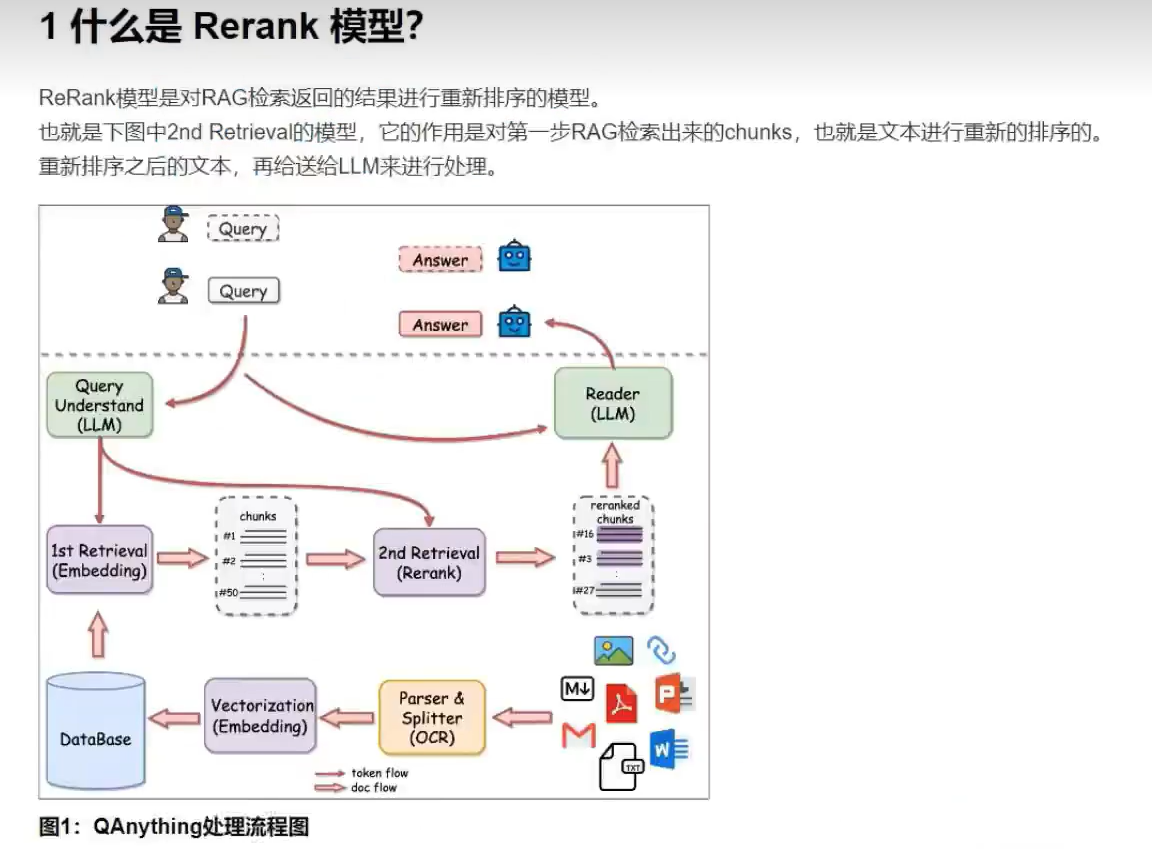
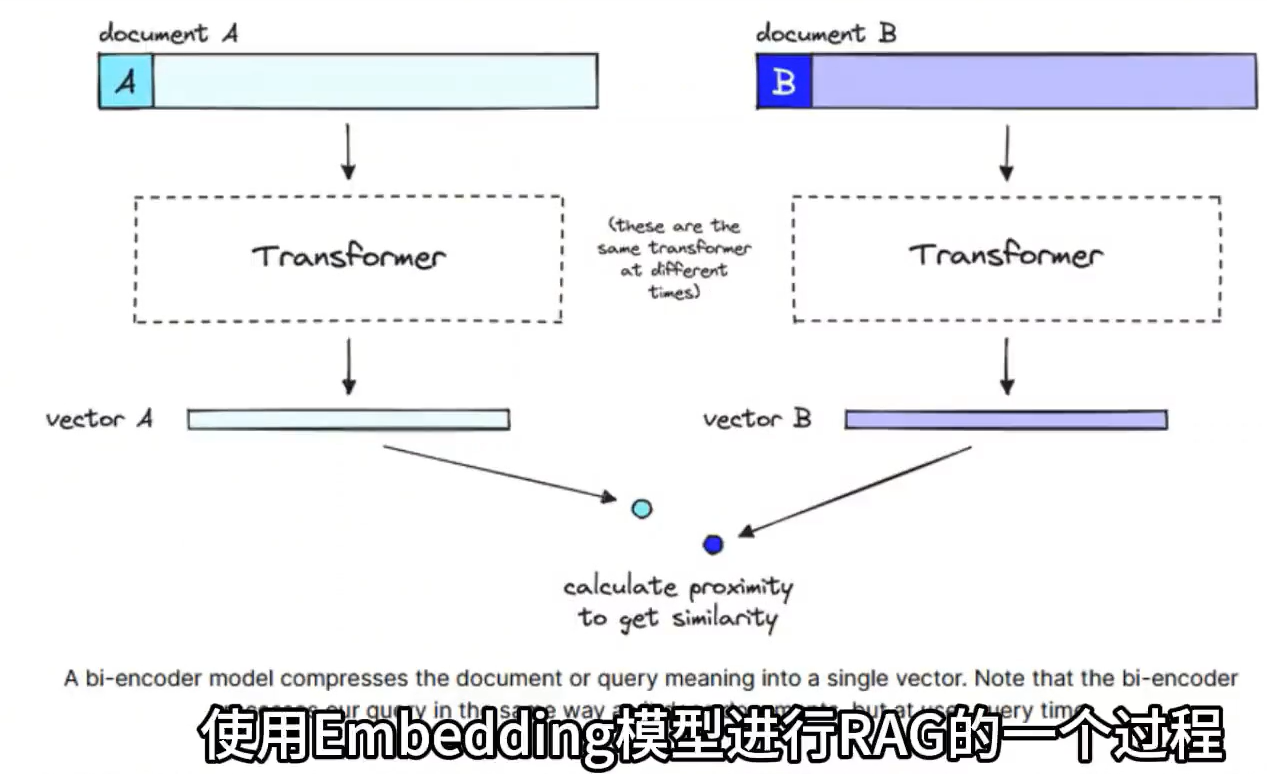
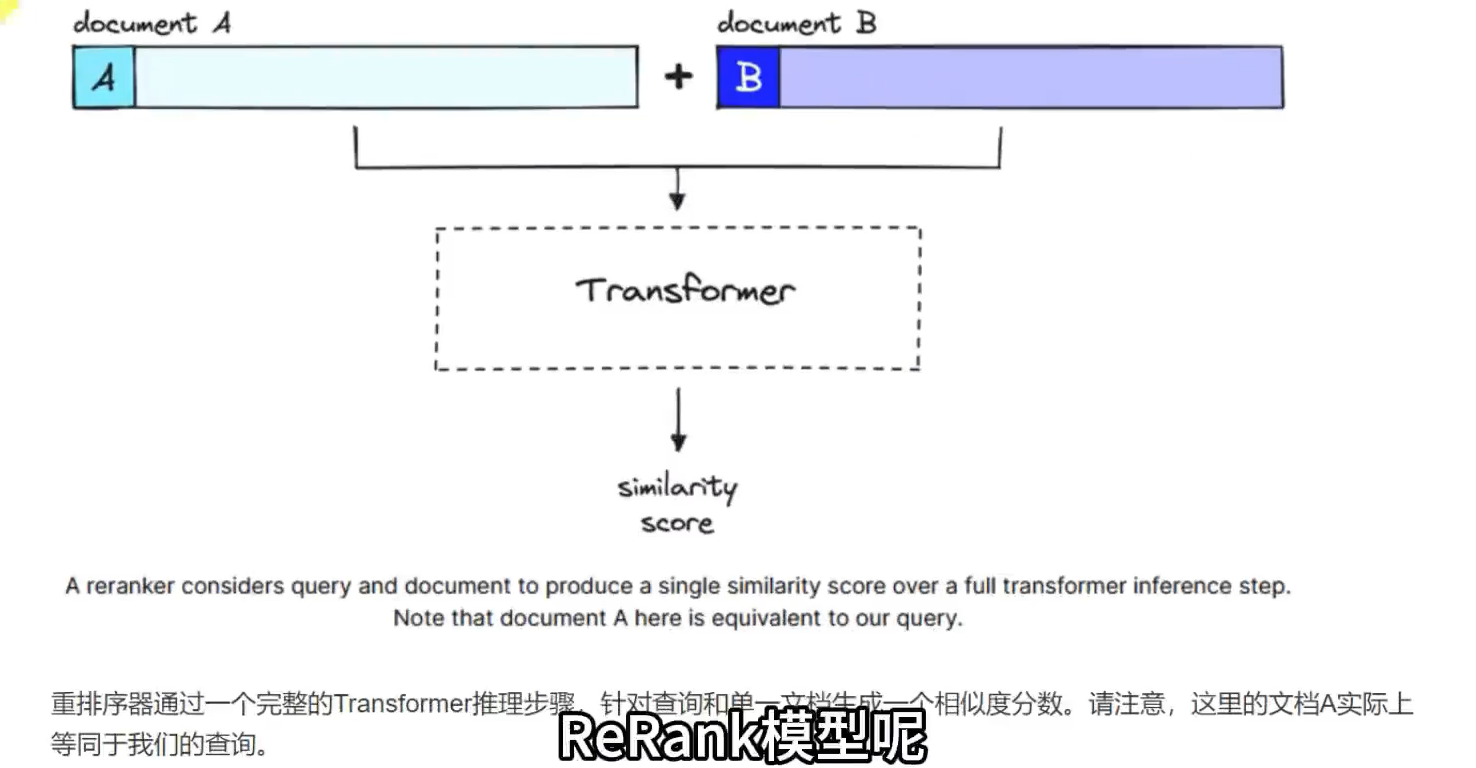
DIFY是一个开源的大语言模型(LLM)应用开发平台,旨在简化和加速生成式AI应用的创建和部署。它融合了以下核心特性:
- 低代码/无代码开发:通过可视化界面定义Prompt、上下文和插件,无需深入底层技术细节。
- 模块化设计:提供清晰的模块接口,开发者可按需选择模块构建AI应用。
- 多模型支持:兼容Claude3、OpenAI等主流大模型,并与多家模型供应商合作。
- 功能组件丰富:包含AI工作流、RAG管道、Agent、模型管理等工具,覆盖从原型到生产的全流程。
ps:dify的安装可以参考博客:dify + deepseek /qwen + win +xinference 等完成知识库建设-CSDN博客
1.dify安装完成创建超管
通过登录地址 dify: http://ip:port/signin
第一个登录的人默认为超级管理员
2.创建新用户
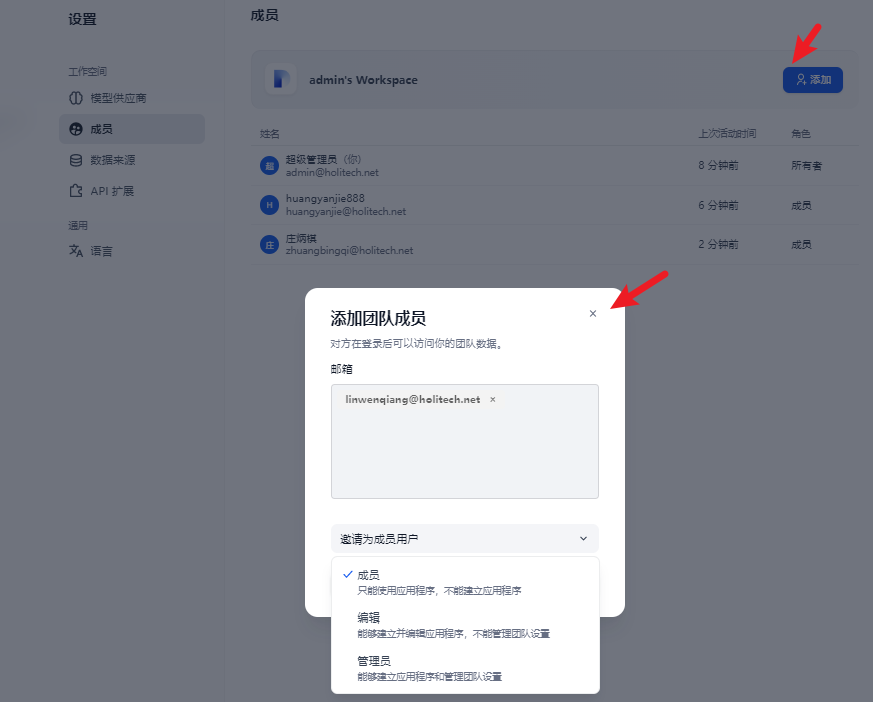
登录系统后,点击右上角头像->设置

点击界面添加,输入邀请成员的邮箱,eg:zhuangbignqi@holitech.net,点击发送邀请。
注:一旦选择用户的角色,后期无法更改。

将邀请链接发送给邀请对象,进行用户注册。

用户接收到邀请后,输入登录密码,至少8位,中英文结合。
登录后,设置用户名,加入后,系统会自动跳转到
普通用户进入后 则可看到对应邀请对象的工作空间。
3.模型供应商选择
