📕参考:大模型研讨课第一期:Why LLMs?、模型结构1(共10期)_哔哩哔哩_bilibili
(本系列是课程笔记)
Transformer
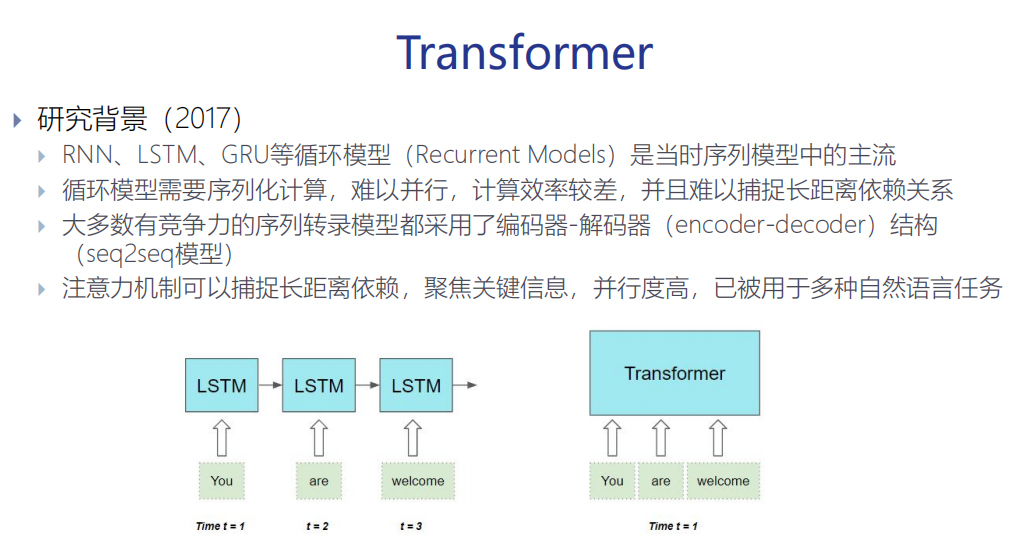
背景:
1.循环模型RNN、LSTM是当时序列模型的主流,但是循环模型需要序列化计算,难以并行,计算效率较差,并且难以捕捉长距离依赖关系。
2.注意力机制,可以捕捉长距离依赖,聚焦关键信息,并行度较高。
【总结思路:循环模型摒弃,seq2seq比较好保留,注意力机制也保留】
∴Transformer进行了改进:
(1)去掉了循环神经网络结构(效率低,无法并行训练)
(2)遵循seq2seq结构,encoder+decoder
(3)大量重复使用attention(attention is all you need)
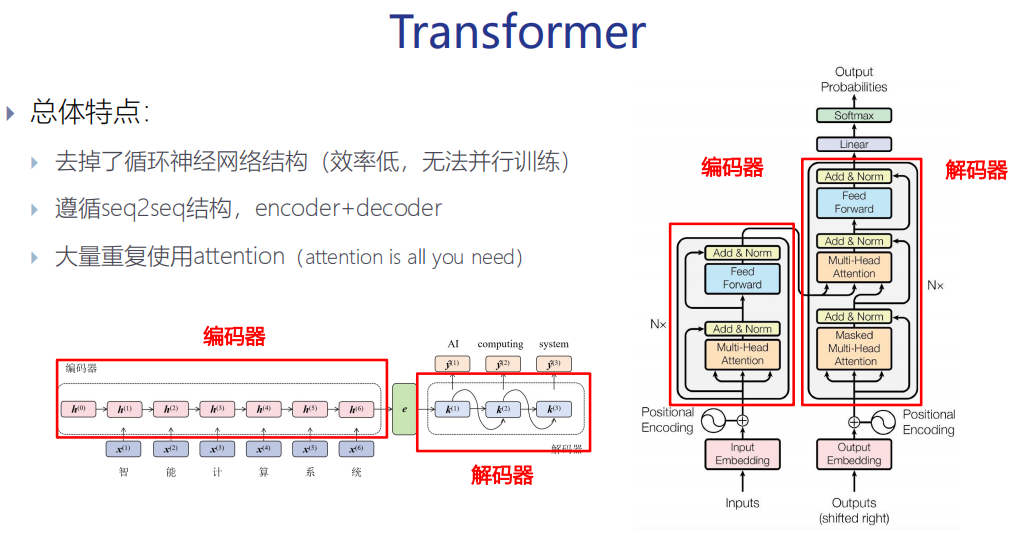
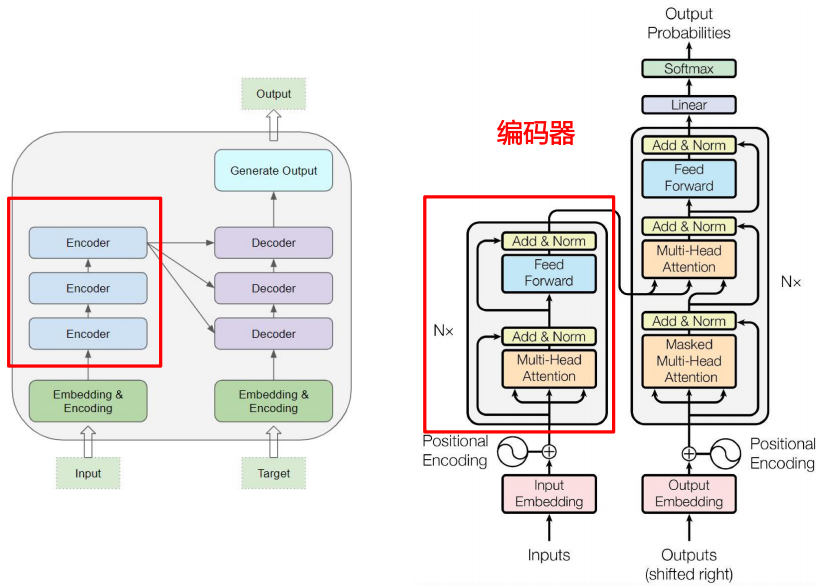
编码器
(1)6个相同的层组成(N=6)
(2)每层由两个子层(Sub-layer)组成
多头注意力机制(Multi-Head Self-Attention)
