概述
使用 Terraform 时,您可能需要为同一资源创建多个实例。这时 count 和 for_each 循环就派上用场了。这些循环允许您创建具有相同配置但具有不同值的多个资源。本指南将讲解如何在 Terraform 中使用 count 和 for_each 循环。
Terraform 中的 Count
Terraform 中的 count 参数允许您创建指定数量的相同资源。它是资源块的组成部分,用于定义应创建特定资源的实例数量。
以下是 Terraform 中使用 count 的示例:
resource "azurerm_resource_group" "example" {count = 3name = "resourceGroup-${count.index}"location = "East US"tags = {iteration = "Resource Group number ${count.index}"}
}在上面的示例中,我们使用 count 参数在 Azure 区域“美国东部”中创建了三个名称不同但相同的资源组。
优点:
易于使用:count 参数可直接创建资源的多个实例。
适用于同质资源:当您创建的所有资源除了标识符之外都相同时,count 可能是一个不错的选择。
缺点:
缺乏基于键的标识:count 不提供直接使用唯一键来寻址资源的方法;您必须依赖索引。
不可变:如果您从 count 列表中间删除一个项目,Terraform 会将所有后续资源标记为重新创建,这在某些情况下可能会造成中断。例如:假设您有一个 Terraform 配置,它使用 count 参数管理 Azure 中的一组虚拟机。假设您最初将 count 参数设置为 5,从而预配了 5 个虚拟机:
resource "azurerm_virtual_machine" "vm" {count = 5name = "vm-${count.index}"location = "East US"resource_group_name = azurerm_resource_group.rg.namenetwork_interface_ids = [azurerm_network_interface.nic[count.index].id]# ... (other configuration details)
}在上面的例子中,假设过了一段时间,您决定不再需要第二个虚拟机(“vm-1”,因为“count.index”从零开始)。要删除此虚拟机,您可以将计数更改为 4,并调整资源名称或索引,这在直观上似乎是正确的方法。
问题就在这里:Terraform 根据资源的索引来决定资源的创建和销毁。如果您只是删除或注释掉“vm-1”的定义,Terraform 将无法识别您确实想要销毁“vm-1”。它会认为从索引 1 开始的所有虚拟机(vm-1、vm-2、vm-3 和 vm-4)都应该被销毁并重新创建,因为它们的索引已更改。
这可能会造成一些破坏性后果:
停机:重新创建虚拟机会导致在其上运行的服务停机,这在生产环境中可能是不可接受的。
数据丢失:如果您未备份虚拟机上的本地数据,则在销毁并重建虚拟机时,这些数据将会丢失。
IP 地址变更:如果虚拟机分配了动态公网 IP,这些 IP 地址可能会发生变化,并可能导致连接问题。
成本:销毁并重建资源可能会产生不必要的成本,例如计算时间的消耗。
为了避免此类count问题,您需要使用 create_before_destroy 生命周期规则,或者考虑 for_each 是否是此类场景的更好选择,因为它提供了一种无需依赖序列即可唯一标识资源的方法。使用 for_each,每个虚拟机将单独管理,您可以移除与不需要的虚拟机对应的单个映射条目,从而只销毁该特定虚拟机,而不会影响其他虚拟机。
Terraform for_each 是什么?
