一、shell概述
1.1 shell是什么
Shell是一种脚本语言
脚本:本质是一个文件,文件里面存放的是特定格式的指令,系统可以使用脚本解析器、翻译或解析指令并执行(shell不需要编译)
Shell既是应用程序又是一种脚本语言(应用程序解析脚本语言)
shell是系统跟计算机硬件交互时使用的中间介质,它只是系统的一个工具
Shell命令解析器:
系统提供shell命令解析器:sh ash bash
查看自己linux系统的默认解析:echo $SHELL

Shell脚本是一种脚本语言,我们只需要使用任意文本编辑器,按照语法编写相应程序,增加可执行权限,即可在安装shell命令解释器的环境下执行
1.2 历史命令
1.2.1 !在命令中的应用
当我们在linux中执行命令时,执行过的每一条命令都会被保存到家目录的.bash_history文件中,需要注意的是:只有当用户正常退出当前shell时,在当前shell中运行的命令才会保存至.bash_history文件中
!!:连续两个!表示执行上一条指令
| [root@localhost ~]# pwd /root [root@localhost ~]# !! pwd /root |
!n:表示执行命令历史中的第n条指令
| [root@localhost ~]# history |grep 90 90 bash 1.sh 155 history |grep 90 [root@localhost ~]# !90 bash 1.sh bash: 1.sh: 没有那个文件或目录 |
!字符串:表示执行命令历史中最近执行的一次以其开头的命令
| [root@localhost ~]# !bash bash 1.sh bash: 1.sh: 没有那个文件或目录 |
1.2.2补全
一次TAB键可以补全一个指令、一个路径、一个文件名;连续两次TAB键,系统列出所有命令或文件名
1.2.3别名
在shell中,别名(alias)是一种将一个或多个命令绑定到一个自定义名称上的方法
创建别名: alias 别名=“实际命令”
| [root@localhost ~]# alias ll="ls -l" [root@localhost ~]# ll 总用量 552 -rw-------. 1 root root 1257 9月 21 17:25 anaconda-ks.cfg drwxr-xr-x. 4 root root 75 10月 8 08:42 shell1 -rw-r--r--. 1 root root 560272 7月 13 09:34 wget-1.14-18.el7_6.1.x86_64.rpm |
查看已有别名:alias
| [root@localhost ~]# alias alias cp='cp -i' alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' alias l.='ls -d .* --color=auto' alias ll='ls -l' alias ls='ls --color=auto' alias mv='mv -i' alias rm='rm -i' alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde' |
删除别名:unalias 别名
| [root@localhost ~]# unalias ll [root@localhost ~]# ll -bash: ll: 未找到命令 |
1.2.4通配符
在shell中,通配符是一种特殊的字符,用于匹配文件名或路径中的特定模式,以下是常用通配符及其含义:
(1)星号*:代表零个或多个任意字符
例:
*.txt匹配所有扩展名为.txt的文件
示例:
| [root@localhost shell]# ls 1.txt file1.txt file2.txt filea.txt fileb.txt images.png script.sh [root@localhost shell]# ls *.txt 1.txt file1.txt file2.txt filea.txt fileb.txt |
◎a*匹配以字母a开头的所有文件
| [root@localhost 1]# ls a1.txt a2.txt abc.txt AbC.txt ABC.txt b1.txt b2.txt [root@localhost 1]# ls a* a1.txt a2.txt abc.txt |
◎*b*匹配任何包含字母b的文件
| [root@localhost 1]# ls *b* abc.txt AbC.txt b1.txt b2.txt |
- 问号?:代表一个单一的任意字符
例:
◎?.txt匹配单个字符后跟.txt扩展名的文件,如a.txt或1.txt
| [root@localhost 2]# ls 1.txt 2.txt a.txt b.txt file1.log file20.log file2.log [root@localhost 2]# ls ?.txt 1.txt 2.txt a.txt b.txt |
◎file?.log匹配file1.log,file2.log.不匹配file10.log
| [root@localhost 2]# ls file?.log file1.log file2.log |
- 方括号[]:代表括号内的任何一个字符,可以指定范围
例:
◎[abc]匹配文件名中包含a、b、c中任意一个字符的文件
◎[a-c]同上,等价于[abc]
| [root@localhost 3]# ls 1.txt 4.txt 7.txt 8.txt 9.txt a.txt b.txt c.txt [root@localhost 3]# ls [a-c].txt a.txt b.txt c.txt [root@localhost 3]# ls [abc].txt a.txt b.txt c.txt |
◎[0-9]匹配文件名中包含0到9之间任何一个数字的文件
| [root@localhost 3]# ls [0-9].txt 1.txt 4.txt 7.txt 8.txt 9.txt |
◎[!abc]或[^abc]匹配不在a、b、c范围内的字符
| [root@localhost 3]# ls [!abc].txt 1.txt 4.txt 7.txt 8.txt 9.txt |
1.2.5输入/输出重定向
在Shell中,输入/输出重定向是一种强大的功能,它允许你改变命令的标准输入(stdin)、标准输出(stdout)和标准错误(stderr)的流向。这可以让你将命令的输出保存到文件中,或者从文件读取输入,甚至可以将一个命令的输出作为另一个命令的输入。
输出重定向
◎>:将命令的输出写入到指定的文件中,如果文件已经存在,则会覆盖文件内容
| [root@localhost ~]# echo "Hello,World" > output.txt [root@localhost ~]# cat output.txt Hello,World |
◎>>:将命令的输出追加到指定的文件中,不会覆盖文件原有内容
| [root@localhost ~]# echo "Another line" >> output.txt [root@localhost ~]# cat output.txt Hello,World Another line |
◎&>或>&:将标准输出和标准错误都重定向到同一个文件中
| [root@localhost ~]# some_command &> combined_output.txt [root@localhost ~]# cat combined_output.txt -bash: some_command: 未找到命令 |
◎2>:将标准错误单独重定向到一个文件中
| [root@localhost ~]# some_command 2> error_output.txt [root@localhost ~]# cat error_output.txt -bash: some_command: 未找到命令 |
输入重定向
◎<:从指定的文件中读取输入
假设input.txt文件中有如下未排序的行
| [root@localhost ~]# vi input.txt banana apple cherry date elderberry |
执行命令
| [root@localhost ~]# sort < input.txt apple banana cherry date elderberry |
输出的内容将会按字母顺序排序后输出到终端
1.2.6管道符
在shell中,管道符(|)允许你将一个命令的输出作为另一个命令的输入
| [root@localhost ~]# cat /etc/passwd |wc -l 19 |
1.2.7作业控制
当运行进程时,你可以使它暂停(Ctrl+Z),然后使用fg(foreground的简写)命令恢复它,或者是使用bg(background的简写)命令使它到后台运行。此外,你也可以使它终止(Ctrl+C)
| [root@localhost ~]# vi test1.txt Testtestetstetste #随便输入一些内容,按Esc键,使用Ctrl+Z暂停任务
#此时提示进程已经停止,使用fg命令恢复,输入jobs,可以查看被暂停或在后台运行的任务 [root@localhost ~]# jobs
#如果想把暂停的任务放在后台重新运行,就使用bg命令 [root@localhost ~]# bg [1]+ vi test1.txt &
#可以看出vi不支持在后台运行,换一个命令查看 [root@localhost ~]# vmstat 1 > /tmp/1.log ^Z [2]+ 已停止 vmstat 1 > /tmp/1.log [root@localhost ~]# jobs [1]- 已停止 vi test1.txt [2]+ 已停止 vmstat 1 > /tmp/1.log [root@localhost ~]# bg 2
#在上面的例子中,出现一个新的知识点,就是多个被暂停的任务会有编号,使用jobs命令可以看到两个任务,使用bg命令或者fg命令时,需要在后面加上编号 [root@localhost ~]# jobs [2]+ 运行中 vmstat 1 > /tmp/1.log & [root@localhost ~]# ps aux|grep vmstat root 1591 0.0 0.1 152576 1376 pts/0 S 13:22 0:00 vmstat 1 root 1594 0.0 0.0 112720 968 pts/0 R+ 13:25 0:00 grep --color=auto vmstat [root@localhost ~]# kill -9 1591 #在kill命令后面直接加pid即可 |
1.2.8 常用命令
(1)命令uniq
uniq命令用于过滤和显示文件中的重复行
示例:加入有一个名为date.txt文件,内容如下:
| [root@localhost ~]# vi date.txt apple banana apple cherry date banana elderberry fig grape apple |
基本去重后输出
| [root@localhost ~]# uniq date.txt apple banana apple cherry date banana elderberry fig grape apple |
注意:用于uniq只处理相邻的重复行,所以这里没有去重效果。正确去重,需要先对文件排序
| [root@localhost ~]# sort date.txt |uniq apple banana cherry date elderberry fig grape |
显示每行出现的次数
| [root@localhost ~]# sort date.txt |uniq -c 3 apple 2 banana 1 cherry 1 date 1 elderberry 1 fig 1 grape |
只显示重复的行
| [root@localhost ~]# sort date.txt |uniq -d apple banana |
只显示不重复的行
| [root@localhost ~]# sort date.txt |uniq -u cherry date elderberry fig grape |
(2)命令tee
tee可以从标准输入读取数据,并同时将数据输出到标准输出和一个或多个文件中,它可以将数据流“分叉”到多个目的地
| [root@localhost ~]# echo "Hello, World" | tee output.txt Hello, World [root@localhost ~]# cat output.txt Hello, World |
多个文件
| [root@localhost ~]# echo "Another line" | tee file1.txt file2.txt Another line [root@localhost ~]# cat file1.txt Another line |
(3)命令tr
tr用于转换或删除字符
常用选项:
-c:使用set1的补集
-d:删除set1中的所有字符
-s:将连续重复的字符压缩为一个字符
-t:确保set1和set2的长度相同,多余的部分被截断
示例:假设你有一个文件example.txt文件,内容如下
| [root@localhost ~]# vi example.txt hello,world this is a test ~ ~ ~ "example.txt" [New] 2L, 27C written #替换字符,将所有小写字母e替换成大写字母W: [root@localhost ~]# cat example.txt |tr 'e' 'W' hWllo,world this is a tWst #删除字符,删除所有的小写字母e: [root@localhost ~]# cat example.txt |tr -d 'e' hllo,world this is a tst #转换大小写,将所有小写字母转换为大写字母 [root@localhost ~]# cat example.txt |tr 'a-z' 'A-z' HELLO,WORLD THIS IS A TEST #压缩重复字符,压缩连续的空格为一个空格 [root@localhost ~]# echo "This is a test." | tr -s ' ' This is a test. #使用字符范围,将所有的数字替换为星号* [root@localhost ~]# echo "The price is $12345" | tr '0-9' '*' The price is **** #使用补集,删除所有非字母和非数字的字符串 [root@localhost ~]# echo "Hello, World! 123" | tr -cd '[:alnum:]' HelloWorld123 |
(4)命令split
split命令用于切割文档
选项参数:
-b:表示依据大小来分割文档,单位为byte
-l:表示依据行数来分割文档
示例:假如你有一个名为1.txt大文件,内容如下:
| [root@localhost ~]# vi 1.txt Line 1 Line 2 Line 3 ... Line 1000 |
按行数分割,将1.txt文件按每100行分割成多个文件
| [root@localhost ~]# split -l 100 1.txt output_ |
这将生成一系列文件,例如output_aa,output_ab,output_ac,每个文件包含100行
按字节数分割,将1.txt文件按每1000字节分割成多个文件
| [root@localhost ~]# split -b 10k 1.txt output_ |
这将生成一系列文件,例如output_aa,output_ab,output_ac等,每个文件最多包含1000字节
(5)命令chattr
Chattr命令用于更改文件属性,这些属性可以提供额外的安全性和控制
基本语法:chattr [操作] [属性] 文件......
选项参数:
操作
+:添加指定的属性
-:移除指定的属性
=:设置指定的属性,其他未指定的属性将被移除
属性
-a:只能追加数据到文件中,不能覆盖或删除
-A:不更新访问时间
-c:压缩文件
-d:使用dump命令时不备份该文件
-D:当使用同步写入时,不会写入磁盘
-e:允许扩展范围链接
-i:使文件不可更改,不可删除,不可重名,不可创建硬链接
-j:将数据写入日志文件系统中的日志
-s:从文件系统中安全的删除文件
-S:同步更新文件
-u:当文件被删除时,保留其内容
-t:不允许对目录进行写操作,除非写入的数据满足尾部追加条件
示例一:(设置单个属性)
| [root@localhost 1]# touch exmple.txt [root@localhost 1]# chattr +i exmple.txt [root@localhost 1]# lsattr exmple.txt ----i----------- exmple.txt |
示例二:(设置多个属性)
| [root@localhost 1]# chattr +ad date.txt [root@localhost 1]# lsattr date.txt -----ad--------- date.txt |
(6)命令lsattr
Lsattr命令用于显示文件的扩展属性的命令
基本语法:lasttr [选项] [文件...]
选项:
-a:显示所有文件,包括隐藏文件
-d:显示目录本身的属性,而不是目录中的文件
-R:递归地显示目录及其子目录中的所有文件的属性
-V:显示版本信息
-v:显示详细的帮助信息
示例:假设你有一个目录/home/user/does,其中包含一些文件和子目录,并且某些文件设置了扩展属性
显示目录中的所有文件的属性
| [root@localhost ~]# lsattr /home/user/documents ----i--------e-- file1.txt -----a--------e-- log.txt ----------------- regular_file.txt |
显示所有文件,包括隐藏文件
| [root@localhost ~]# lsattr -a /home/user/documents ----i--------e-- .hidden_file ----i--------e-- file1.txt -----a--------e-- log.txt ----------------- regular_file.txt |
显示目录本身的属性
| [root@localhost ~]# lsattr -d /home/user/documents ----------------- /home/user/documents |
1.3正则表达式
1.3.1 正则表达式概念:
正则表达式描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串,将匹配的子串替换或者从某个串中取出符号某个条件的子串等,在linux中代表自定义的模式模版,linux工具可以用正则表达式过滤文本。Linux工具能够在处理数据时使用正则表达式对数据进行模式匹配,如果数据符合匹配的要求,那么就会进入下一步处理,如果数据不符合匹配的要求,就会被过滤掉
1.3.2 正则表达式分类
(1)基本正则表达式:
使用元字符时需在其前面添加反斜线转义:\?、\+、\{、\}、\|和grep sed默认使用基础正则表达式
- 扩展正则表达式:
使用元字符时不需要在其前面添加反斜线转义:?、+、{、}、|、()和grep -E、sed -r、egrep、awk使用扩展正则表达式
1.3.3 grep命令
grep(global regular expression print):表示全局正则表达式,使用权限是所有用户,grep命令是文本搜集工具,能够使用正则表达式搜索文本,并把匹配的行打印出来
| -m 匹配几次后停止 -v 反选 -i 忽略字符大小写 -n 显示匹配行号 -c 统计匹配行数 -o 仅显示匹配到的字符串 -q 静默模式 -A 后几行 -B 前几行 -C 前后各几行 -e 多个选项之间“或者”关系 -w 匹配整个单词 -E 启用扩展正则表达式=egrep -F 不支持正则表达式=fgrep -f 处理两个文件的相同内容,以第一个文件作为匹配条件 -r 递归,但不处理软链接 -R 递归,处理软链接 |
示例:A、B、C用法
| #打印包含halt的行以及下面三行 [root@localhost ~]# grep -A3 "halt" /etc/passwd halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin #打印包含halt的行以及上面三行 [root@localhost ~]# grep -B3 "halt" /etc/passwd lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt #打印包含halt的行以及上下面三行 [root@localhost ~]# grep -C3 "halt" /etc/passwd lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin |
过滤出带有某个关键词的行,并输出行号
| [root@localhost ~]# grep -n "root" /etc/passwd 1:root:x:0:0:root:/root:/bin/bash 10:operator:x:11:0:operator:/root:/sbin/nologin |
过滤出不带有某个关键词的行,并输出行号

