一、安装部署
fio是一款优秀的磁盘IO测试工具,在Linux中比较常用于测试磁盘IO
其下载地址:https://brick.kernel.dk/snaps/fio-2.1.10.tar.gz
或者登录其官网:http://freshmeat.sourceforge.net/projects/fio/ 进行下载。
tar -zxvf fio-fio-2.11.tar.gz
cd fio-fio-2.11
./configure && make && make install
which fio
fio -v
fio多线程需要libaio引擎,yum install -y libaio-devel,后重新编译fio
二、主要性能指标
IOPS
每秒的IO数量。体现存储系统性能的最主要指标。现在主流的IOPS都在90K以上了(机械硬盘还在5K左右徘徊),比如模拟<4K>大小的文件读写。每秒最高能读或写90000个<4K>的文件;如果增加磁盘,则每秒IO数量就可以变多。比如增加相同的一块盘则IOPS就可以翻倍。
带宽(吞吐量)
每秒钟最大吞吐数据量的大小。每秒传输多大的数据比如500M/s。iops和带宽是正相关,因为知道每秒IO数量,和平均每个IO的大小则可以算出整体每秒数据量大小也就是带宽。IOPS * I/O size = Bandwidth。
大文件持续传输型的应用需要的是充分的带宽性能,而小文件随机读写的应用则要求足够的I/O能力。在存储领域有个不成文的规定,只要以IOPS来描述,那么就一般代表是小I/O(<32KB),以Bandwidth来描述,那就是大I/O(>32KB)。
延迟
是指完成一次IO请求所需的时间。延迟是关注存储性能时最重要的单个指标。
我们从发出请求到存储层的那一刻开始测量,并在获取请求的数据或确认数据已存储在磁盘上时停止测量。数据得到响应前需要等待的时间。
他和IOPS的区别:比如说我一个主机挂了一块SSD和100块HDD,SSD速度快其实就是延迟低,就是说我发送一条请求可以比HDD更快的返回。但是这里100块HDD的IOPS要高于SSD,因为他每秒能处理的IO要更多。
三、条件指标
访问方式:
顺序读写:比如将一个很大的文件写入。则读取大量的是相邻的顺序的数据块。这个模式可显示最高的吞吐量。主要是针对的大容量文件读写文件性能,这时我们主要关注带宽指标。
随机访问读写。不遵循文件的先后顺序,读写操作的时候能够任意跳到某个文件,主要作用是针对零碎文件(病毒扫描、启动程序等)任务。这时我们主要关注IOPS指标。
队列深度(iodepth):
它表示平均有多少I / O请求(在运行中),也就是同时处理多少个IO。拥有队列是有益的,因为队列中的请求可以以优化的方式(通常是并行方式)提交给存储子系统。
类似于cpu处理多线程,一个cpu处理一个线程一段时间然后切换到另一个线程去处理,这样每个线程处理时间提高了,但是充分利用了CPU性能提高了多线程的性能。加大硬盘队列深度就是让硬盘不断工作,减少硬盘的空闲时间。但是代价就是提高了延迟。
不同队列深度有着不同的性能表现,通常队列深度为1时有最好的延迟表现;随着队列深度的增加,其IOPS会随之增长,QD1~QD4基本是线性提升,QD8大概是QD4的双倍,QD16又是QD8的双倍,直到获得SSD的最大IOPS(一般是32);在未达到SSD的最大IOPS时,随着队列深度的增加,其延迟增加通常并不剧烈;在达到最大IOPS后,随着队列深度的增加,其IOPS趋于稳定,但延迟通常会随队列深度的增加而线性增长。
加大队列深度 -> 提高利用率 -> 获得IOPS和MBPS峰值 ->注意响应延迟在可接受的范围内
