1.高纬度介绍Transformer
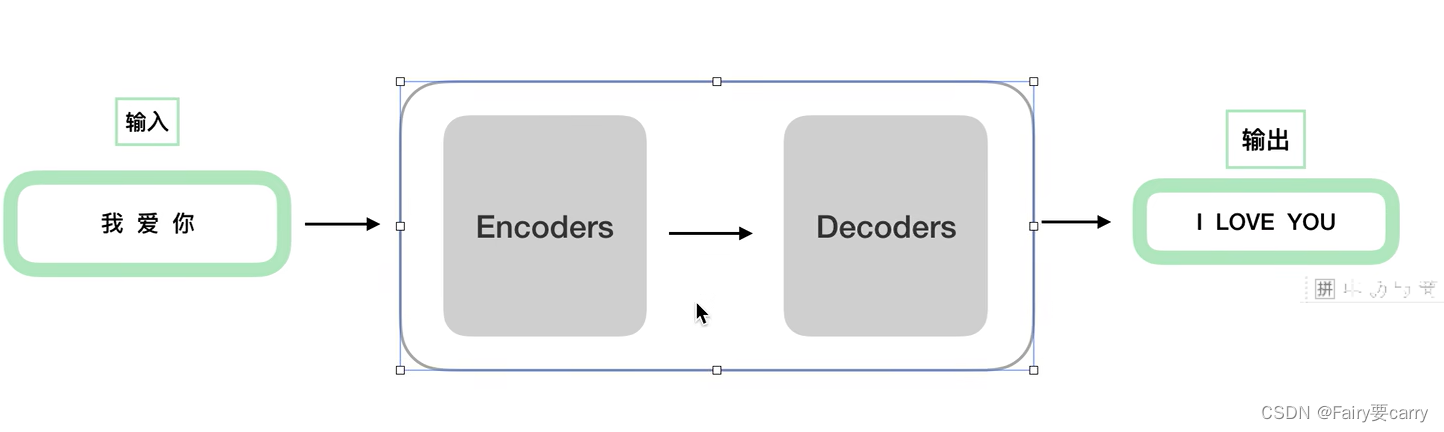
1.分为编码Encoders和解码器Decoders:“我爱你”作为编码器Encoders的输入进行编码得到序列码后,作为解码器的输入得到输出即为,“I Love you”。
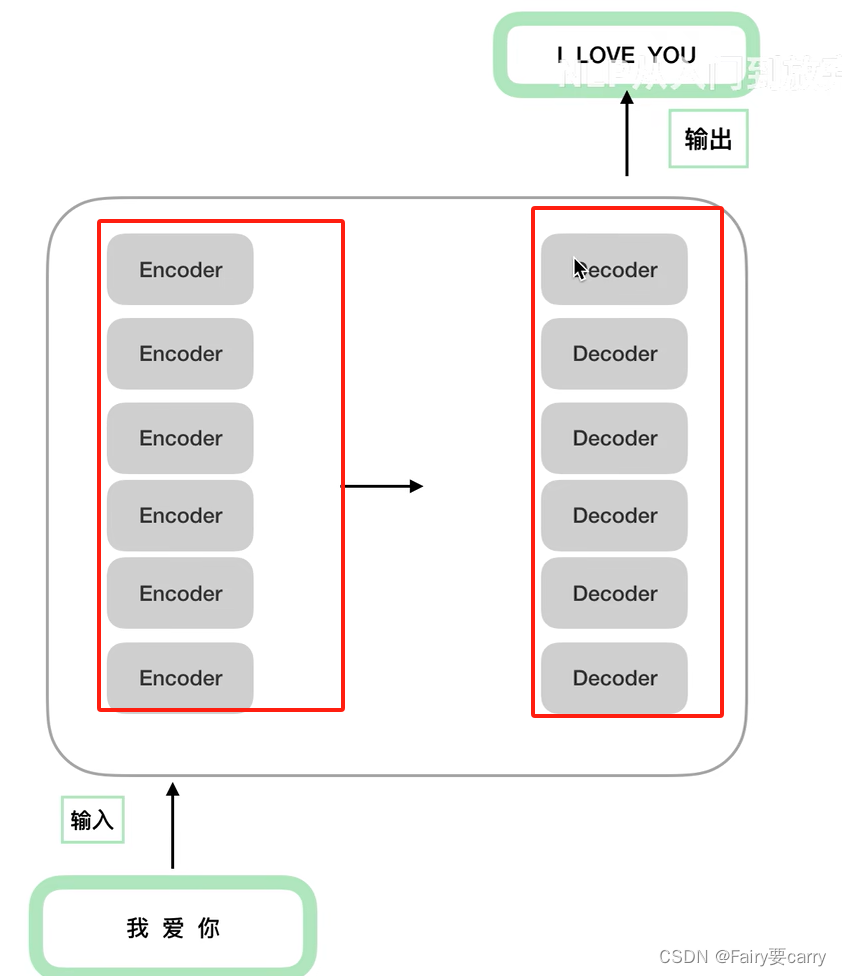
2.编码器和译码器的具体拆分: 左边的编码器Encoders的数量会 x n倍,而右侧的解码器Decoders与左侧同理,即为n相同;在架构方面,编码器数量虽然有 n 个,但是他们各自的参数是不相同的【架构相同,参数不同】,同理解码器亦是如此【类似与CNN】。
