随着社交媒体的普及,微博等平台成为了信息传播的重要渠道。然而,虚假信息和谣言的传播也带来了严重的社会问题。因此,自动化的谣言检测技术变得尤为重要。本文将介绍如何基于文本特征,使用深度学习模型(如LSTM、CNN)和传统机器学习模型(如SVM)来实现微博谣言检测,并对这些模型的性能进行比较。
完整项目地址:基于文本特征的微博谣言检测
1. 项目概述
本项目旨在通过分析微博文本内容,自动检测其中的谣言。系统通过预训练的词向量进行文本表示,并使用交叉熵损失函数进行模型训练。项目的主要模块包括:
-
数据预处理:使用
jieba和pkuseg进行分词,去除停用词,并将文本转换为词向量表示。 -
模型定义:定义了LSTM、CNN和SVM三种模型,分别用于谣言检测。
-
训练与测试:实现了模型的训练和测试过程,支持早停机制和模型保存。
-
性能评估:通过准确率、精确率、召回率和F1分数对模型性能进行评估。
2. 数据预处理
数据预处理是谣言检测任务中的重要步骤。本项目使用jieba和pkuseg进行分词,并去除停用词。分词后的文本通过预训练的词向量(如sgns.weibo.bigram)转换为词向量表示。
def jieba_cut(contents):
contents_S = []
for line in contents:
current_segment = jieba.lcut(line)
contents_S.append(current_segment)
return contents_Sdef pkuseg_cut(contents, model_name="web"):
seg = pkuseg.pkuseg(model_name='web')
contents_S = []
for line in contents:
line = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", line)
current_segment = jieba.lcut(line)
contents_S.append(current_segment)
return contents_S
3. 模型定义
本项目实现了三种谣言检测模型:LSTM、CNN和SVM。
3.1 LSTM模型
LSTM(长短期记忆网络)是一种常用的序列模型,能够捕捉文本中的长距离依赖关系。LSTM模型的输入是词向量序列,输出是文本的分类结果(谣言或非谣言)。
class LSTM_Model(nn.Module):
def __init__(self):
super(LSTM_Model, self).__init__()
self.embedding = nn.Embedding.from_pretrained(utils.embedding, freeze=True)
self.lstm = nn.LSTM(input_size=config.embedding_dim,
hidden_size=config.lstm_hidden_size,
num_layers=config.lstm_num_layers,
batch_first=True,
bidirectional=config.lstm_bidirectional,
dropout=config.dropout)
self.fc1 = nn.Linear(config.lstm_hidden_size * 2, config.lstm_hidden_size)
self.fc2 = nn.Linear(config.lstm_hidden_size, 2)def forward(self, input):
x = self.embedding(input)
out, (h_n, c_n) = self.lstm(x)
output_fw = h_n[-2, :, :]
output_bw = h_n[-1, :, :]
out_put = torch.cat([output_fw, output_bw], dim=-1)
out_fc1 = F.relu(self.fc1(out_put))
out_put = self.fc2(out_fc1)
return out_put
3.2 CNN模型
CNN(卷积神经网络)通过卷积操作捕捉文本中的局部特征。与LSTM不同,CNN更适合处理短文本或局部特征明显的文本。
class CNN_Model(nn.Module):
def __init__(self):
super(CNN_Model, self).__init__()
self.embedding = nn.Embedding.from_pretrained(utils.embedding, freeze=True)
self.conv = nn.Conv1d(in_channels=config.embedding_dim,
out_channels=config.cnn_out_channels,
kernel_size=3,
padding=1)
self.pool = nn.AdaptiveMaxPool1d(1)
self.dropout = nn.Dropout(config.dropout)