前馈网络(Feed-forward network)
(3)每个子层还增加了残差连接(Residual Connection) 和层归一化(Layer Normalization)

编码器的输入
编码器的输入:token embedding + position encoding
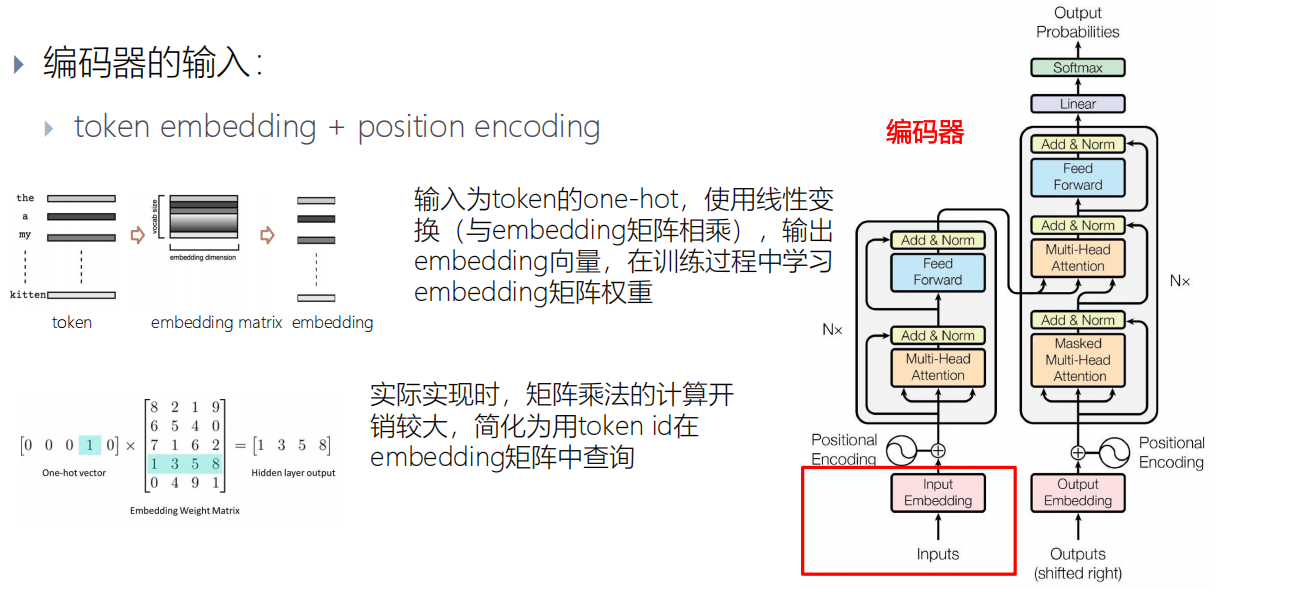
position encoding和token embedding的维度相同,直接相加
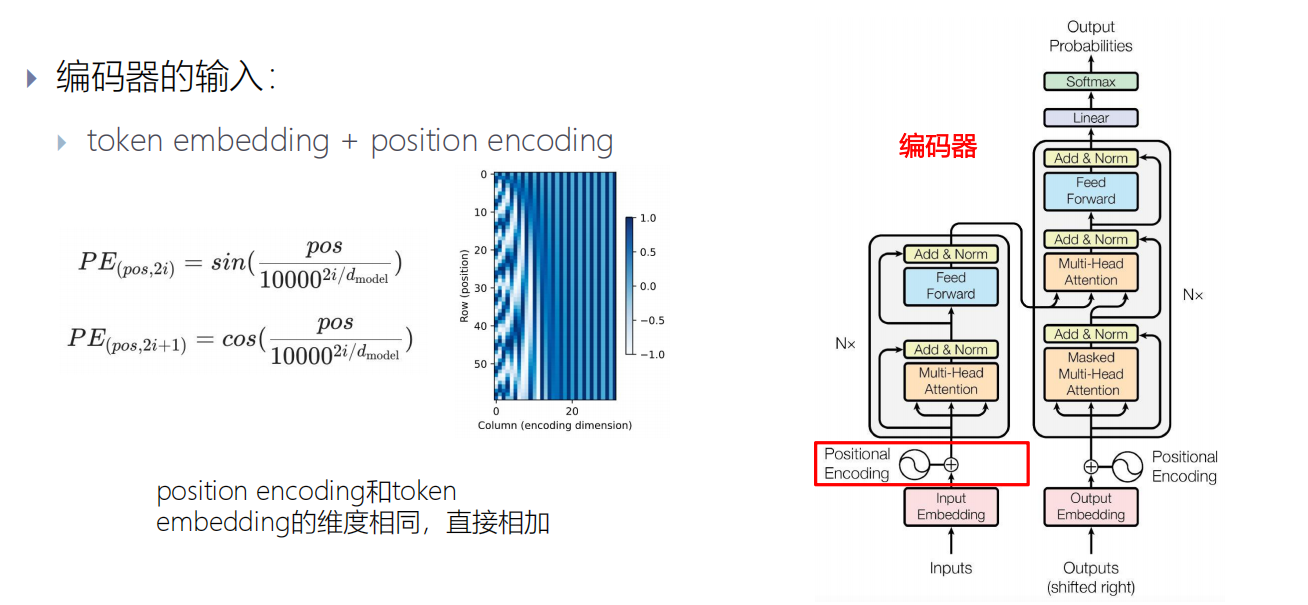
编码器层
编码器有6层:
(1)第一个编码器layer的输入是emb+PE
(2)后面N-1个编码器layer的输入是上一个 编码器layer的输出
一个多头自注意力子层
编码器layer:一个多头自注意力子层和一个FFN子层
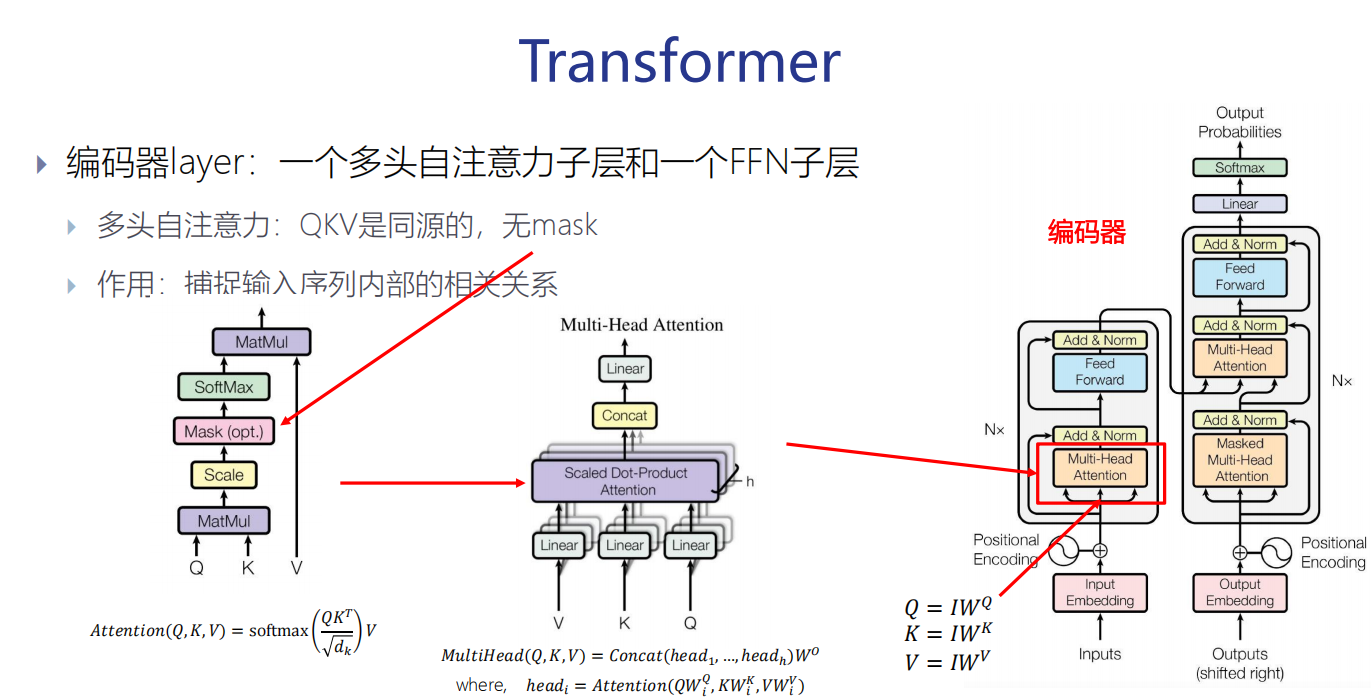
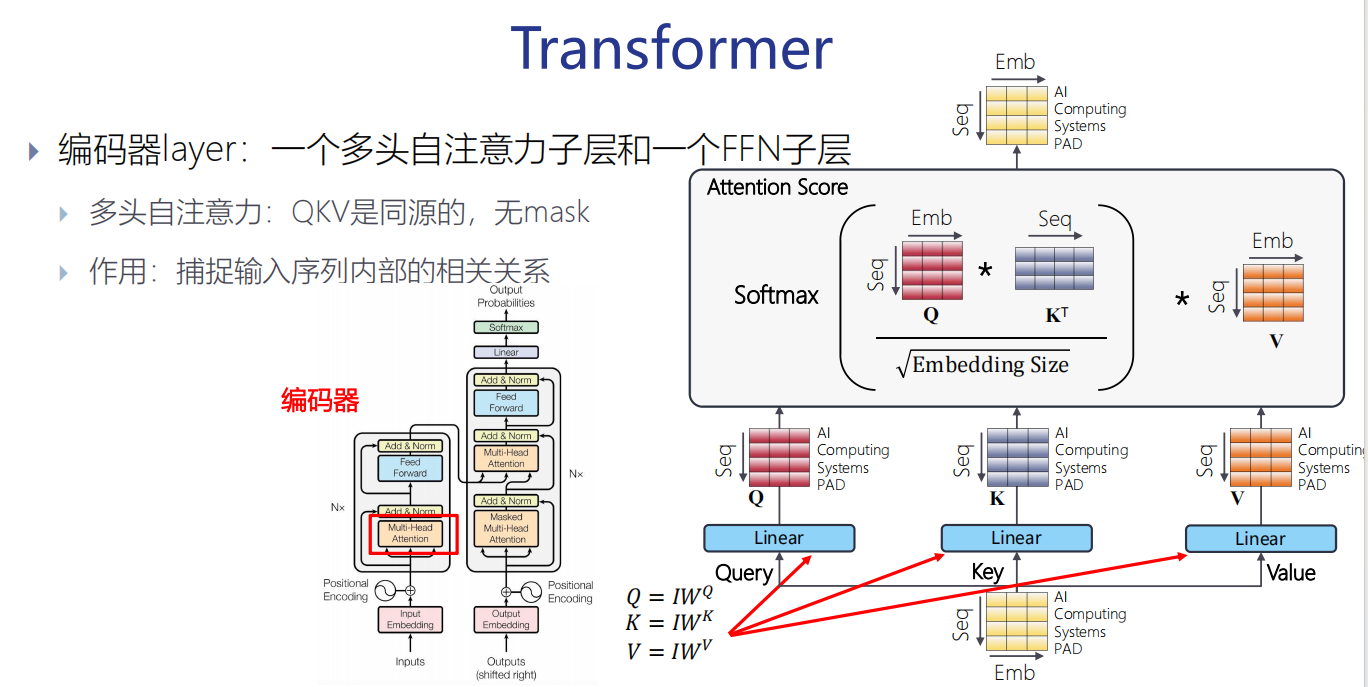
QKV 同源,它们是由同一个矩阵 I 乘以不同的矩阵变换来的。
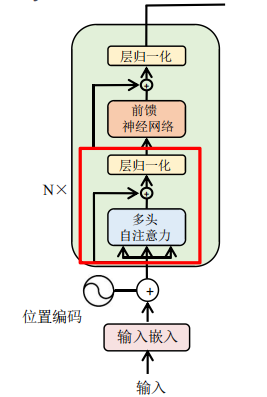