2.相关工作
2.1 位置编码详细解读
首先,编码器分为三个部分:1、输入部分【位置嵌入,Embedding】;2、注意力机制;3、前馈神经网络。
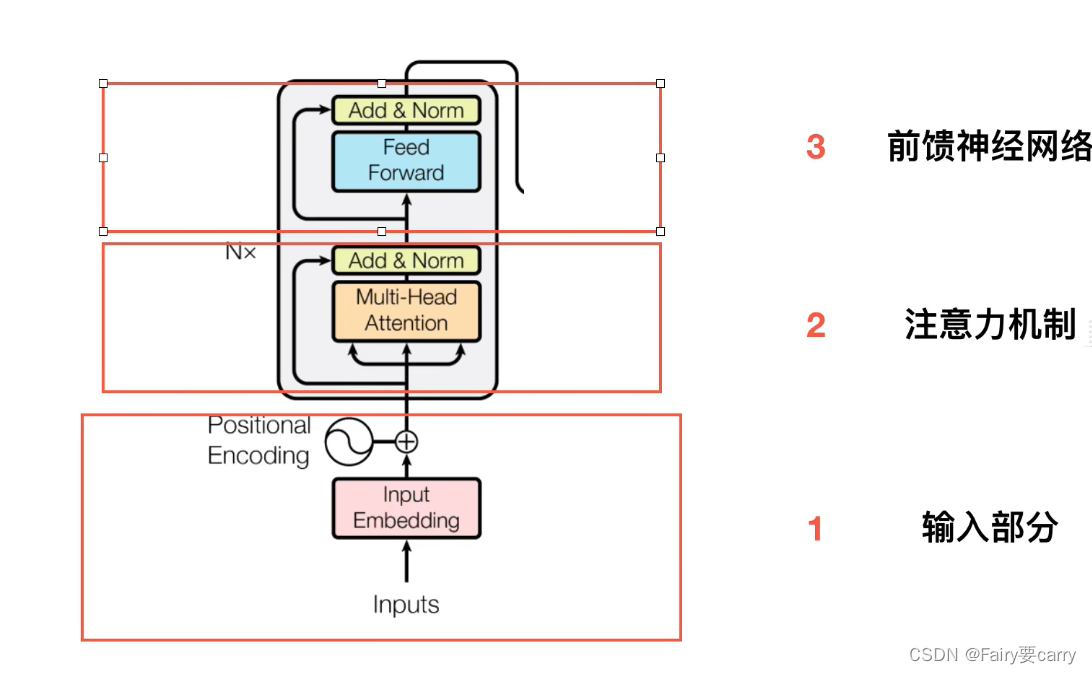
2.1.1 输入部分【Embedding】
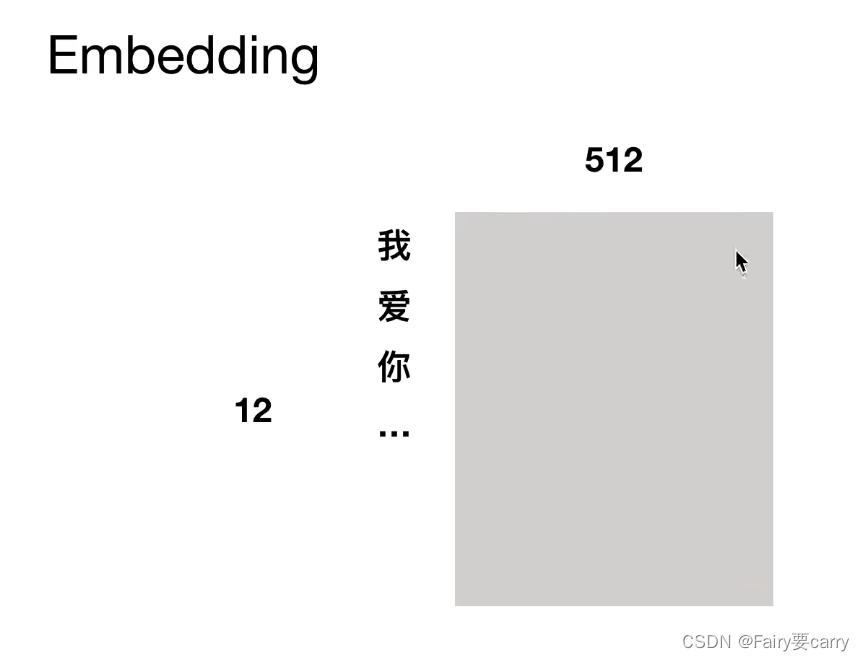
按字切分,每个字对应一个512维度的字向量【随机初始化向量或者vector】
2.1.2 位置编码
1、首先回顾一下RNN:
(为什么RNN共享一套参数?)
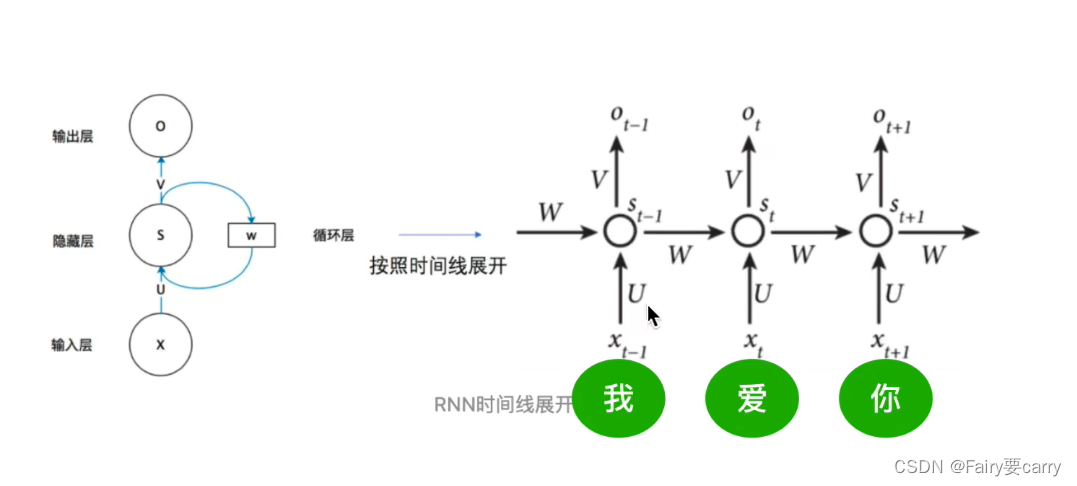
2、RNN的梯度消失跟其他网络的梯度消失有什么不同之处?