登录系统后,点击右上角头像->设置 进入设置界面

用户可根据已安装的模型进行选择添加自身的供应商(若已有供应商 则直接配置,否则需要在安装供应商下方找到对应的供应商模型进行安装并配置)
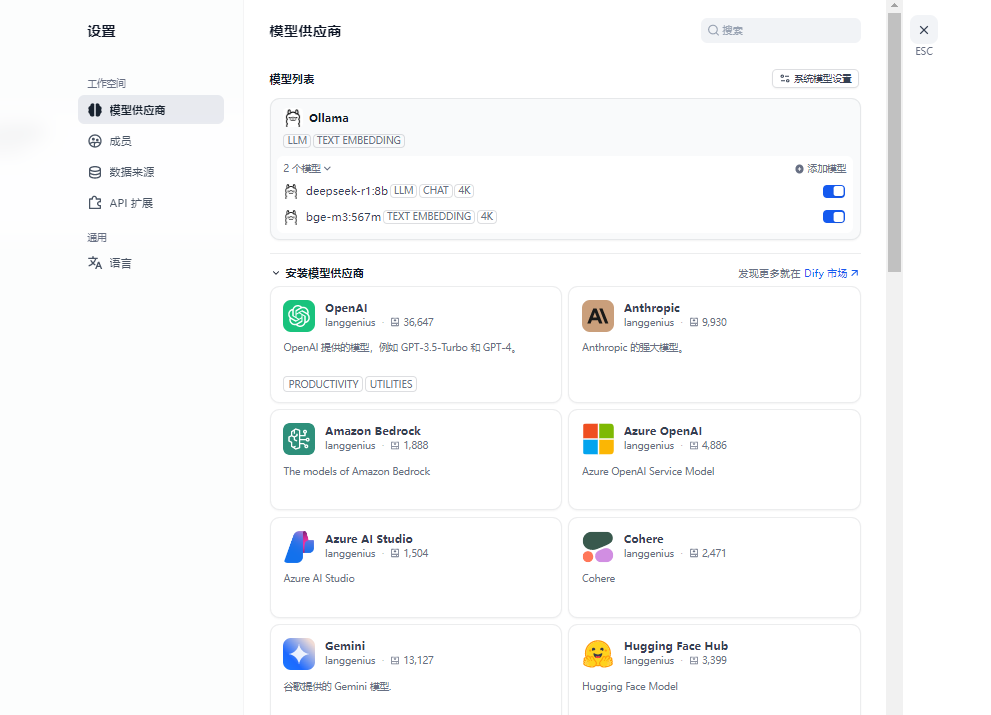
根据已安装的模型,填写相对应的信息,即可完成模型添加
1) ollama下的模型

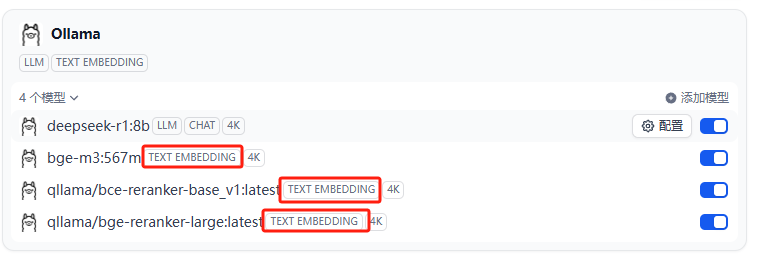
Ollama可根据如上图添加
2) Xorbits Inference 如下
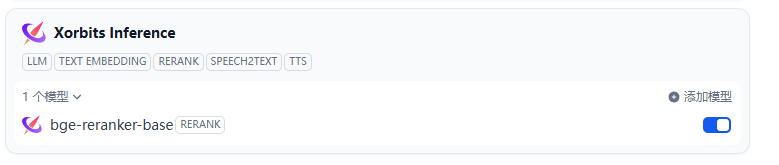
Xorbits Inference
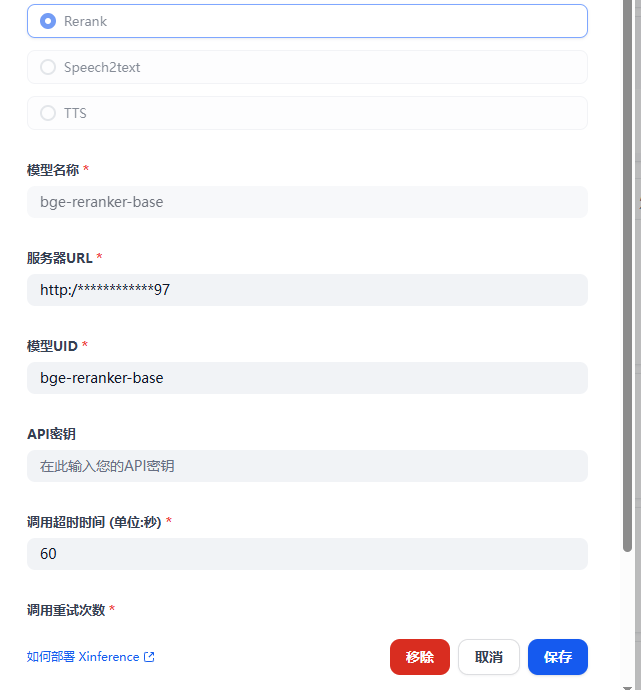
http://10.6.16.97:9797