每一个层都有残差连接(residual connection)和层归一化(layer norm)
先计算residual,再计算layer norm
residual connection(残差连接)

问题: 增加层数后,训练误差和测试误差都上升 但构造一个较深的模型,模型优化后, 较深模型的结果应该不会比较浅模型差 ,说明是没有优化好,不是过拟合
然后为了优化的更好,加了残差连接层。
原来的方法是 直接拟合输出函数H(x)(左1)。
残差学习是引入新的参数,令H(x)=F(x)+x, 引入残差函数 F(x),拟合残差函数F(x)比直接拟合输出函数要容易的多。
残差函数F(x)=H(x)-x。
层归一化(layer norm)

问题:在训练过程中每一层的输入分布随着前一层的参数变化而变化,会导致梯度消失或者梯度爆炸,训练变得困难,需要较低的学习速率和仔细的参数初始化。
Norm的做法:将中间层的输入标准化为均值为0,方差为1的高斯分布
Layer Norm和Batch Norm
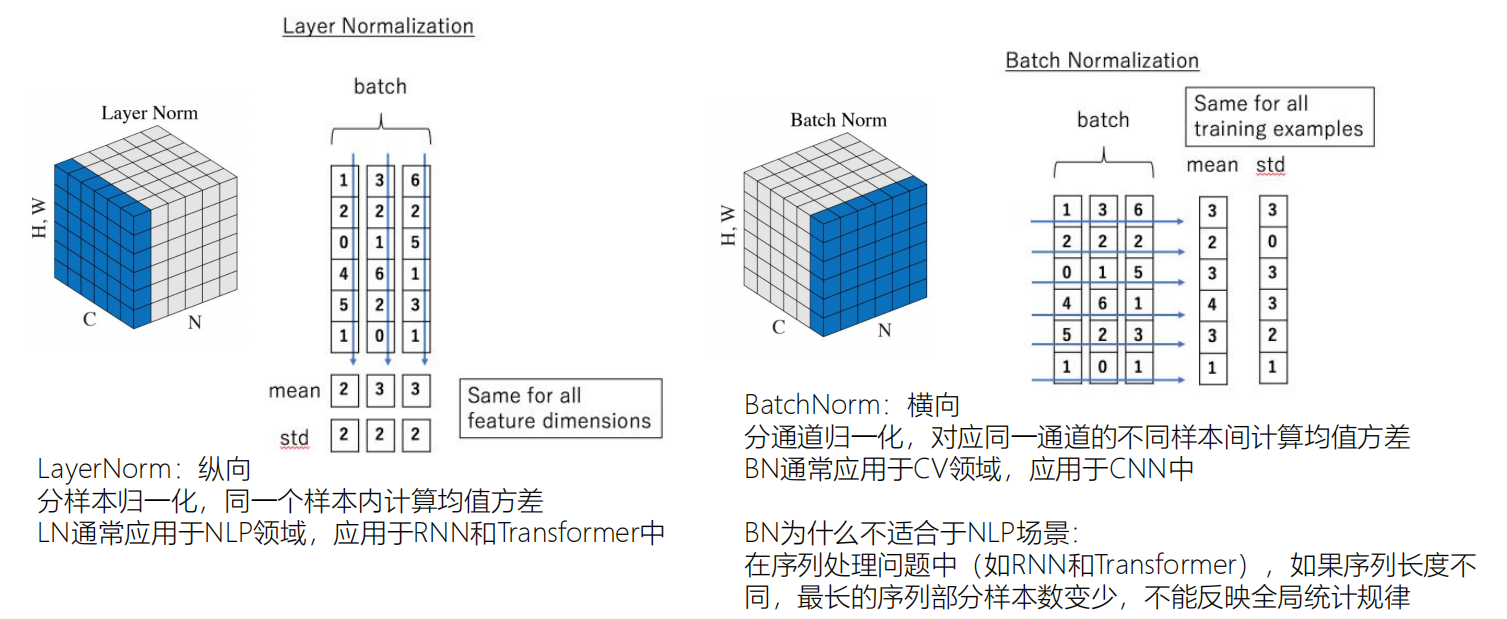
LayerNorm:纵向 ,分样本归一化,同一个样本内计算均值方差。
LN通常应用于NLP领域,应用于RNN和Transformer中。