总梯度之和被近距离阻挡,被远距离归为0
3、Transformer 处理信息和RNN处理信息的不同之处:
编码器可以并行的处理我们的字,比如 “我爱你” 这三个字他可以一起进行并行处理,相反,RNN他是一个一个字的处理,在时效方面,RNN的效率就要低很多【时效方面】。但在顺序方面,因为Transformer是一起处理的,所以字与字之间的顺序并没有像RNN一样符合明确的序列要求【顺序方面】。
4、因此产生位置编码保证字的顺序
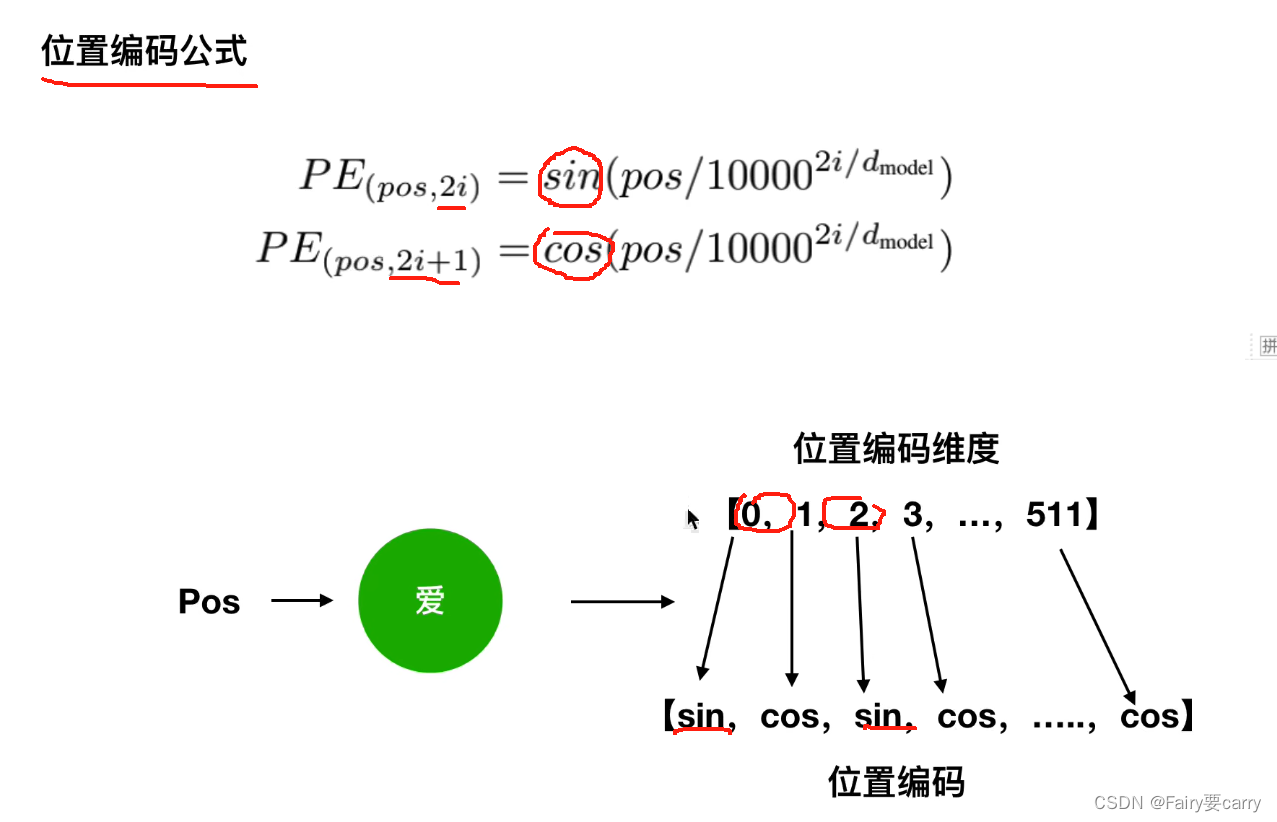
首先会求得该字的位置编码:
然后我们将该字的词向量Embedding与该字的位置编码进行相加,得到:
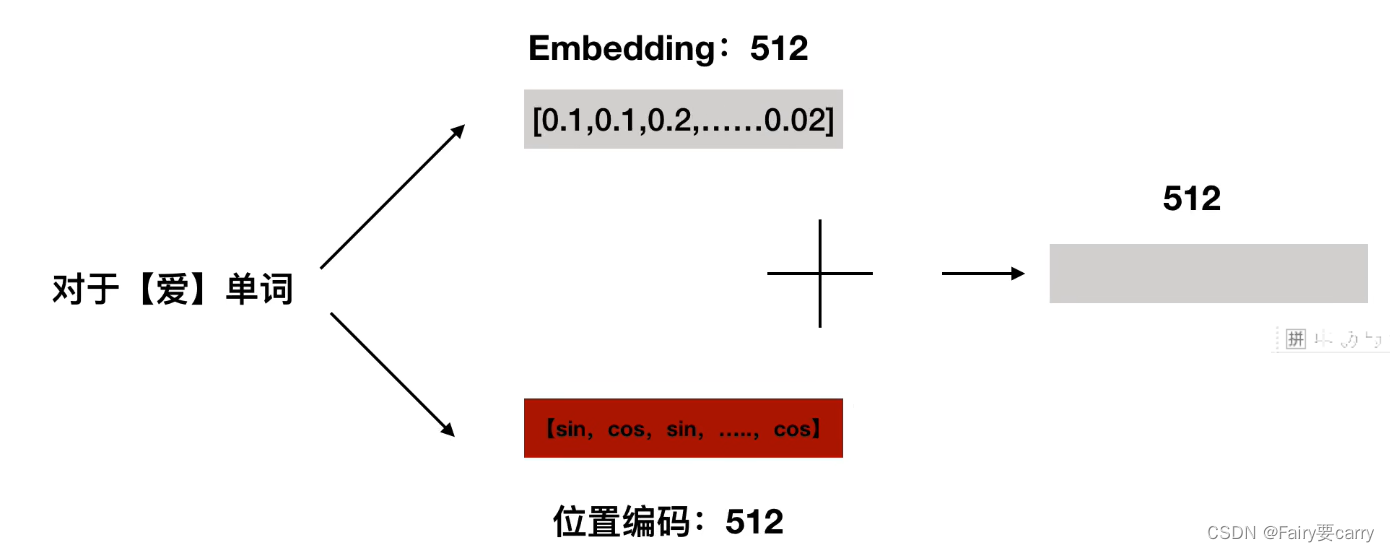
最后得到相加后的内容,作为输入
5、为什么要用位置编码呢?
刚才我们说过,位置编码能够得到词的绝对位置,具体原因如下:
我们利用三角函数性质得到词的绝对位置,得到公式3;
公式3的主要思想是:绝对位置向量信息中蕴含着相对位置向量信息;
比如:“我爱你”,我即为pos,爱即为k,pos+k即为你;

3.自注意力机制
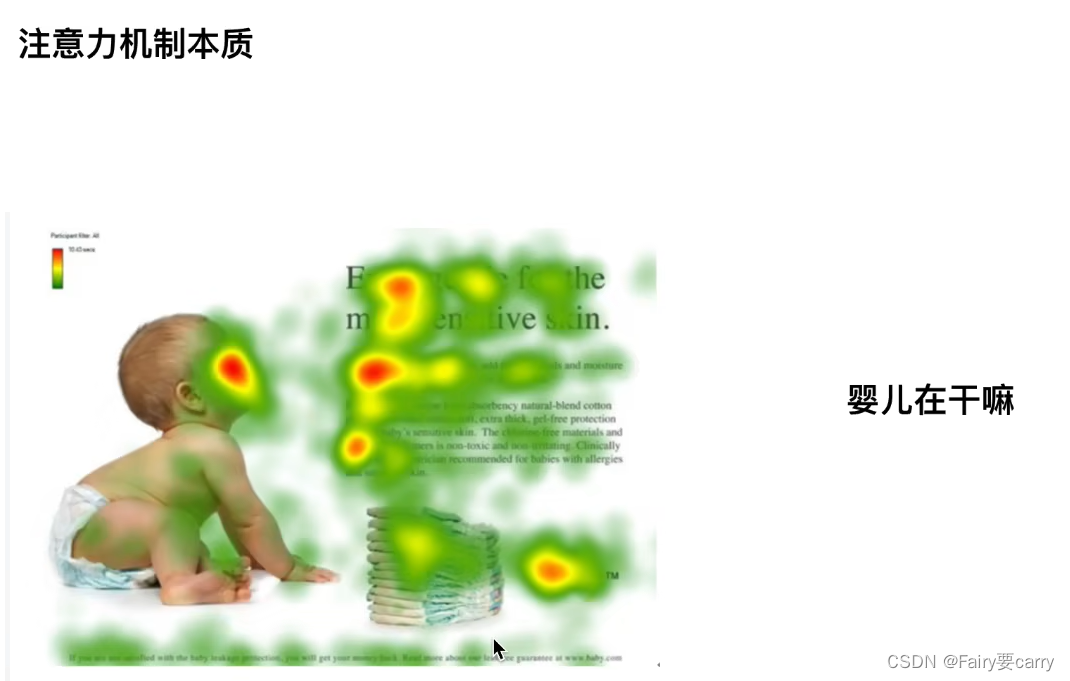
1.目的: 找到最关注哪个区域,哪个区域和我们的目的最相似。
2.公式:
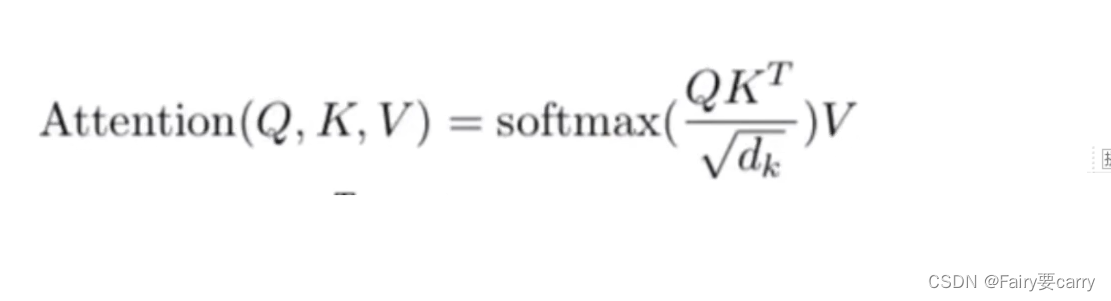
3.为什么要点乘?: 点乘是一个向量在另一个向量投影的长度,它是一个标量【可以反映两个向量的相似度,点乘值越大,相似度越大】
4.如何找到最关注的区域: 通过上面的公式进行计算,Q 是输入【婴儿在做什么?】,K转置是我们的图像上的几个区域【图像区域特征】,进行点积得到的值即为相似度【表示为输入在特征上的投影长度,如果为0表示平行】,比如【0.1,0.3,0.2,0.4】说明关注右下部分,然后再和微矩阵相乘【相当于偏置】;
PCA主成分分析
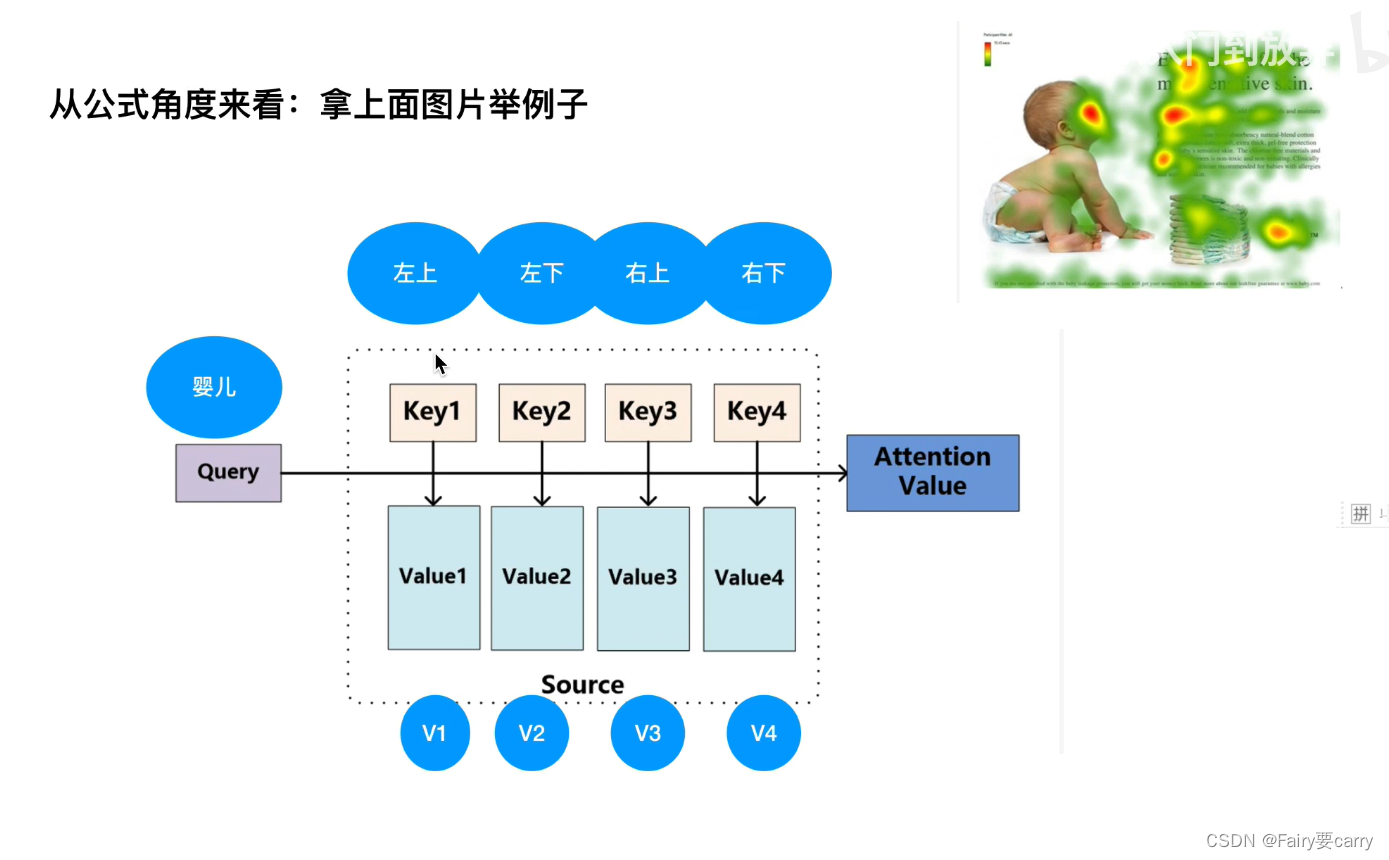
5.从NLP中的角度体现注意力机制:
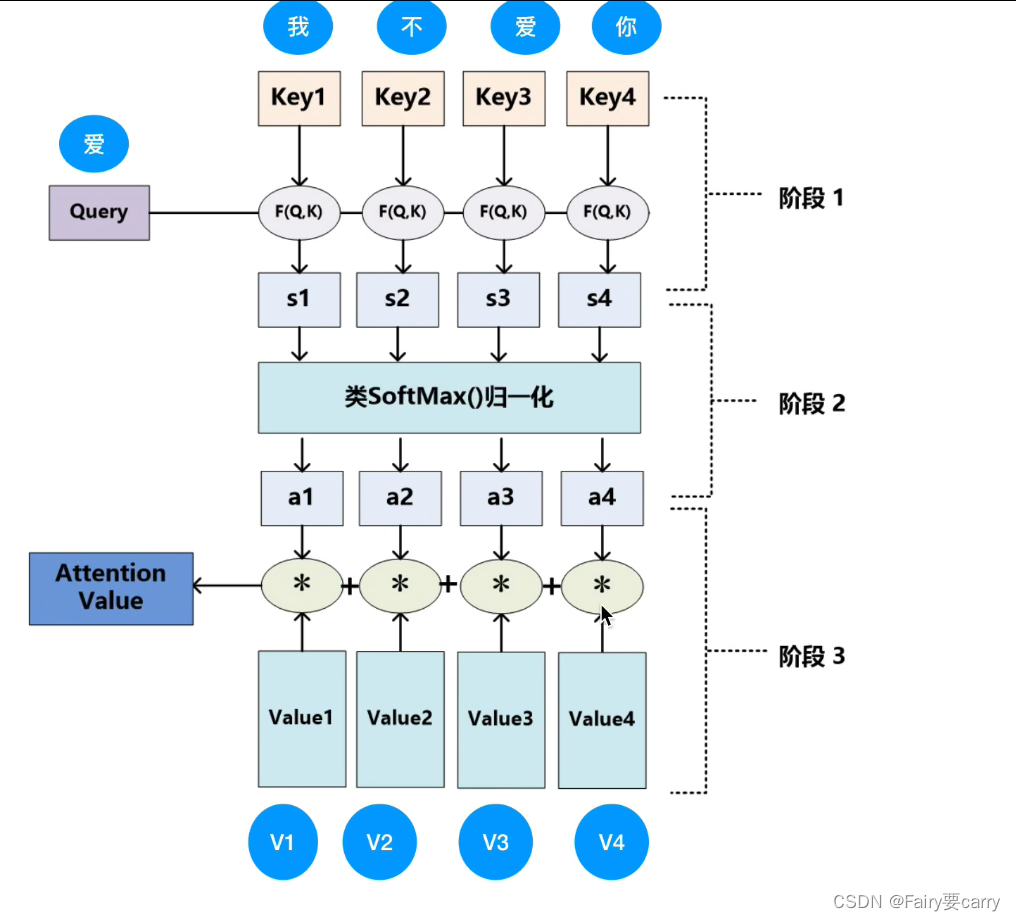
**第一步Query:**通常是指当前需要关注的目标。例如,在翻译任务中,Query可能是当前正在翻译的词或句子的表示。
第二步Key:通常代表输入序列中每个单元(如单词)的表示。在图中,Key1、Key2、Key3和Key4可能代表四个不同单词或短语的向量表示。
**第三步Value(值):**与每个Key相对应的Value 包含了与每个输入单元相关的信息,它们会根据相应的注意力权重被汇总,以产生输出【注意:Values可能与Keys相同(自注意力机制)或者有所不同】。
然后进行点积运算: Query与每个Key做点积计算(F(Q,K)),目的是测量Query与各个Key的相似度【也可以用协同过滤,cos余弦角公式计算相似度】。
接着进行softmax进行计算: 点积计算得到的结果(s1, s2, s3, s4)通过SoftMax函数进行归一化,这样可以得到每个Value的权重(a1, a2, a3,
a4)。SoftMax确保所有权重的总和为1,权重越大表示与Query的相关性越高【概率分布】。
最后进行加权和: 每个Value(Value1, Value2, Value3, Value4)根据其对应的权重(a1, a2, a3, a4)进行加权。然后,所有加权后的Value被加总,形成最终的输出(Attention
Value),这个输出是对输入信息的加权表示,侧重于与Query更相关的部分。
6.Transformer中的注意力集中机制:
6.1 输入Input: 输入通常是文本数据,如一句话或一段文字。
6.2 嵌入Embedding: 嵌入是将这些文本数据转换成数值形式的向量。
6.3 位置编码(Positional Encoding): 由于Transformer完全基于自注意力,因此它本身并不理解词的顺序。因此,为了让模型能够利用词语的顺序信息,输入嵌入会加上位置编码。位置编码通常是一组固定的向量,每个位置有一个唯一的向量,通过数学公式计算得到,与词嵌入相加,使得模型能感知到每个词在句子中的位置。【提供了词汇必要的位置信息,使得模型能够理解输入数据的序列信息】
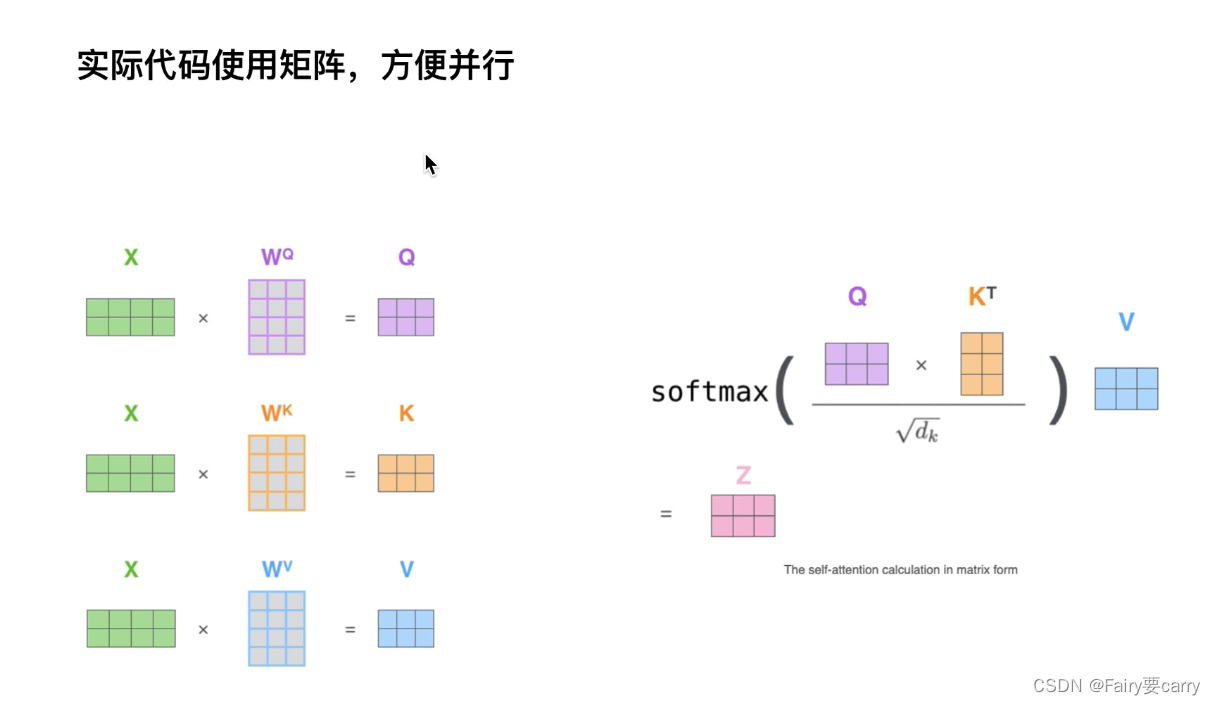
6.4 生成Query,Keys,Value: 经过位置编码的输入嵌入向量接下来会通过三组不同的权重矩阵(分别为 WQ,WK,WV)进行线性变换,从而分别产生Query、Key和Value。【这些权重矩阵是模型训练中学习的参数】
首先明确定义:
1、Query(查询向量)Query向量代表了“请求者”的角色,即它是当前我们想要寻找上下文相关性的基点。Query的目的是从其他输入中找出与当前位置最相关的信息。每个位置的Query都会与序列中的所有Key进行比较。【可以理解为 ‘词’ 的绝对位置】
2、Key(键向量)则代表了“被请求者”的角色,即它是可以被Query查询的对象。每个位置的Key都会与所有位置的Query比较,以确定它们对于每个Query的相关性程度。【可以理解为该‘词’对于其他词的相对位置】
举个例子: 假设我们已经有了每个词的嵌入向量加上位置编码后的结果,这些向量通过不同的权重矩阵 WQ、WK和 WV转换,为每个词生成Query、Key、 Value。具体地说:【The cat sat】
1、“The” 转换后得到 Query1, Key1, Value1;“cat” 转换后得到 Query2, Key2, Value2;“sat” 转换后得到 Query3, Key3, Value3。
2、对于每个词作为Query,计算它与所有Key的点积得分:
Query1 和 Key1, Key2, Key3 的点积得分【比如Query1和key2进行点积得到就是以The为基准和sat的相似度】
Query2 和 Key1, Key2, Key3 的点积得分