建议:也就是说队列深度最好设置到16或者32,以获得最大的IOPS。就是设置能达到最大IOPS的最小的队列深度。
线程数:比如设置为8。在固态硬盘内部,单次读取耗时主要分为两部分:寻址延迟时间和传输时间。单线程的时候,即使队列深度大于1,但每个访问请求的这两步都是串行的,也就是必须先寻址然后才能传输。而多线程的时候,不同线程的这两步是可以并行的。传输完线程1的数据后就可以马上开始线程2的数据传输。也就是提升线程数可以明显提升SSD的性能。但这个提升并不是倍数关系,因为可能2线程比1线程提升很大,但是8线程并不比2线程有很大幅度的性能提升。
四、fio指标解读
配置参数.fio
ioengine=libaio
libaio - Linux 原生的异步 I/O,这也是通常我们这边用的最多的测试盘吞吐和延迟的方法
sync - 也就是最通常的 read / write 操作
vsync - 使用 readv / writev,主要是会将相邻的 I/O 进行合并
psync - 对应的 pread / pwrite
pvsync / pvsync2 - 对应的 preadv / pwritev,以及 preadv2 / p writev2
rw=randrw
read - 顺序读
write - 顺序写
trim - 顺序裁剪
randread - 随机读
randwrite - 随机写
randtrim - 随机裁剪
rw, readwrite - 混合顺序读写
randrw - 混合的随机读写
trimwrite - 顺序的裁剪 + 顺序写
rwmixwrite=90 (混合模式使用)
混合读写中,写占的百分比
bs=4k(block size)一次io操作大小
通常我们都是读写使用相同的 block,譬如 bs=4k,我们还可以用 bs=4k,16k 来设置读是 4k,但写是 16k。每次4k的io进行测试
iodepth=16,队列深度
numjobs=8,线程数,比如设置8
size=512m,每个线程读写的数据量521M 传输完成就结束
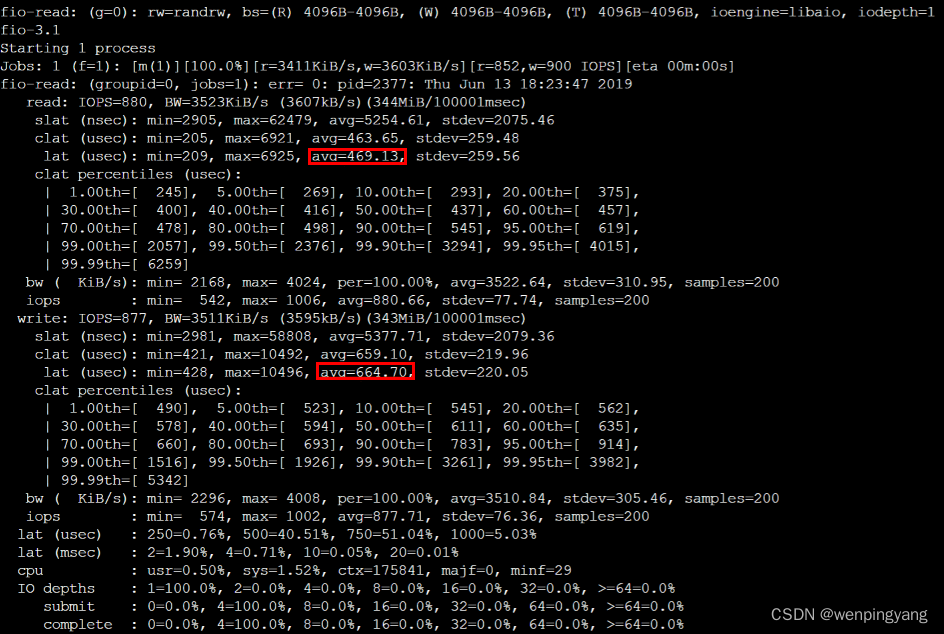
IOPS: 每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一;
Bw: 带宽;
slat 表示fio 提交到内核某个I/O的延迟;
clat 表示fio 内核完成某个I/O的延迟;
lat 表示从fio将请求提交给内核,再到内核完成这个I/O为止所需要的时间;
关系是 lat = slat + clat
usr:表示用户空间进程;
sys:表示内核空间进程;
五、测试命令
参见:云硬盘 如何衡量云硬盘的性能-最佳实践-文档中心-腾讯云
或如何在Linux实例中使用FIO工具测试块存储性能_云服务器 ECS(ECS)-阿里云帮助中心
fio -bs=4k -ioengine=libaio -iodepth=1 -direct=1 -rw=randread -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randread-lat --size=10G -filename=/dev/sda
bs = 4k iodepth = 1:随机读/写测试,能反映硬盘的时延性能
bs = 128k iodepth = 32:顺序读/写测试,能反映硬盘的吞吐性能
bs = 4k iodepth = 32:随机读/写测试,能反映硬盘的 IOPS 性能
测试nfs或samba共享存储时,命令中-filename=block_device要换成-directory=共享目录
裸盘的测试结果:
