4.虚拟地址空间布局
4.1虚拟地址空间划分
对于64位处理器,目前不支持完全的64位虚拟地址

1.ARM64内核/用户虚拟地址划分
1. 虚拟地址的最大宽度
- 最大宽度:虚拟地址的最大宽度是48位。
内核虚拟地址:
- 在64位地址空间的顶部。
- 高16位全是1。
- 范围是 [0xFFFF FFFF FFFF FFFF, 0xFFFF FFFF FFFF FFFF]。
用户虚拟地址:
- 在64位地址空间的底部。
- 高16位全是0。
- 范围是 [0x0000 0000 0000 0000, 0x0000 FFFF FFFF FFFF]。
不规范地址空间:
- 高16位全是1或者全是0的地址称为规范的地址。
- 两者之间是不规范的地址,不允许使用。
2. 编译ARM64架构的Linux内核时的选择
页长度选择:
- 如果选择页长度为4KB,默认的虚拟地址宽度是39位。
- 如果选择页长度为16KB,默认的虚拟地址宽度是47位。
- 如果选择页长度为64KB,默认的虚拟地址宽度是42位。
- 可以选择48位虚拟地址。
3. 内核和用户虚拟地址空间
内核虚拟地址:
- 所有进程共享内核虚拟地址空间。
用户虚拟地址:
- 每个进程有独立的用户虚拟地址空间。
- 同一个线程组的用户线程共享用户虚拟地址空间。
- 内核线程没有用户虚拟地址空间。
4.2 用户虚拟地址空间布局
1.进程的用户虚拟地址空间
起始地址: 0
长度: TASK_SIZE
定义: TASK_SIZE 是由每种处理器架构定义的宏。
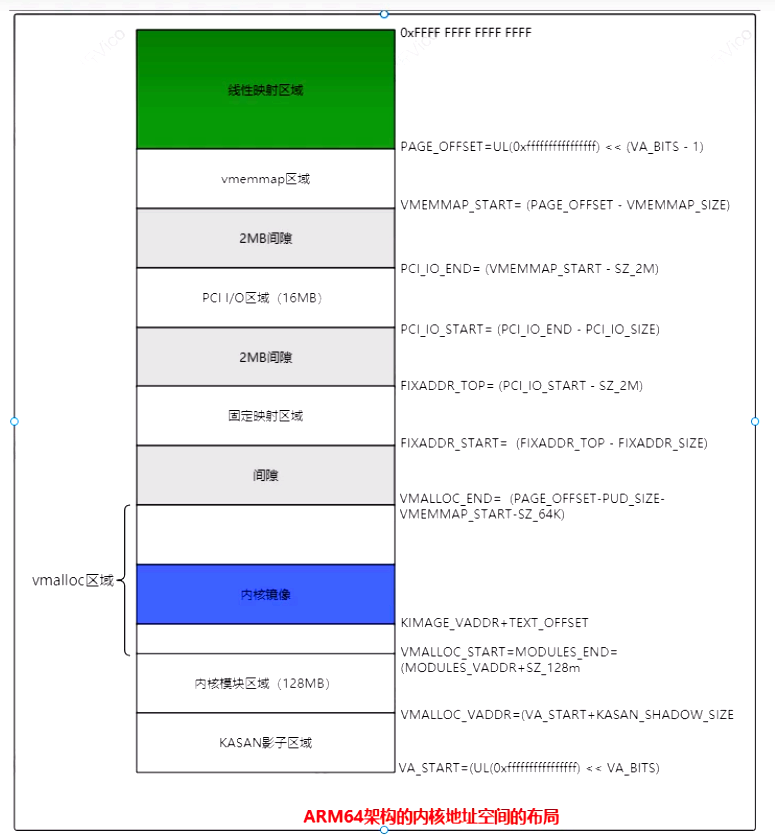
#define VA_BITS (CONFIG_ARM64_VA_BITS)
#define VA_START ((UL(0xffffffffffffff) << VA_BITS)
#define PAGE_OFFSET ((UL(0xffffffffffffff) << (VA_BITS - 1))
#define KIMAGE_VADDR (MODULES_END)
#define MODULES_END (MODULES_VADDR + MODULES_VSIZE)
#define MODULES_VADDR (VA_START + KASAN_SHADOW_SIZE)
#define MODULES_VSIZE (SZ_128M)
#define VMEMMAP_START (PAGE_OFFSET - VMEMMAP_SIZE)
#define PCI_IO_END (VMEMMAP_START - SZ_2M)
#define PCI_IO_START (PCI_IO_END - PCI_IO_SIZE)
#define FIXADDR_TOP (PCI_IO_START - SZ_2M)