4.创建知识库
1) 创建本地知识库
管理员进入管理界面后,选择创建知识库,即可进入配置页面。
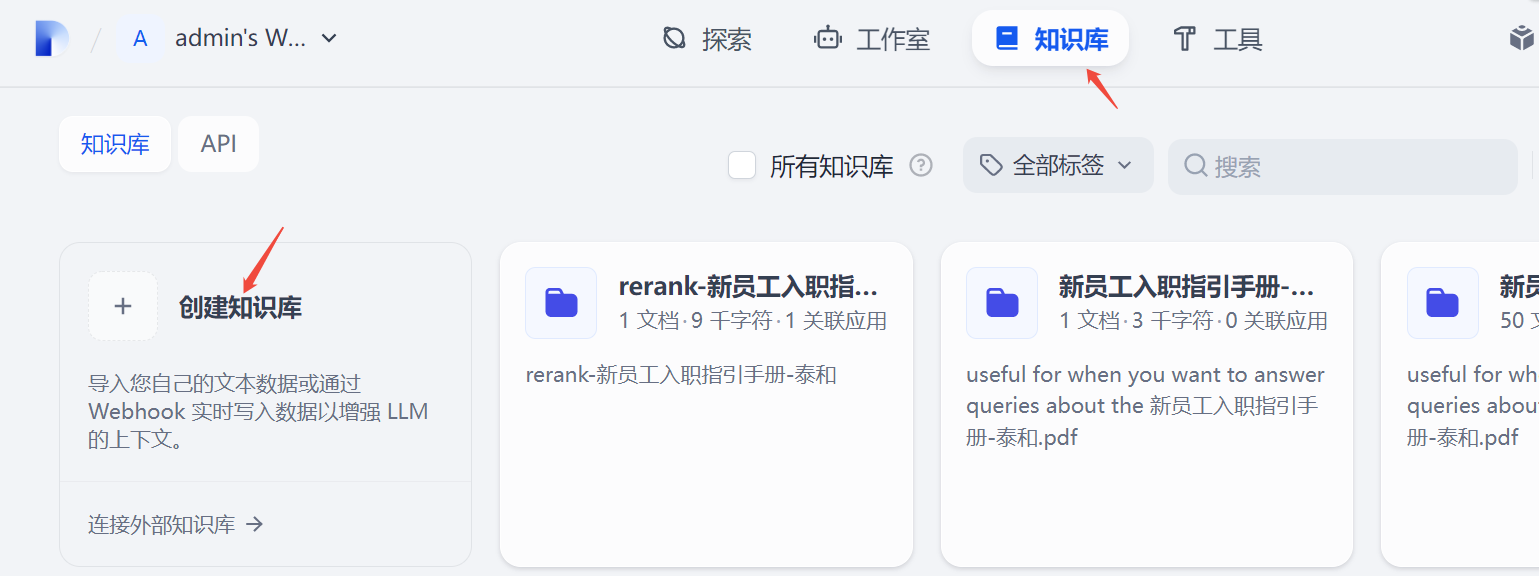
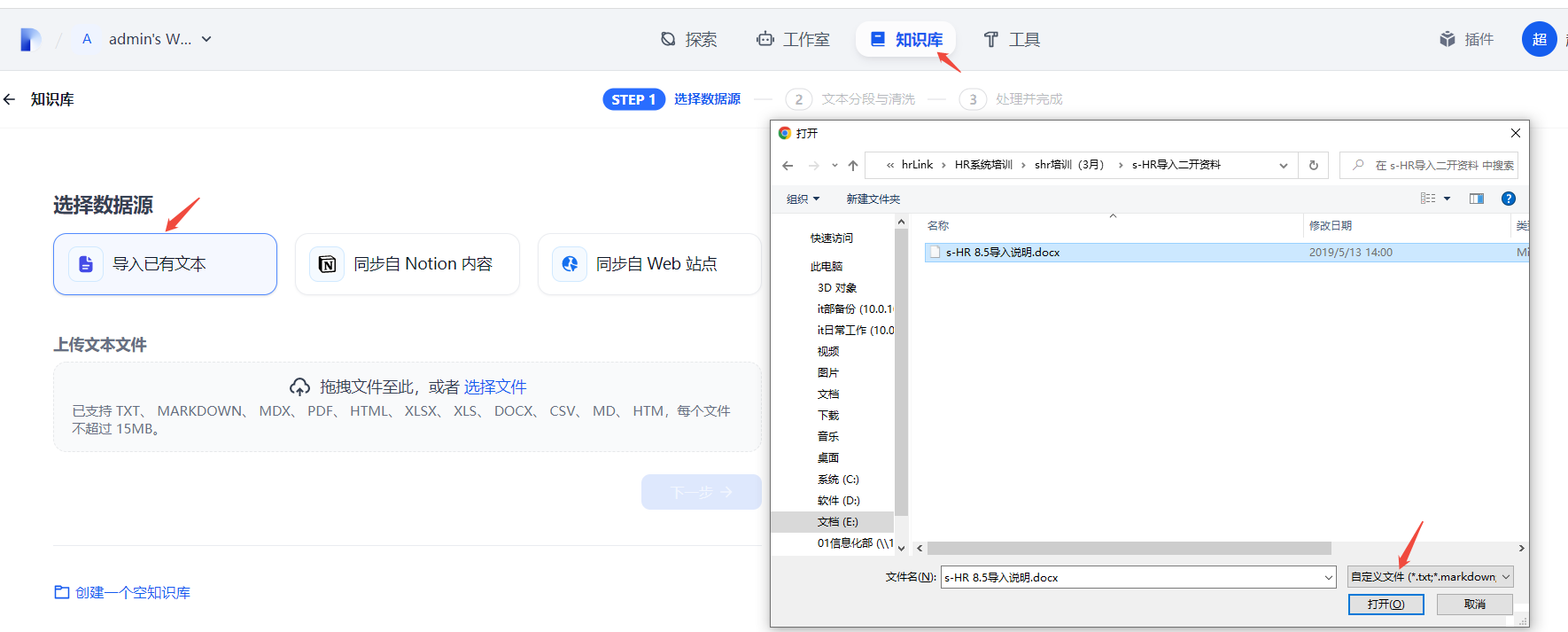
进入配置页面后,可根据自身已有的知识文档,web链接、notion等读取知识库信息,或者先创建一个空白知识库,后期进行知识文档上传操作。
ps:本地文档可以直接进行导入,如果需要通过在线的一些文档 需要配置对应的信息,也是通过右上角头像 ->设置->数据来源 进行配置
已“新员工入职指引手册-泰和”为例,导入进去
2)文档的清洗
上传后,点击下一步,配置文本分段与清洗信息
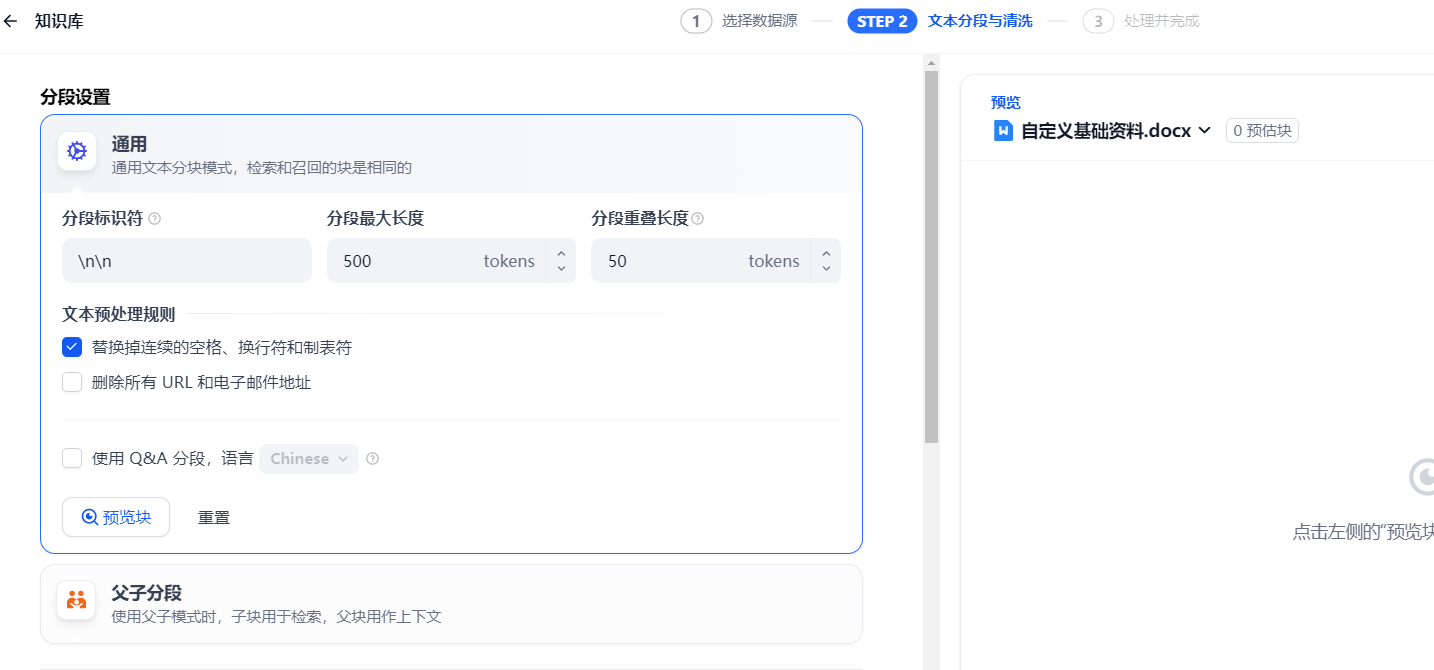

分段设置:推荐使用通用的分段
