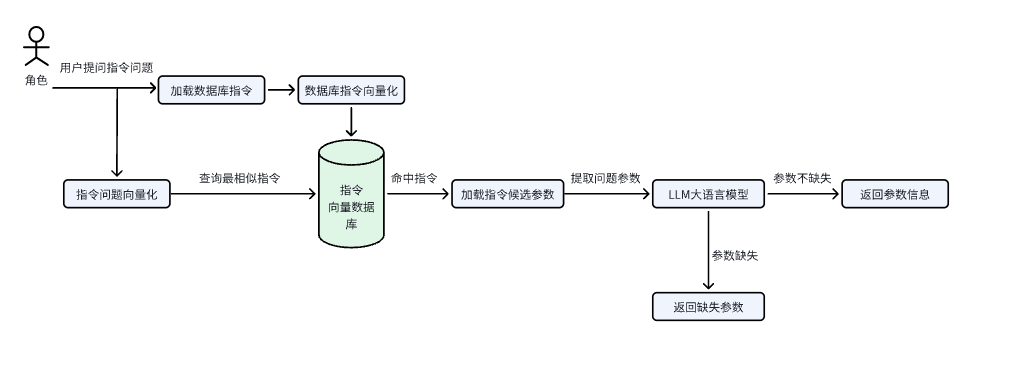
本文主要记录根据用户问题指令,基于大模型做Rag,匹配最相关描述集进行指令调度,可用于匹配后端接口以及展示答案及图表等。
1.指令查询处理逻辑
1.实现思路
-
指令识别:主要根据用户的问题q计算与指令描述集is = [i0, ... , im]和指令关键词集ks = [k0, ... , km]之间的匹配距离sim,选取最匹配的指令,top1/top5
-
用户指令与指令描述集embedding向量匹配相似度
-
关键词处理:提取指令中的关键参数据,用户的问题q计算与指令提示词集ps = [p0, ... , pm],从用户问题中抽取指令执行需要的参数集
2.指令查询实现参数介绍
参数示例
{ attribute_ids: "[{"paramName":"项目名称","paramCode":"prejectname","paramPrompt":"请提取出项目名称","paramWeight":"0.4"}]", uni_key: "001", candidate_value: "科技园工人数量", name: "查询科技园工人数量", description: "查询科技园工人数量", tip_word: "", id: 2, keyword: "科技园,工人,数量", instruction_id: 2 }
参数代表含义
"attribute_ids": 属性值
"uni_key": 参数编码 示例:projectname
"candidate_value": 候选值
"name": "查询科技园工人数量"
"description": "查询科技园工人数量"
"tip_word": "",参数不全提示词
"id": 2,
"keyword": 关键词,
"instruction_id": 2
3.指令查询实现细节
这一部分主要对指令描述集和指令关键词集的处理,针对参数为id,description,keyword
指令识别,主要根据用户的问题q计算与指令描述集is = [i0, ... , im]和指令关键词集ks = [k0, ... , km]之间的匹配距离sim
存储在在self.INSTTS中,记录id,指令描述集description,指令关键词集keyword,示例如下
# 提取内容
ists = jsonobj["data"]
for ist in ists:cid = ist["id"]cdes = ist["description"]ckws = ist["keyword"]self.INSTTS.append((cid, cdes, ckws))# self.INSTTS值
self.INSTTS = [(2, '查询科技园工人数量', '科技园,工人,数量'), (4, '查询3月份营业额', 营业额'), (5, '打开百度首页', '打开,百度'), (6, '查询某项目某地区某段时间的营业额', '查询,项目,地区,营业额'), (7, '请帮我打开智慧工地指挥中心', '打开,智慧工地,指挥中心'), (8, '打开数据标注', '打开,数据标注'), (9, '测试表格指令', '输出,测试表格'), (10, '查询七日气温', '查询,气温'), (12, '测试折线图', '测试折线图'), (13, '测试饼图', '测试饼图'), (14, '测试柱状图', '测试柱状图')]指令描述集向量化,记录id2des,id2kws
self.id2key:记录编号和id,用于后续查询
self.id2des: 记录id和des指令描述,用于向量化
self.id2kws: 记录id和kws关键词,用于计算用户query和关键词相似度
num0 = 0
for record in self.INSTTS:_id = record[0]_des = record[1]_kws = record[2]d_embeddings = self.model.encode([self.instruction + _des], normalize_embeddings=True)self.index.add(d_embeddings)self.i2key[num0] = _idself.id2des[_id] = _desself.id2kws[_id] = _kwsnum0 += 14.属性查询实现细节
这一部分主要针对指令,对应参数为tip_word:参数不全提示词,attribute_ids:属性值的处理,其中attribute_ids的参数示例如下
attribute_ids: "[{"paramName":"项目名称","paramCode":"prejectname","paramPrompt":"请提取出项目名称","paramWeight":"0.4"}]",参数代表意思解析
attribute_ids: "[{ "paramName":"项目名称", "paramCode":"prejectname", "paramPrompt":"请提取出项目名称", # 需要提取的内容 "paramWeight":"0.4"}]" # 参数权重参数的存储,记录TIPSINFOS,cvalue,PARAMINFOS
self.TIPSINFOS:记录id和tip_word,后续用于根据id提取对应参数
cvalue: 记录paramName, paramCode, paramPrompt, paramWeight
self.PARAMINFOS:记录id和cvalue
jsonobj = json.loads(response.text)
params = jsonobj["data"]
for param in params:print(param)cid = param["id"]if "tip_word" in param:tip_word = param["tip_word"]self.TIPSINFOS[cid] = tip_wordcvalue = []if "attribute_ids" in param and len(param["attribute_ids"])>0:attrs = json.loads(param["attribute_ids"])for attr in attrs:paramName = attr["paramName"]paramCode = attr["paramCode"]paramPrompt = attr["paramPrompt"]paramWeight = attr["paramWeight"]if len(paramName)>0 and len(paramCode)>0 and len(paramPrompt)>0 and len(paramWeight)>0 :cvalue.append((paramName, paramCode, paramPrompt, paramWeight))print(cid, paramName, paramCode, paramPrompt, paramWeight)self.PARAMINFOS[cid] = cvalue2.用户指令与指令描述集处理
