本文将要介绍的文献主题为浮点存内计算,题目为《A 16nm 96Kb Integer/Floating-Point Dual-Mode-Gain-CellComputing-in-Memory Macro Achieving 73.3-163.3TOPS/W and 33.2-91.2TFLOPS/W for AI-Edge Devices》,下面本文将从文章基本信息与背景知识、创新点解析和现有工作对比三个方面进行论文详解。
一.文章基本信息[1]
(1)研究团队:
台湾台积电,台湾国立清华大学,台湾工业技术研究院。
(2)研究背景:
当前先进的AI边缘芯片需要计算灵活性和高能效,并对推理精度提出了更高的要求。浮点(FP)数值表示可用于需要高推理精度的复杂神经网络,然而,这种方法比定点整数(INT)数值表示需要更高的能量和更多的参数存储。目前许多存内计算(CIM)架构针对 INT乘累加运算(INT-MAC)具有良好的能效,然而很少能够支持FP乘累加运算(FP-MAC)。因此,开发既支持INT又支持FP运算且能有效应对上述挑战的计算架构变得尤为重要。
(3)面临挑战:
FP运算可支持需要高精度的复杂神经网络,但是通常需要更多的功耗,特别是在高密度存储单元内进行计算时,如何有效管理能耗和散热已成为一个关键科学问题。此外,FP运算提出更多参数存储需求,而随着大模型技术的发展,神经网络本身也需要越来越多的参数存储需求,因此FP存算的网络部署面临着空间和资源不足的挑战。
在本文介绍的文献中,研究团队实现INT/FP双模(DM)乘累加操作(MAC)时,主要面临以下挑战:
①低面积效率:在执行INT-MAC操作期间,FP-MAC功能会闲置,导致资源未充分利用;
②高系统级延迟:小容量SRAM-CIM在没有同时写入与计算功能的情况下,神经网络数据更新中断会导致延迟增加;
③高能耗:计算过程中系统到CIM架构的频繁数据传输增加了能耗。
(4)本文工作:
为了解决上述面临挑战,研究团队提出了一种INT/FP DM宏结构,简要概括如下:
①DM区域输入处理方案(ZB-IPS):消除指数计算中的减法,并在INT模式下复用对齐电路,从而提升能效比和面积效率;
②DM本地计算单元(DM-LCC):复用指数加法作为INT-MAC中的加法树阶段,进一步提高INT模式下的面积效率;
③基于静止的双端口增益单元阵列(SB-TP-GCA):支持数据的同时更新与计算,减少系统到CIM架构及内部数据访问,从而改善能效和降低延迟。
- 相关名词解释:
①FP:Floating Point,浮点数。浮点数由三部分组成:符号位、指数部分、尾数部分,根据这三部分的不同,浮点数具有多个种类,其中FP32和FP16是常用的浮点数类型。FP32如图1所示,一共有32bit,符号位为1bit、指数位8bit、尾数位23bit,提供了较高的精度和动态范围,适用于大多数科学计算和通用计算任务;FP16如图2所示,一共有16bit,符号位为1bit、指数位5bit、尾数位10bit,相对于FP32提供了较低的精度,但可以减少存储空间和计算开销,主要应用于深度学习和机器学习等计算密集型任务[2]。

图1 FP32位数组成[2]
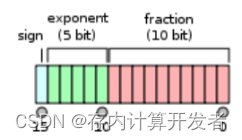
图2 FP16位数组成[2]
②INT:Integer,整数。INT8表示8位整数,是常用的整数类型,使用8bit内存来存储每个数值,最高位代表符号位,可以表示范围从-128到127的整数。主要用于对图像、音频等进行量化处理,以减少计算量和存储需求。
③MAC:Multiply Accumulate,是在数字信号处理器或一些微处理器中的特殊运算,具体是将乘法器乘积结果输入累加器,累加器再将几个周期的乘积相加。
④BF:BF16指的是一种16位宽的浮点数据类型,全称为Bfloat16。这种数据类型由Google的TensorFlow团队提出,用于优化深度学习模型的性能,近年来在深度学习和高性能计算领域受到越来越多的关注,因为它在保持良好的数值范围的同时,减少了数据的位宽,从而可以提高计算速度和降低功耗。它包含:1位符号位(Sign bit)、8位指数(Exponent)、7位尾数(Mantissa)。与传统的IEEE 754标准的单精度浮点数(FP32)相比,FP32有1位符号位、8位指数和23位尾数。尽管BF16的尾数较短,但它保持了与FP32相同的指数范围,这意味着它在表示数值的范围上与FP32相当,但在精度上有所降低。
二.本文主要工作
1.双模CIM(DM-CIM)的结构与数据流
本文创新性的提出了面积利用率更高的双模CIM结构和数据流,可以支持整型数INT8和浮点数BF16两种模式的计算。相比于传统的双模CIM结构,传统双模CIM在进行INT计算时的exp加法器与对齐电路处于闲置状态,使得芯片面效与面积利用率较低。在本文的工作中,INT模式下DM-ADD结构充当2*NACCU的加法器树,并利用对齐电路作为输入稀疏感知电路(INAC),极大的提升了INT模式下的能效与面效。

图3 传统双模CIM在INT模式下存在资源闲置
双模CIM包括基于DM区域的输入处理单元(ZB-IPU)、DM-GC计算阵列(DM-GCCA)、数字移位加法器(DSaA)和时序控制器(CTRL)。其中的DM-GCCA由64个GC计算模块(GC-CB)组成,每个GC计算块包含一个用于64b存储数据和16b固定数据的SB-TP-GCA,以及一个包含DM-ADD和DM多路复用器(DM-MUX)的DM-LCC。DM-GCCA可以执行两种模式的计算:
1)BF16模式:
在此模式下,DM-CIM的各个模块均处于工作状态。SB-TP-GCA存储1b符号数+7b尾数+8b指数。第一步,DM-ADD会将8b的输入指数和8b的权重指数相加,也即得到了指数部分积(PDE);第二步,ZB-IPU找到最大的PDE值并根据对齐的INMA来对齐每一个输入尾数INM;第三步,选择器(DM-MUX)计算PDM;第四步,DSaA将指数和尾数相结合,输出结果。
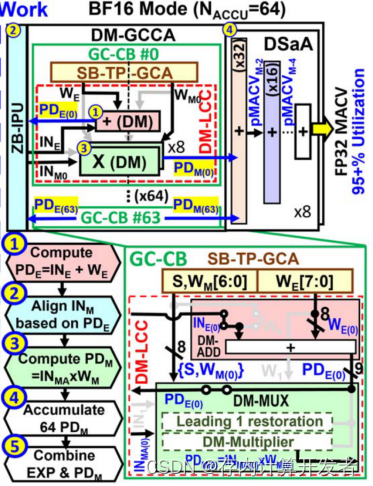
图4 BF16模式下的数据流
2)INT8模式:
在此模式下,DM-CIM的各个模块同样均处于工作状态。SB-TP-GCA存储两个8b的权重。第一步,DM-ADD将两个权重相加得到pSUM,通过利用权重数据复用可以将其用于多个计算;第二部,ZB-IPU检测输入值的稀疏度来减少DM-GCCA和DSaA中的MAC能耗,并解码两个按位IN0[k]和IN1[k]作为DM-MUX的选择信号;第三步,DM-MUX对IN0和IN1执行部分MAC运算并生成pMAC值;第四步,DSaA累加64个pMACV,输出结果。

图5 INT8模式下的数据流
2.基于DM区域的输入处理单元操作(ZB-IPU方案)
ZB-IPU方案/模块是处理BF16模式下的对齐和INT8模式下的稀疏性检测的关键模块,该模块创新性地提出了基于区域检测对齐的方案(ZDBA),在这个方案下的对齐操作仅使用3个反相器就能完成,代替传统的n比特减法器,显著降低了模块的能量与面积开销。此外,ZB-IPU模块也支持INT8模式下的稀疏性检测,总之,他也可以执行两种模式的计算:
1)BF16模式:
在此模式下,ZDBA方案下的对齐操作分为两步。第一步,pEMAXF 查找 PDE-MAX 的 MSB-6b (PDE-MAX[8:3])。然后ZBU根据PDE-MAX[8:3]生成3个区域参考(PDE-REF1~3),这三个区域参考将作为后续对齐时的重要依据;第二步,每个PDE(n)根据以下条件被分类为三个区域(ZFG=1/2/3)中的一个,DM-IPB根据通过反转PDE[2:0](LSB3b)获得的区域移位数(NSHZ)来对齐INM,这是PDE和PDE-REF之间的差值。以图中的PDE(0)=011111101 (253)为例,它是PDE-MAX,并且PDE-REF1=011111111(255),则PDE(0)位于 zone-0(ZFG=1),它仅需对PDE(0)[2:0]进行反转,即101反转为010,反转值为2(NSH(0)=2),这样一来,就可以利用三个反相器完成对齐的操作。如图6为BF16模式下的对齐分类区域、对齐输出和时序示意图。

图6 BF16模式下的对齐操作
2)INT8模式:
在此模式下,我们只需要对ZDBA方案下的参考值置0,即可完成稀疏度检测,ZB-IPU此时相当于输入稀疏感知电路,可以大幅降低后续计算的功耗与面积,在图7的表格中可以明显看出其对于输入的操作。
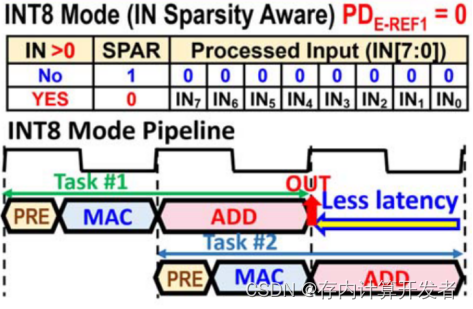
图7 INT8模式下的稀疏度检测
3.基于固定端口的双端口增益单元(SB-TP-GCA)
为了应对传统CIM在计算过程中反复进行系统和CIM的数据传输所造成的高能耗的挑战,本文提出了一种支持并行数据更新和计算的方法,减少系统与CIM交换内部数据间的时间,改善延时和能量消耗。

图8 双端口计算流程
如上图所示,是SB-TP-GCA这一设计的双端口工作时序图。对比传统CIM的顺序执行,本文介绍的工作使用了双口工作,一口负责读写、一口负责计算,以解决延时问题,提升计算效率。能效方面的提升主要依靠数据复用,降低读写次数的方式来实现。
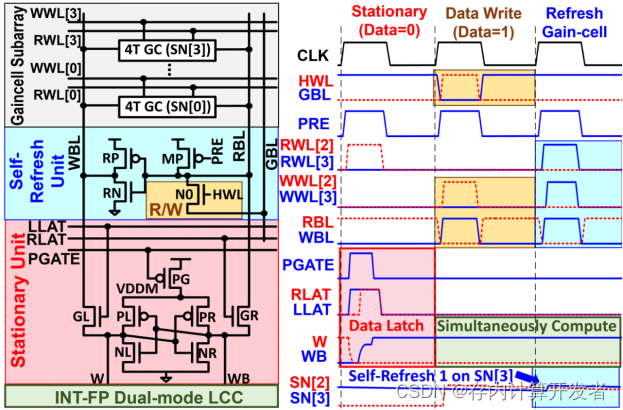
图9 芯片双端口中三个模式对应执行电路与执行时序图
上图所示是电路的设计图和时序图。
SB-TP-GCA结构允许在进行乘加运算的同时进行数据更新。这种并行操作减少了系统在不同时间段内需要进行的数据传输次数,从而降低了总能耗。并且,阵列内部的静态单元可以在多个计算周期内重用权重数据,减少了每次计算所需的数据传输量。通过减少内部数据访问频率,有效地降低了能耗。每个SB-TP-GCA列由四个4T增益单元(GC)、一个4T自刷新单元(SRU)和一个7T静态单元(STU)组成。在存储更新模式下,数据从全局位线(GBL)传输到SRU,然后通过SRU驱动写入位线(WBL)以更新选定的GC单元。这种存储单元设计减少了不必要的数据移动和功耗。SB-TP-GCA提供了三种操作模式(静态更新、存储更新和自刷新),针对不同模式的分类可以针对使用场景管理数据的存取和刷新,进一步减少了功耗。例如,在静态更新模式下,存储的数据可以通过读位线(RBL)传输到自刷新单元(SRU)进行刷新,而无需频繁的全局数据传输。
通过这以上几点改进,优化高功耗问题。
三、性能对比与拓展
文中将该工作与已有的相似工作进行对比,性能对比表和芯片电镜图如图所示,可以看到本工作在面积效率和能效上更优。
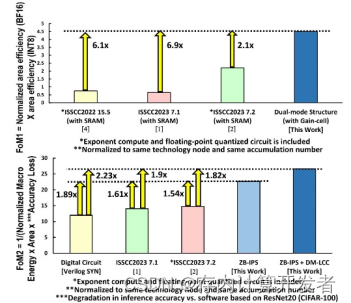

图10 本文芯片性能对比
本工作与以往工作的主要区别在于采用双端口设计,本文基于这一想法开展多项优化。从本文针对的计算能效、传输延时、浮点/整数计算支持三个角度来看:
(1)计算能效/面效方面:[1]采用双端口设计,提高数据复用,减少数据流动,提高计算能效;[3]模拟域和数字域结合,将两类计算模式按照一定比例进行耦合,兼具两种计算模式的优点来提高计算效率和准确度;[4]设计双位存储器和FCU浮点计算单元,提升吞吐率,采用高精确低近似的乘法器,提高面销和能效;[5]提出BM2控制器,使用按位输入的Booth编码,部分积重编码,减少近50%的循环次数和位乘法次数,以提升计算能效。
(2)传输延时方面:[1]采用双端口设计,读写和计算并行,提高计算效率;[3]使乘法的中间结果在同一列累积。
(3)浮点支持方面:[1]设计了同芯片双模式,针对该模式设计了一种新型输入数据处理方式,在计算浮点数时将其用于尾数对齐,计算整数时将其用于稀疏度检测,最大化面积利用效率;[4]提出了FCU,解决浮点与整数映射不一致的问题,利用同一个MAC模块;[5]实现了一种无指数对齐的浮点乘累加计算流水线,使CIM专注提升尾数乘累加的计算速度
针对浮点支持方面,已有的工作主要针对尾数计算算法进行改进,以提升效率。在思路上是共性的,即对浮点计算部分尾数乘累加计算流程进行优化,以尽可能减小计算周期数。早期的浮点存算正如本文背景所说,采用分离程度较高的硬件进行工作。近期的浮点存算工作,已进行了一定改进,但也未能充分利用面积资源,主要的资源浪费集中在指数对齐计算方面,整数计算本不需该计算模式,因此在计算整数时,这部分浮点计算硬件未能得到应用,如下图所示。
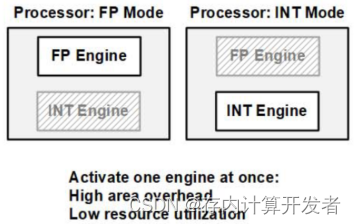
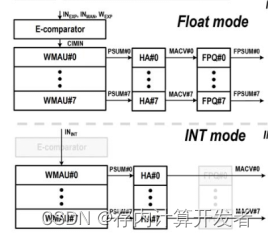
图11 已有浮点存算工作中存在的问题
相比之下,本文方案在设计了ZB-IPS的输入调整模块设计,在整数计算和浮点计算时只有数据流的不同,在实现浮点存算计算效率提升的同时,使所有硬件模块均被充分利用。
综上,本文所介绍的ISSCC2024 34.2这篇工作向浮点存算中引入双端口以支持浮点/整数双模计算,最大化面积利用效率并提升计算速度、提升能效。其中输入处理单元是将尾数对齐于整数稀疏度判断继承在一起,是极其巧妙的设计。
参考文献
[1]W. -S. Khwa et al,“34.2 A 16nm 96Kb Integer/Floating-Point Dual-Mode-Gain-Cell-Computing-in-Memory Macro Achieving 73.3-163.3TOPS/W and 33.2-91.2TFLOPS/W for AI-Edge Devices,”2024 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2024.
[2]FP32、FP16 和 INT8-CSDN博客.
[3] Wu, Ping-Chun, et al. “A 22nm 832Kb hybrid-domain floating-point SRAM in-memory-compute macro with 16.2-70.2 TFLOPS/W for high-accuracy AI-edge devices.” 2023 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2023.
[4] Guo, An, et al. “A 28nm 64-kb 31.6-TFLOPS/W digital-domain floating-point-computing-unit and double-bit 6T-SRAM computing-in-memory macro for floating-point CNNs.” 2023 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2023.
[5] Tu, Fengbin, et al. “A 28nm 29.2 TFLOPS/W BF16 and 36.5 TOPS/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise in-memory booth multiplication for cloud deep learning acceleration.” 2022 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 65. IEEE, 2022.