过滤出所有包含数字的行
| [root@localhost ~]# grep "[0-9]" /etc/inittab # multi-user.target: analogous to runlevel 3 # graphical.target: analogous to runlevel 5 |
过滤掉所有以#开头的行
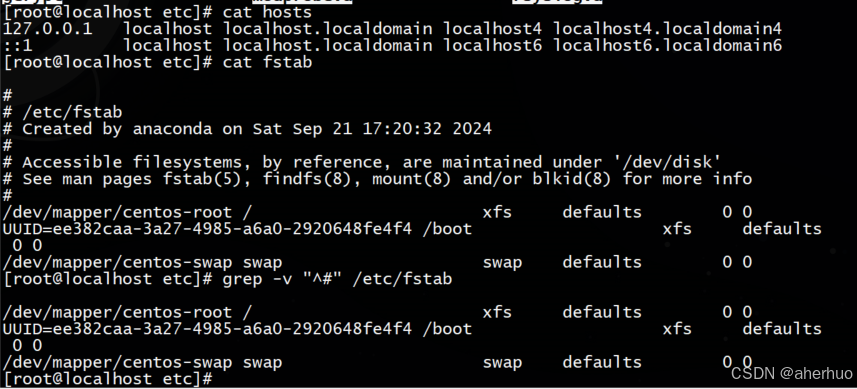
过滤掉所有空行和以#开头的行
| [root@localhost etc]# grep -v "^#" /etc/fstab |grep -v "^$" /dev/mapper/centos-root / xfs defaults 0 0 UUID=ee382caa-3a27-4985-a6a0-2920648fe4f4 /boot xfs defaults 0 0 /dev/mapper/centos-swap swap swap defaults 0 0 |
在正则表达式中,^表示行的开始,$表示行的结尾,那么空行则可以用^$表示
过滤出任意一个字符和重复字符
| [root@localhost ~]# grep "r.o" /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin .表示任意一个字符,上例中,r.o表示把r与o之间有一个任意字符的行过滤出来 [root@localhost ~]# grep "ooo*" /etc/passwd root:x:0:0:root:/root:/bin/bash lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin postfix:x:89:89::/var/spool/postfix:/sbin/nologin *表示零个或多个*前面的字符,上例中,ooo*表示oo、ooo、oooo.....或者更多的 [root@localhost ~]# grep ".*" /etc/passwd |wc -l 19 [root@localhost ~]# wc -l /etc/passwd 19 /etc/passwd *表示零个或多个*前面的字符,空行也包含在内,它会把/etc/passwd文件里面的所有行都匹配到 |
指定要过滤出的字符出现次数

