公式识别时文档智能解析中的重要一环,本文笔者将介绍笔者自己的工作,仅供参考。
关于文档智能的全链路的技术路线,笔者在前期做了大量的技术解析,详细可以看专栏《文档智能专栏(点击跳转)》
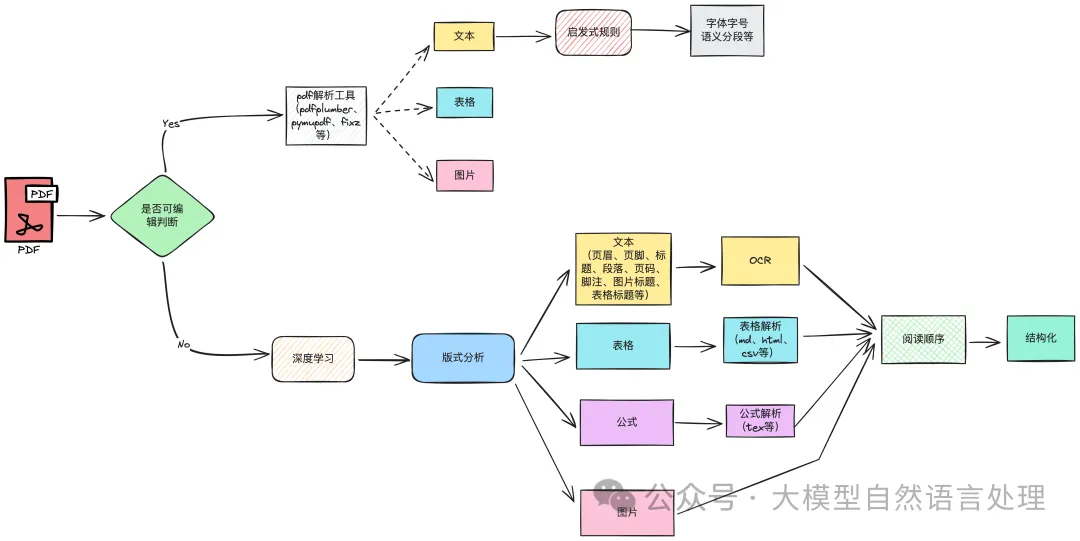
问题陈述与动机

数学公式是逻辑的建筑蓝图——它们在求和符号中嵌套分数,在行文中堆叠矩阵,并分支为条件分段函数。然而,尽管数学公式具有复杂的结构,当前的数学表达式识别(MER)模型甚至难以可靠解析中等复杂度的表达式。试想:当公式的视觉密度增加时,其渲染图像会扩大以保持清晰度。但问题在于——模型会将所有输入严格调整为224×224像素等固定尺寸。图1中的负号在原始高分辨率图像中清晰可辨,但经过压缩后,它会坍缩成一个与分数线模糊融合的两像素污点。这种压缩会引发连锁故障:下标与基准字符粘连,括号等定界符失去方向感,层级关系消解为视觉噪声。
数学表达式识别挑战
复杂公式带来了三个关键挑战。首先,层次嵌套(如分数内的矩阵)需要精确解析。其次,不同LaTeX代码可能渲染出相同图像,导致歧义问题。第三,现有数据集规模小且缺乏结构多样性。
为应对这些挑战,我们提出三项贡献,重新定义数学表达式识别领域:
-
HDR数据集——MER研究的重大突破。不同于局限于简单方程的现有数据集,HDR包含超过10亿个公式,精心组织为HDR-100M训练集和覆盖12个复杂度层级的专项测试集。从基础分数到嵌套矩阵求和,再到多分支分段函数,该资源完整捕捉了真实科学符号的多样性。每个公式包含多标签注释和替代性语法表示,使模型能够学习不同LaTeX格式的等价表达。
-
HDNet架构——带有颠覆性层次子公式模块的编解码架构。其动态裁剪机制可分离求和界限、矩阵括号、分数线等关键子组件,在分层融合特征前对每个组件进行最优分辨率处理。
-
公平评估协议——针对MER评估体系性缺陷的解决方案。现有指标将有效LaTeX变体误判为错误,混淆语法偏好与真实错误。我们的评估协议为数学等价表达式建立等价类标准。
1. HDR数据集

首先是HDR数据集。我们在表1中的分析展示了HDR-Test如何系统地按层次级别和线条数对公式进行分类。HDR数据集涵盖八个类别的公式,其复杂度分别由层次级别和线条数计算得出。
分层如下:
- 0级:独立字符

-
1级:字符+位置关系

-
2级:构造结构

- 3级:多层

首先是HDR数据集。为标准化公式复杂度的表示,我们在此解释层次级别的含义:
在0级,我们定义原子元素——独立字符如"a"或数字,它们是构成公式的基础单元。当这些元素与上标、下标等操作符结合时,复杂度上升至1级。
2级引入结构性复杂度——分数、积分或求和符号。此时空间关系决定了语义。但真正的挑战出现在更高层级,公式呈现俄罗斯套娃式嵌套结构:例如包裹矩阵的分段函数,这类表达式要求跨多层精确匹配开闭定界符。
通过在复杂度梯度上训练模型,我们迫使它们掌握LaTeX的结构语法——不仅识别符号,更要理解其嵌套依赖关系。这种层次划分不仅是理论概念,更是解析真实公式的关键。
HDR-1亿数据集提供了前所未有的规模和多样性,涵盖了从数学到计算机科学领域的arXiv论文中的公式。HDR测试集包含多标签注释,以涵盖有效的LaTeX变体。如图3所示,HDR在复杂性方面超越了先前的数据集,能够支持强大的模型训练和评估。

2. HDNet架构

HDNet将视觉Transformer编码器与Transformer解码器相结合。其关键创新点在于特征融合:将主公式的全局上下文信息与子公式的局部细节信息相融合。损失函数通过参数α来平衡主公式损失和子公式损失。这种双重关注确保了对公式结构和细节的准确解析。
在训练过程中,如图2的左侧所示,公式会根据其标签进行分层解析。每个公式会被拆分、渲染并调整大小成为子公式。主公式也会进行渲染和调整大小。主公式和子公式都会被输入到编码器中以提取特征。然后,子公式的特征会通过加权聚合的方式与主公式的特征相融合,以提供额外的视觉细节信息。经过加权的特征会被传递到解码器,以预测主公式的结果。此外,每个子公式的特征会被单独传递到解码器,以预测子公式的结果。该模型的优化目标包括主公式的损失以及子公式损失的总和。
loss如下:

- 公平评估策略
评估的公平性至关重要。传统的评估方法局限于字符层面,当数学公式图像可以用多种有效方式进行解释时,这些方法往往无法公平地评估模型。由于具有功能等效性的LaTeX命令,预测结果和真实标签在字符层面可能会有所不同,但作为图像渲染出来时却是相同的。例如,一些LaTeX公式在功能上是相同的,但在文本表达上存在差异。
为了克服这一问题,如图所示,我们提出了一种简单而高效的评估策略,该策略考虑了功能等效表达式的所有有效解析选项。我们的方法在进行字符层面的评估之前,会用等效表达式来替换标签和模型预测结果。

这种方法能够涵盖更广泛的有效表达式,确保在识别和解析复杂公式时,对模型性能进行更可靠、更公平的评估。通过处理基于LaTeX的公式生成过程中的可变性,我们的策略提高了字符层面评估的准确性和公平性。
评价指标:Edit distance, BLEU, character recall
实验评测
我们将HDNet与一些基线模型进行了比较,结果见表。HDNet的表现优于所有基线模型,实现了最高的字符召回率(0.968)、最低的平均编辑距离,以及最高的BLEU分数。

跨数据集泛化:
我们还对现有的公式识别数据集进行了比较,HDNet同样取得了最佳结果。值得一提的是,HDNet在参数数量方面也具有优势,如图4所示,子公式模块并未增加额外的参数。


消融实验
为了验证我们的分层子公式模块,我们进行了四种配置下的消融实验:不裁剪、随机裁剪、子公式裁剪,以及子公式和随机裁剪相结合。
实验结果总结在表IV中,结果表明“子公式 + 随机裁剪”的配置取得了最佳性能,公平字符召回率(Fair-CR)得分达到了0.968。然而,仅使用子公式裁剪时,得分降至0.837。这是为什么呢?

子公式裁剪在训练过程中依赖标签来提取子公式,但在测试阶段这些标签是不可用的。这就导致了训练阶段和测试阶段之间的不匹配。通过将子公式裁剪与随机裁剪相结合(在训练和测试中都一致应用),我们消除了这种差距,确保了模型的稳健性能。
这个实验强调了使训练条件和推理条件保持一致的重要性,尤其是对于像数学表达式识别(MER)这样对细节敏感的任务来说。
总结与展望
我们的工作解决了数学表达式识别(MER)领域的两个根本性局限:一是缺乏能够涵盖复杂层次结构的数据集,二是现有模型无法解析复杂公式中的细粒度细节。
首先,HDR数据集为MER研究树立了新的标杆。它拥有一亿个训练样本,并且有一个涵盖多个不同学科领域的多标签测试集。这促使模型去处理嵌套结构、多行公式以及功能等效的解释。通过纳入从简单字符到深度嵌套矩阵的不同层次,HDR弥合了理论研究与实际应用之间的差距。
其次,HDNet重新定义了模型处理复杂公式的方式。它的分层子公式模块将表达式分解为高分辨率的子组件,从而实现对细节的精确识别。通过融合主公式及其子公式的特征,HDNet在面对尺度变化和复杂的符号排列时表现出很强的稳健性。双重损失函数进一步确保了平衡优化,既重视全局结构,又注重局部的准确性。
我们的实验表明,HDNet优于现有的MER模型,在编辑距离和字符召回率等指标上均取得了最佳性能。至关重要的是,我们引入了一个公平的评估框架,该框架考虑了公式的多种有效解释,这是对以往严格的字符层面比较的一种范式转变。
展望未来,我们设想HDNet将成为科学文献分析、教育技术以及多语言公式识别的基础工具。未来的工作将扩展HDR数据集,使其包含手写表达式,并针对实时应用对HDNet进行优化。
总之,HDR数据集和HDNet架构解决了数学表达式识别(MER)领域的关键缺陷。未来的工作将包括将其扩展到手写表达式识别以及多语言环境中。我们相信这项工作为人工智能系统实现更可靠的数学理解奠定了基础。