BatchNorm:横向 ,分通道归一化,对应同一通道的不同样本间计算均值方差
BN通常应用于CV领域,应用于CNN中。
BN是横向的,对同一通道的不同样本间计算均值方差。通常用于处理图像,因为图像会填充,使它们长度相同。但是NLP 文本的话样本的长度可能不同,那样就不方便横向处理了。应该是纵向,同一个样本内计算。
FFN子层(Feed-Forward Network Sublayer)
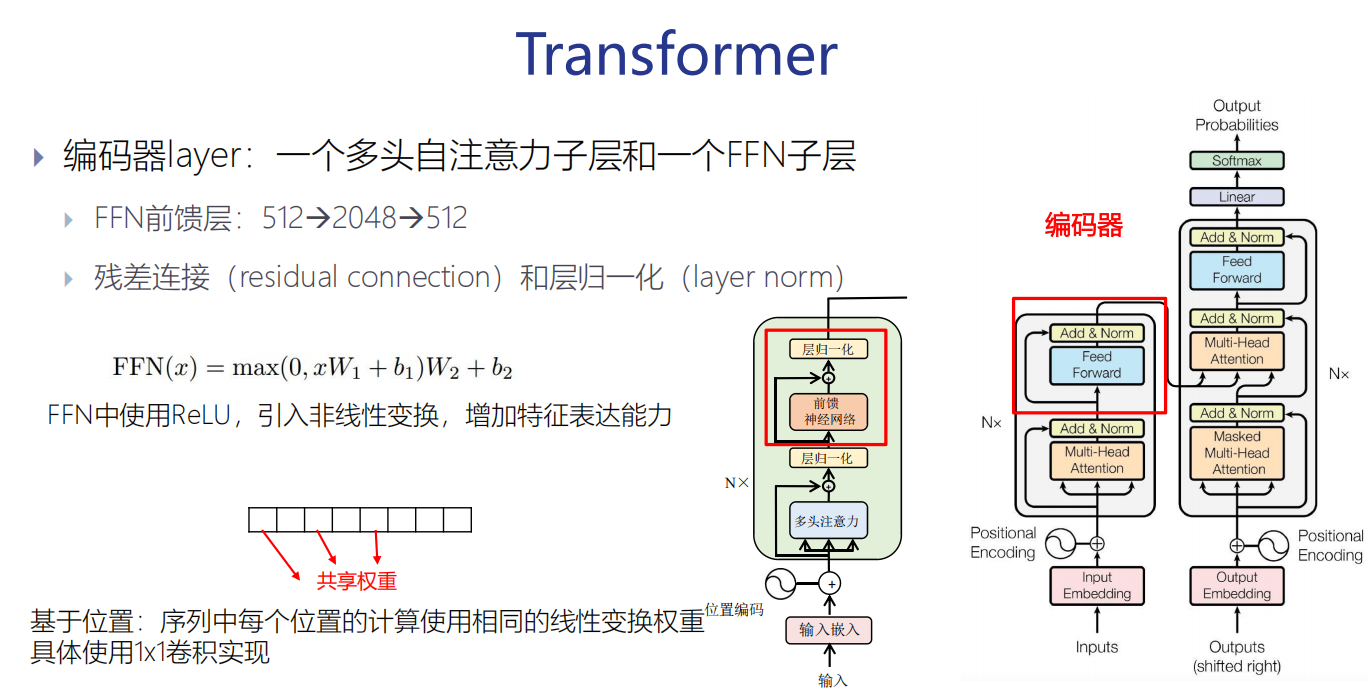
FFN前馈层:低维→高维→低维。
FFN子层(Feed-Forward Network Sublayer)通常由两个线性变换和一个激活函数组成

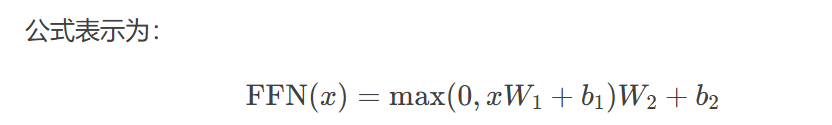
其实是一个序列,这个序列在计算时使用相同的W1和W2,这样就可以用1x1的卷积实现。
主要作用
-
特征变换:增强模型的表达能力。
-
非线性引入:通过激活函数增加非线性,提升模型拟合能力。
-
维度调整:通过线性变换调整特征维度,便于后续处理。
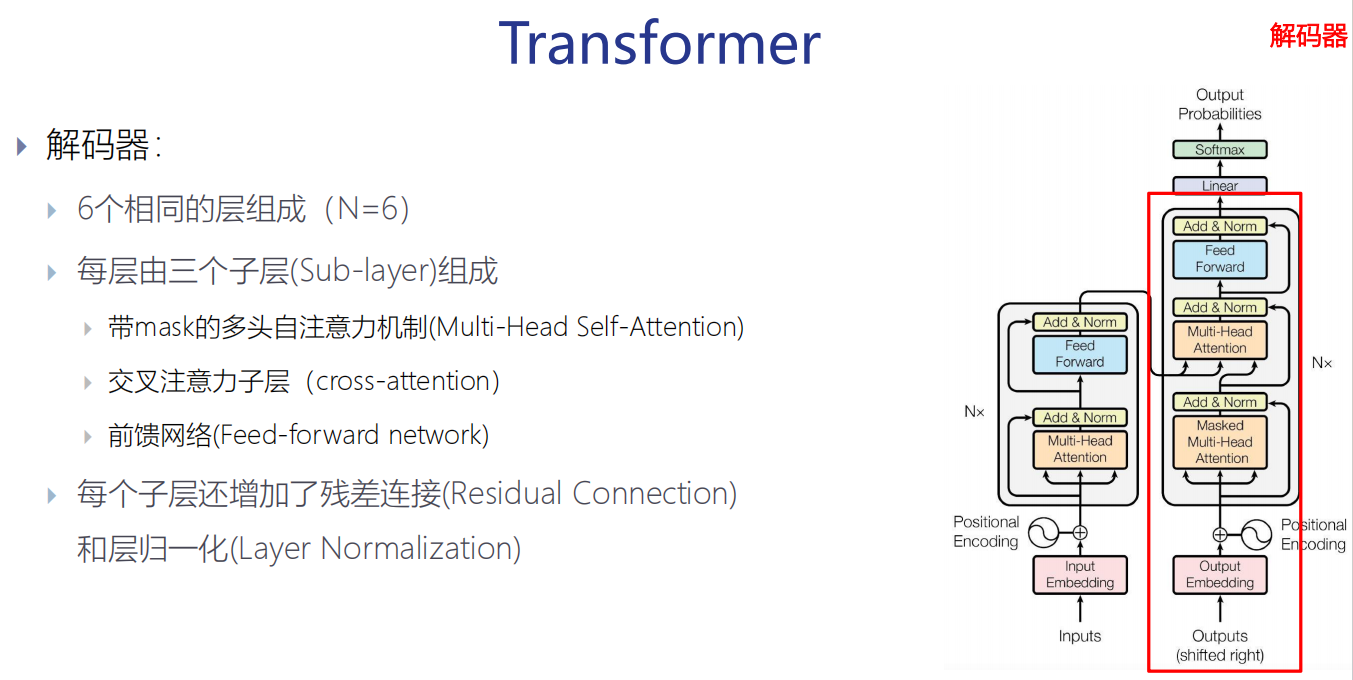
解码器
解码器的输入