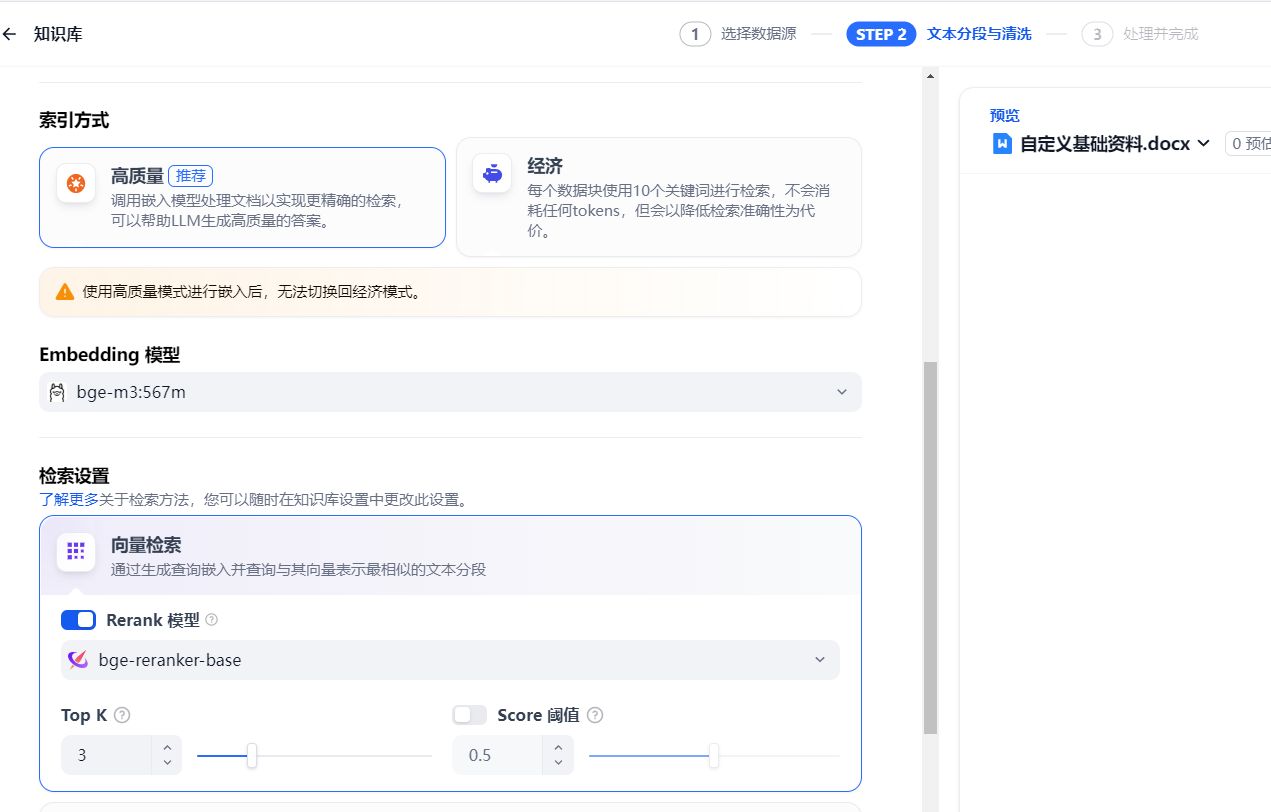
索引方式:高质量,更准确的识别
检索设置:使用混合检索。
3)rerank模型检索
如果有rerank模型 则可以使用rerank模型检索更准确
点击保存后,完成知识库的创建,此时无法修改知识库的名称。
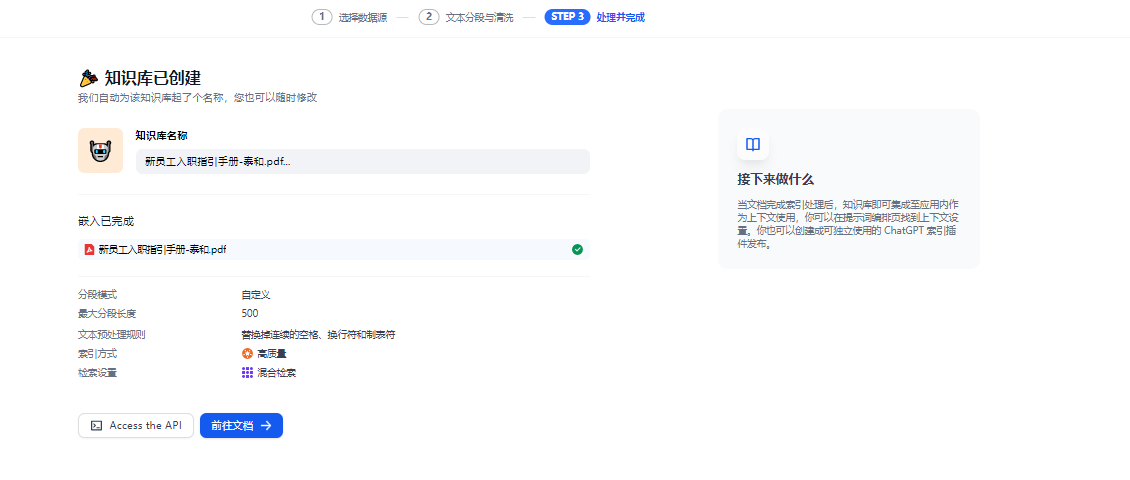
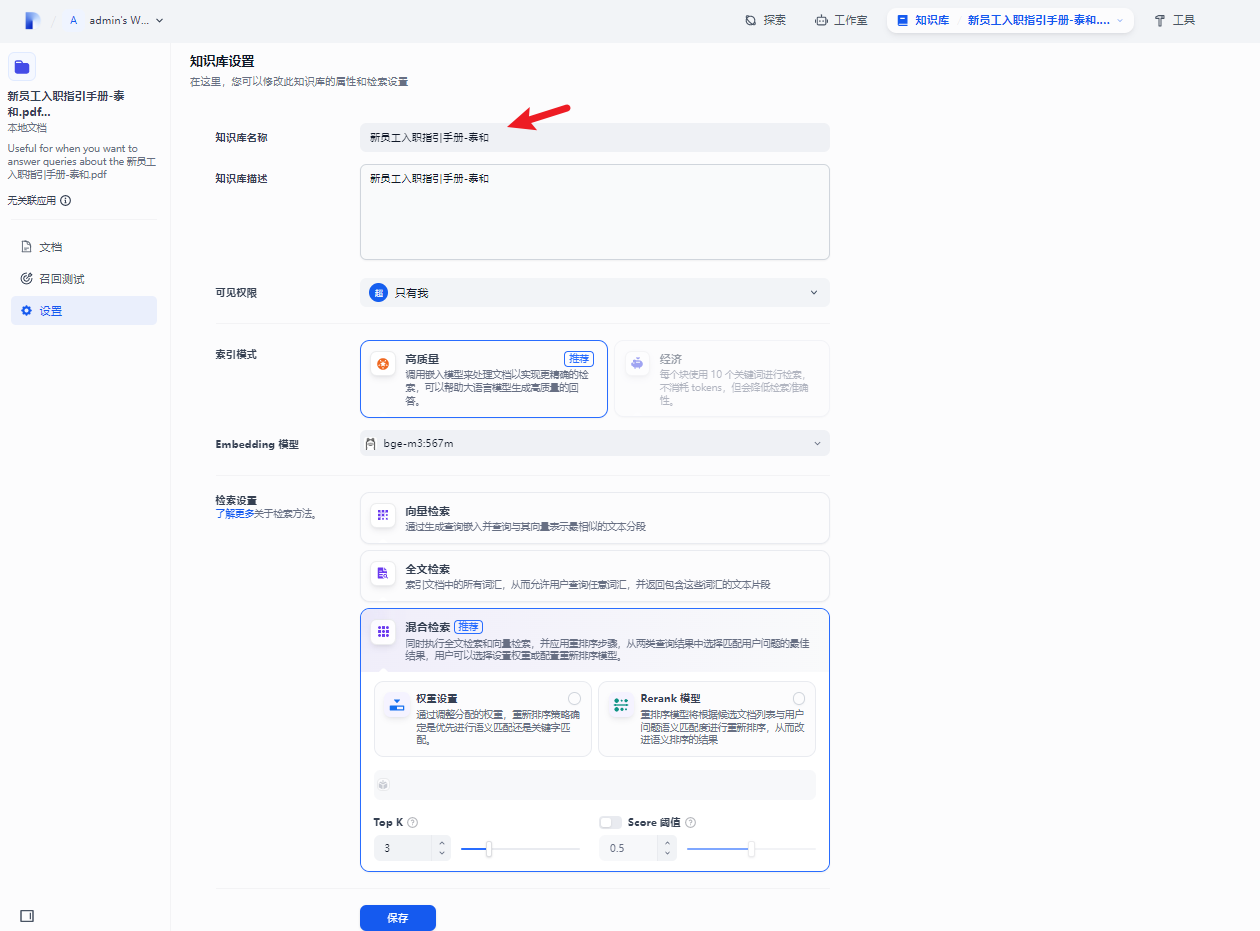
需要修改进入文档界面调整
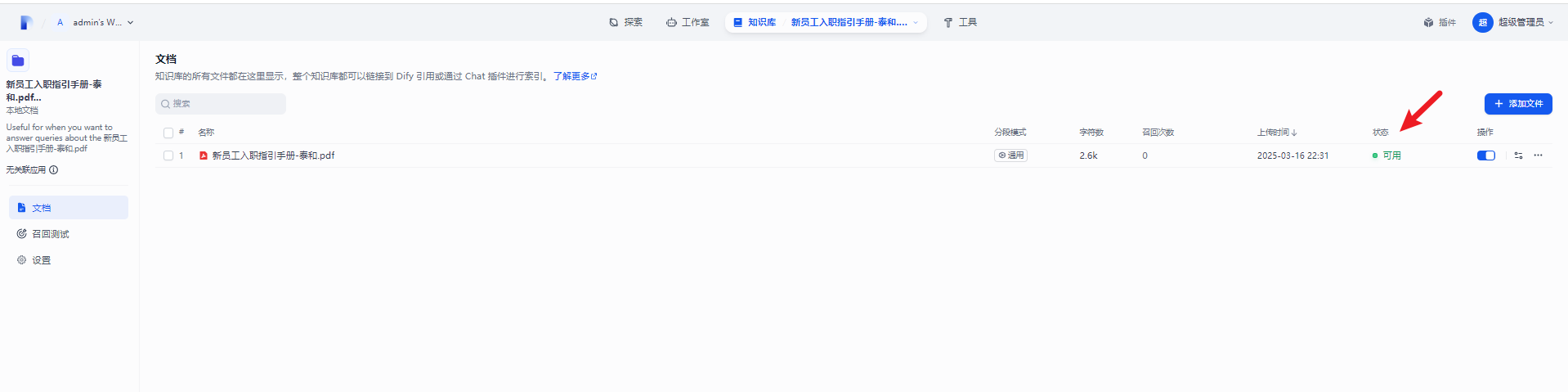
文档界面中可以进行文档的补充,查询文档是否已经智能处理完成等操作。
5. 创建机器人
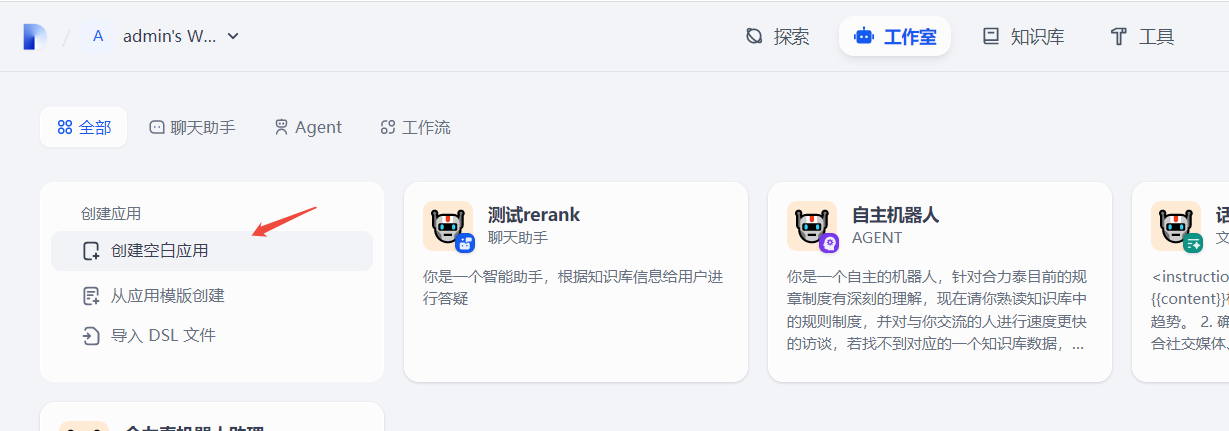
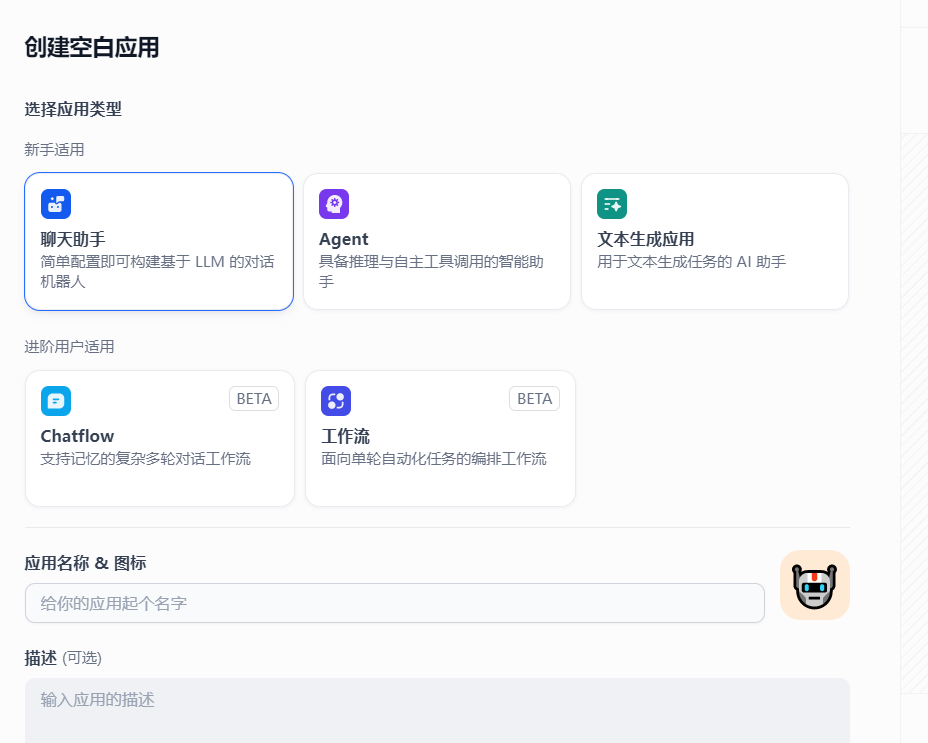