1.计算用户指令与指令描述集相似度,选取topk
-
整体代码
question:用户指令问题
k:topk选取
theata:相似度阈值
def find_vec2(self, question, k, theata):print(question)q_embeddings = self.model.encode([self.instruction + question], normalize_embeddings=True)# print(q_embeddings)D, I = self.index.search(q_embeddings, k) # v为待检索向量,返回的I为每个待检索query最相似TopK的索引list,D为其对应的距离result = []for i in range(k):sort_k = i + 1sim_i = I[0][i]uuid = self.i2key.get(sim_i, "none")sim_v = D[0][i]midkws = self.id2kws.get(uuid, "none")score = self.calculate_score(sim_v, question, midkws) # 计算得分if score < theata:doc = {}doc["score"] = scoredoc["action_id"] = uuidresult.append(doc)return resultuuid = self.i2key.get(sim_i, "none"): 根据编号查询id
midkws = self.id2kws.get(uuid, "none"): 根据id查询kws关键词
-
进一步计算相似度
score = self.calculate_score(sim_v, question, midkws) :根据sim_v向量得分,question用户指令问题,midkws,kws关键词进一步计算匹配度得分
def calculate_score(self, score, question, kws):if kws == "none" or kws == "":return int(score * 1000)else:ckws = kws.split(",")chit = 0for kw in ckws:if question.find(kw) > -1: # 检测问题中是否包含关键词chit += 1# print(score, chit, question, kws)return int(score * 1000) - 100 * chit2.加载指令候选参数
如果命中指令,提取指令候选参数
self.TIPSINFOS: 参数不全提示词
self.PARAMINFOS:参数属性信息
optstr = self.TIPSINFOS.get(action_id, "指令参数不全。") # 通过action_id获取参数不全提示词
cur_parms = self.PARAMINFOS.get(action_id, []) # 通过action_id获取属性信息3.依据大模型判断是否参数不全
没有参数不全提取任务
如果cur_parms的长度为0,证明没有判断参数不全的任务,直接返回结果
self.SUCCESS_SIGN:参数提前标志,默认为1,代表成功(没有参数提取任务也设置为1)
self.EMPTY_PARMS: 缺失参数字符,默认为空字符串
self.MISS_VALUE:缺失字符,默认为空字符串
if len(cur_parms) == 0:return self.SUCCESS_SIGN, self.EMPTY_PARMS, self.MISS_VALUE有参数不全提取任务
-
datestr = time.strftime("%Y%m%d", time.localtime()) parmnames = [] for cp in cur_parms:parmnames.append(cp[0]) parmnames_str = "、".join(parmnames) newquestion1 = "问题:'" + "我想查看" + question + "'\n" + \"假设今天是" + datestr + ",请根据以上问题,提取"+parmnames_str+",要求:\n" for n1 in range(len(cur_parms)):record = str(n1+1) + "、" + cur_parms[n1][2] + ";\n"newquestion1 = newquestion1 + recordnewquestion1 = newquestion1 + "请以JSON格式输出,要求:\n" for n1 in range(len(cur_parms)):record = str(n1+1) + "、" + cur_parms[n1][0] + "用" + cur_parms[n1][1] + "表示;\n"newquestion1 = newquestion1 + recordprint(newquestion1)rststr = self.excute_prompt(str(newquestion1)) # 访问星火大模型封装提示词给大模型
示例 newquestion1值
这个示例中,问题为我想查看打开百度,经过属性信息将要提取的参数封装到prompt提示词中
"问题:'我想查看打开百度' 假设今天是20250417,请根据以上问题,提取项目名称,要求: 1、请提取出项目名称; 请以JSON格式输出,要求: 1、项目名称用projectname表示; "
访问大模型之后的rststr值
'```json
{
"projectname": "查看打开百度"
}
```'
参数不全处理逻辑
默认设置参数缺失
这里cur_parms=[('项目名称', 'projectname', '请提取出项目名称', '0.4')],
默认设置miss_value中每一个参数都是缺失的
keywords_value = []
for cp in cur_parms:keywords_value.append(cp[1])