Query3 和 Key1, Key2, Key3 的点积得分
3、将每个得分通过Softmax转换为概率,这表明每个词对当前词的重要性:
例如,对于"cat"作为Query,可能发现与"sat"的Key得分最高,说明在这个上下文中"sat"与"cat"关系紧密。
4、接着,用这些Softmax输出的概率去加权对应的Value,得到每个词的加权Value求和:
如果"cat"与"sat"的关系得分高,则"sat"的Value对于"cat"位置的输出贡献更大。

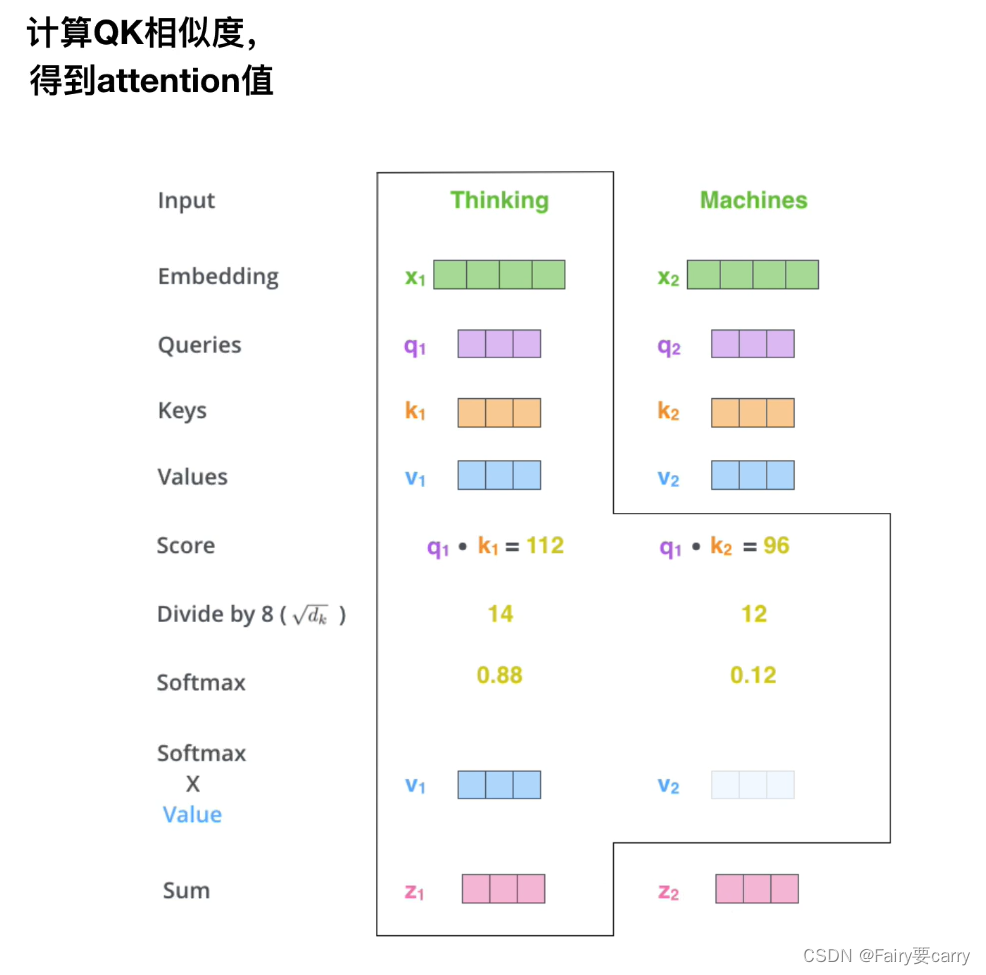
7.为什么在点积计算权重后要除以根号下dk?
**点积大小:**当我们计算Query和Key的点积时,如果两个矩阵维度很大,相乘后的结果也可能很大,因为维度大代表需要累加的项数就会很多,数值就会很大。
**数据稳定性:**当较大的点积值输入到softmax函数中,就可能导致数值稳定性的问题,比如梯度消失或者梯度爆炸。Softmax函数对于其输入非常敏感,极端的输入值会使得梯度传递变得困难。因此我们要维护输出的数值大小以缓解梯度消失/爆炸的问题。
维持输出尺度: 通过除以根号下dk,调整点积的规模,使其不因为Key和Query的维度变化而改变太多。这样可以保持模型在不同设置下的表现一致性。【dk为Key向量维度】
**理论依据:**这种缩放方法有理论支持。从概率角度看,向量中的元素通常假定为独立同分布,它们的方差为1,那么它们点积后的方差就是dk,除以根号下dk就能使方差控制到1左右,避免方差太大带来的数值问题。模型的训练更加稳定,能够更快地收敛,并且在多种任务上表现更好。
为什么要保持方差为1?