1) 创建空白应用
在工作室中 点击创建空白应用,
2)填写机器人用途 及名称
填写机器人名称,创建机器人助手
3) 调试机器人信息
根据自身需要,填写提示词(非必填),选择知识库,及右上方的处理模型,则可以进行机器人调试。

4) 选择知识库
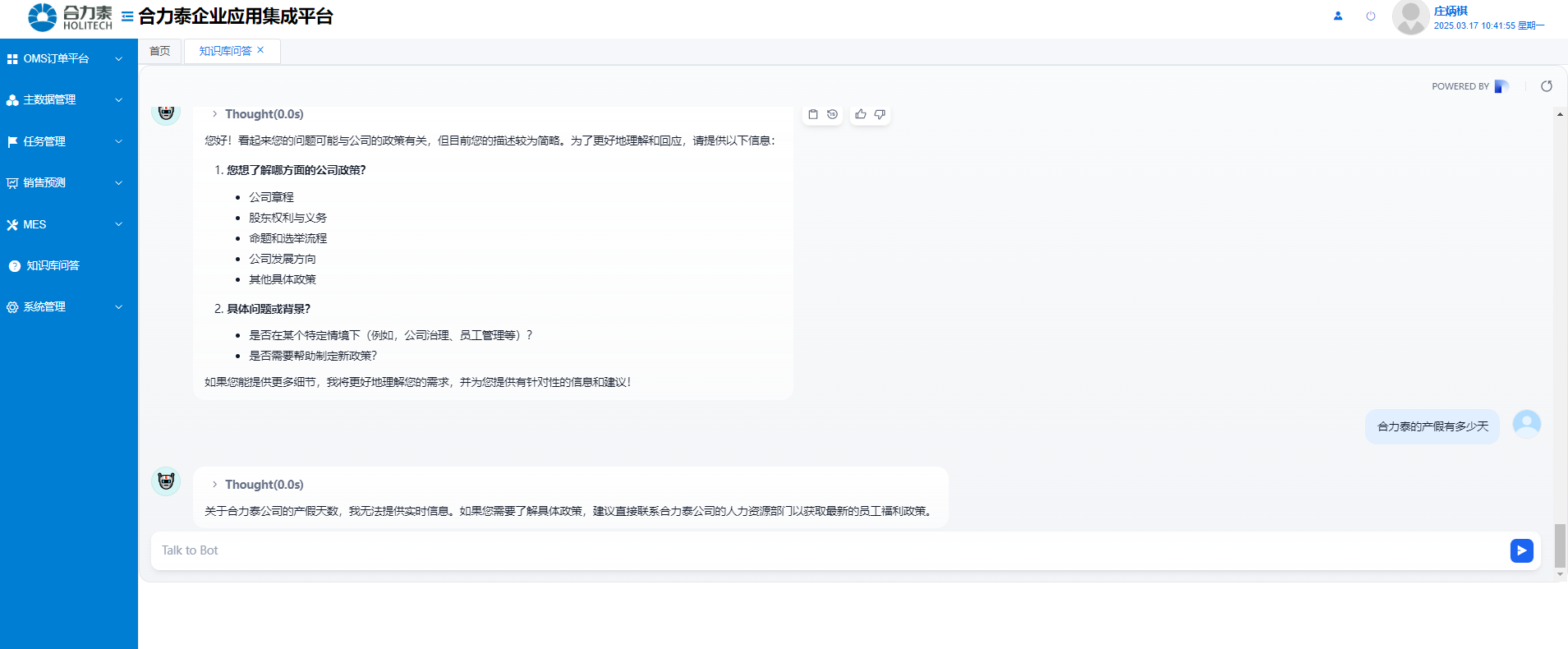
根据知识库已有信息,与机器人交流,得到对应响应

6. 对外发布
调试无误后,点击右上角的发布
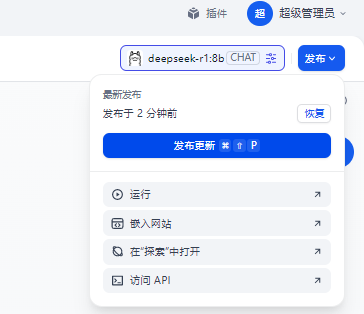
即可让其他局域网内的人链接。
登陆地址:对应本机的一个机器人连接
7.内联嵌入到其他自研网站
通过代码,可嵌入到其他的网站中
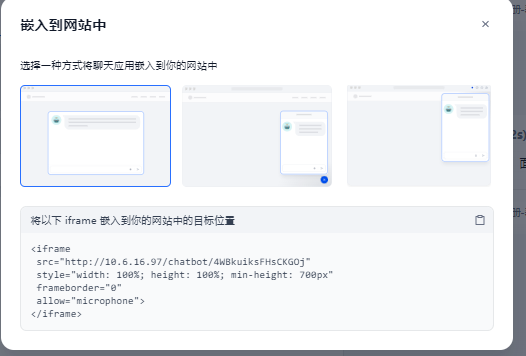
