一、介绍

mochi是近期Genmo公司开源的先进视频生成模型,具有高保真运动和强大的提示遵循性。此模型的发布极大的缩小了闭源和开源视频生成系统之间的差距。

目前,视频生成模型与现实之间存在巨大差距。其中最影响视频生成的两个关键功能也就是运动质量和提示词遵循性。
mochi模型性能评估:当前发布的480p预览版有以下优势:
提示词遵循:对文本提示具有极高的遵从性,确保生成的视频能够准确反映所给的命令。
运动质量:Mochi 1 以每秒 30 帧的速度生成流畅的视频,持续时间长达 5.4 秒,具有很高的时间一致性和逼真的运动动态。能模拟流体动力学、毛皮和头发模拟等物理特性,并可以表达出人们穿越恐怖谷场景时一致的、流畅的动作。


其它更多信息可点击官网详细了解:https://www.genmo.ai/,进入官网登录之后还可以在线体验视频生成功能
接下来就谈谈如何在 ComfyUI 上进行部署:
二、部署
要求:
显存 >=24G
CUDA 版本 >=11.8
1. 部署 ComfyUI
(1)使用命令克隆 ComfyUI
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
(2)安装 conda(如已安装则跳过)
下面需要使用 Anaconda 或 Mimiconda 创建虚拟环境,可以输入 conda --version 进行检查。下面是 Mimiconda 的安装过程:
- 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
- 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
- 遵循安装提示并初始化
按 Enter 键查看许可证条款,阅读完毕后输入 yes 接受条款,安装完成后,脚本会询问是否初始化 conda 环境,输入 yes 并按 Enter 键。
- 运行
source ~/.bashrc命令激活 conda 环境 - 再次输入
conda --version命令来验证是否安装成功,如果出现类似conda 4.10.3这样的输出就成功了。
(3)创建虚拟环境
输入下面的命令:
conda create -n comfyui
conda activate comfyui
(4)安装 pytorch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
(5)安装项目依赖
pip install -r requirements.txt
此时所需环境就已经搭建完成,通过下面命令进行启动:
python main.py
访问网址得到类似下图界面即表示成功启动:

到这里 Comfy UI 就初步搭建好了(这里只是简单实现 ComfyUI 的基础功能,如果想要安装更多细节,请看我“Comfy UI”部署教程)
2. 部署 mochi
(1)下载文本编码模型
第一步是要下载文本编码器文件(如果你没有从Flux模型中下载过): t5xxl_fp16.safetensors
进入 hugging face 网站,点击搜索:mochi_preview_repackaged

第一次登录需要注册,然后搜索后需要填写信息获取模型访问的权限。通过后点击“Flies”选择"split_files":
出现的三个文件夹就是我们所需的模型文件。点击 text_encoders文件夹,将其中的t5xxl模型下载到 ComfyUI/models/text_encoders/ 文件夹中

两个模型,根据自己的情况选择一个下载,fp16肯定是要比fp8效果要好的。
(2)下载VAE模型
同理,点击“vae”文件夹,将其中的模型下载到ComfyUI/models/vae/文件夹中
(3)下载视频生成模型mochi
点击进入diffusion_models文件夹

下载mochi_preview_bf16.safetensors文件,放在你的 ComfyUI/models/diffusion_models/ 目录中:

你会看到两个mochi模型文件,因为官方发布的原生模型是40G,在ComfyUI中进行了量化,因此有bf16版本和fp8版本,其中,fp8是包含了视频生成、clip文本编码和vae功能的多合一模型,这能降低视频生成所需要的显存,以及缩短所需时间,但是,也会降低生成视频的质量,可以根据情况进行选择。
(3)下载工作流
点击链接:Mochi Video Model | ComfyUI_examples,然后将下图拖入 Comfy UI 即可出现工作流:

fp8多合一模型的工作流:

工作流如下:
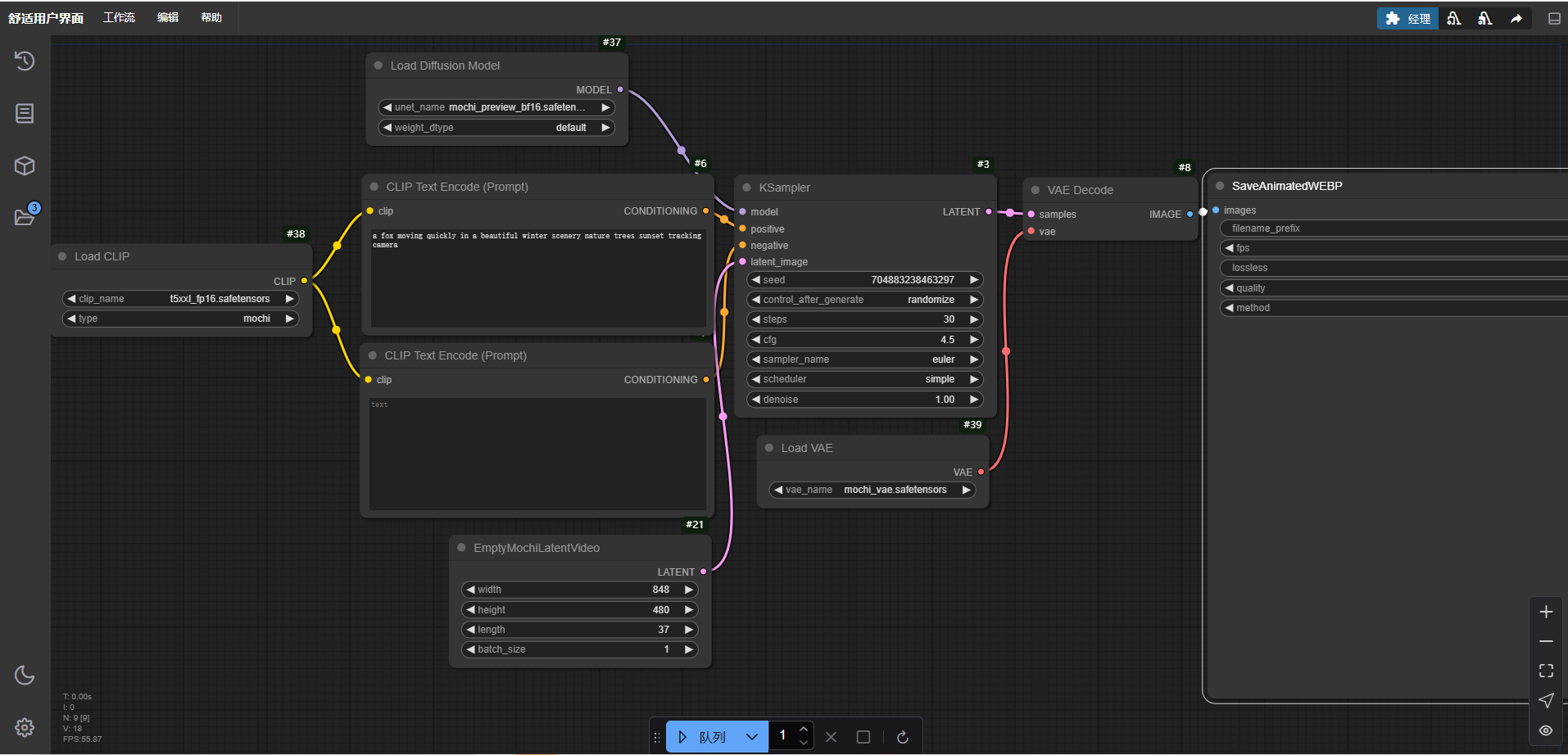
至此 mochi 模型就部署在 Comfy UI 中了。