解码器的输入: token embedding(shifted right) + position encoding
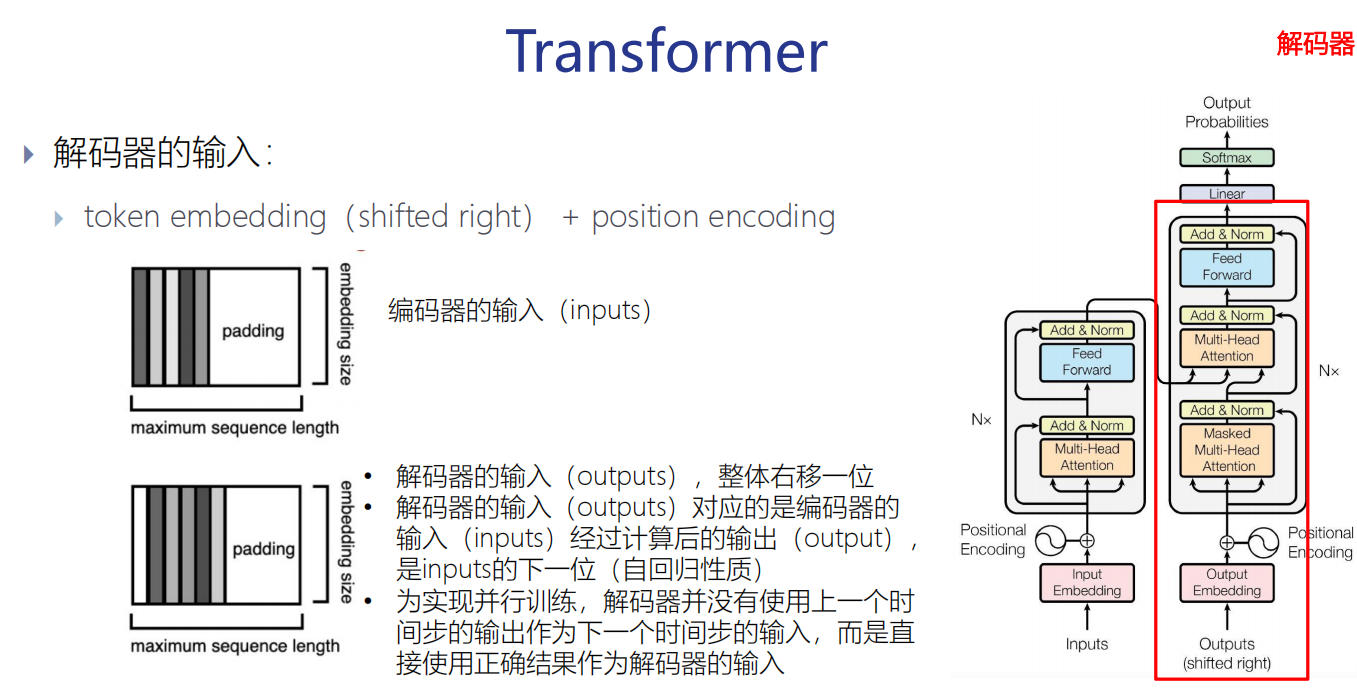
解码器的输入对应的是编码器的输入经过计算后的输出,是inputs的下一位。
为实现并行训练,解码器并没有使用上一个时间步的输出作为下一个时间步的输入,而是直
接使用正确结果作为解码器的输入。
解码器有一个自回归的性质,应该是解码器上一个时间步的输出给到下一时间步的输入,这样就实现了一个自回归。
在训练的时候,如果上一步的输出给到下一步的输入,那么就有一种循环的感觉了,这对训练不友好。为了便于并行训练,直接拿正确的结果作为解码器的输入。(这是训练过程)
为了配合那个过程,所以整体往右移动一位。
自回归:在文本生成中,模型根据已生成的词逐个预测下一个词。
解码器layer
解码器的组成:
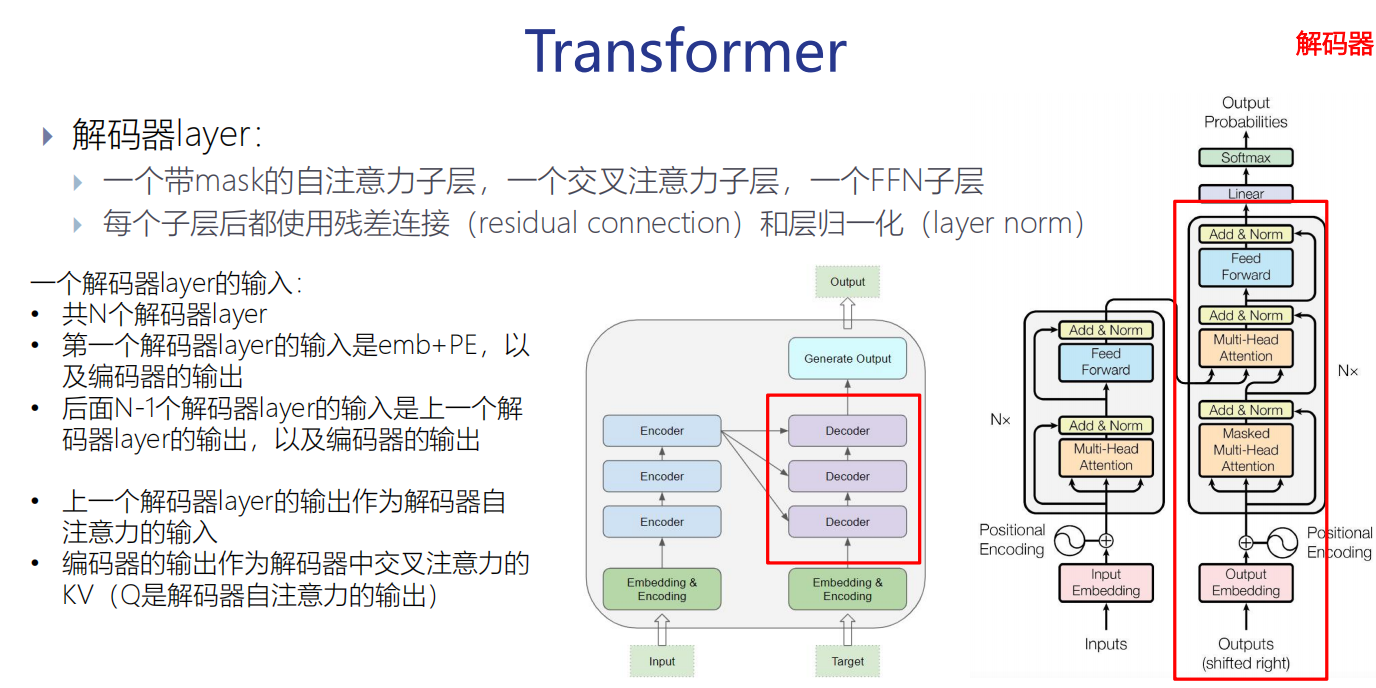
(1)一个带mask的自注意力子层,一个交叉注意力子层,一个FFN子层
(2) 每个子层后都使用残差连接(residual connection)和层归一化(layer norm)
一个解码器layer的输入:
(1) 第一个解码器layer的输入是emb+PE,以及编码器的输出