多个模式条件匹配
| [root@localhost shell]# grep -e "root" -e "/bin/bash" /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin |
1.3.4 sed命令
sed编辑器是一种流编辑器,流编辑器会在编辑器处理数据之前基于预先提供的一组规则来编辑数据流
sed编辑器可以根据命令来处理数据流中的数据,这些命令要么从命令行中输入,要么存储在一个命令文本文件中
| s 替换,替换指定字符 d 删除,删除选定的行 a 增加,在当前行下面增加一行指定内容 i 插入,在选定行上面插入一行指定内容 c 替换,将选定行替换为指定内容 Y 字符转换,转换前后的字符长度必须相同 p 打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCII码输出。其通常与"-n"选项一起使用 = 打印行号 l 打印数据流中的文本和不可打印的ASCII字符(比如结束符$、制表符\t) |
打印某行
| [root@localhost ~]# sed -n '2'p /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin |
打印所有行
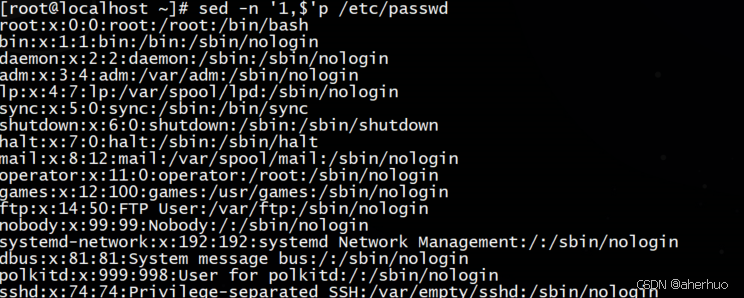
打印某个区间内的行数
| [root@localhost ~]# sed -n '1,3'p /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin |
打印包含某个字符串的行
| [root@localhost ~]# sed -n '/root/'p /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin |
删除某些行
| [root@localhost ~]# sed '1'd /etc/passwd |
Sed分组查找和替换
| [root@localhost ~]# echo 123xyzabc |sed -r 's/123(xyz)abc/\1/' xyz [root@localhost ~]# echo 123xyzabc |sed -r 's/(123)(xyz)(abc)/\1\2/' 123xyz [root@localhost ~]# echo 123xyzabc |sed -r 's/(123)(xyz)(abc)/\3\2\1/' abcxyz123 |
Sed变量查找
| [root@localhost ~]# sed -nr "/$name/p" /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@localhost ~]# sed -nr '/'$name'/p' /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin |
直接修改httpd的80端口
| [root@localhost ~]# grep "Listen" /etc/httpd/conf/httpd.conf # Listen: Allows you to bind Apache to specific IP addresses and/or # Change this to Listen on specific IP addresses as shown below to #Listen 12.34.56.78:80 Listen 80 [root@localhost ~]# port=8080 [root@localhost ~]# sed -ri 's/^Listen 80/Listen '$port'/' /etc/httpd/conf/httpd.conf [root@localhost ~]# grep "Listen" /etc/httpd/conf/httpd.conf # Listen: Allows you to bind Apache to specific IP addresses and/or # Change this to Listen on specific IP addresses as shown below to #Listen 12.34.56.78:80 Listen 8080 |
1.3.5 awk命令
awk是一种处理文本文件的语言,是一个强大的文本分析工具,可以在无交互的模式下实现复杂的文本操作,相较于sed常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理,因为awk相当适合小型的文本数据
awk格式及原理
awk命令逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理,awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印
| FS 列分隔符,指定每行文本的字段分隔符,默认为空格或制表位,与-F作用相同 NF 当前处理的行的字段个数 NR 当前处理的行的行号(序数) $0 当前处理的行的整行内容 $n 当前处理行的第n个字段(第n列) FILENAME 被处理的文件名 OFS 输出内容的列分隔符 RS 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’ $NF 最后一段 $(NF-1) 倒数第二段 |
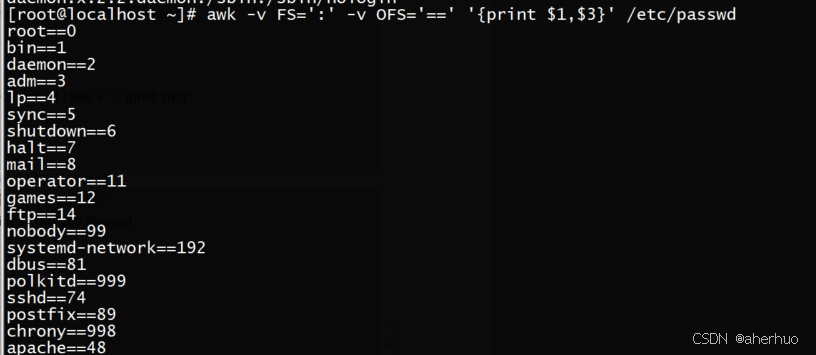
截取文档中的某个段
| [root@localhost ~]# head -n2 test.txt |awk -F ':' '{print $1}' root Bin 解析: Awk是一个强大的文本处理工具 -F‘:’:选项指定字段分隔符为冒号 {print $1}:表示打印每行的第一个字段 [root@localhost ~]# head -n2 test.txt |awk -F ':' '{print $0}' root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin |
匹配字符或者字符串
| [root@localhost ~]# awk '/oo/' test.txt root:x:0:0:root:/root:/bin/bash lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@localhost ~]# awk -F ':' '$1 ~/oo/' test.txt root:x:0:0:root:/root:/bin/bash |
条件操作符
| [root@localhost ~]# awk -F ':' '$3=="0"' /etc/passwd [root@localhost ~]# awk -F ':' '$3>="500"' /etc/passwd shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin polkitd:x:999:998:User for polkitd:/:/sbin/nologin sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin postfix:x:89:89::/var/spool/postfix:/sbin/nologin chrony:x:998:996::/var/lib/chrony:/sbin/nologin [root@localhost ~]# awk -F ':' '$3>=500' /etc/passwd polkitd:x:999:998:User for polkitd:/:/sbin/nologin chrony:x:998:996::/var/lib/chrony:/sbin/nologin |
awk的内置变量
awk常用的变量有OFS、NF和NR,OFS和-F选项有类似的功能,也是用来定义分隔符的,但是他是在输出的时候定义,NF表示用分隔符分隔后一共有多少段,NR表示行号
OFS的用法示例如下:输出内容的列分隔符
指定内容的列分隔符
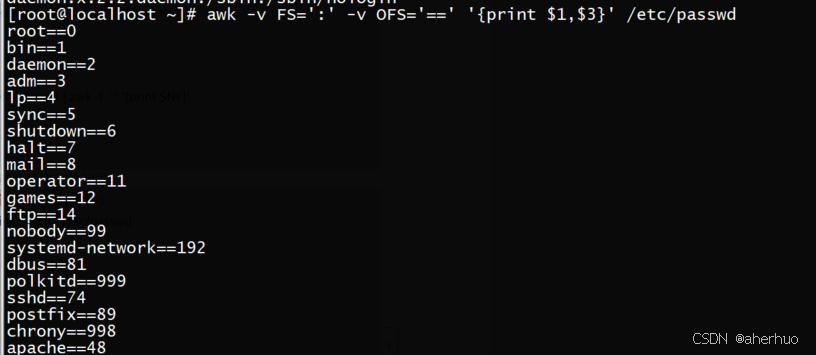
变量NF的具体用法如下:当前处理的行的字段个数
| [root@localhost ~]# head -n3 /etc/passwd |awk -F ':' '{print NF}' 7 7 7 [root@localhost ~]# head -n3 /etc/passwd |awk -F ':' '{print $NF}' /bin/bash /sbin/nologin /sbin/nologin |
RS:行分隔符,awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录进行处理预设值是“/n”
指定输入内容以分隔符并把每个分隔符的内容独行显示