self.fc1 = nn.Linear(config.cnn_out_channels, config.lstm_hidden_size)
self.fc2 = nn.Linear(config.lstm_hidden_size, 2)def forward(self, input):
x = self.embedding(input)
x = x.permute(0, 2, 1)
conv_out = self.conv(x)
conv_out = F.relu(conv_out)
pooled = self.pool(conv_out)
pooled = pooled.squeeze(-1)
pooled = self.dropout(pooled)
out_fc1 = F.relu(self.fc1(pooled))
output = self.fc2(out_fc1)
return output
3.3 SVM模型
SVM(支持向量机)是一种传统的机器学习模型,本项目通过神经网络的方式实现了SVM模型。SVM模型通过注意力机制和特征增强层提升分类性能。
class SVM_Model(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding.from_pretrained(utils.embedding, freeze=False)
self.attention = nn.Sequential(
nn.Linear(config.embedding_dim, 64),
nn.Tanh(),
nn.Linear(64, 1, bias=False)
)
self.feature_enhancer = nn.Sequential(
nn.Linear(config.embedding_dim, 256),
nn.ReLU(),
nn.Dropout(config.dropout),
nn.Linear(256, 128)
)
self.classifier = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 2)
)def forward(self, x):
embeds = self.embedding(x)
attn_weights = self.attention(embeds)
attn_weights = torch.softmax(attn_weights, dim=1)
weighted = torch.sum(embeds * attn_weights, dim=1)
features = self.feature_enhancer(weighted)
return self.classifier(features)
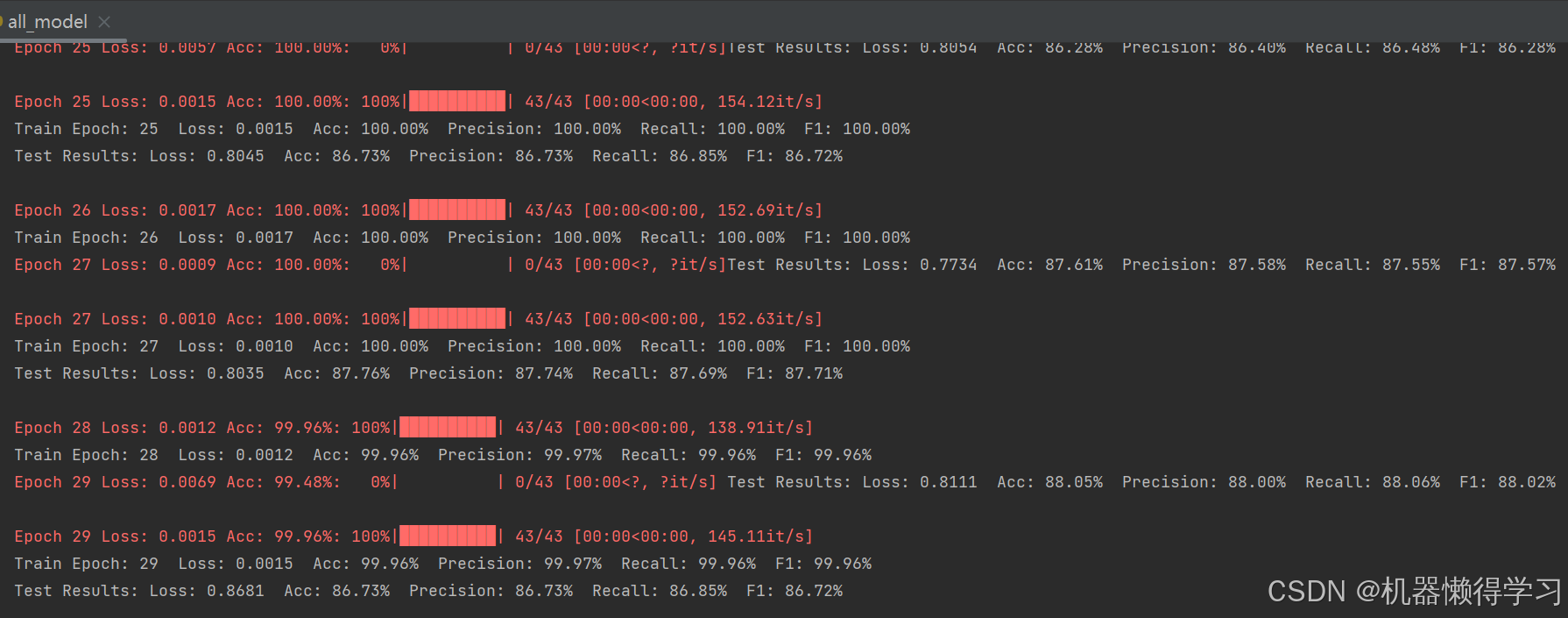
4. 训练与测试
模型的训练和测试过程通过train和test函数实现。训练过程中使用Adam优化器和交叉熵损失函数,支持早停机制和模型保存。
def train(epoch, model, loss_fn, optimizer, train_dataloader):
model.train()
loss_list = []
train_acc = 0
train_total = 0
bar = tqdm(train_dataloader, total=len(train_dataloader))
for idx, (input, target) in enumerate(bar):
input, target = input.to(device), target.to(device)
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
pred = output.argmax(dim=1)
train_acc += pred.eq(target).sum().item()
train_total += target.size(0)
loss_list.append(loss.item())
bar.set_description(f"Epoch {epoch} Loss: {np.mean(loss_list):.4f} Acc: {train_acc / train_total:.2%}")
avg_loss = np.mean(loss_list)
acc = train_acc / train_total
print(f"Train Epoch: {epoch} Loss: {avg_loss:.4f} Acc: {acc:.2%}")
return acc, avg_lossdef test(model, loss_fn, test_dataloader):
model.eval()
loss_list = []
test_acc = 0
test_total = 0
with torch.no_grad():
for input, target in test_dataloader:
input, target = input.to(device), target.to(device)