#define TASK_SIZE_64 ((UL(1) << VA_BITS)#ifdef CONFIG_COMPAT
#define TASK_SIZE_32 UL(0x100000000)
#define TASK_SIZE (test_thread_flag(TIF_32BIT) ? \
TASK_SIZE_32 : TASK_SIZE_64)
#define TASK_SIZE_OF(tsk) (test_tsk_thread_flag(tsk, TIF_32BIT) ? \
TASK_SIZE_32 : TASK_SIZE_64)
#else
#define TASK_SIZE TASK_SIZE_64
#endif /* CONFIG_COMPAT */不同架构下的 TASK_SIZE 定义如下:
32位用户空间程序:
- TASK_SIZE 的值: TASK_SIZE_32
- 具体值: 0x100000000
- 等价于: 4GB
64位用户空间程序:
- TASK_SIZE 的值: TASK_SIZE_64
- 具体值: 2^VA_BITS 次方字节
- VA_BITS: 编译内核时选择的虚拟地址位数
- 如果 VA_BITS 为 48,则 TASK_SIZE_64 为 2^{48}字节,即 256TB
2.进程的用户虚拟地址空间包含如下区域:
代码段、数据段和未初始化数据段:
- 代码段:存放程序的执行代码,通常是只读的。
- 数据段:存放已初始化的全局变量和静态变量。
- 未初始化数据段:存放未初始化的全局变量和静态变量。
动态库的代码段、数据段和未初始化数据段:
- 代码段:存放动态链接库中的执行代码。
- 数据段:存放动态链接库中已初始化的全局变量和静态变量。
- 未初始化数据段:存放动态链接库中未初始化的全局变量和静态变量。
存放动态生成的数据的堆:
- 堆用于动态内存分配,例如通过 malloc 或 new 操作符分配的内存位于此区域。堆从低地址向高地址增长。
存放局部变量和实现函数调用的栈:
- 栈用于存储函数的局部变量和控制信息(如函数调用的返回地址)。栈从高地址向低地址增长。
存放在栈底部的环境变量和参数字符串:
- 环境变量和参数字符串通常在进程启动时被加载到栈底部,用于传递命令行参数和其他环境信息。
把文件区间映射到虚拟地址空间的内存映射区域:
- 内存映射区域允许文件或设备直接映射到进程的地址空间,从而可以直接像访问内存一样访问文件内容。这通常用于高效地处理大文件或共享内存。
3.内核用户态内存结构补充:
任务空间管理-用户态内存结构-CSDN博客
4.进程描述符(task_struct)中的内存相关成员:
struct task_struct {struct mm_struct *mm; // 指向进程的 mm_structstruct mm_struct *active_mm;// 指向当前活跃的 mm_struct...
};内核线程的特殊情况
内核线程:
- 内核线程是内核的一部分,主要用于执行内核内部的任务,如定时器处理、中断处理等。
- 它们不需要自己的用户虚拟地址空间,因此 mm 通常是空指针。
- 当内核线程需要访问用户空间数据时,它会借用其他进程的 mm_struct,此时 active_mm 指向被借用的 mm_struct。
1. struct mm_struct *mm
- 类型: struct mm_struct *
- 用途: 指向一个 mm_struct 结构体,该结构体描述了进程的虚拟地址空间。
说明:
- 对于用户进程,mm 指向当前进程的 mm_struct,包含了所有与虚拟地址空间相关的信息,如页表、内存区域等。
- 对于内核线程(例如调度器线程),由于它们没有自己的用户虚拟地址空间,因此 mm 是空指针。
2. struct mm_struct *active_mm
- 类型: struct mm_struct *
- 用途: 指向当前进程正在使用的 mm_struct。
说明:
- 对于用户进程,active_mm 总是指向同一个 mm_struct,即进程的虚拟地址空间描述符。
- 对于内核线程,在没有运行时,active_mm 是空指针。
- 当内核线程运行时,active_mm 指向从上一个进程借用的 mm_struct。这意味着内核线程可以暂时使用其他进程的虚拟地址空间来执行某些操作。
在 Linux 内核中,mm_users 和 mm_count 是与进程的内存描述符 (mm_struct) 相关的两个重要引用计数字段。它们的作用是跟踪和管理 mm_struct 的生命周期,以确保内存资源的正确分配和释放。
当两个进程属于同一个线程组时,或者当进程不属于线程组时,这两个计数的关系会有所不同
(1)进程不属于线程组的情况
如果进程不属于线程组,则每个进程都有自己独立的 mm_struct,并且 mm_users 和 mm_count 的关系如下:
mm_users:
- 对于单个进程,mm_users 的值通常为 1,因为只有一个进程在使用这个 mm_struct。
mm_count:
- mm_count 至少等于 mm_users。
- 如果有其他内核组件(如内核线程)临时借用该 mm_struct,则 mm_count 会大于 mm_users。
(2) 两个进程属于同一个线程组的情况
在 Linux 中,线程组是指一组共享相同虚拟地址空间的线程。这些线程由一个主线程创建,并且它们共享同一个 mm_struct。在这种情况下,mm_users 和 mm_count 的关系如下:
mm_users:
- 每当一个新的线程加入线程组时,mm_users 会增加。
- 例如,如果线程组中有 3 个线程,则 mm_users 的值为 3。
mm_count:
- mm_count 至少等于 mm_users。
- 如果有内核线程或其他组件临时借用该 mm_struct,则 mm_count 会大于 mm_users。
(3) 示例场景分析
场景 1: 单个进程
假设有一个独立的用户进程 A。
