经常和出版社编辑老师交流读者的反馈。毕竟是小众书籍,豆瓣评分的人并不多。
而京东作为主要读书销售渠道,非常有必要整合一下京东读者评论,看看读者们都说了什么,以便后续的改进!
一条条的翻看非常不方便,干脆能不能搞个爬虫把评论采集下来呢?这是我最初始的想法。
等我采集下来数据后,我就想咱们有 kibana,有 Elastic Stack 技术栈体系,能不能顺带做个可视化效果图呢?
于是就有了开篇的效果图。
读者们可能会说,书中第18章就讲的怎么处理,看下来也并不复杂。是的,基本都是重复的工作。
我进一步想,能不能尽可能一行代码也不写,全部借助大模型 ChatGPT 完成呢。
所以,和之前不同,整个采集、解析、Elasticsearch 预处理、写入 Elasticsearch 等全过程全是基于大模型问答完成的。
如果你对 AI 代码实现感兴趣,如果你对上面可视化效果感兴趣,建议看到最后。
1、AI 工具选型
我近期使用大模型最大的收获就是:一定要货比三家。
不要依赖任何一种大模型,哪怕付费版的ChatGPT,一定得货比三家,都试试。
我近期用的最多也是我逢人就推荐的是:ChatGPT 4o 付费版本(每个月20美金)。
另外我用的 perplexity AI,他的整合能力是远远大于 Kimi的(个人观点,欢迎留言交流)。
2、整体架构构思
大模型有了以后,写代码相当于外包给大模型了,我们基本不用写了,只需要微调就可以。
什么能力变得更加急迫呢?Prompt 能力、提示词能力、提问能力变得越发重要!