变量NR的具体用法如下:当前处理的行的行号
| #打印源文件以分隔符的第一个字段且显示行号 [root@localhost ~]# awk -F: '{print $1,NR}' /etc/passwd root 1 bin 2 daemon 3 adm 4 lp 5 sync 6 shutdown 7 halt 8 mail 9 operator 10 games 11 ftp 12 nobody 13 systemd-network 14 dbus 15 polkitd 16 sshd 17 postfix 18 chrony 19 apache 20 #只打印第二行 [root@localhost ~]# awk 'NR==2{print $1}' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin #打印1~3行 [root@localhost ~]# awk 'NR==1,NR==3{print}' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [root@localhost ~]# head -n3 /etc/passwd |awk -F ':' '{print NR}' 1 2 3 |
$0:当前处理的行的整行内容
$0代表整行的内容,awk是逐行读取,配合$0即打印全文
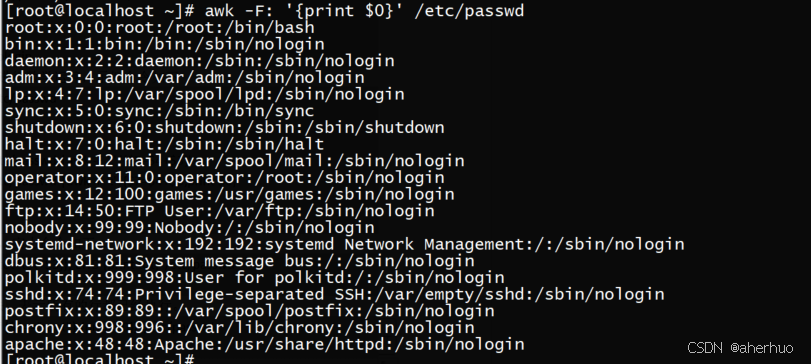
还可以使用NR作为判断条件,如下所示
awk可以更改段值,示例命令如下
| [root@localhost ~]# head -n 3 /etc/passwd |awk -F ':' '$1="root"' root x 0 0 root /root /bin/bash root x 1 1 bin /bin /sbin/nologin root x 2 2 daemon /sbin /sbin/nologin |
awk也可以进行对各个段的值进行数学运算,示例命令如下
| [root@localhost ~]# head -n2 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin [root@localhost ~]# head -n2 /etc/passwd |awk -F ':' '{$7=$4+$3}' [root@localhost ~]# head -n2 /etc/passwd |awk -F ':' '{$7=$4+$3;print $0}' root x 0 0 root /root 0 bin x 1 1 bin /bin 2 |
FILENAME:显示处理的文件名

awk还可以计算某个段的总和,实力命令如下
| [root@localhost ~]# awk -F ':' '{(tot=tot+$3)}; END {print tot}' /etc/passwd 2605 |
这里的END是awk特有的语法,表示所有的行都已经执行。
| [root@localhost ~]# awk -F ':' '{if ($1=="root") {print $0}}' /etc/passwd root:x:0:0:root:/root:/bin/bash |
二、脚本的调用形式
打开终端时系统自动调用:/etc/profile或~/.bashrc
/etc/profile
此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行,系统的公共环境变量在这里设置
开机自启动的程序,一般也在这里设置
~/.bashrc
用户自己的家目录中的.bashrc
登录时会自动调用,打开任意终端时也会自动调用
这个文件一般设置与个人用户有关的环境变量,如交叉编译器的路径等等
用户手动调用:用户实现的脚本

三、shell语法初识
3.1定义开头
第一行一定是:#!/bin/bash,该命令说明,该文件使用的是bash语法。如果不设置该行,则该脚本不会被执行。以#开头的行为解释说明。Shell脚本通常以sh为后缀,用于区分只这是一个shell脚本
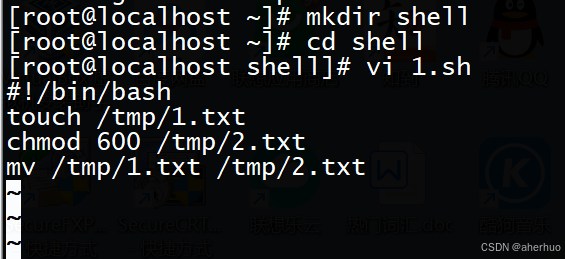
执行1.1编写的脚本

加上可执行权限

三种执行方式(./xxx.sh bash xxx.sh .xxx.sh)
(1)./xxx.sh:先按照文件中#!指定的解析器解析
如果#!指定的解析器不存在,才会使用默认的解析器
(2)bash xxx.sh:指明先用bash解析器解析
如果bash不存在,才会使用默认解析器
(3).xxx.sh直接使用默认解析器解析
3.2 date命令
3.2.1. 显示年、月、日
date +%Y-%m-%d #年(以四位数字格式打印年份)月日
date +%y-%m-%d #年(以两位数字格式打印年份)月日
date +%T #年(以四位数字格式打印年份)月日
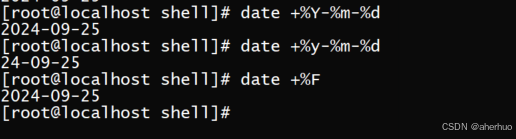
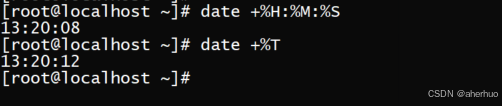
3.2.2 显示小时、分钟、秒
3.2.3 显示星期
date +%w #一周中的第几天
date +%W #一年中的第几周
3.2.4 时间戳
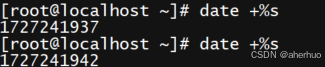
命令date +%s显示从1970年1月1日00:00:00UTC到目前为止的秒数
使用命令 date -d @1727241942显示输入秒数之前的时间
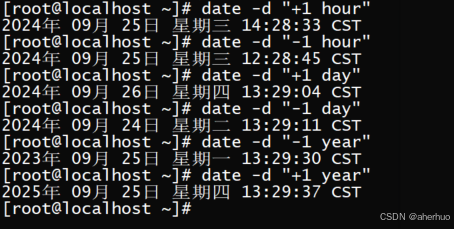
3.2.5 显示一个小时/一天/一年 之前\之后
3.3变量
在shell脚本中,变量用于存储和操作数据,变量可以存储各种类型的数据,如字符串、数字等
3.3.1定义变量
Shell支持三种定义变量的方式:
直接将字符串赋值给变量,用单引号包围字符串再赋值给变量,用双引号包围字符串再赋值给变量,如下所示:variadb是变量名,value是变量的值
| [root@localhost ~]# variadb=value [root@localhost ~]# variadb='value' [root@localhost ~]# variadb="value" |
●变量名通常是字母、数字和下划线的组合,但不能以数字开头
●定义变量时不需要声明类型,直接赋值即可
●赋值号的周围不能有空格
变量名=变量值
如: num=10 variadb_name=value
3.3.2引用变量
使用$符号来引用变量的值
例:echo $variadb_name
3.3.3删除变量
(1)使用unset命令可以删除变量
(2)unset命令不能删除只读变量
(3)变量被删除后不能再次使用
运行结果

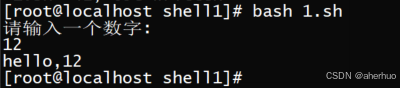
3.3.4 与用户交互
从键盘获取read值
运行结果
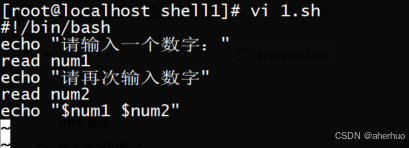
读取多个值
运行结果
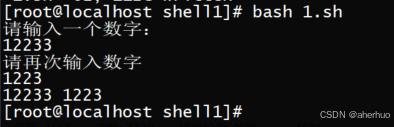
3.3.5内置变量
创建一个名为bian.sh的脚本
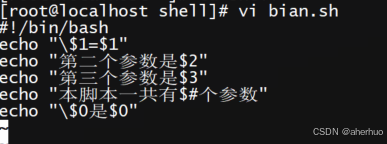
执行脚本后,再次执行脚本
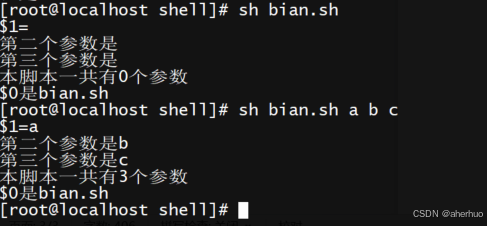
3.3.6 数学运算
Shell脚本中的变量常用于数学运算当中
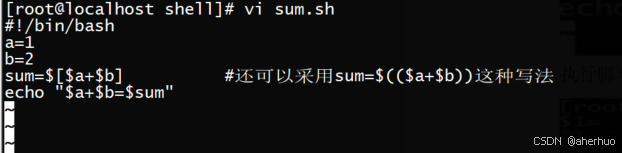
执行脚本

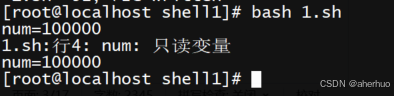
3.3.7只读变量
使用readonly命令可以将变量定义为只读变量,只读变量的值不能被改变
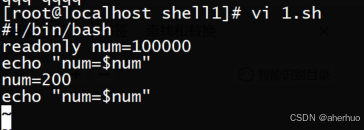
运行结果
Shell变量的作用域
Shell变量的作用域,指的是可以使用这个shell变量的范围
Shell变量的作用域可分为三种:
- 局部变量:变量只能在函数内部使用
- 全局变量:变量可以在当前shell进程中使用
- 环境变量:变量可以在子进程(shell所启动的程序)中使用
3.3.8 Shell局部变量
在shell函数中定义的变量默认是全局变量,要想让变量的作用域仅限于函数内部,在定义时加上local命令
| [root@localhost shell]# vi 1.txt #!/bin/bash function fun () { local a=66 } fun echo $a "1.txt" [New] 6L, 59C written [root@localhost shell]# bash 1.txt [root@localhost shell]# |
输出结果为空,说明变量a在函数外部无效,是一个局部变量
3.3.9 shell全局变量
全局变量就是指变量在当前的整个shell进程中都有效。每个shell进程都有自己的作用,彼此之间互不影响
3.3.10环境变量
使用export命令将全局变量导出,它就会在所有的子进程中也有效,这称为“环境变量”
设置环境变量
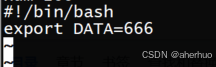
使用source命令使文件生效
Source Filename 作用:在当前bash环境下读取并执行Filename中的命令
| [root@localhost shell1]# source 1.sh [root@localhost shell1]# env |
使用env查看环境变量中已有DATA
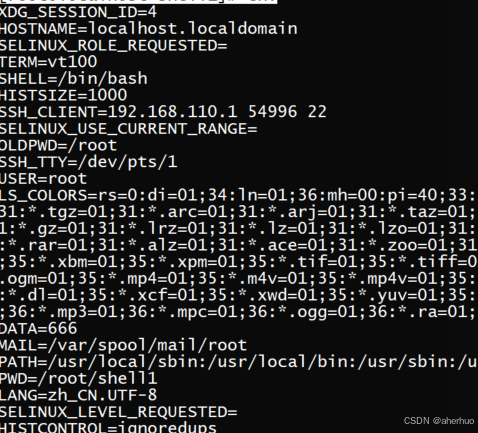
也可在终端读取
| [root@localhost shell1]# echo $DATA 666 |
在其他sh脚本读取
| [root@localhost shell1]# vi 2.sh #!/bin/bash echo "DATA=$DATA" [root@localhost shell1]# bash 2.sh DATA=666 |
如果想在PATH变量中追加一个路径写法
export PATH=$PATH:/需要添加的路径
3.3.11预设变量
Shell直接提供无需定义的变量

案例
| [root@localhost shell1]# vi 1.sh #!/bin/bash echo "参加的个数=$#" echo "参加的内容=$*" echo "第一个参数:$1" echo "第二个参数:$2" echo "第三个参数:$3" readonly data=10 data=666 echo "data=250的结果:$?" echo "进程名:$0" echo "进程号:$$" |
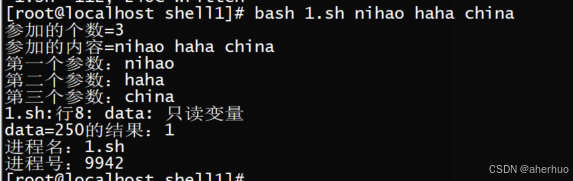
脚本标量的特殊用法

单引号与双引号的区别
定义变量时,变量的值可以由单引号包围,也可以由双引号包围,它们有什么区别呢?
- 单引号包围变量的值时,单引号里面是什么就输出什么,即使内容中有变量和命令(命令反引起来)也会把他们照样输出。这种方式比较适合定义显示纯字符串的情况下
- 双引号包围变量的值时,输出时会先解析里面的变量和命令,而不是把双引号中的变量名和命令原样输出。这种方式比较适合字符串中附带有变量和命令并且想将其解析后再输出的变量定义
- 如果需要原样输出就加单引号;没有别的要求的字符串等最好都加上双引号
3.3.12变量的扩展
判断变量是否存在
| #!/bin/bash #${num:-val} 如果num存在,整个表达式的值为num,否则为val echo ${num:-100} #100 num=200 echo ${num:-100} #200 #!/bin/bash # ${num:=val} 如果num存在,整个表达式的值为num,\ #否则为val,同时将num的值赋值为val echo ${num:=100} #100 echo "num=$num" #100 |
3.4字符串的操作
| [root@localhost shell1]# vi 1.sh #!/bin/bash str="hehe:haha:xixi:lala" #测试字符串的长度${#str} echo "str的长度为:${#str}" #19 #从下标3为位置提取${str:3} echo ${str:3} #"e:haha:xixi:lala" #从下标为3的位置提取长度为6字节 echo ${str:3:6} #"e:haha" #${str/old/new} 用new替换str中出现的第一个old echo ${str/:/#} #"hehe#haha:xixi:lala" # $ {str//old/new} 用new替换str中所有的old echo ${str//:/#} #"hehe#haha#xixi#lala" |
运行结果
| [root@localhost shell1]# bash 1.sh str的长度为:19 e:haha:xixi:lala e:haha hehe#haha:xixi:lala hehe#haha#xixi#lala |
3.5条件测试
test命令:用于测试字符串、文件状态和数字
test命令格式:test condition 或[condition]
文件测试
文件测试:测试文件状态的条件表达式
-e 是否存在 -d 是目录 -f 是文件 -r 可读 -w 可写 -x 可执行
-L 连接符号 -c 是否字符设备 -b 是否块设备 -s 文件非空
| #!/bin/bash read -p "请输入一个文件名" filename [ -e $filename ] echo $? [root@localhost shell1]# bash 1.sh 请输入一个文件名1.sh 0 |
字符串测试

运行结果
3.6数值测试


| #!/bin/bash read -p "请输入第一个数值" data1 read -p "请输入第二个数值" data2 test $data1 -eq $data2 echo "相等:$?" test $data1 -ge $data2 echo "大于等于:$?" [ $data1 -lt $data2 ] echo "小于:$?" |
运行结果
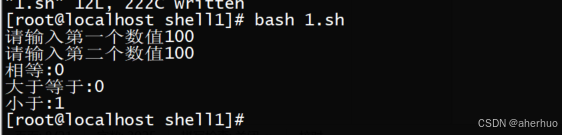
符合语句测试

多重条件判定

四、shell中的逻辑判断
4.1 不带有else
基础结构:
if 判断语句; then
command
fi
示例如下:
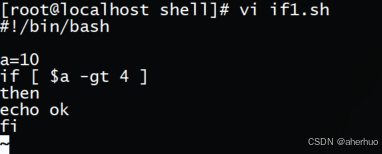
执行脚本
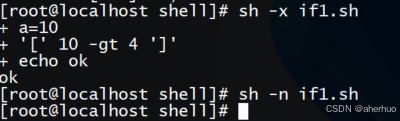
4.2 带有else
基础结构
if 判断语句 ; then
command
else
command
fi
示例如下:
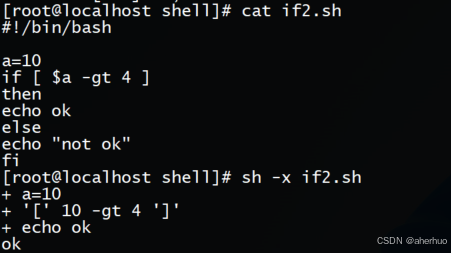
4.3 带有elif
示例如下:
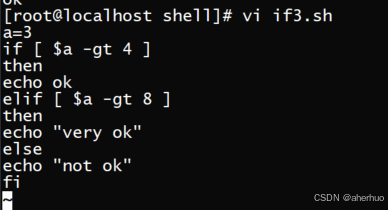
执行脚本
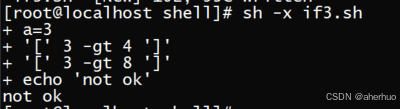
4.4 嵌套
示例如下

执行脚本
4.5多个条件
if [ $a -gt 5 ] && [ $a -lt 10 ] == if [ $a -gt 5 -a $a -lt 10] # -a表示 and
if [ $b -gt 5 ] || [ $b -lt 3] == if [ $b -gt 5 -o $b -lt 3 ] # -o表示 or
4.6 if控制语句
4.6.1 if判断文件的目录属性
shell脚本中if经常用于判断文档的属性,比如判断是普通文件还是目录,判断文件是否有读、写、执行权限等。If常用选项如下:
-e:判断文件或目录是否存在。
-d:判断是不是目录以及是否存在。
-f:判断是不是普通文件以及是否存在。
-T:判断是否有读权限。
-w:判断是否有写权限。
-X:判断是否可执行。
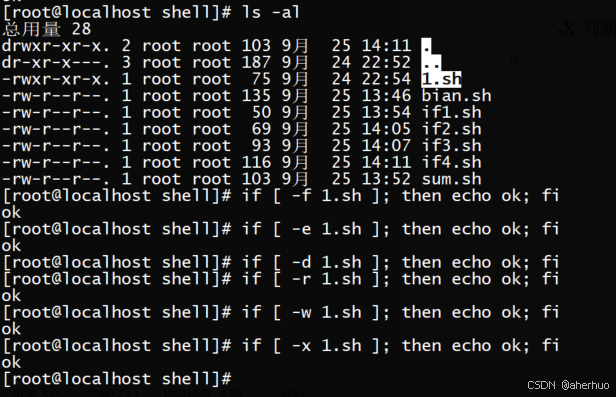
Root用户对文件的读写比较特殊,即使一个文件没有给root用户读或者写的权限,root也可以读或者写
4.6.2 if判断的一些特殊用法
命令if[ -z “$a”];表示当变量a的值为全空时会怎么样

命令 if [ -n "$a" ]; 表示当变量a的值不为空时会怎么样

命令 if grep -q '123' 1.sh; then 表示如果1.sh中含有’123’会怎么样,其中-q表示即使过滤出内容也不要打印出来

if (($a<1)); then 等同于 if [ $a -lt 1 ];then 二者都可以用来进行判断,需要注意的是,当我们未对变量a进行赋值时则会报错,如下图所示
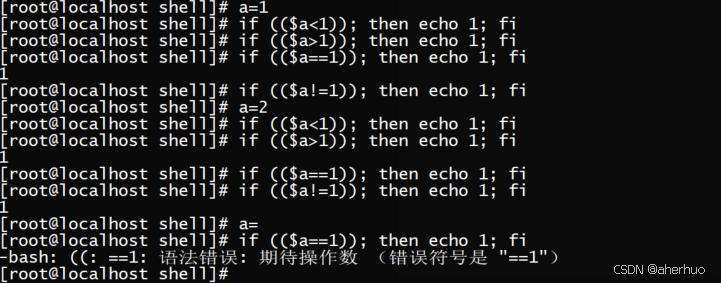
注意:[ ]中不能使用<,>,==,!=,>=,<=这样的符号,需要时要使用固定写法 -gt (>); -lt(<); -ge(>=); -le(<=);-eq(==); -ne(!=)。
4.6.3 if格式
格式一:
if [条件1]; then
执行第一段程序
else
执行第二段程序
fi
格式二:
if [条件1]; then
执行第一段程序
elif [条件2];then
执行第二段程序
else
执行第三段程序
fi
案例分析
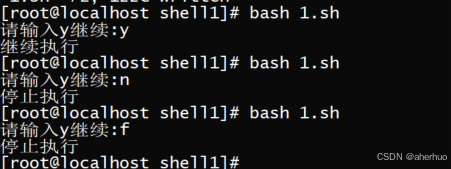
| #!/bin/bash read -p "请输入y继续:" yn if [ $yn = "y" ];then echo "继续执行" else echo "停止执行" fi |
运行结果
案例:判断当前路径下没有文件夹,有就进入创建文件夹,没有就创建文件夹,在进入文件夹
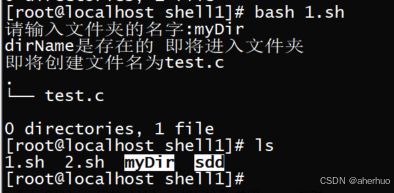
| #!/bin/bash read -p "请输入文件夹的名字:" dirName #判断文件夹是否存在 if [ -e $dirName ]; then echo "dirName是存在的 即将进入文件夹" cd $dirName echo "即将创建文件名为test.c" touch test.c else #不存在 echo "该文件 不存在 即将创建该文件夹" mkdir $dirName echo "进入$dirName里面" cd $dirName echo "即将创建文件test.c" touch test.c fi tree |
运行结果
案例分析
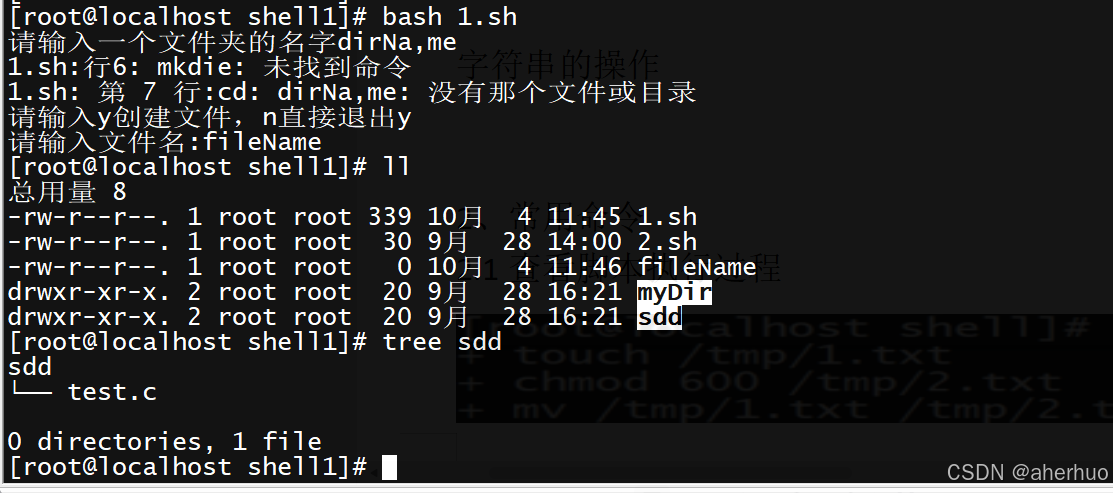
| #!/bin/bash read -p "请输入一个文件夹的名字" dirName if [ -e $dirName ]; then cd $dirName else mkdie $dirName cd $dirName fi read -p "请输入y创建文件,n直接退出" yes if [ $yes = "y" ]; then read -p "请输入文件名:" fileName touch $fileName elif [ $yes = "n" ]; then echo "退出了" fi |
运行结果:
4.7 case控制语句

案例分析:
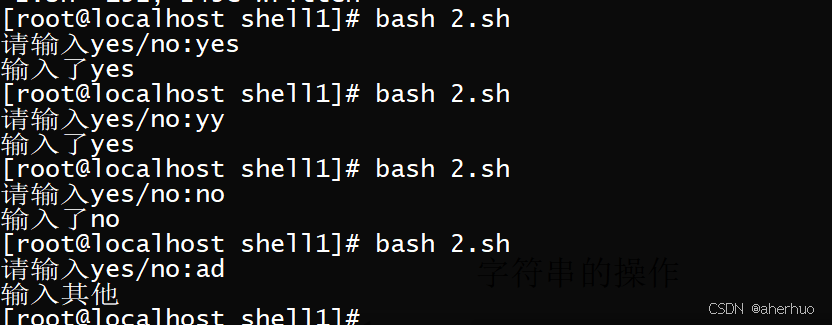
| [root@localhost shell1]# vi 2.sh #!/bin/bash #!/bin/bash read -p "请输入yes/no:" choice case $choice in yes | y* | Y*) echo "输入了yes" ;; no | n* |N*) echo "输入了no" ;; #break *) #default echo "输入其他" ;; esac |
运行结果
4.8 for循环语句
形式一:
for ((初始值;限制值;执行步阶))
do
程序段
done
解析:
初始值:变量在循环中的起始值
限制值:当变量在这个限制范围内时,就继续进行循环
执行步阶:每作一次循环时,变量的变化量
declare是bash的一个内建命令,可以用来声明shell变量、设置变量的属性。Declare也可以写作typeset
Declare -i s 代表强制把s变量当做int型参数运算
案例分析
| #!/bin/bash #显示使用declare执行为int类型 declare -i sum=0 declare -i i=0 for (( i-0; i<=100; i++ )) do sum=$sum+$i; done echo "sum=$sum" |
运行结果

形式二:
for var in con1 con2 con3 ...
do
程序段
done
第一次循环时,$var的内容为con1
第二次循环时,$var的内容为con2
第三次循环时,$var的内容为con3
........
案例分析
| #!/bin/bash #显示使用declare执行为int类型 declare -i sum=0 declare -i i=0 for i in 1 2 3 4 5 6 7 8 9 10 do sum=$sum+$i; done echo "sum=$sum" |
运行结果

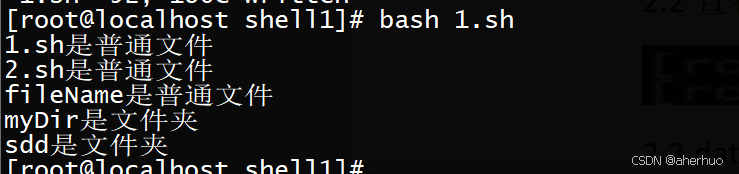
案例:扫描当前文件
| #!/bin/bash for fileName in `ls` do if [ -d $fileName ]; then echo "$fileName是文件夹" elif [ -f $fileName ];then echo "$fileName是普通文件" fi done |
运行结果
4.9 while
while [condition]
do
程序段
done
当condition成立的时候进入while循环,直到condition不成立时才退出循环
案例分析
| #!/bin/bash declare -i i declare -i s while [ "$i"="101" ] do s+=i; i=i+1; done echo "The count is $s" |
4.10 until
until [condition]
do
程序段
done
这种方式与while恰恰相反,当condition成立的时候退出循环,否则继续循环
案例分析:
| #!/bin/bash declare -i i declare -i s until [ "$i"="101" ] do s+=i; i=i+1; done echo "The count is $s" |
4.10 break continue exit
break 命令允许跳出循环
break 通常在进行一些处理后退出循环或case语句
continue 命令类似于break命令
只有一点重要差别,它不会跳出循环,只是跳过这个循环步
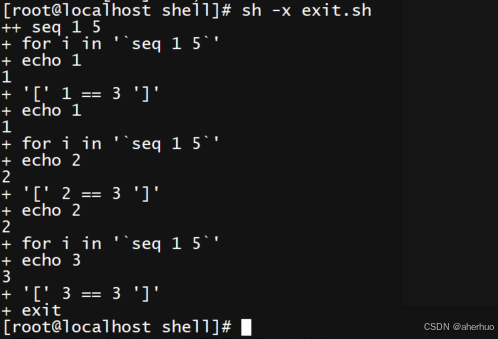
当我们在shell脚本中遇到exit时,其表示直接退出整个shell脚本
exit 用于退出整个shell脚本
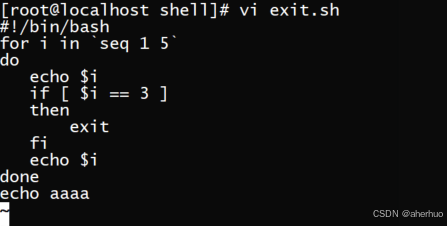
执行过程
五、函数
函数function是由若干条shell命令组成的语句块,实现代码重用和模块化编程,它与shell程序形式上是相似的,不同的是它不是一个单独的进程,不能独立运行,而是shell程序的一部分
5.1 函数格式:
格式一:
函数名 () {
函数体
}
格式二:
function 函数名 (){
命令 ...
}
格式三:
function 函数名{
命令序列
}
所有函数在使用前必须定义,必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用
说明:
★function是shell中的关键字,专门用来定义函数;可以带function funname()定义,也可以直接funname()定义,不带任何参数
★funname是函数名
★函数体是函数要执行的代码,也就是一组语句
5.2 函数的返回值
return int 表示函数的返回值,其中return是shell关键字,专门用在函数中返回一个值;这一部分可写可不写,如果不加,将以最后一条命令运行结果,作为返回值
5.3 函数变量
语法:num=1
变量作用域
局部变量:作用域是函数的生命周期;在函数结束时被自动销毁
定义局部变量的方法:lacal VAR=VALUE
全局变量:作用域是运行脚本的shell进程的生命周期,其作用范围为当前shell
全局变量示例
| #!/bin/bash #在函数外定义本地变量 var="Hello,World" function show () { #在函数内改变变量内容 var="Hi,var is changed" echo “$var” } echo "$var" show echo "$var” |
执行结果

局部变量示例
| #!/bin/bash #在函数外定义本地变量 var="Hello,World" function show () { #在函数内改变变量内容 local var="Hi,var is changed" echo "$var" } echo "$var" show echo "$var" |
执行结果

5.4 函数调用
定义函数的代码段不会自动执行,而是在调用时执行;在函数定义好后,用户可以在shell中直接调用,调用时不用带上();调用shell函数时可以给它传递参数,也可以不传递。如果不传递,直接给出函数名字即可
| #!/bin/bash #函数定义 function show () { echo "hello,world" } show |
运行结果

5.5 函数传参
函数传参调用语法:
函数名 参数1 参数2 ...
在shell中,调用函数时可以向其传递参数。在函数体内部,函数中的变量均为全局变量,没有局部变量,若使用局部变量需要在变量前加上local,通过$n的形式来获取参数的值
示例
| #!/bin/bash function show () { echo "第一个参数为$1!" echo "第二个参数为$2!" echo "第十个参数为$10!" echo "第十个参数为$[10]!" echo "第十一个参数为${11}!" echo ”参数总数有$#个“ echo "作为一个字符串输出所有参数$*!" } show 0 1 2 3 4 5 6 7 8 9 10 11 |
运行结果
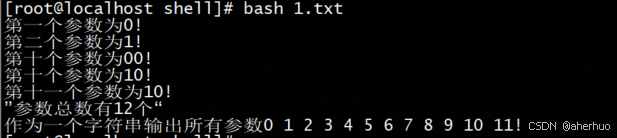
注:$10不能获取第十个参数,获取第十个参数需要${10}。当n>=10时,需要使用$n来获取参数
| 参数处理 | 说明 |
| $# | 传递到脚本的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数 |
| $$ | 脚本运行时当前进程ID号 |
| $! | 与$*相同,使用时加引号,在引号中返回每个参数 |
| $@ | 与$*相同,使用时加引号,在引号中返回每个参数 |
| $- | 显示shell使用的当前选项,与set命令功能相同 |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误 |
5.6 退出状态码
Shell中运行的每个命令都使用退出状态码(exit status)来告诉shell它完成了处理。退出状态码是一个0-255之间的整数值,在命令结束运行时由命令传给shell
Linux退出状态码
| 状态码 | 描述 |
| 0 | 命令成功结束 |
| 1 | 通用未知错误 |
| 2 | 误用shell命令 |
| 126 | 命令不可执行 |
| 127 | 没找到命令 |
| 128 | 无效退出参数 |
| 128+x | Linux信号x的严重错误 |
| 130 | 通过Ctrl+C终止 |
| 255 | 退出状态码越界 |
示例一
| #!/bin/bash #函数定义 function show () { echo $(date +%y-%m-%d) } show echo $? |
运行结果