例如嵌入到eip系统
8.调用的API
机器人对外提供的api接口
在右上角中 选择发布->访问API跳转到swagger页面
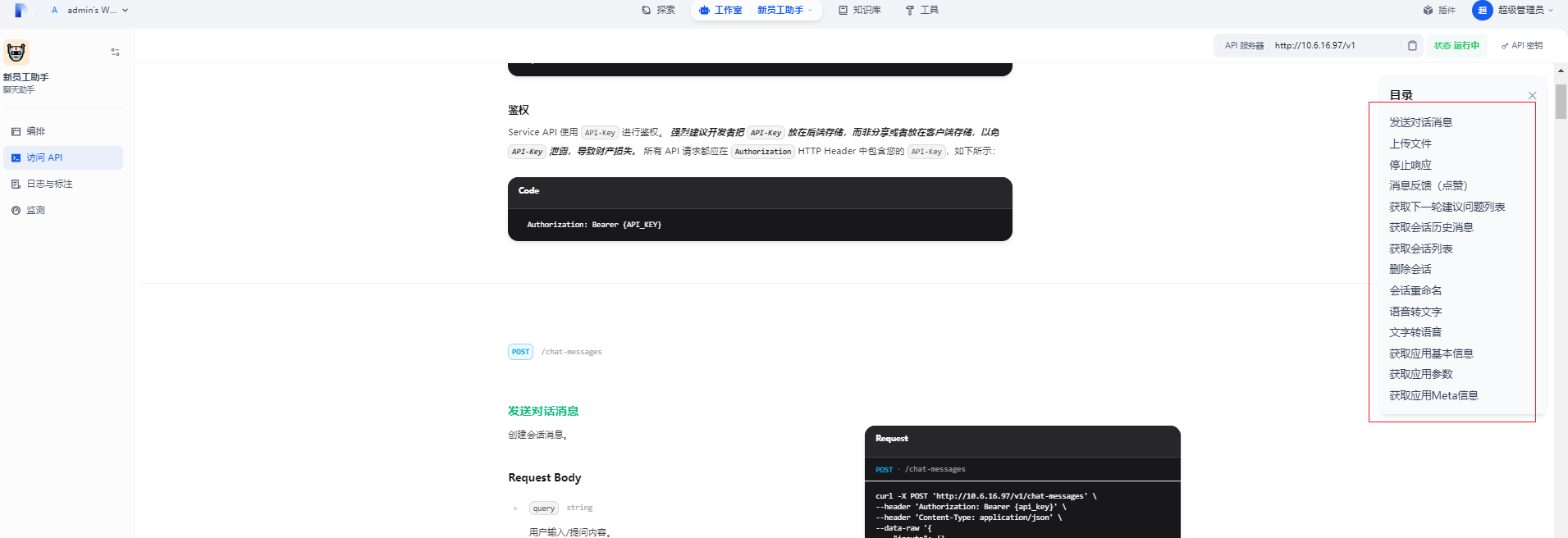
根据需要可将对应的接口提供给各大自研系统中。
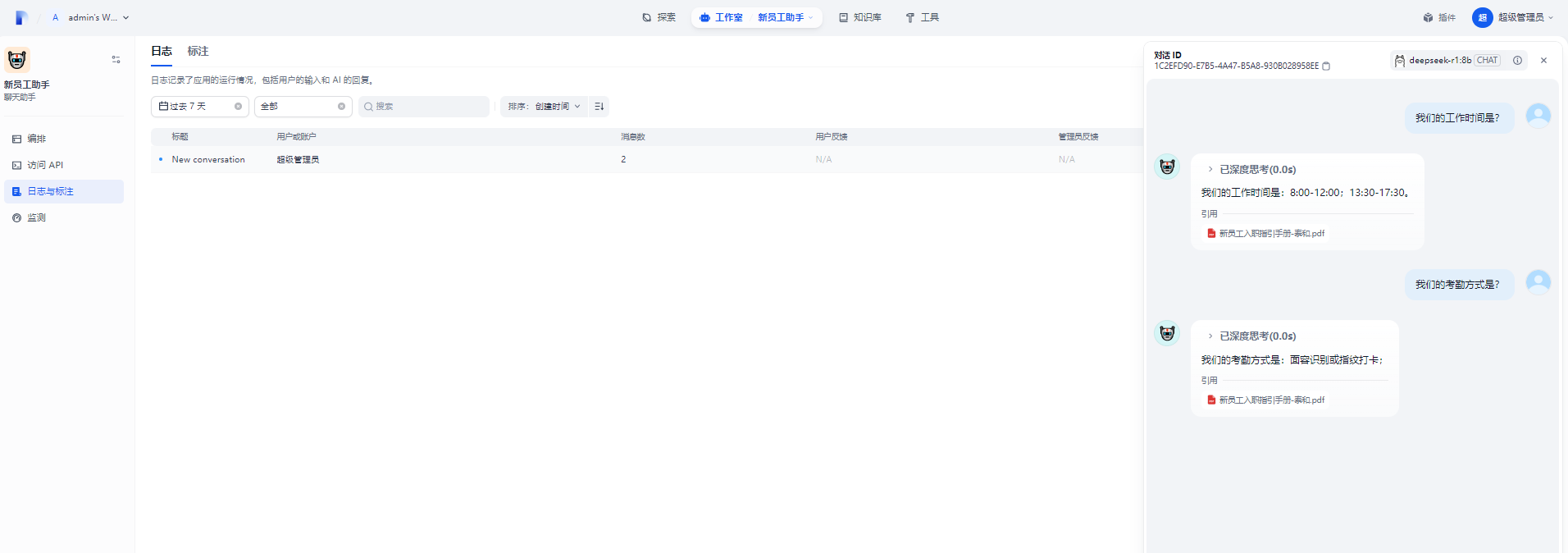
9.日志与标注
该系统提供了访问日志,可知道对应的访问日志信息
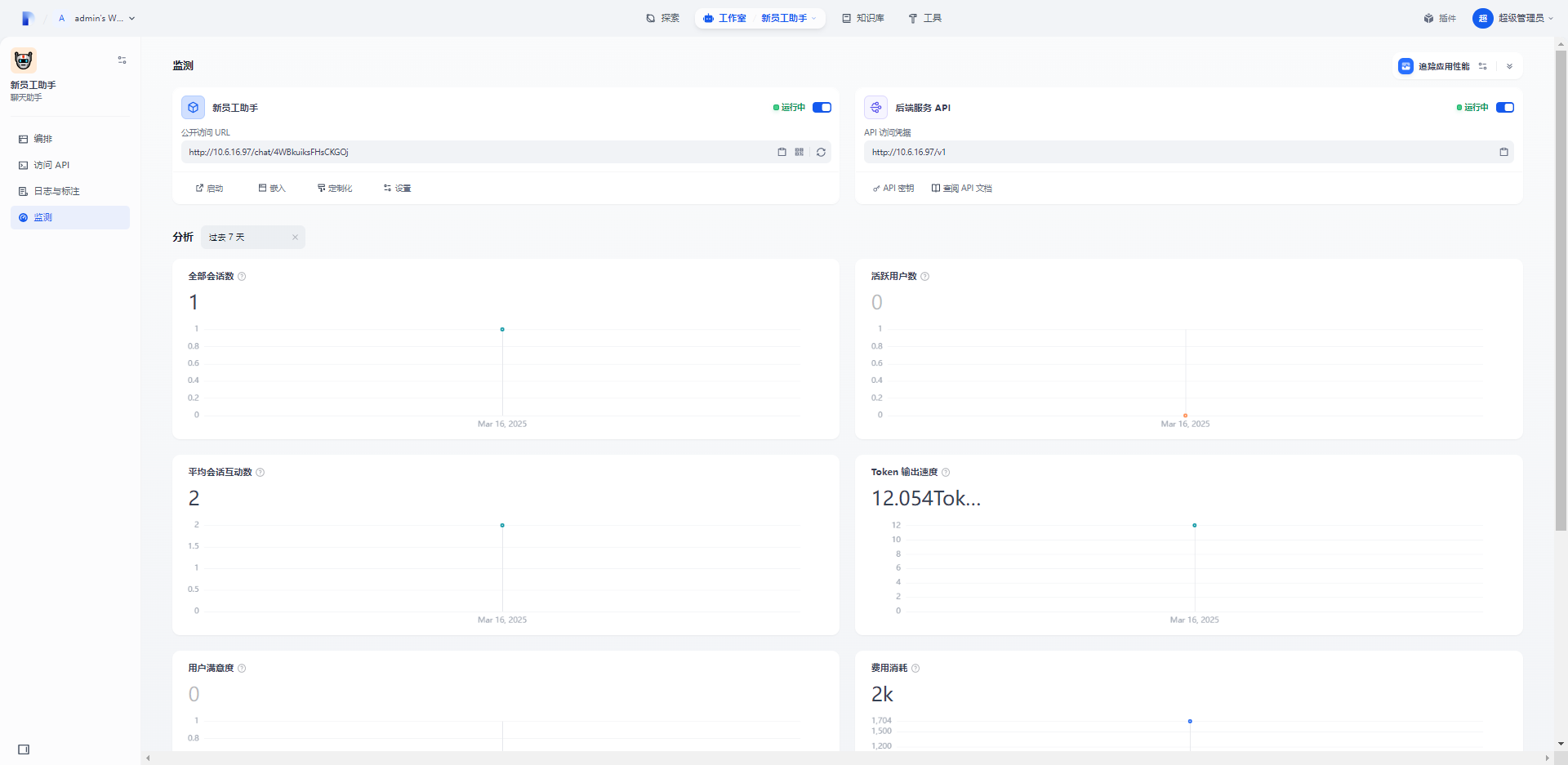
10.监测
系统自带监测信息,可通过视图查看
11.向量检索的知识了解
| 向量检索:擅长语义根据语义理解,可以根据查询的含义返回相关信息,即使文档中没有返回确切的词语,它更智能,可以跨语言理解,多模态理解,支持文本、图像、音频等。主要是通过计算提问query和文档之间的余弦相似度的数值大小,这个值越大,说明越相似。这里如果设置了top k,则按照余弦的大小排序,取前k名。