(2)后面N-1个解码器layer的输入是上一个解码器layer的输出,以及编码器的输出
解释:
(1)上一个解码器layer的输出作为解码器自注意力的输入
(2)编码器的输出作为解码器中交叉注意力的KV(Q是解码器自注意力的输出)
编码器的输出会给到解码器的每一层。
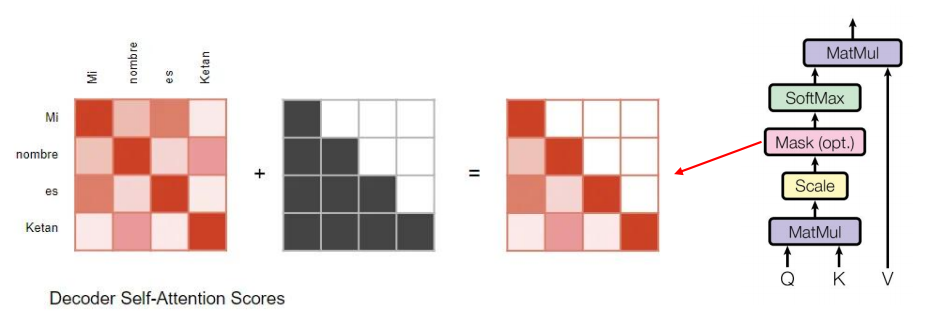
带mask的自注意力子层
带mask的自注意力子层:
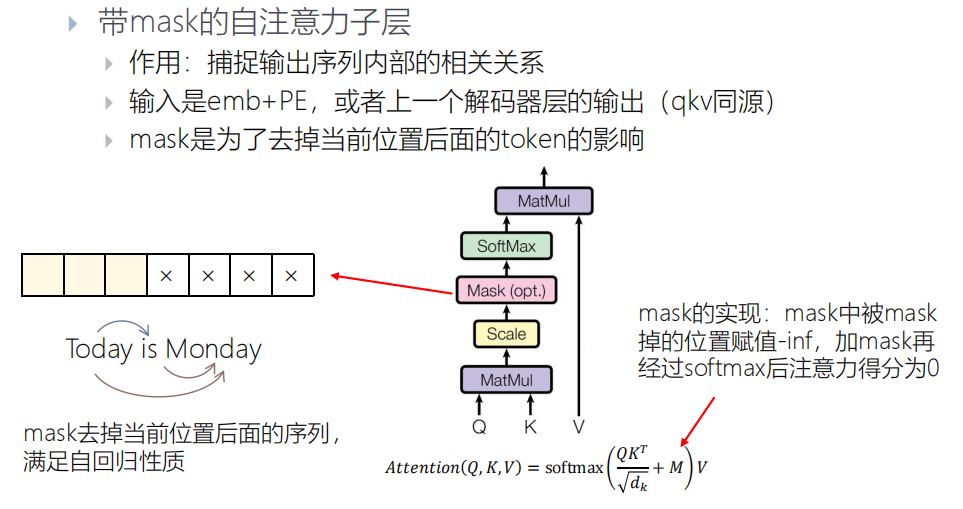
mask,去掉当前位置后面token的影响,是为了满足自回归的属性
自回归:用前面序列去预测后边的序列
mask的实现:mask中被mask掉的位置赋值为负无穷,在经过softmax后,后面就是一堆0
交叉注意力子层
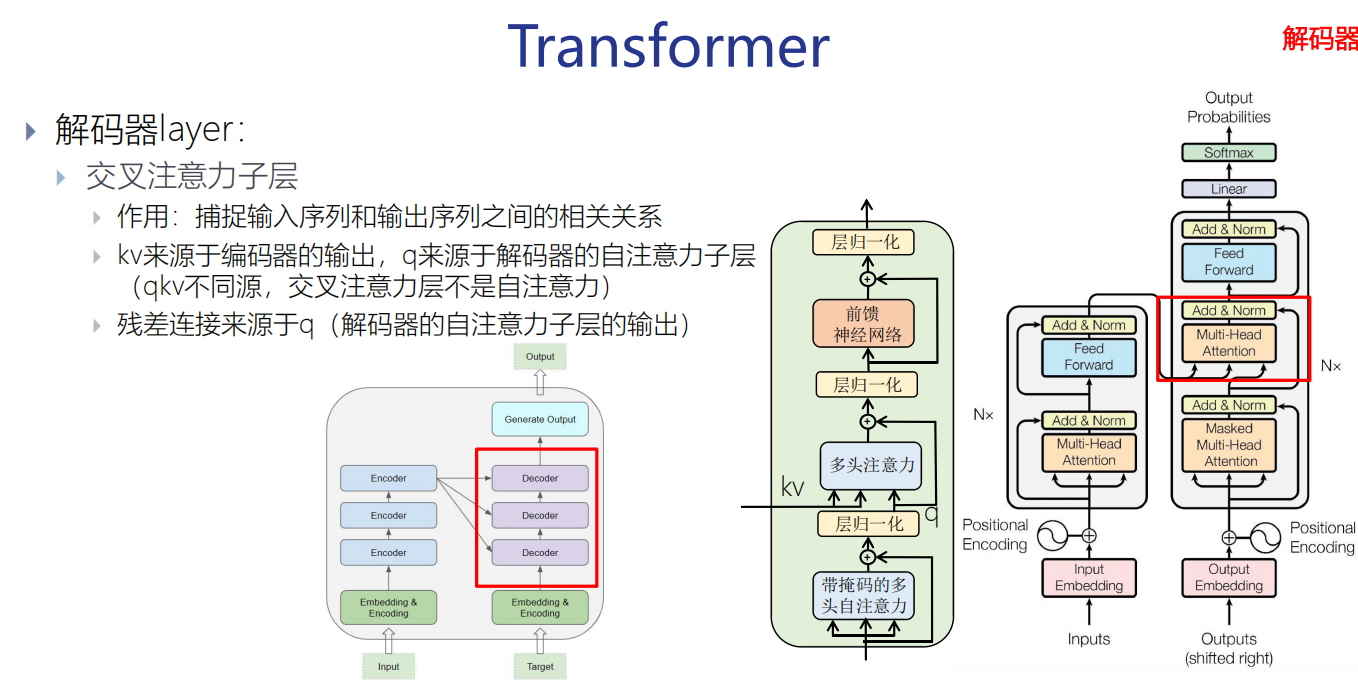
交叉注意力子层:KV来源于编码器的输出,Q来源于解码器的带mask的自注意力子层。【Q来源于前边的子层(带mask的自注意力子层)】
注意,这里可能会考。
KV是成对的,来源相同。Q可以和它们的来源不同。
做多模态的时候,可能会使用交叉注意力层。
再问一下Q K V 的作用?