- mm_users: 1(只有进程 A 使用自己的 mm_struct)。
- mm_count: 1(没有其他组件借用 mm_struct)。
场景 2: 线程组中的多个线程
假设有一个线程组,包含 3 个线程(T1、T2、T3),它们共享同一个 mm_struct。
- mm_users: 3(每个线程都使用该 mm_struct)。
- mm_count: 3(如果没有其他组件借用 mm_struct)。
场景 3: 内核线程借用 mm_struct
假设有一个内核线程 K,它临时借用了一个用户进程的 mm_struct。
- mm_users: 1(只有用户进程使用该 mm_struct)。
- mm_count: 2(内核线程 K 借用了该 mm_struct,导致引用计数增加)。
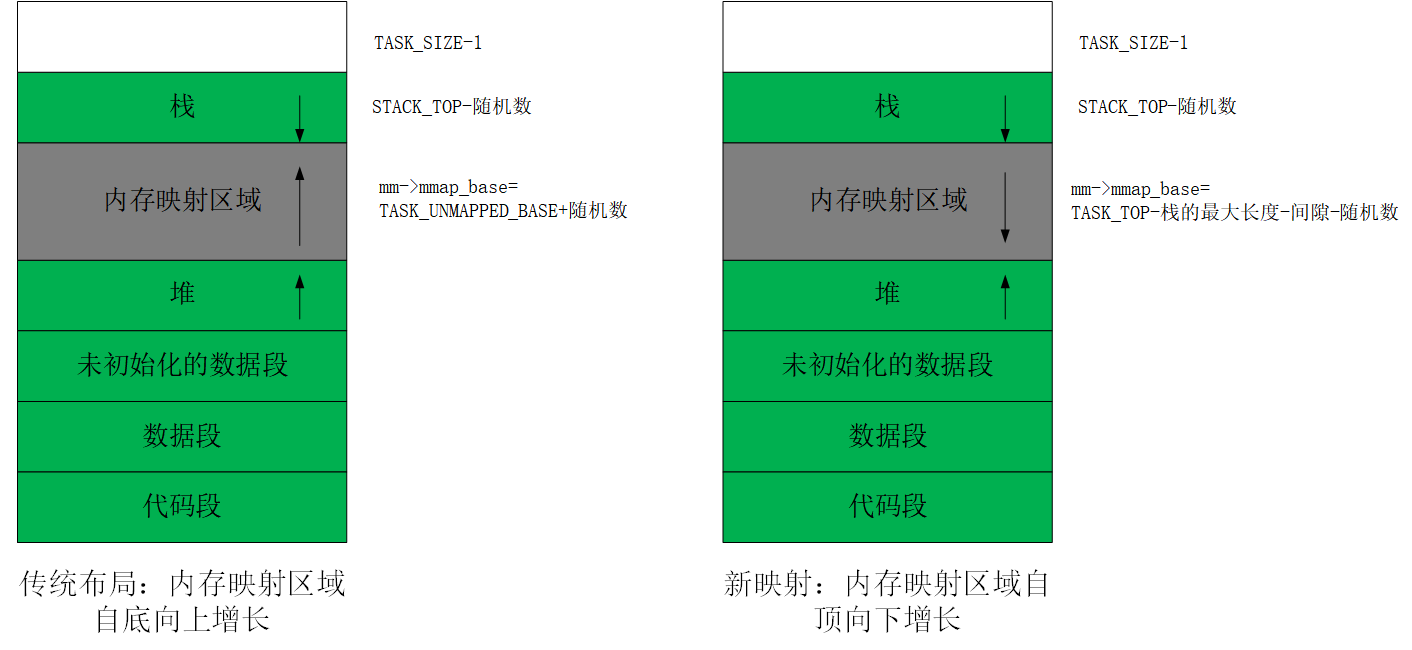
传统布局与新布局的比较
传统布局:
- 内存映射区域自底向上增长。
- 堆的最大长度受到限制,尤其是在32位系统中影响较大。
- 优点:简单直观。
- 缺点:在32位系统中,堆的最大长度受限。
新布局:
- 内存映射区域自顶向下增长。
- 堆的最大长度不受限制。
- 优点:在64位系统中,可以充分利用大内存空间。
- 缺点:实现复杂度较高。
各种处理器自定义的函数 :void arch_pick_mmap_layout(struct mm_struct *mm)负责选择内存区域布局。
/** This function, called very early during the creation of a new process VM* image, sets up which VM layout function to use:*/
void arch_pick_mmap_layout(struct mm_struct *mm)
{unsigned long random_factor = 0UL;if (current->flags & PF_RANDOMIZE)random_factor = arch_mmap_rnd();/** 如果给进程描述符的成员personality设置标志位ADDR_COMPAT_LAYOUT表示使用传统的* 虚拟地址空间布局,或者用户栈可以无限增长,或者通过文件/proc/sys/vm/legacy_va_layout指定*/if (mmap_is_legacy()) {mm->mmap_base = TASK_UNMAPPED_BASE + random_factor;mm->get_unmapped_area = arch_get_unmapped_area;} else {mm->mmap_base = mmap_base(random_factor);mm->get_unmapped_area = arch_get_unmapped_area_topdown;}
}4.3 内核地址空间布局
ARM64 架构的内核地址空间布局
补充:任务空间管理 - 内核态结构-CSDN博客