output = model(input)
loss = loss_fn(output, target)
loss_list.append(loss.item())
test_acc += output.argmax(dim=1).eq(target).sum().item()
test_total += target.size(0)
avg_loss = np.mean(loss_list)
acc = test_acc / test_total
print(f"Test Results: Loss: {avg_loss:.4f} Acc: {acc:.2%}\n")
return acc, avg_loss
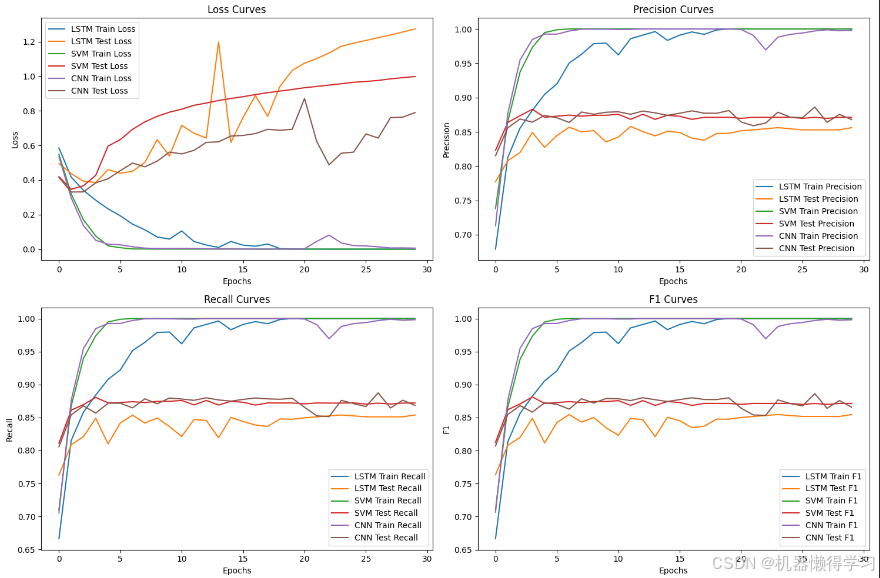
5. 性能评估
本项目通过准确率、精确率、召回率和F1分数对模型性能进行评估。all_model.py中实现了多个模型的训练和测试,并绘制了损失曲线和性能指标曲线。
def plot_comparison_curves(models, train_losses, test_losses, train_precisions, test_precisions, train_recalls, test_recalls, train_f1s, test_f1s):
import matplotlib.pyplot as plt
epochs = range(len(train_losses[0]))
plt.figure(figsize=(15, 10))
# Loss curves
plt.subplot(2, 2, 1)
for i, model_name in enumerate(models):
plt.plot(epochs, train_losses[i], label=f'{model_name} Train Loss')
plt.plot(epochs, test_losses[i], label=f'{model_name} Test Loss')
plt.title('Loss Curves')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# Precision curves
plt.subplot(2, 2, 2)
for i, model_name in enumerate(models):
plt.plot(epochs, train_precisions[i], label=f'{model_name} Train Precision')
plt.plot(epochs, test_precisions[i], label=f'{model_name} Test Precision')
plt.title('Precision Curves')
plt.xlabel('Epochs')
plt.ylabel('Precision')
plt.legend()
# Recall curves
plt.subplot(2, 2, 3)
for i, model_name in enumerate(models):
plt.plot(epochs, train_recalls[i], label=f'{model_name} Train Recall')
plt.plot(epochs, test_recalls[i], label=f'{model_name} Test Recall')
plt.title('Recall Curves')
plt.xlabel('Epochs')
plt.ylabel('Recall')
plt.legend()
# F1 curves
plt.subplot(2, 2, 4)
for i, model_name in enumerate(models):
plt.plot(epochs, train_f1s[i], label=f'{model_name} Train F1')
plt.plot(epochs, test_f1s[i], label=f'{model_name} Test F1')
plt.title('F1 Curves')
plt.xlabel('Epochs')
plt.ylabel('F1')
plt.legend()
plt.tight_layout()
plt.show()
6. 实验结果
通过对比LSTM、CNN和SVM三种模型的性能,我们可以得出以下结论:
-
LSTM模型:在处理长文本时表现较好,能够捕捉文本中的长距离依赖关系,适合处理微博中的长文本谣言。
-
CNN模型:在处理短文本或局部特征明显的文本时表现较好,训练速度较快,适合处理微博中的短文本谣言。
-
SVM模型:虽然SVM是一种传统机器学习模型,但通过神经网络的方式实现后,其在谣言检测任务中仍然具有一定的竞争力,尤其是在小数据集上表现较好。
完整项目地址:基于文本特征的微博谣言检测
7. 总结
本项目实现了基于LSTM、CNN和SVM的微博谣言检测模型,并通过实验对比了它们的性能。实验结果表明,不同的模型在不同的文本分类任务中各有优劣。在实际应用中,可以根据具体的任务需求选择合适的模型。