提问什么呢?还是需要我们提前整体构思。
类似数据存储到可视化,咱们视频都录制过好几期,战争电影题材评论的、Wireshark抓包的、微博评论的,都做了可视化处理。
核心就是:
Step1:数据采集
Step2:数据清洗(看是否需要)
Step3:数据预处理
Step4:数据写入 Elasticsearch
Step5:Kibana 可视化
Step3 和 Step4 步骤可以互换的,因为 Elasticsearch 预处理是借助 pipeline 实现的,可以索引创建阶段,也可以写入后借助 update_by_query 批量更新实现。
有了上面整体构思,剩下就是逐个击破。
逐个构思 Prompt,让咱们的外包 AI 帮写代码,我们只需要评审代码,用代码就可以了。
3、数据采集
其实这个需要电脑端打开某东,实际调研发现,某东是有 API 接口的,不过频繁调用会封禁 24 小时。
还好咱们的数据量不大。
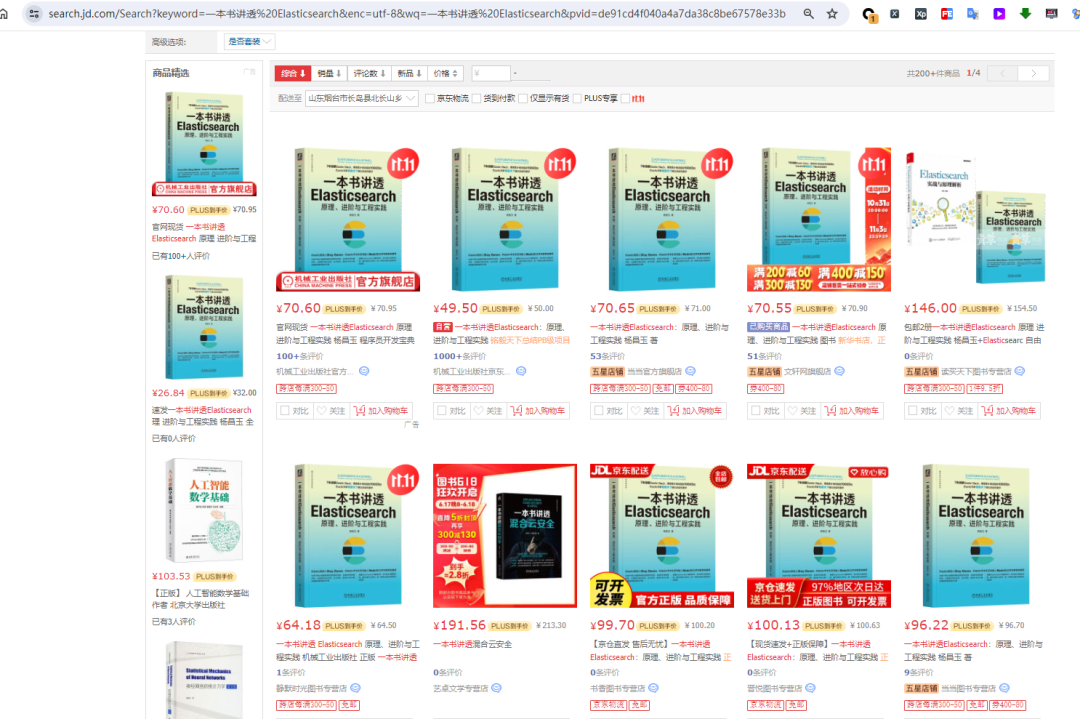
接口参考如下:
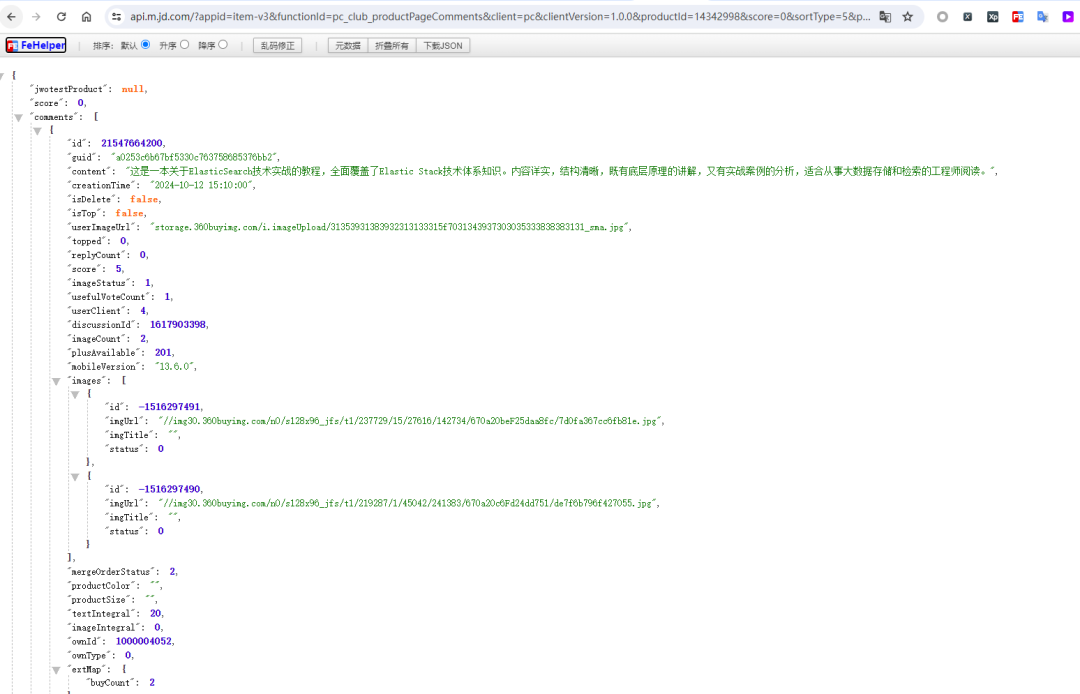
有了接口之后,我们会发现如入无人境地,“拿”数据变得容易、可行!
详尽代码参见:https://articles.zsxq.com/id_lj2wtgectd25.html
这里的提示词可以反复提问,我是借助 perplexity.ai 实现的。


中间代码不一定 100% 正确,需要我们拿到代码微调一下,确保可用,可以采集到才可以。
3、数据写入与存储
3.1 写入前,先创建索引。
这里最核心的 Mapping 和 Setting,弄不好,后面可视化要经常返工。
我把全部的评论都丢给 ChatGPT 4o1-mini, 让他帮我想可以可视化的维度。结果是模型比我想的更加全面。

然后,我提取了可以可视化的部分,让 GPT 帮创建的索引。Prompt 参考如下:

最终代码和DSL 完整版:https://articles.zsxq.com/id_cidkaht43ssd.html
3.2 数据写入
注意:字段原因,我先写入,后做的预处理。
上面采集数据已经存储为 csv,且验证是正确的后。正常应该对数据做一下清洗,我没有做任何处理,直接写入 Elasticsearch。
写入 Elasticsearch,这个也不复杂,就是多轮问一下就可以。
参见提示词:

4、数据预处理
为什么需要预处理?
因为采集的地理位置信息是省份。
我们之前积累的可视化必须是城市的 GEO 经纬度坐标信息。
所以,这里需要两次转换。
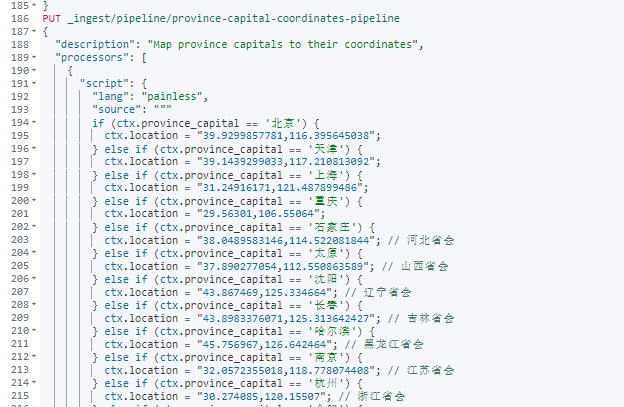
第一:省对应省会,比如:咱们采集到的河北,需要新增字段:石家庄。
第二:省会对应 GEO 经纬度坐标。(前面做战争题材有积累,我猜测不用积累,直接生成问题也不大)。
这块也可以提问实现。
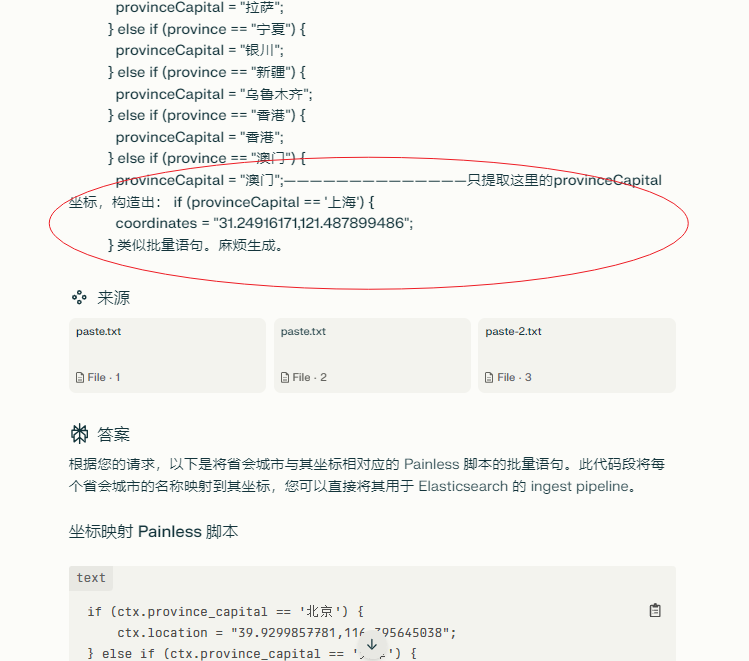
最终效果参考:
5、Kibana 可视化
这快咱们视频讲的很多,基本一步步实现就行。
这块没有用AI ,自己搞定就可以。
结果就是大家开头看到的结果。
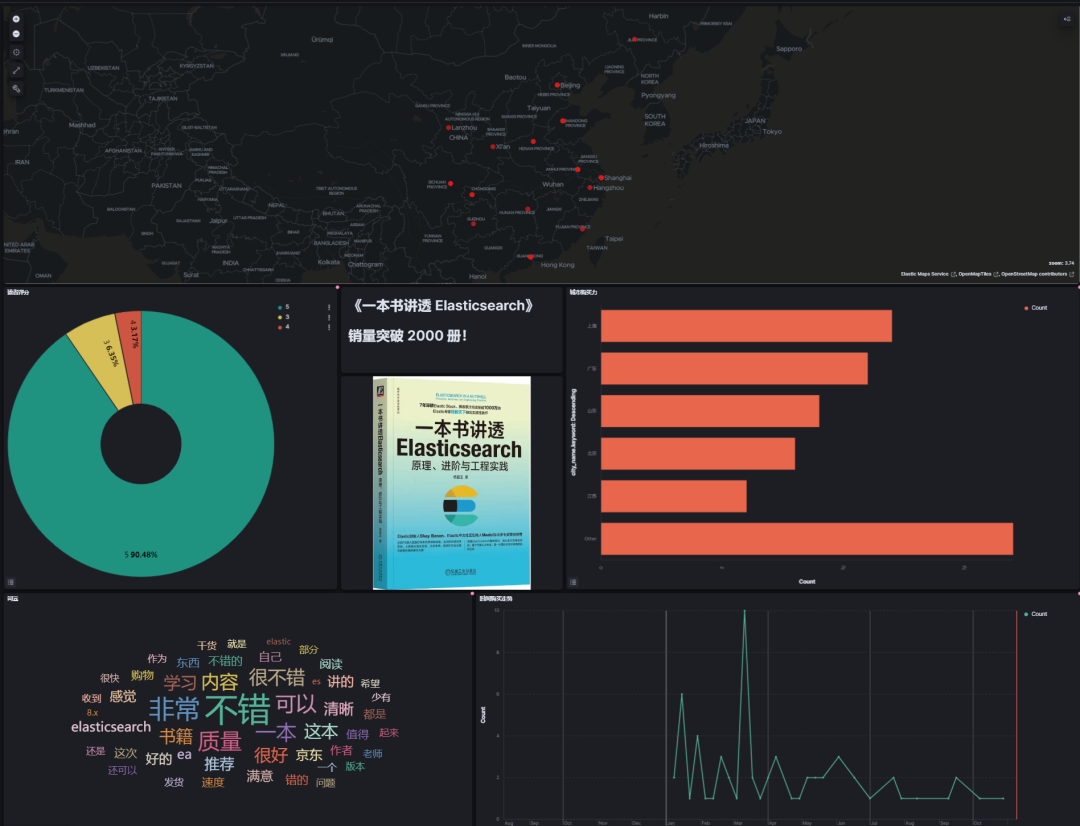
5.1 读者城市分布图
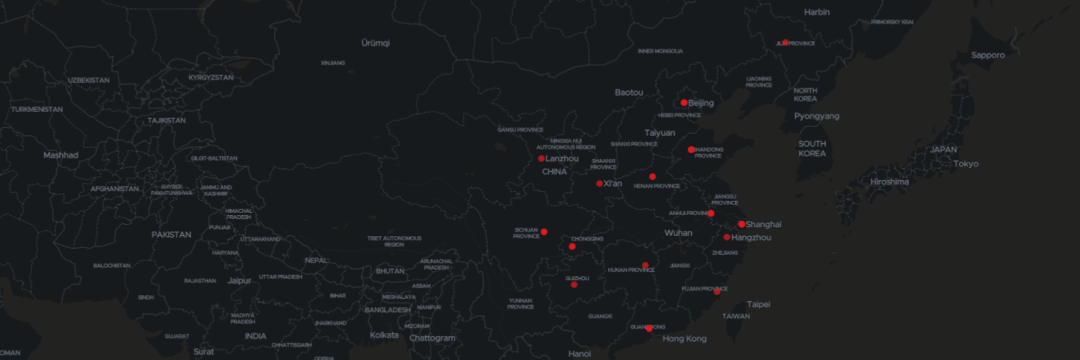
基本覆盖全国各个大城市。
5.2 省份分布条形图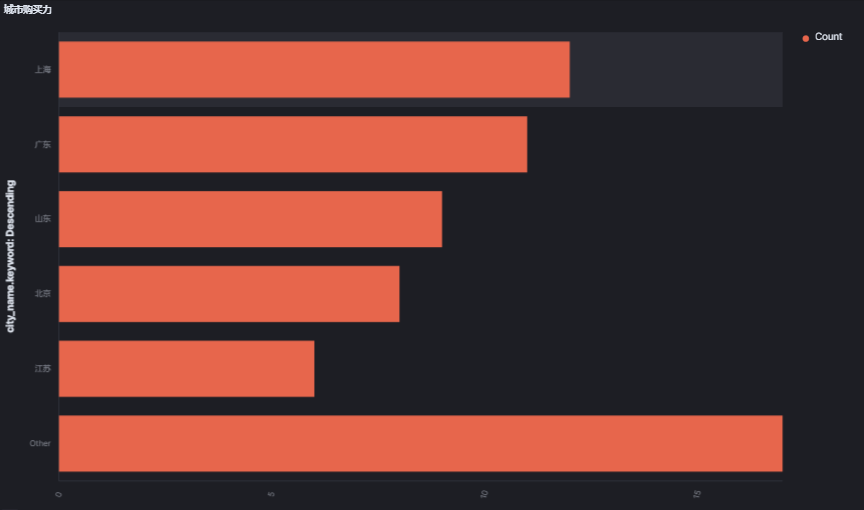
5.3 读者评分饼状图

看得出来,90.48%左右给出了5分好评!
5.4 评论词云效果图

5.5 时间走势图
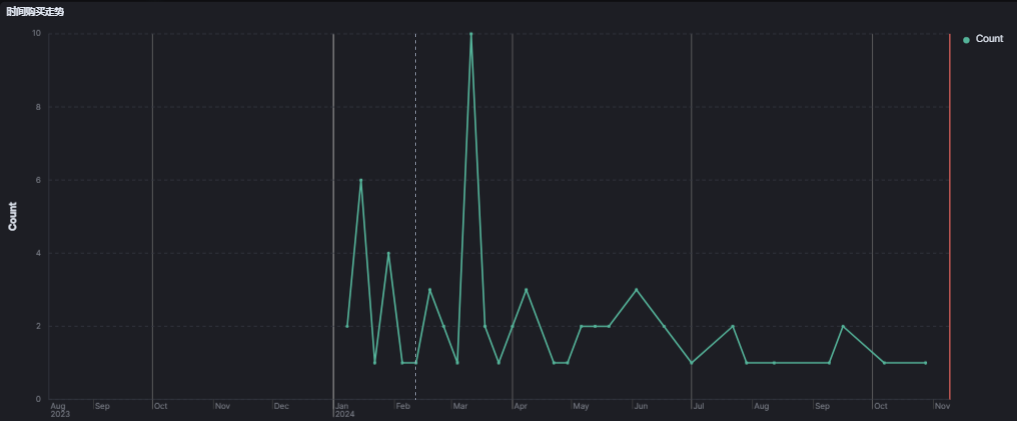
走势相对趋于平稳态势。
5.6 销量图

这个是咱们自己加的文字和配图,kibana 端是允许导入的。
基本和预期一致!!
6、AI 使用反思
之前自己写代码效率和现在相比是小巫见大巫,基本 AI 能解放很大一部分双手。
但是,最好的方式和 AI 一起讨论逐步给出清晰的解析方案。
AI 就是我们的架构师、大学教授、代码外包工程师、XXXX 一切都可以是。看我们怎么用它!
AI 一定不要一棵树吊死,一定要货比三家。
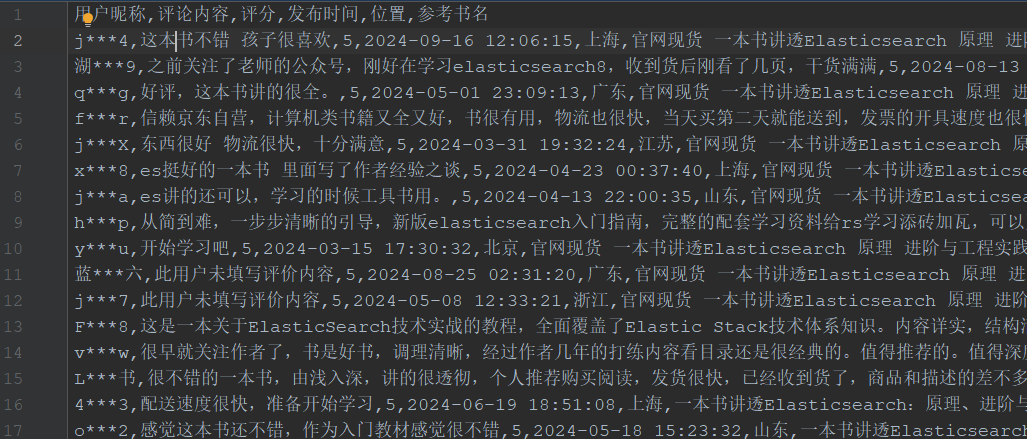
7、全部基于真实评论书评汇总
Elasticsearch 作为当今最流行的分布式搜索和分析引擎之一,在大数据存储和检索领域扮演着重要角色。

然而,市面上关于 Elasticsearch 的书籍大多版本较旧,且内容偏重于代码层面的讲解,缺乏对最新版本的系统性阐述。
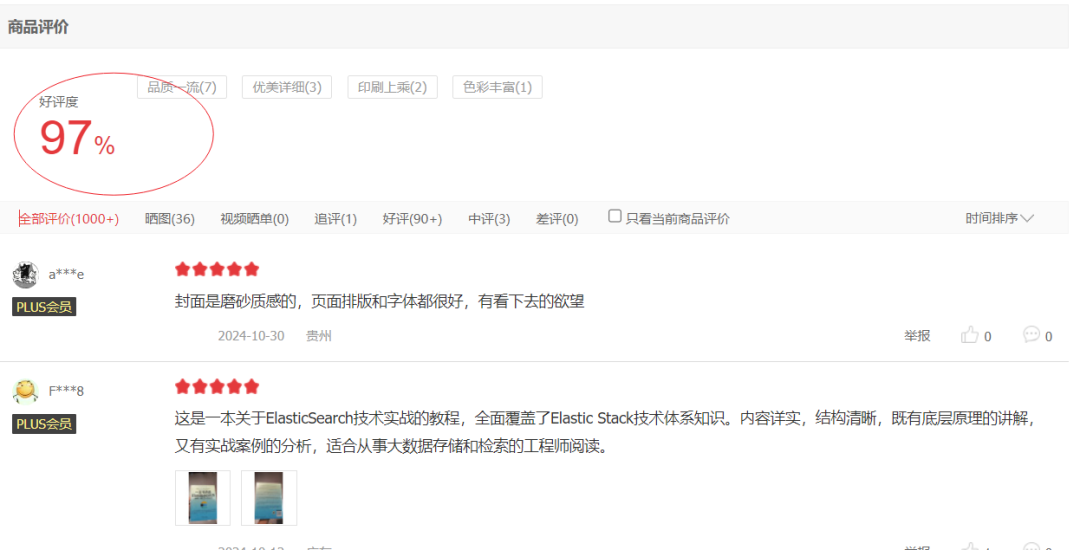
近期出版的《一本书讲透 Elasticsearch:原理、进阶与工程实践》填补了这一空白,受到了广大读者的热烈好评。
读者真实反馈采集:https://t.zsxq.com/nS4va
7.1 全面覆盖 Elasticsearch 8.x 版本
这本书是市面上少有的全面讲解 Elasticsearch 8.x 版本的书籍之一。
很多读者反馈,书中内容紧跟最新版本,让他们在学习和工作中受益匪浅。
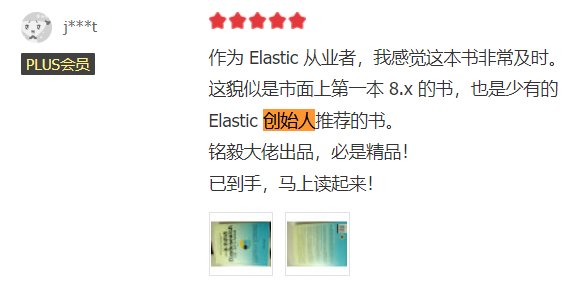
“这貌似是市面上第一本 8.x 的书,也是少有的 Elastic 创始人推荐的书。”——读者反馈
7.2 从入门到精通,由浅入深的讲解
书中内容结构清晰,从基础原理开始,一步步引导读者深入理解 Elasticsearch 的核心概念和高级特性。无论是新手入门,还是有经验的开发者,都能从中找到有价值的内容。
“由浅入深,讲得很透彻,个人推荐购买阅读。”——读者反馈

“从简到难,一步步清晰的引导,完整的配套学习资料给学习添砖加瓦。”——读者反馈

7.3 实战案例与工程实践
除了理论知识,书中还包含了大量的实战案例和工程实践经验。这些内容源自作者多年的一线工作积累,具有很高的实用价值。
“既有底层原理的讲解,又有实战案例的分析,适合从事大数据存储和检索的工程师阅读。”——读者反馈

“里面写了作者经验之谈,很实用,面试 offer 每天都有。”——读者反馈
7.4 精心的内容设计与排版
不少读者提到,书的排版和字体设计合理,纸张质量好,阅读体验佳。同时,每章末尾的思维导图总结,也方便了知识的梳理和回顾。
“封面是磨砂质感的,页面排版和字体都很好,有看下去的欲望。”——读者反馈

“每章末尾脑图部分总结,看得出作者的用心。”——读者反馈

7.5 适合的学习人群
这本书适合以下人群阅读:
Elasticsearch 初学者:从零开始,系统性地学习 Elasticsearch 的核心概念和使用方法。
有经验的开发者:深入理解 Elasticsearch 的高级特性和内部原理,提升技术水平。
大数据工程师:掌握 Elasticsearch 在大数据存储和检索中的应用。
面试求职者:书中涵盖了大量实用知识点,有助于在面试中脱颖而出。
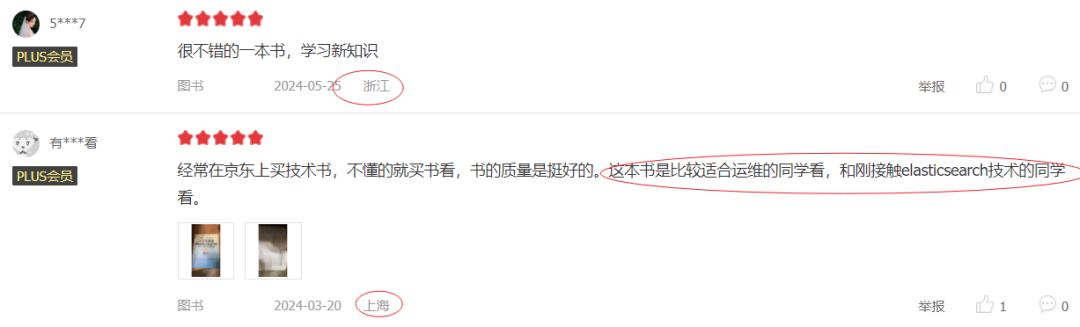
7.6 读者的真实反馈
许多读者在阅读后,都给予了高度评价:
干货满满:内容详实,涵盖了从基础到高级的各个方面。

结构清晰:章节安排合理,逻辑性强,易于理解和消化。

实用性强:结合实际案例,提供了很多可操作的经验和技巧。
8、结语
《一本书讲透 Elasticsearch:原理、进阶与工程实践》无疑是一本不可多得的好书。它不仅填补了 Elasticsearch 8.x 版本的空白,还以其全面、深入和实用的特点,成为广大技术人员的必备参考书。
如果你正在寻找一本能够全面提升自己 Elasticsearch 技能的书籍,不妨一读。
参考:Kibana 8.X 如何做出靠谱的词云图?