8.对于Transformer自注意力机制的总结:
问题: 比如Fairy Carry,根据Fairy输入找到相关单词,Q1,K1,V1为Fairy经过三个矩阵得到的值,Carry同理得到Q2,K2,V2,然后我们计算Fairy和carry的相似度,也就是上述公式:Q1与K2进行点积除以根号下K2的维度*权重得到概率值,这样理解有问题吗?另外这样算的话是不是需要抛去本身呀?比如Fairy。

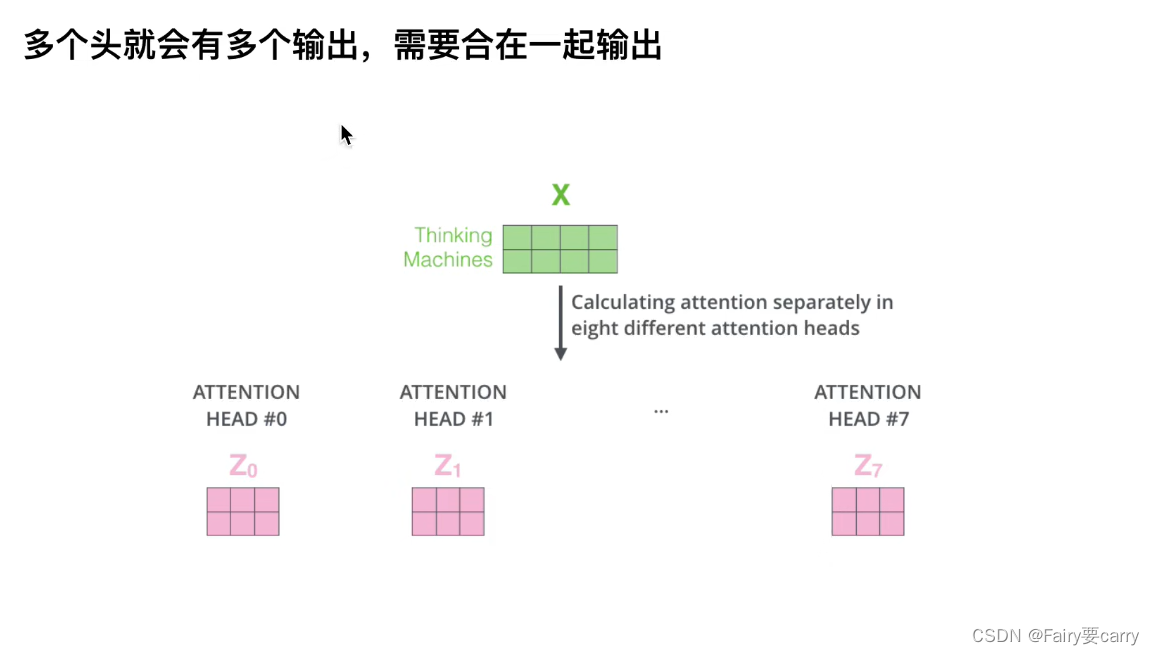
4.多头注意力机制
目的: 每个头可以关注不同的方面,比如一个头关注句子的语法结构,另一个头可能关注语义内容,最后合并。
输入X: 输入是一些词的嵌入向量,比如这里可能是一个句子中的词向量。
注意力头#0: 使用权重矩阵W0Q,W0K,W0V分别对输入X进行变换得到Q0,K0,V0【绝对Q,相对V,权重偏置V】
注意力头#1: 使用权重矩阵W1Q,W1K,W1V都得到Q1,K1,V1
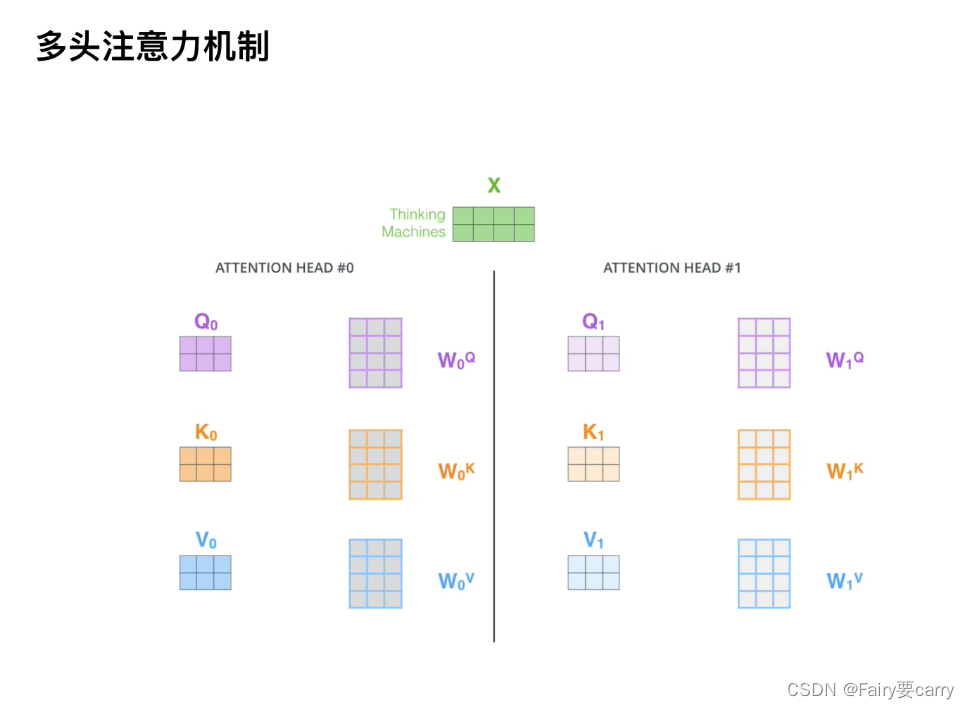
合并输出: 最终的输出是通过将所有注意力头的输出 𝑍 合并。【通常是通过拼接后再通过一个线性层来形成一个单一的输出表示】
【PS:在多头注意力机制中,不同头的输出通过拼接而不是简单相加,而是拼接向量,使其包含了所有头中信息的完整表示】