Q:理解成查询矩阵,要找的东西
K:理解成要和Q做相似度计算的东西,用它来算出权重
V:真正输入的信息,最后用权重对Vi加权求和得到output。
Transformer中各种注意力机制的关系
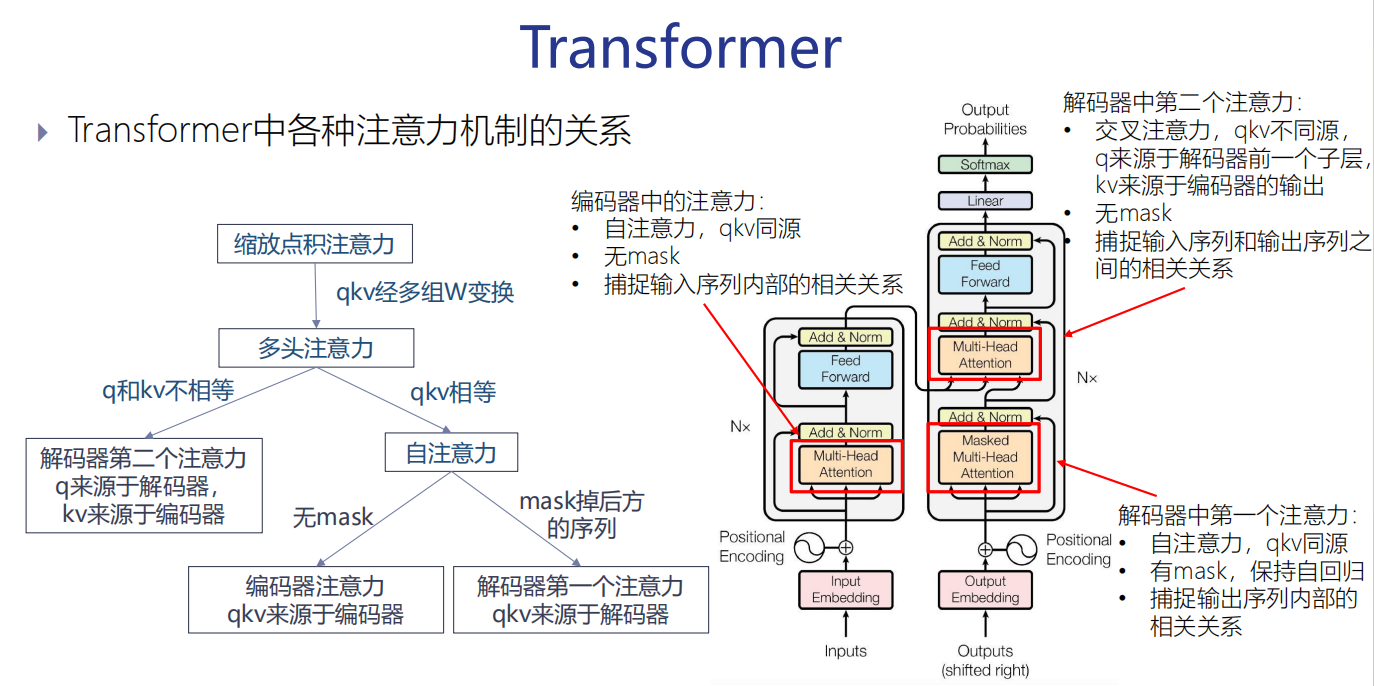
各种注意力机制的关系:
首先看 如果QKV同源,那么就是自注意力,没有mask的就是encoder用的,有mask的就是decoder用的。 Q KV不同源那么就是交叉注意力。Q来源于前边的子层(带mask的自注意力子层)。
Transformer的输出
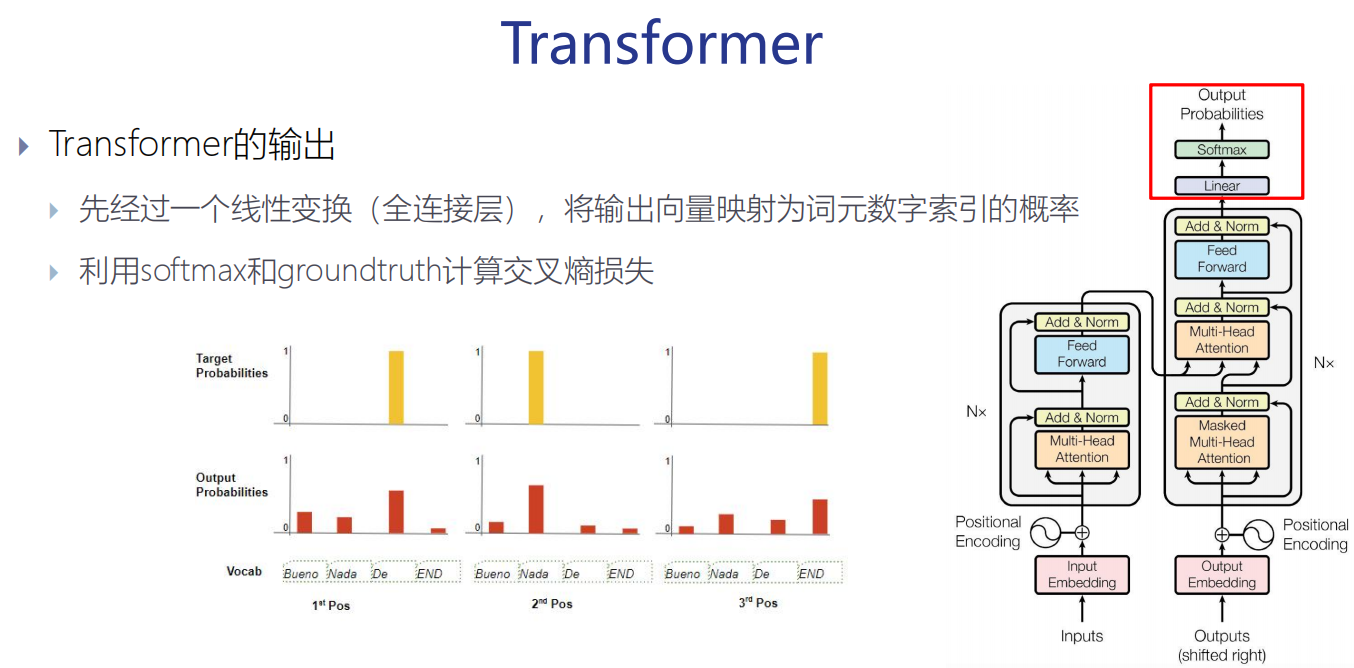
直接结果是一个概率,然后选最大的,最后将其映射成对应的vocab
Transformer的训练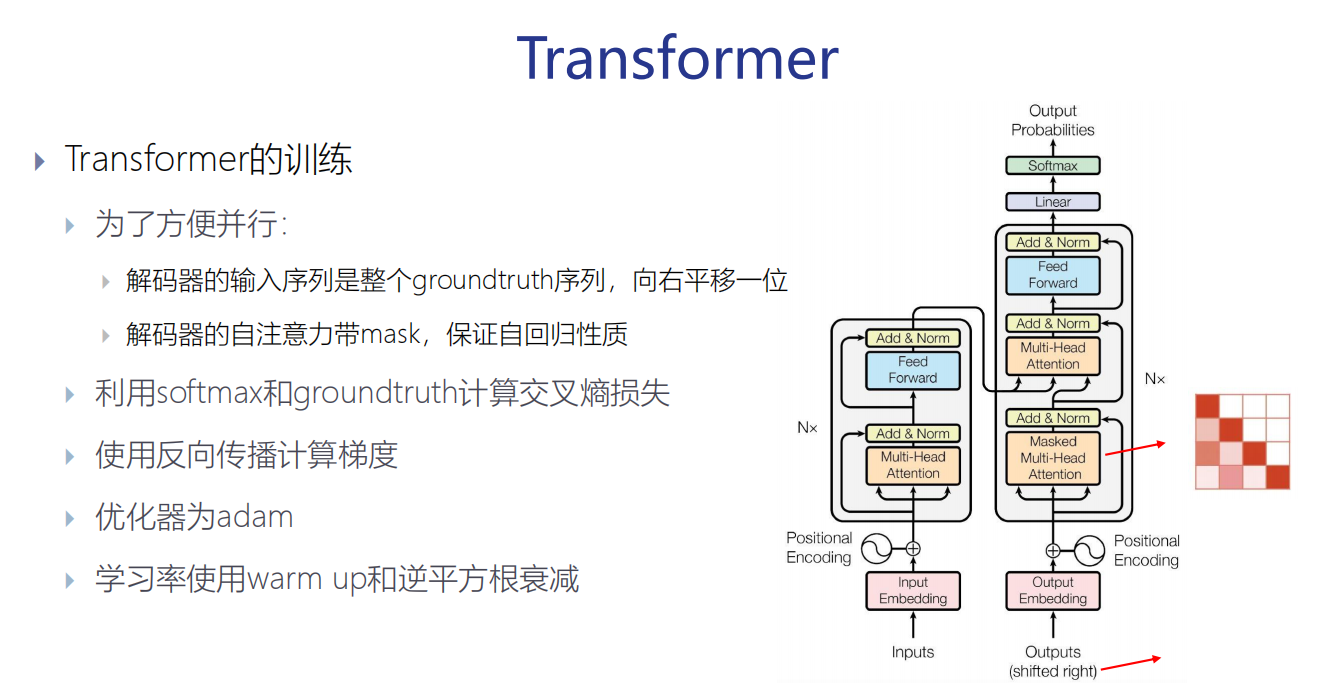
为了方便并行:
(1) 解码器的输入序列是整个groundtruth序列,向右平移一位
(2) 解码器的自注意力带mask,保证自回归性质