示例二
| #!/bin/bash SYS_DATE=$(date +%Y%m%d) echo $SYS_DATE # 函数定义 function show(){ log=`lt` echo log return 2 } show echo $? |
运行结果
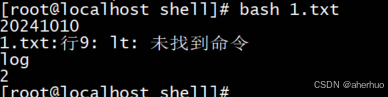
这次,由于函数最后一行命令正确执行,函数的退出状态码就是0,尽管函数中有一条命令没有成功运行。使用函数的默认退出状态码是很危险的,幸运的是return命令可以解决这个问题
5.7 函数返回值
(1)return语句
Shell函数的返回值通过return语句返回时,只能用来返回整数值
| #!/bin/bash function getResultFun(){ echo "这是我的第一个 shell 函数!" return `expr 1 + 1` } getResultFun echo $? |
运行结果

Shell 函数返回值只能是整形数值,一般是用来表示函数执行成功与否的,0表示成功,其他值表示失败。用函数返回值来返回函数执行结果是不合适的。如果return某个计算结果,比如一个字符串,往往会得到错误提示:“numeric argument required”。
如果一定要让函数返回一个或多个值,可以定义全局变量,函数将计算结果赋给全局变量,然后脚本中其他地方通过访问全局变量,就可以获得那个函数“返回”的一个或多个执行结果了。
示例
(2)echo语句
Echo是通过输出到标准输出返回,可以返回任何类型的数据
示例
| #!/bin/sh function getStr(){ return "string" } getStr #!/bin/sh function test() { echo "arg1 = $1" if [ $1 = "1" ] ;then echo "1" else echo "0" fi } echo echo "test 1" test 1 echo echo "test 0" test 0 echo echo "test 2" test 2 |
运行结果
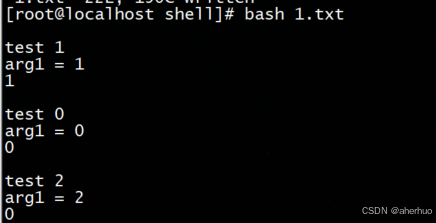
六、shell中的数组
在shell脚本中,数组是一种可以存储多个值的数据结构,数组可以让你在一个变量中存储和操作一组相关的数据
6.1 数组声明
| [root@localhost shell]# declare -a array_name #声明数组,也可不声明 [root@localhost shell]# declare -a nums=(1 2 3 4) #声明数组,同时也可赋值 [root@localhost shell]# unset arrary_name #删除数组,撤销数组 [root@localhost shell]# unset nums[0] #删除数组中的某个元素 |
6.2 数组定义
方式一:
array_name=(
Value0
Value1
Value2
)
方式二:
Names=(xiaoming xiaoli xiaoyan )
方式三:
Names[0]=xiaoming
Names[1]=xiaoli
Names[2]=xiaoyan
方式四:
Names=([0]=xiaoming [1]=xiaoli [2]=xiaoyan)
方式五:
Str=”xiaoming xiaoli xiaoyan”
Names=($str)
注意事项:
(1)数组中的元素,必须以"空格"来隔开,这是其基本要求;
(2)定义数组其索引,可以不按顺序来定义,比如说:names=([0]=xiaoming [1]=xiaoli [4]=xiaoyan);
(3)字符串是SHELL中最重要的数据类型,其也可通过($str)来转成数组,操作起来非常方便
6.3数组读取
首先我们需要先定义一个数组a=(1 2 3 4 5);
命令 echo ${a[@]} 读取数组中的全部元素。示例如下:

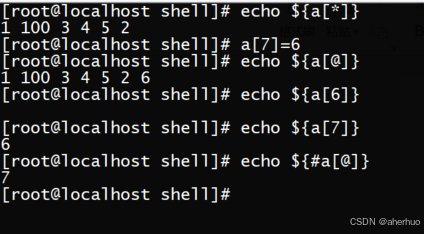
命令 echo ${#a[@]} 获取数组的元素个数。示例如下:

命令 echo ${a[2]} 读取第三个元素,数组从0开始。示例如下:

echo ${a[*]} 等同于 ${a[@]} 作用为显示整个数组。示例如下

数组索引
| [root@localhost shell]# s="A B C D" [root@localhost shell]# a=(`echo $s | tr ',' ','`) [root@localhost shell]# echo ${!a[@]} 0 1 2 3 |
6.4数组赋值
a[1]=100; echo ${a[@]} 替换指定的元素值。示例如下
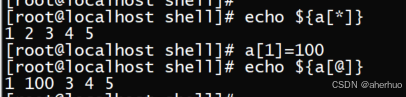
a[5]=2; echo ${a[@]} 如果下标不存在则会自动添加一个元素。示例如下:
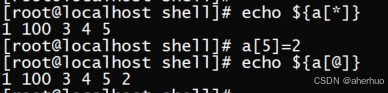
a[7]=6; echo ${a[@]} 跳着添加元素时,中间未赋值的元素,不显示且无值。示例如下:
6.5数组的删除
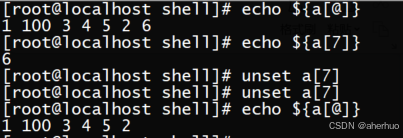
命令unset a[1] 用于删除单个元素。示例如下
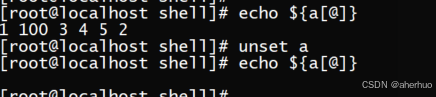
命令unset a 用于删除整个数组。示例如下:
6.6数组添加
方式一:直接赋值给不在的索引一个值
| nums=(1 2 3 4) #定义一个数组 nums[4]=5 #给第四个新元素赋值 echo ${nums[@]} #结果变成1 2 3 4 5 |
方式二:直接使用 新数组=(旧数组 新元素)的方式来添加元素
| old=(1 2 3 4) new=(${old[*]} 5) echo ${new[@]} |
6.7数组分片
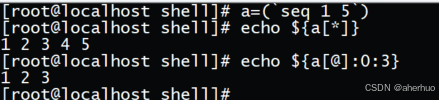
在进行实验操作之前,需要对一个数组进行赋值 a=(`seq 1 5`) 。
命令echo ${a[@]:0:3} 表示从第一个元素开始,截取3个元素,并打印出来。示例如下:
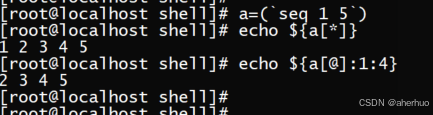
命令echo ${a[@]:1:4} 表示从第二个元素开始,截取4个元素,并打印出来。示例如下:
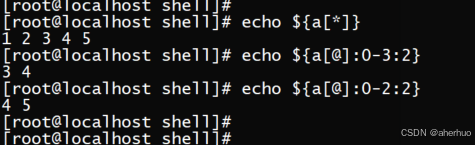
echo ${a[@]:0-3:2} 表示从倒数第3个元素开始,截取2个元素,并打印出来。示例如下:
6.8数组替换
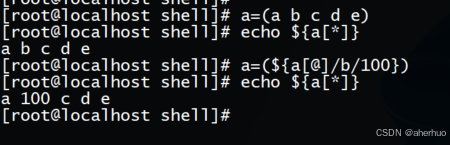
使用命令echo 使用命令a=(${a[@]/b/100}) 表示用100替换b,这种方法不仅可以打印出来还可以保存替换。示例如下:

使用命令a=${a[@]/b/100} 表示用100替换b,但不会保存替换,只是打印出来。示例如下:
6.9数组应用
示例:在1-10之间,随机生成10个不重复的数,将其放置于数组中
| [root@localhost shell]# vi 1.txt #!/bin/bash declare -a array array=(`seq 1 10 | awk 'BEGIN{srand();ORS=" "} \ {b[rand()]=$0} END{for(x in b) print b[x]}'`) echo "数组中随机生成10个数为:${array[@]}" |
运行结果

(1)生成[1,10]范围内不重复的随机整数,并保存到数组array中
(2) seq 1 10 用于生成1~10的整数序列(包含边界值1和10)
(3)awk中的rand()函数用于随机产生一个0到1之间的小数值(保留小数点后6位)
(4)rand()只生成一次随机数,要使用srand()函数使随机数滚动生成
(5)括号里留空即默认采用当前时间作为随机计数器的种子,这样以秒为间隔,随机数就能滚动随机生成了
(6)由于以秒为间隔,所以如果快速连续运行两次脚本(1s内),你会发现生成的随机数还是一样的