
🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、Hugging Face简介
2、Qwen2-Audio-7B-Instruct模型简介
二、下载模型
1、注册Hugging Face
2、下载模型
3、检查模型
三、应用编写
1、安装工具包
2、封装函数调用模型
3、封装切割函数
4、主函数调用
一、引言
1、Hugging Face简介
Hugging Face 是什么?(通俗易懂版)
Hugging Face 就像 AI 版的 GitHub,是一个提供 人工智能模型、工具 和 社区 的平台,主要用于 自然语言处理(NLP)、计算机视觉(CV) 和 语音处理 等领域。
简单来说,它可以帮你 快速使用 AI 模型,就像下载软件一样简单,不用自己从头训练,非常方便!🎉
Hugging Face 有哪些工具?
🔹 Transformers(模型库)
👉 提供各种 AI 模型,比如 GPT、BERT、T5,随时调用,支持 PyTorch、TensorFlow。
🔹 Datasets(数据集)
👉 直接加载海量 AI 训练数据,省去找数据的麻烦。
🔹 Tokenizers(分词工具)
👉 让 AI 更快理解文本,比如把 "我喜欢 Hugging Face" 切分成 ["我", "喜欢", "Hugging", "Face"]。
🔹 Hugging Face Hub(模型市场)
👉 你可以像逛应用商店一样,下载 AI 模型,还能上传自己的模型,全球共享。

2、Qwen2-Audio-7B-Instruct模型简介
Qwen2-Audio-7B-Instruct 是阿里巴巴通义千问团队开源的音频语言模型,属于 Qwen2-Audio 系列。该模型能够接受各种音频信号输入,并根据语音指令执行音频分析或直接生成文本响应。
与之前的模型相比,Qwen2-Audio-7B-Instruct 在以下方面进行了改进:
-
语音聊天模式:用户可以自由地与模型进行语音交互,无需输入文本。
-
音频分析模式:用户可以在交互过程中提供音频和文本指令,对音频进行分析。
-
多语言支持:该模型支持超过 8 种语言和方言,包括中文、英语、粤语、法语、意大利语、西班牙语、德语和日语。
Qwen2-Audio-7B-Instruct 的模型结构包含一个 Qwen 大语言模型和一个音频编码器。在预训练阶段,依次进行自动语音识别(ASR)、音频-文本对齐等多任务预训练,以实现音频与语言的对齐。随后,通过监督微调(SFT)强化模型处理下游任务的能力,再通过直接偏好优化(DPO)方法加强模型与人类偏好的对齐。

二、下载模型
1、注册Hugging Face
官网:Hugging Face – The AI community building the future.
注册官网账户并成功登录后,在右上角查看一下Token,等会下载的时候会用的到
2、下载模型
安装客户端工具
pip install huggingface-cli下载模型,在终端执行以下命令
huggingface-cli download --token **************** Qwen/Qwen2-Audio-7B-Instruct --local-dir E:\model_cache\QwenQwen2-Audio-7B-Instruct把我们刚刚申请的token加进去,不然下载的时候可能会报错
下载过程中可能会中断,重新执行上面的命令即可,huggingface-cli 工具默认会断点续传
3、检查模型
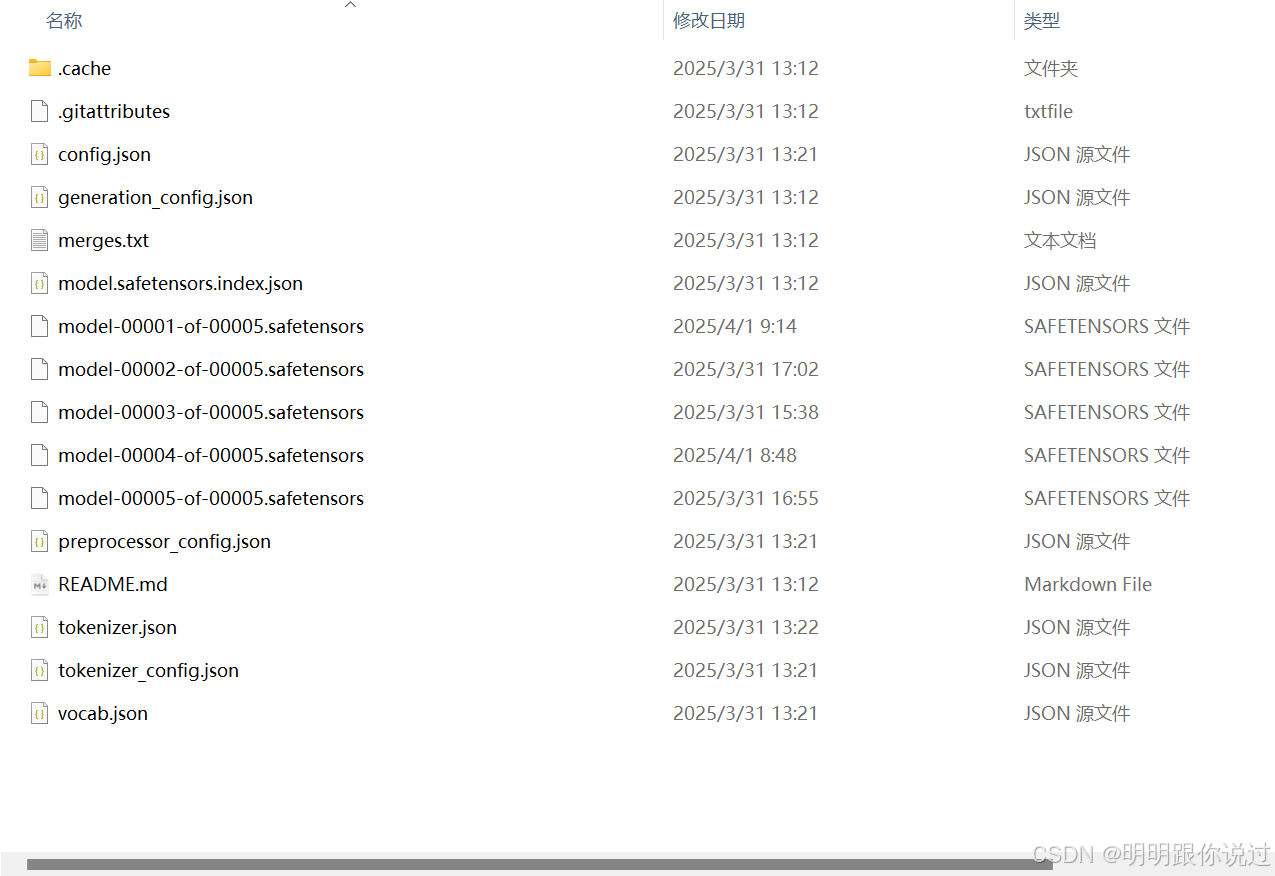
下载完成后,进入文件夹查看,如果和我下面的截图一样,并且整个文件夹大小为15.6GB,就没问题
三、应用编写
1、安装工具包
pip install requests torch librosa tenacity transformers pydub2、封装函数调用模型
def audio_to_text(audio_path) :# 检查 GPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载模型processor = AutoProcessor.from_pretrained("E:/model_cache/QwenQwen2-Audio-7B-Instruct")model = Qwen2AudioForConditionalGeneration.from_pretrained("E:/model_cache/QwenQwen2-Audio-7B-Instruct",device_map="auto")# 移动模型到 GPUmodel.to(device)# 处理音频audio_data, sr = librosa.load(audio_path, sr=16000) # 明确设置采样率# 规范化 conversationconversation = [{"role": "user", "content": "<|AUDIO|>"},{"role": "assistant", "content": "将这段语音输出为文本,直接输出文本内容即可,不要输出多余的话"},]# 生成文本输入text = processor.tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)# 生成输入inputs = processor(text=text, audios=[audio_data], return_tensors="pt", padding=True)inputs = {key: value.to(device) for key, value in inputs.items()} # 移动到 GPU# **使用 max_new_tokens 代替 max_length**response_ids = model.generate(**inputs, max_new_tokens=512)# 解析结果response = \processor.tokenizer.batch_decode(response_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]# print(response)print("--------------------------------------------")# 正则表达式查找第二个 'assistant' 后面的内容match = re.search(r'(?<=assistant)(.*)', response.split('assistant', 2)[-1], re.DOTALL)if match:# 输出第二个 'assistant' 后面的内容# print(match.group(1).strip())# 使用 replace 方法将 "assistant" 替换为空cleaned_text = match.group(1).strip().replace("这段音频的原始内容是:", "")cleaned_text = cleaned_text.replace("这段语音的原始文本内容是:", "")print(cleaned_text)return cleaned_textelse:print("未找到匹配的内容")return ""上面的代码
1.加载模型:
- 检查是否有 GPU,并加载 Qwen2-Audio-7B-Instruct 模型和 processor。
2.处理音频:
- 使用 librosa 读取音频,并转换为 16kHz 采样率。
- 通过 conversation 定义语音转文字的 prompt。
3.输入转换:
- processor 负责把音频 + 文本转换成模型可以理解的格式。
- 确保输入数据和模型都在 GPU 上运行。
4.推理 & 解析:
- 使用 model.generate() 让模型输出音频对应的文本。
- 通过 batch_decode() 解码生成的文本。
5.提取 & 清理:
- 通过正则表达式 re.search() 提取核心内容。
- 过滤掉模型可能多输出的无关信息,确保最终输出只包含语音文本。
这样就能用 Qwen2-Audio-7B-Instruct 实现高质量的语音转文本处理! 🚀
3、封装切割函数
笔者在测试Qwen2-Audio-7B-Instruct模型时,发现上转换超过30秒的音频时,回答的内容会不完整,所以这里我们定义一个函数,将一个长音频切割为若干的短音频
def split_audio(input_wav, segment_length=30, output_dir="output"):"""将WAV文件按指定的时长进行分割(默认30秒)。:param input_wav: 输入的WAV文件路径:param segment_length: 每段的时长,单位为秒(默认30秒):param output_dir: 分割后的文件保存目录(默认"output")"""# 载入音频文件audio = AudioSegment.from_wav(input_wav)# 计算每段的毫秒数segment_ms = segment_length * 1000# 创建输出目录(如果不存在)if not os.path.exists(output_dir):os.makedirs(output_dir)# 获取音频的总时长(毫秒)audio_length = len(audio)# 根据音频时长进行分割count = 0for i in range(0, audio_length, segment_ms):# 截取当前的音频段segment = audio[i:i + segment_ms]# 生成输出文件路径output_file = os.path.join(output_dir, f"{count}.wav")# 导出音频片段为WAV文件segment.export(output_file, format="wav")print(f"保存: {output_file}")count += 1该函数的作用是:
-
读取 WAV 音频文件。
-
计算每个片段的时长(以毫秒为单位)。
-
检查并创建存放分割音频的文件夹。
-
遍历整个音频,每次截取
segment_length秒的片段。 -
将音频片段保存为新的 WAV 文件,并按照
0.wav、1.wav命名。
4、主函数调用
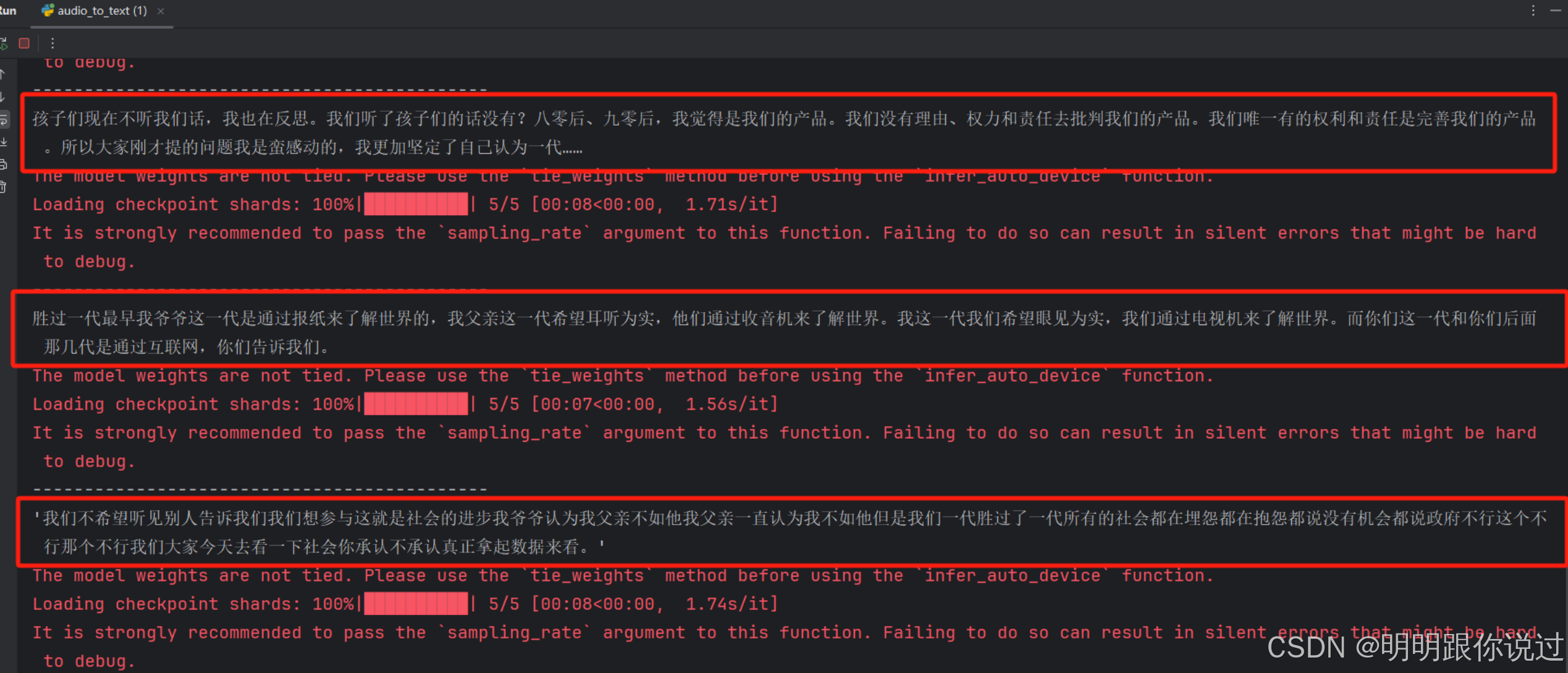
if __name__ == "__main__":# 调用函数进行分割input_wav = "C:/Users/LMT/Desktop/my.WAV" # 输入的WAV文件路径split_audio(input_wav,output_dir="E:/voice")# 遍历输出目录下的所有WAV文件,进行语音识别count = 0text = ""while True:file_name = "E:/voice/" + str(count) + ".wav"if os.path.exists(file_name):text += audio_to_text(file_name)os.remove(file_name)count += 1else:breakprint("============================")print(text)上面的代码执行完成后,就会最终得到语音转换后的文本
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!