Terraform for_each 是一个元参数,用于创建已定义资源的多个实例。它还使我们能够灵活地根据用于创建实际副本的变量类型,动态设置每个已创建资源实例的属性。
for_each 主要使用字符串集合 (set(string)) 和字符串映射 (map(string))。提供的字符串值用于设置特定于实例的属性。
例如,在创建多个子网时,我们可以为使用同一资源块创建的每个子网指定不同的 CIDR 范围。
当在资源块中使用 for_each 元参数时,会自动提供一个特殊对象 each 来引用由 for_each 创建的每个实例。each 对象用于引用集合中提供的值以及映射类型变量中提供的键值对。
如何在 Terraform 中使用 for each
使用 for_each 元参数的一般语法如下所示。
resource "<resource type>" "<resource name>" {for_each = var.instances// Other attributestags = {Name = each.<value/key>}
}<resource type> 是 Terraform 资源的类型,例如“aws_vpc”。
<resource name> 是此资源的用户定义名称,用于在 Terraform 配置中的其他位置引用。for_each 属性被赋值为“var.instances”形式的变量值。“var.instances”可以是列表或映射类型。
根据此集合或映射的长度,将创建“<resource type>”类型的资源数量。
最后,each 对象用于为由此创建的每个资源实例分配一个名称标签。如果“var.instances”是集合类型,则“each.value”是唯一可用的属性。如果是映射类型,则可以使用 each.key 和 each.value 同时检索键和值。
在一些高级用例中,也可以将对象映射 (map(object)) 与 for_each 元参数一起使用。我们将在本文的后面部分介绍。
示例 1:使用 for_each 函数处理一组字符串
假设我们需要在 AWS 中创建特定数量的 EC2 实例。
需要创建的实例的具体数量取决于提供的输入。如果输入是“字符串数组”(就 Terraform 而言,即 set(string) ),则 Terraform 的配置如下所示。
variable "instance_set" {type = set(string)default = ["Instance A", "Instance B"]
}resource "aws_instance" "by_set" {for_each = var.instance_setami = "ami-0b08bfc6ff7069aff"instance_type = "t2.micro"tags = {Name = each.value}
}这里,我们声明了一个 set(string) 类型的输入变量。该变量的默认值是几个字符串。该集合的长度为 2,我们期望“aws_instance”资源块能够创建两个 EC2 实例。
aws_instance 资源块的第一个属性是 for_each,它被赋值为 set(string) 类型的“instance_set”变量值。ami 和 instance_type 属性是硬编码的,因为它们与本博文的主题无关。
此外,Name 标签使用 each 对象来引用 instance_set 变量中包含的每个字符串的值。
执行此 Terraform 配置时,它会创建两个名为“实例 A”和“实例 B”的 EC2 实例。
可以使用下面的 plan 命令输出进行验证。
+ tags = {+ "Name" = "Instance B"}+ tags_all = {+ "Name" = "Instance B"}+ tenancy = (known after apply)+ user_data = (known after apply)+ user_data_base64 = (known after apply)+ user_data_replace_on_change = false+ vpc_security_group_ids = (known after apply)Plan: 2 to add, 0 to change, 0 to destroy.───────────────────────────────────────────────────────────────────────────────────Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run "terraform apply" now.Terraform for_each 函数用于字符串列表
如果使用 list(string) 而不是 set 函数,请使用 Terraform 的内置函数 toset() 进行类型转换。
使用 list(string) 的配置更改很简单,如下所示。
variable "instance_set" {type = list(string)default = ["Instance A", "Instance B"]
}
resource "aws_instance" "by_set" {for_each = toset(var.instance_set)ami = "ami-0b08bfc6ff7069aff"instance_type = "t2.micro"tags = {Name = each.value}