(3)利用softmax和groundtruth计算交叉熵损失
(4)使用反向传播计算梯度
(5) 优化器为adam
(6)学习率使用warm up和逆平方根衰减
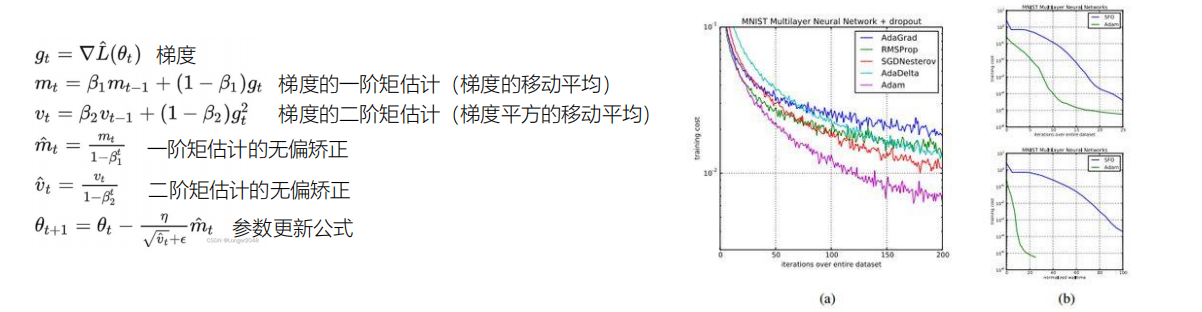
优化器为adam
Adam(adaptive moment estimation,自适应矩估计) :利用梯度的一阶矩估计和二阶矩估计,自适应动态调整每个参数的学习率 。
收敛速度快,训练过程稳定,通用性强。
学习率使用warm up和逆平方根衰减
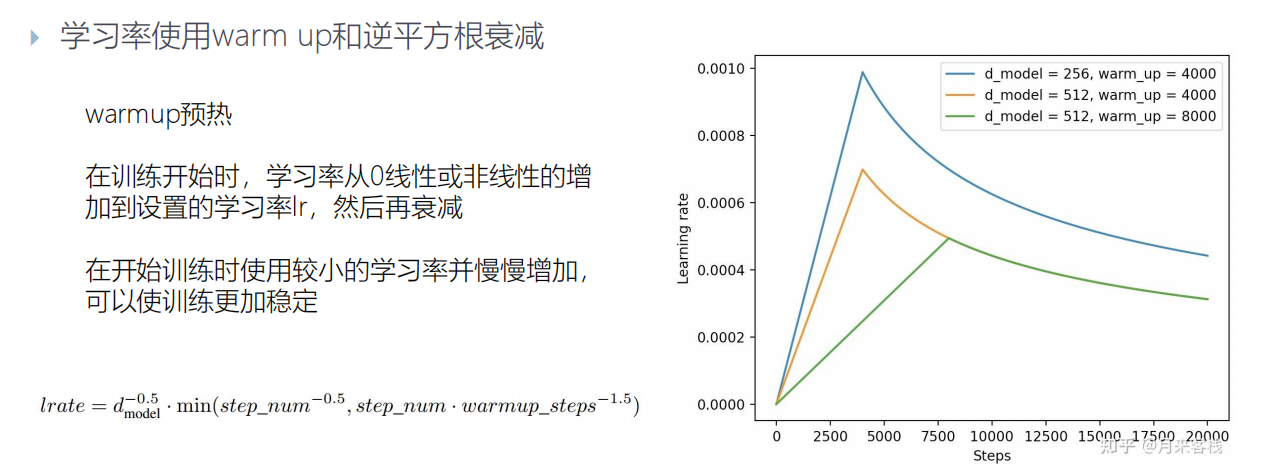
在训练开始时,学习率从0线性或非线性的增加到设置的学习率lr,然后再衰减。
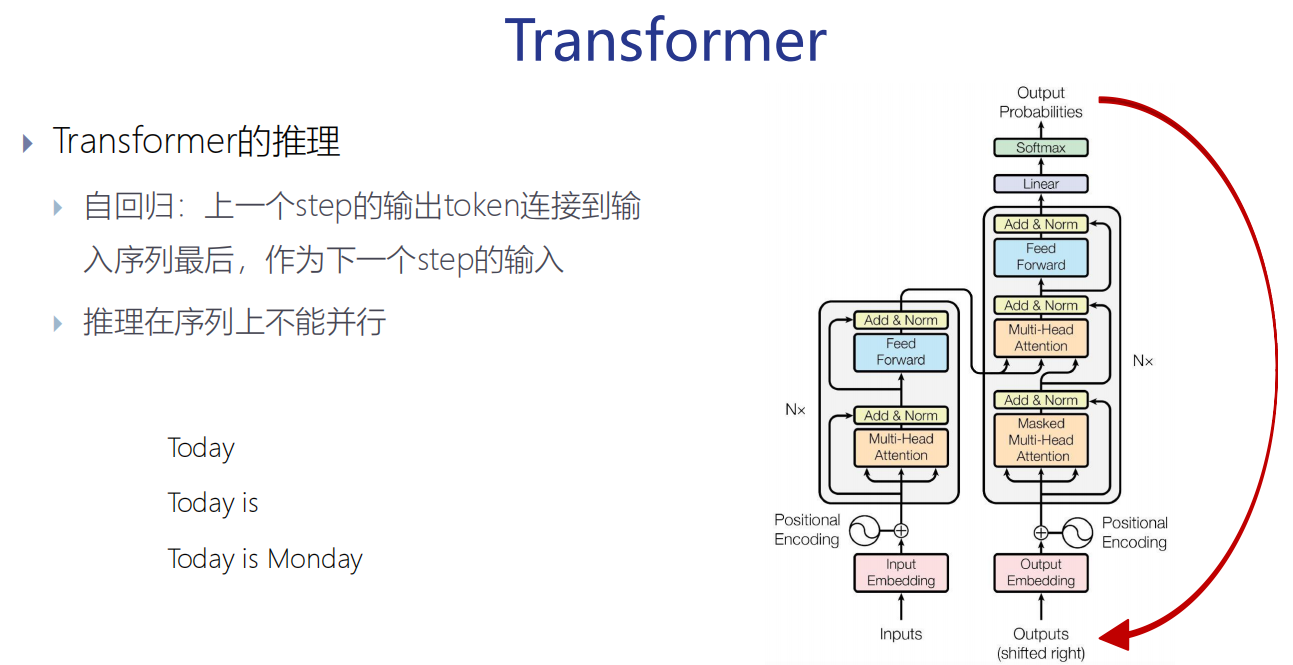
自回归:在文本生成中,模型根据已生成的词逐个预测下一个词。
推理的时候,没有正确结果,所以就是循环着。
(训练的时候,有正确答案,所以是输入正确答案)