miss_value = {key: '1' for key in keywords_value}4.参数不全处理
这里使用的星火大模型,模型返回的结果中,如果参数不全,会出现"由于问题中"的提示字符,这里通过它进行判断,如果要提取的参数key在大模型返回的结果中,则设置miss_value[key] = '0',表示该参数key不缺失,例如miss_value={'projectname': '0'}代表projectname不缺失。
if "由于问题中" in rststr:# rst = {key: '' for key in keywords_value}rststr = self.excute_prompt(str(newquestion1))if "由于问题中" in rststr:rststr = self.excute_prompt(str(newquestion1))if "由于问题中" in rststr:return self.PARAMTER_PARTIAL, optstr, miss_valueelse:for key in keywords_value:if key in rststr:miss_value[key] = '0'else:for key in keywords_value:if key in rststr:miss_value[key] = '0'
else:for key in keywords_value:if key in rststr:miss_value[key] = '0'
# 打印结果
print(miss_value)5.解析大模型返回的参数
sindex = rststr.find("{")
eindex = rststr.find("}")
print(sindex, eindex)
if sindex == -1 and eindex == -1:return self.PARAMTER_PARTIAL, optstr, miss_valuerststrjson = rststr[sindex:eindex + 1]
print(rststrjson)
rststrjson = rststrjson.replace("'", "\"")
print(rststrjson)rst = {}
rstjson = json.loads(rststrjson)
n = len(cur_parms)
# rst = json.dumps(rst)6.计算相似度
-
根据大模型返回参数和配置的参数计算相似度
for n1 in range(len(cur_parms)):midcode = cur_parms[n1][1]midtheta = 0.4try:midtheta = float(cur_parms[n1][3])except:passprint(midcode, midtheta)if midcode in rstjson:midvalue = rstjson[midcode]if midtheta > 0.0:msim, mval = self.search.match_parameter(action_id, midcode, midvalue, theata=midtheta)if msim > 0:rst[midcode] = mvalelse: # 查询的项目名称与参数完全不同print("msim is 0.0.")rst[midcode] = ''miss_value[midcode] = '1'n-=1continue# return self.FAILED_SIGN, json.dumps(rst), miss_valueelse:print("midtheta is 0.0.")rst[midcode] = midvalueelse:print(midcode, " not in ", rstjson)rst["optstr"] = optstrreturn self.FAILED_SIGN, json.dumps(rst), miss_value print(rst) if n != len(cur_parms):rst["optstr"] = optstrreturn self.FAILED_SIGN, json.dumps(rst), miss_value return self.SUCCESS_SIGN, json.dumps(rst), miss_value -
参数相似度计算,找到最相似的参数
def match_parameter(self, action_id, uni_key, parm, theata=0.4):midkey = str(action_id) + "_" + uni_key# 存储参数parm中的元素cwds = {}for i in range(len(parm)):cwds[parm[i]] = ""rstsim = 0.0 # 初始化相似度结果为0.0rstsss = "" # 初始化最匹配的候选值为空字符串"""# 遍历 self.PARAMS 字典中以 midkey 为键的所有候选值及其拆分后的字典表示# sss 表示候选值,wds 表示候选值拆分后的字典"""for sss, wds in self.PARAMS[midkey].items():# print(sss, wds)csim = self.sim_parameter(cwds, wds) # 计算输入的cwds 与 库里的 wds相似度# 如果相似度csim大于预先设定的theata阈值,并且相似度csim大于之前设定的最大相似度rstsimif csim >= theata and csim > rstsim:# 更新最大相似度为当前相似度rstsim = csim# 更新最匹配的候选值为当前候选值rstsss = sss# 打印匹配结果,包括输入参数、相似度(保留三位小数)、最匹配的候选值和阈值print("match_parameter --- ", parm, round(rstsim, 3), rstsss, theata)# 返回最大相似度和最匹配的候选值return rstsim, rstsss -
计算交并比
def sim_parameter(self, parm1, parm2):union_ws = {}join_ws = {}for w1 in parm1.keys():union_ws[w1] = ""if w1 in parm2:join_ws[w1] = ""for w2 in parm2.keys():union_ws[w2] = ""return 1.0 * len(join_ws.keys()) / len(union_ws.keys())