}
示例 2:将 for_each 与 map 结合使用
map 类型提供了一组键值对,为配置更复杂的循环资源提供了更多自定义选项。
在本例中,要创建的实例数量等于 map 对象的长度。但是,除了 each.value 之外,我们还可以利用 each.key 中存储的字符串值。下一步,我们将使用同一个 Terraform 资源块动态设置两个属性,而不是一个。
variable "environments" {type = map(string)default = {prod0415 = "eastus2"dev0415 = "westus"test0415 = "centralus"}
}resource "azurerm_storage_account" "example" {for_each = var.environmentsname = "storage${each.key}"resource_group_name = azurerm_resource_group.example[each.key].namelocation = each.valueaccount_tier = "Standard"account_replication_type = "LRS"
}
上面的environments变量的默认值为三个键值对。
我们在for_each元参数中使用此变量来创建三个资源组,如下面的配置块所示
resource "azurerm_resource_group" "example" {for_each = var.environmentsname = "${each.key}-resource-group"location = each.valuetags = {Name = each.key}
}上述代码片段中的 for_each 元参数负责创建三个资源组。
此外,location 指的是在 environments 变量的默认值中设置的值,Name 标签指的是在 environments 变量的默认值中设置的键字符串。
在第二个示例中,我们使用一组字符串创建了具有特定名称的资源组:“prod0415-resource-group”、“dev0415-resource-group”和“test0415-resource-group”。我们使用映射创建了位于不同位置并与相应资源组关联的存储帐户。

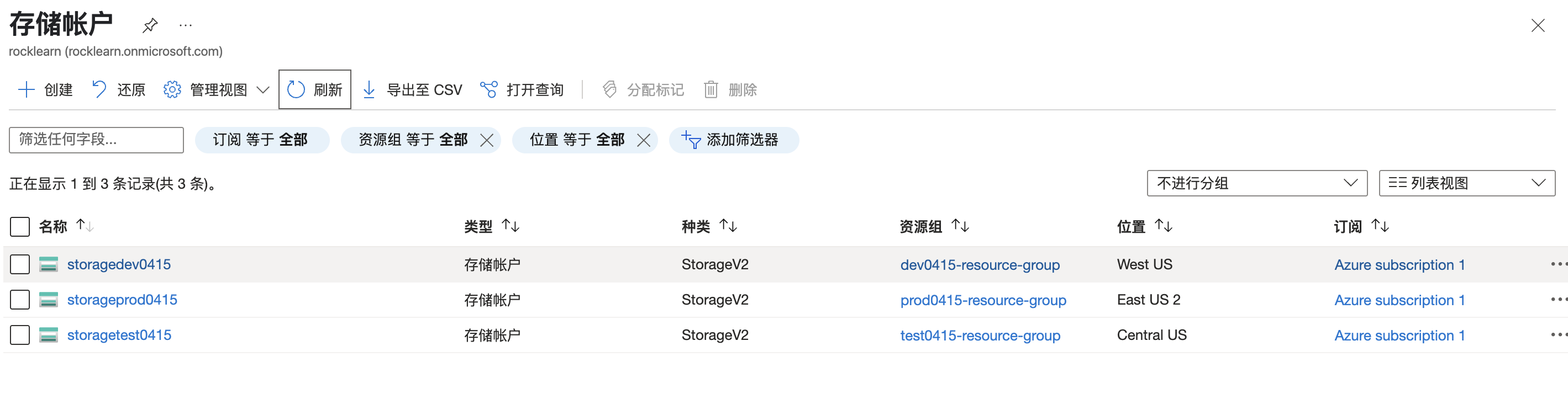
示例 3:将 for_each 与模块结合使用
Terraform 模块明确公开了一些在使用时需要提供的输入变量。模块帮助我们打包 IaC,以配置一组预定义的基础设施。有时,我们需要多次配置模块中包含的资源。这时,for_each 元参数也与模块结合使用。
在下面的示例中,我们使用 Terraform 注册表中的一个模块在 AWS 中创建安全组。
该模块负责创建安全组和入口规则,这是 Terraform 安全组的基本要求。如果我们需要创建多个具有不同入口 CIDR 块和不同名称的安全组来标识它们,那么我们可以遵循以下方法。
- 定义一个 map(string) 类型的变量,其中键值对中的键表示安全组的名称,值表示字符串格式的 CIDR。
- 包含模块资源块并初始化它。
- 使用 for_each 创建多个安全组,并使用每个对象将 name 和 ingress_cidr_blocks 输入替换为适当的值。请参阅下面的 Terraform 代码。
variable "sg_map" {type = map(string)default = {"SG 1" = "10.10.1.0/24","SG 2" = "10.10.2.0/24"}
}
module "web_server_sg" {for_each = var.sg_mapsource = "terraform-aws-modules/security-group/aws//modules/http-80"name = each.keyvpc_id = aws_vpc.example_vpc.idingress_cidr_blocks = [each.value]
}运行terraform plan后看到
+ resource "aws_security_group" "this_name_prefix" {+ arn = (known after apply)+ description = "Security Group managed by Terraform"+ egress = (known after apply)+ id = (known after apply)+ ingress = (known after apply)+ name = (known after apply)+ name_prefix = "SG 1-"+ owner_id = (known after apply)+ revoke_rules_on_delete = false+ tags = {+ "Name" = "SG 1"}+ tags_all = {+ "Name" = "SG 1"}+ vpc_id = (known after apply)+ timeouts {+ create = "10m"+ delete = "15m"}}
.
.
.
# module.web_server_sg["SG 1"].module.sg.aws_security_group_rule.ingress_rules[0] will be created+ resource "aws_security_group_rule" "ingress_rules" {+ cidr_blocks = [+ "10.10.1.0/24",]+ description = "HTTP"+ from_port = 80+ id = (known after apply)+ ipv6_cidr_blocks = []+ prefix_list_ids = []+ protocol = "tcp"+ security_group_id = (known after apply)+ self = false+ source_security_group_id = (known after apply)+ to_port = 80+ type = "ingress"}
.
.
.
# module.web_server_sg["SG 2"].module.sg.aws_security_group.this_name_prefix[0] will be created+ resource "aws_security_group" "this_name_prefix" {+ arn = (known after apply)+ description = "Security Group managed by Terraform"+ egress = (known after apply)+ id = (known after apply)+ ingress = (known after apply)+ name = (known after apply)+ name_prefix = "SG 2-"+ owner_id = (known after apply)+ revoke_rules_on_delete = false+ tags = {+ "Name" = "SG 2"}+ tags_all = {+ "Name" = "SG 2"}+ vpc_id = (known after apply)+ timeouts {+ create = "10m"+ delete = "15m"}}
.
.
.
# module.web_server_sg["SG 2"].module.sg.aws_security_group_rule.ingress_rules[0] will be created+ resource "aws_security_group_rule" "ingress_rules" {+ cidr_blocks = [+ "10.10.2.0/24",]+ description = "HTTP"+ from_port = 80+ id = (known after apply)+ ipv6_cidr_blocks = []+ prefix_list_ids = []+ protocol = "tcp"+ security_group_id = (known after apply)+ self = false+ source_security_group_id = (known after apply)+ to_port = 80+ type = "ingress"}
.
.
.
Plan: 9 to add, 0 to change, 0 to destroy.示例 4:将 for_each 与对象列表结合使用
作为一名 Terraform 开发者,如果打算使用 for_each 创建多个资源实例,那么使用字符串映射 (map(string)) 可能会显得力不从心。尤其是在每个对象需要返回两个以上的值(键和值)且需要调整两个以上属性的情况下。
在这种情况下,可以使用 map(object),其中每个对象可能具有多个属性。但是,为了便于本示例说明,我们将使用 list(object)。
当第三方应用程序的输入不受我们控制时,了解如何使用 for_each 与 list(object) 结合使用非常重要。
请注意,使用 map(object) 比使用 list(object) 更好,因为 map(object) 是使用 for_each 元参数更简洁的方式,因为它更容易检索键和值字符串。
for_each 元参数接受集合或 map(string) 类型。因此,为了使其与 list(object) 配合使用,需要将其与返回字符串值的 for 循环一起使用。for 循环与 for_each 一起使用,返回对象的特定属性,该属性的计算结果为字符串值。
以下代码声明了一个 (list(object)) 类型的变量来创建两个 EC2 实例。
variable "instance_object" {type = list(object({name = stringenabled = boolinstance_type = stringenv = string}))default = [{name = "instance A"enabled = trueinstance_type = "t2.micro"env = "dev"},{name = "instance B"enabled = falseinstance_type = "t2.micro"env = "prod"},]
}实例对象包含以下属性:
- name – 为 EC2 实例分配名称标签
- enabled – 一个布尔值,用于决定是否配置 EC2 实例。下一节将详细介绍。
- instance_type – AWS 实例类型
- env – 为 EC2 实例分配环境标签。
如上所示,根据默认值提供的多个属性,从此对象创建的 EC2 实例数量会有所不同。
以下代码使用 for_each 元参数创建了两个 EC2 实例,其默认值由上述对象的默认值提供。
resource "aws_instance" "by_object" {for_each = { for inst in var.instance_object : inst.name => inst }ami = "ami-0b08bfc6ff7069aff"instance_type = each.value.instance_typetags = {Name = each.keyEnv = each.value.env}
}这里,我们使用了由“instance_object”变量提供的“instance_type”、“name”和“env”属性,并通过“each.value.<property>”语法设置了 aws_instance 资源的相应属性。
请注意,用于设置 for_each 元参数的 Terraform for 循环会从“instance_object”输入变量中选择 name 属性。由于有两个对象被定义为默认值,因此将创建两个 EC2 实例。
这也会导致 Terraform 将“each”对象的“key”设置为 name 属性。此 each.key 用于设置 Name 标签。此外,使用“each.value.name”也可以达到相同的效果。
这从计划输出中显而易见,如下所示。
tags = {+ "Name" = "Instance B"}+ tags_all = {+ "Name" = "Instance B"}+ tenancy = (known after apply)+ user_data = (known after apply)+ user_data_base64 = (known after apply)+ user_data_replace_on_change = false+ vpc_security_group_ids = (known after apply)
Plan: 2 to add, 0 to change, 0 to destroy.───────────────────────────────────────────────────────────────────────────────────Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run "terraform apply" now.示例 5:将 for_each 与 Terraform 数据源结合使用
假设我们想要使用与 AWS 中特定类型的多个资源相关的信息,这些资源通过不同的路径(例如不同的 Terraform 代码库)进行配置和管理,在这种情况下,可以使用 for_each。
例如,假设在某个 AWS 区域中配置了多个 EC2 实例,并且我们想要在 Terraform 配置中使用与它们相关的信息。list(string) 类型的变量保存了 EC2 实例 ID 的列表。
variable "instance_ids" {description = "List of EC2 instance IDs"type = list(string)default = ["i-1abcd234", "i-2efgh345", "i-3ijkl456", "i-4mnop567", "i-5qrst678"]
}为了访问与这些 EC2 实例相关的信息,我们使用 aws_instance Terraform 数据源,如下所示。这里我们使用 for_each 元参数来读取上面列表中提到的每个实例的值。
data "aws_instance" "ec2_instances" {for_each = toset(var.instance_ids)instance_id = each.value
}稍后,我们可以使用此 Terraform 数据源基于这些 EC2 实例配置更多资源。
在下面的代码中,我们使用此数据源通过输出变量打印这些实例的多个属性。
output "instance_info" {value = {for instance_id, instance in data.aws_instance.ec2_instances :instance_id => {id = instance.idpublic_ip = instance.public_ipprivate_ip = instance.private_ipinstance_type = instance.instance_type# more attributes as needed}}
}
运行terraform plan
data.aws_instance.ec2_instances["i-02f5e4f2747588bed"]: Reading...
data.aws_instance.ec2_instances["i-061d243847333fec0"]: Reading...
data.aws_instance.ec2_instances["i-02f5e4f2747588bed"]: Read complete after 3s [id=i-02f5e4f2747588bed]
data.aws_instance.ec2_instances["i-061d243847333fec0"]: Read complete after 4s [id=i-061d243847333fec0]Changes to Outputs:+ instance_info = {+ i-02f5e4f2747588bed = {+ id = "i-02f5e4f2747588bed"+ instance_type = "t2.medium"+ private_ip = "172.31.6.120"+ public_ip = ""}+ i-061d243847333fec0 = {+ id = "i-061d243847333fec0"+ instance_type = "t2.micro"+ private_ip = "172.31.200.156"+ public_ip = "13.238.100.100"}
何时使用 Count 还是 For_each
这两种结构都很强大,但它们的适用场景不同。以下是快速参考,可帮助您确定使用哪种结构:
在以下情况下使用 Count:
您需要创建固定数量的相似资源。
资源差异可以用索引表示。
在以下情况下使用 For_each:
您正在处理具有唯一标识符的项目集合。
您的资源并非完全相同,需要单独配置。
您计划在未来进行修改,但这些修改不应影响所有资源。
结论
在 count 和 for_each 之间进行选择很大程度上取决于具体场景。count 参数非常适合简化操作,尤其适用于处理同质资源。而 for_each 则非常适合更受控制的资源声明,它提供灵活性和精确性,这在复杂的基础架构中尤为有益。