全文检索:又名关键字检索,擅长处理精确匹配,适合那些需要找到特定词语、技术属于或者文件的场景。他能快速找到包含确切关键词的内容,但不能理解器背后的含义。这里也会关注关键词和文档之间的预选相似度的大小排名。 混合检索:相当于向量检索和全文检索的结合。
Rerank:重新排序,是一种根据查询query和文档的相关性打分,并进行排序的技术,通过这种方式可以在检索系统中,更准确的排序返回的结果。尽管看起来与嵌入模型的余弦相似度计算类似,但是两种实现模式不同。
|


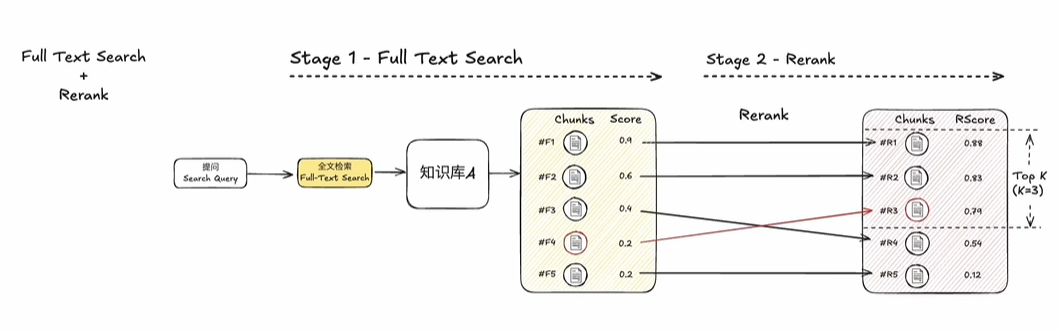
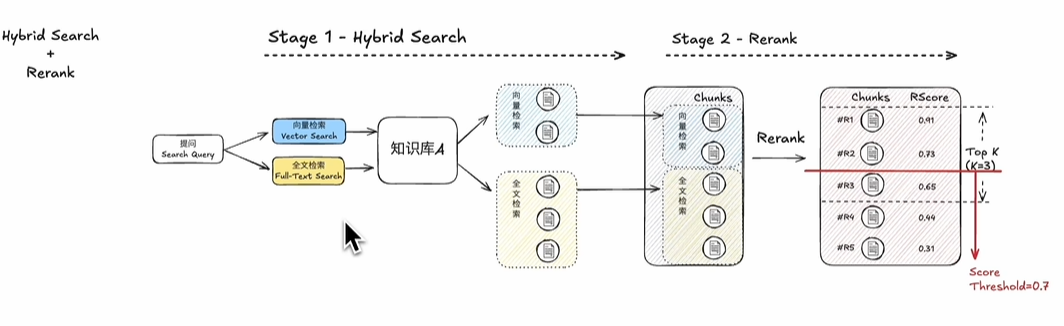


12.Rerank模型: