文章目录
- 零、tensorboard
- 一、数据结构:Tensor
- 1.1数据类型
- 1.1Tensor的创建方式
- 1.2张量的基本运算
- 二、数据集加载器DataLoaders
- 2.0前置知识
- 2.0.1torch.scatter()、torch.scatter_()
- 2.1官方案例
- 2.1.1从TorchVision加载数据集
- 2.1.2迭代和可视化数据集
- 2.2创建自定义数据集Dataset
- 2.2.1官方文档
- 2.2.2自定义数据集
- 2.3数据集加载器DataLoader
- 2.3.1函数介绍
- 2.3.2读取数据
- 2.3.2可视化drop_last作用
- 2.3.3可视化shuffle作用
- 三、Transforms
- 3.1transforms.ToTensor()
- 3.2transforms.Normalize()
- 3.3
- 二、自动求导
- 2.1backward()、torch.autograd.grad()案例
- 2.1.1backward()
- 2.1.2torch.autograd.grad()
- 2.2Pytorch动态图机制
Torchvision、torchaudio和torch是PyTorch框架的三个重要组成部分:
torch:是PyTorch的一个核心库提供了张量(tensor)操作和计算图构建的功能,也提供了自动求导(Autograd)功能,使得用户可以轻松地构建和训练神经网络模型。Torchvision:是PyTorch的一个独立子库,主要用于计算机视觉任务,包括图像处理、数据加载、数据增强、预训练模型等。在Torchvision中提供了各种经典的计算机视觉数据集的加载器,如CIFAR-10、ImageNet,以及用于数据预处理和数据增强的工具,可以帮助用户更轻松地进行图像分类、目标检测、图像分割等任务。Torchaudio:是PyTorch的一个独立子库,用于处理音频信号和音频数据,提供了加载、处理和转换音频数据的工具,以及用于构建声音处理模型的函数。
零、tensorboard
一、数据结构:Tensor
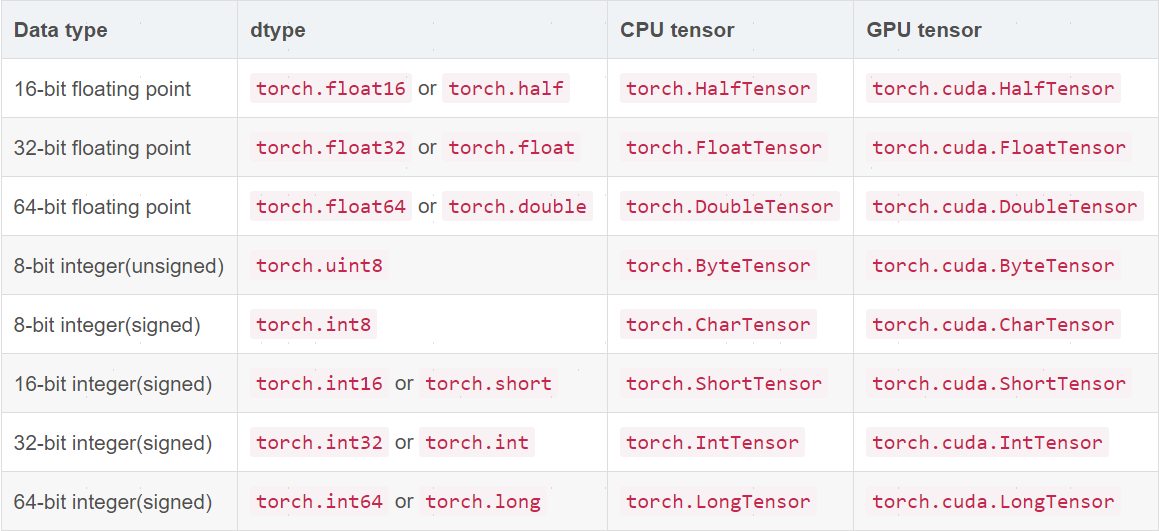
1.1数据类型
Tensor,即张量,是PyTorch中的基本操作对象,可以看做是包含单一数据类型元素的多维矩阵。Tensor与numpy中的ndarrays对象,不同之处在于,Tensor对象可在CPU、GPU上进行运算,而ndarrays对象只能在CPU上进行运算。Tensor共有八种数据类型,其中有七种只能在CPU上运算,在创建张量时即可指定所含的数据类型:
import torch
x = torch.rand(2, 3, dtype=torch.float32)
y = torch.rand(2, 3, dtype=torch.double)
print(x, y, sep='\n')

1.1Tensor的创建方式
Tensor对象与Ndarrays对象的创建方式基本一致:
| 方法名 | 说明 |
|---|---|
| Tensor() | 指定大小创建Tensor对象,支持将list、numpy数组转化为Tensor类型 |
| eye() | 创建指定大小的单位阵 |
| linspace(start,end,count) | 创建[start,end]内含有count个元素的一维tensor |
| logspace(start,end,count) | 创建[ 1 0 s t a r t 10^{start} 10start, 1 0 e n d 10^{end} 10end]内含有count个元素的一维tensor |
| ones(size) | 返回大小为size全1的Tensor对象 |
| zeros(size) | 返回大小为size全0的Tensor对象 |
| ones_like(t) | 传入Tensor对象,返回相同大小且全1的Tensor对象 |
| zeros_like(t) | 传入Tensor对象,返回相同大小且全0的Tensor对象 |
| arange(start,end,step) | 在区间[s,e)上以间隔sep生成一个序列张量 |
| rand() | 创建均匀分布的张量,范围为[0,1) |
| randn() | 创建正态分布的张量,范围为[0,1) |
| randperm() | 创建含有[0,n)数据的张量,并随机排列 |
| empty() | 创建未初始化的张量 |
import torch
import numpy as np#1.Tensor()
t1 = torch.Tensor(2, 3, 3)
t2 = torch.Tensor(np.arange(2, 3)) #从numpy对象创建Tensor
t3 = torch.Tensor([[1, 2], [3, 3]]) #从list对象创建Tensor#2.eye()
t4 = torch.eye(2, 3)#3.linspace()
t5 = torch.linspace(1, 50, 3)#4.logspace()
t6 = torch.logspace(2, 3, 10)#5.ones_like()
t7 = torch.ones_like(t6)#6.zeros_like()
t8 = torch.zeros_like(t7)#7.arange()
t9 = torch.arange(1, 10, 2)#8.创建均匀分布的张量
t10 = torch.rand((2,3))#9.创建正态分布的张量
t11 = torch.randn((2, 3))#10.创建含有n个整数,随机排列的Tensor
t12 = torch.randperm(10)#10.创建未初始化的张量
t13 = torch.empty((2, 3))
1.2张量的基本运算
| 函数 | 作用 |
|---|---|
| torch.abs(A) | 将张量元素取绝对值并返回 |
| torch.add(A,B) | 将两个张量对应元素相加并返回,支持常量运算、广播运算 |
| torch.clamp(A,min,max) | 裁剪张量,小于min的元素置换为min,大于max的元素同理 |
| torch.div(A,B) | 将两个张量对应元素相除并返回,支持常量运算、广播运算 |
| torch.pow(A,B) | 以A元素为底数,B元素为指数运算,支持常量运算、广播运算 |
| torch.mm(A,B) | 将两个张量作矩阵乘法,需满足运算法则,且二者必须是矩阵,不能是向量 |
| torch.mv(A,B) | 将矩阵A与向量B进行矩阵向量乘法运算 |
| Tensor.T | 将Tensor进行转置操作 |
| Tensor.numpy() | 将Tensor对象转为Numpy类型 |
| Tensor.item() | |
| Tensor.shape | 查看形状 |
| Tensor.dtype | 查看数据类型 |
| Tensor.viem() | 相当于shape(),返回修改后的新张量 |
| A[1:]、A[-1,-1]=100 | 、A[:,:-1] |
| torch.stack((A,B),dim) | 指定维度拼接张量,同numpy的stack()操作 |
二、数据集加载器DataLoaders
Pytorch中提供了数据加载器,存于torch.utils.data包下,用于对数据进行批量加载和处理。事实上,模型的训练过程通常需要大量的数据,而将所有数据一次性加载到内存中是不可行的。这时候就需要使用数据加载器DataLoader将数据分成小批次进行加载。并且,DataLoader可以自动完成数据的批量加载、随机洗牌(shuffle)、并发预取等操作,从而提高模型训练的效率。同时,可使用torchvision提供的工具进行常用的图像处理。
2.0前置知识
2.0.1torch.scatter()、torch.scatter_()
torch.scatter()与torch.scatter_()功能相同,但scatter()不会修改原来的Tensor,后者则会直接在原Tensor上进行修改。常用参数:
ouput = torch.scatter(input, dim, index, src)
# 或者是
input.scatter_(dim, index, src)
src:源Tensor对象。index:选中需要填充的input元素,当src是Tensor对象时,index形状需与src相同。dim:决定index操作的维度。input:被修改的Tensor对象,与src类型(dtype)应相同。
dim=0:遵循映射规则input[index[i][j]][j] = src[i][j]
链接
链接
index=[0,0,1]表示对第0、1个数据执行操作,相应的,index=[1,0,0]表示对第1、2个数据进行操作。而src中对数据索引的定义方式需使用dim进行指定。当dim=0时,表示对src维度0的数据操作:
当dim=1时表示对src维度1的数据进行操作:

执行代码:
2.1官方案例
2.1.1从TorchVision加载数据集
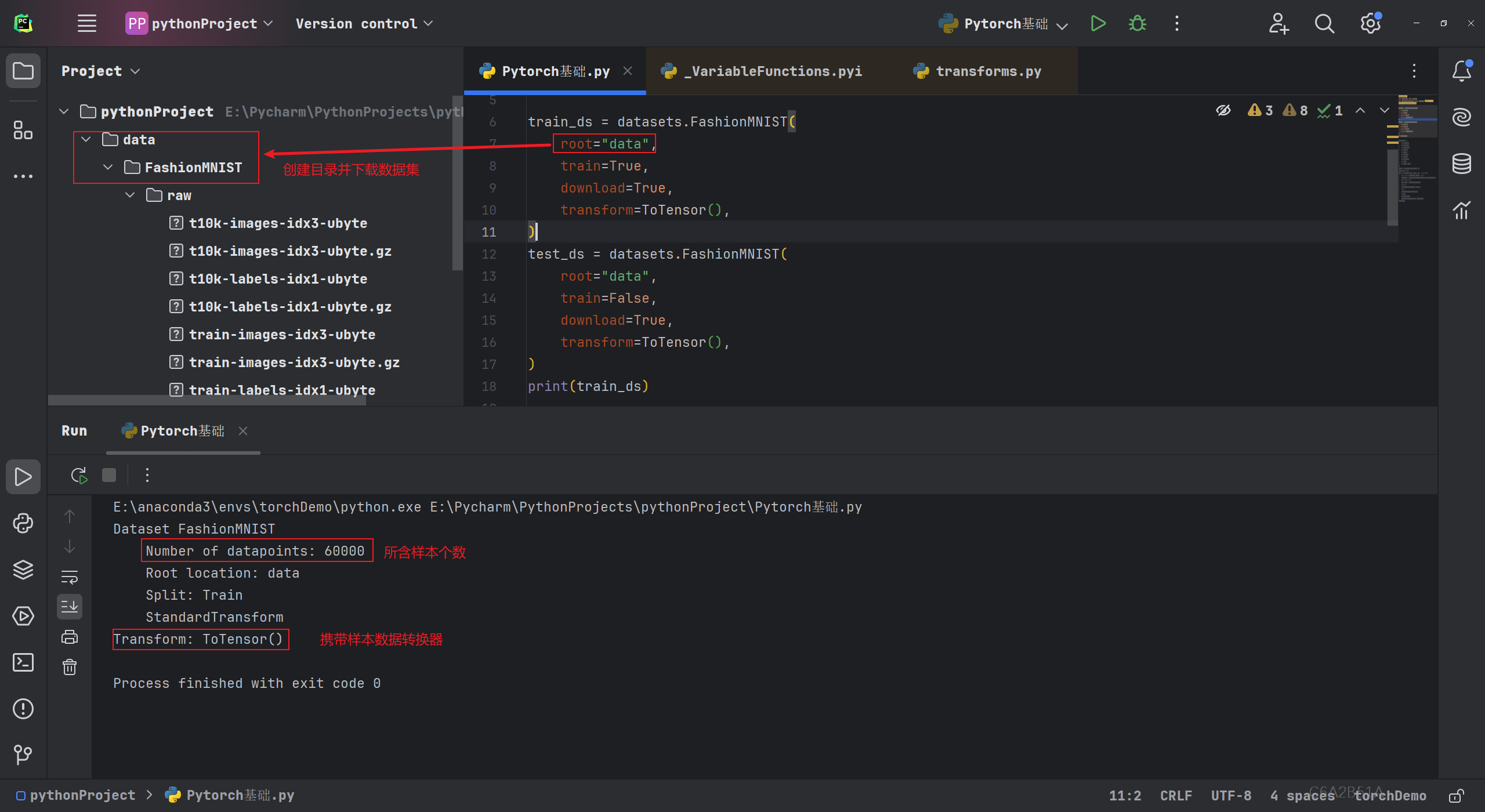
在TorchVision模块中提供了一些常用的图片数据集,如MNIST、COCO等。现使用DataLoader加载Fashion-MINIST数据集示例,数据集中包含7000个28x28灰度图像,其中6000个用作训练,一共有10个类别标签。使用了如下参数:
root:指定本地存储训练/测试数据的路径。train:指定加载测试集或训练集数据。download:若无法从root路径中加载数据集,则从网络上进行下载。transform:使用转换器预处理数据。target_transform:使用转换器预处理标签。
torchvision.transforms下的ToTensor可用于对特征数据进行预处理;
ToTensor:将PIL图像或NumPy ndarray转换为浮点张量,并将特征张量归一化处理,处理后范围为[0,1]。若大小为[HxWxC]则处理后大小为[CxHxW],即[通道,高度,宽度],卷积层默认使用该方式输入。
执行代码下载数据集:
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambdatrain_ds = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),
)
test_ds = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor(),
)
#查看数据集基本信息
print(train_ds)
2.1.2迭代和可视化数据集
labels_map = {0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1): #定义循环添加9张图片#随机生产一个整数,范围为[0,60000],其中60000是训练集图片的个数sample_idx = torch.randint(len(training_data), size=(1,)).item()#取出随机一张图片对应的矩阵与标签img, label = training_data[sample_idx] #img为(1,28,28图片)#向画布上添加子图figure.add_subplot(rows, cols, i)#加上图片名plt.title(labels_map[label])#关闭axisplt.axis("off")#img.squeeze()用于删除多余的轴,28x28的灰度图被Tensor处理后变为1x28x28,此时需去掉表示通道的维度plt.imshow(img.squeeze(), cmap="gray")
plt.show()

2.2创建自定义数据集Dataset
2.2.1官方文档
在Pytorch中可以创建自定义的数据集来加载数据,创建时需继承torch.utils.data下的Dataset类,并实现__init__、__len__和__getitem__方法。官方文档代码:
import os
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import DataLoader,Datasetclass CustomImageDataset(Dataset):# 传入标签目录、数据目录、transform、target_transformdef __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transform# 返回样本个数def __len__(self):return len(self.img_labels)# 返回指定索引处样本数据及标签def __getitem__(self, idx):#获取样本数据的路径img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])#读取数据文件image = read_image(img_path)#读取对应标签label = self.img_labels.iloc[idx, 1]#查看是否进行if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
在Pytorch中可以创建自定义的数据集来加载数据,创建时需继承Dataset类,并实现__init__、__len__和__getitem__方法。
__init__:在实例化Dataset对象时自动执行,一般用于初始化数据以及对应标签的目录、加载调用DataLoader时传入的transform和target_transform。__len__:返回数据集中样本的个数。__getitem__:加载给定索引处的样本(包括图片、标签),根据索引识别样本在磁盘上的位置,若含有transform和target_transform转换器,则进行转化并返回张量图片和相应的标签。
2.2.2自定义数据集
from torch.utils.data import Dataset, DataLoader class MyDataset(Dataset): def __init__(self, x_tensor, y_tensor): self.x = x_tensor self.y = y_tensor def __getitem__(self, index): return (self.x[index], self.y[index]) def __len__(self): return len(self.x) x = torch.arange(10)
y = torch.arange(10) + 1 my_dataset = MyDataset(x, y)
loader = DataLoader(my_dataset, batch_size=4, shuffle=True, num_workers=0) for x, y in loader: print("x:", x, "y:", y)

2.3数据集加载器DataLoader
2.3.1函数介绍
数据集加载器DataLoader是Pytorch提供的数据加载器,用于对数据进行批量加载和处理。它存在于torch.utils.data包下,需要的时候应该在该包下导入DataLoader。引入以下概念:
Epoch(轮):所有训练样本都已输入到模型中,称为一个epoch。Iteration(批次): 一批样本(batch_size)输入到模型中,称为一个Iteration。Batchsize: 一批样本的大小, 决定一个epoch有多少个Iteration。
DataLoader()的常用参数:
dataset:加载的数据集。batch_size:指定一批(Iteration)数据集的大小。模型并不会一个一个读入样本进行训练,而是以Batchsize为单位输入数据,当最后一批数据不足Batchsize个数时,通过drop_last=True可将其丢弃。shuffle:布尔类型,每轮训练时是否将数据洗牌,默认为False。若不洗牌,则每轮训练时同一批次传入的Batchsize大小的样本数据是相同的。将输入数据洗牌可使样本更有独立性(不同批次数据更独立)。但对于有序的数据不应设为True。num_workers:加载数据时的并发线程/进程数。根据计算机硬件的配置和数据加载的速度来设置,并发加载数据以加快训练速度。但是,过多的并行加载也可能会导致性能下降,因此需要进行适当的调整。drop_last:当数据样本数量不能被批次大小整除时,是否丢弃最后一个不完整的批次。
此处使用torchvision.datasets提供的CIFAR10的测试数据集查看各个参数的功能:
import torchvision.datasets
# 导入dataloader的包
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 获取测试数据集
test_dataset = torchvision.datasets.CIFAR10(root="CIRFA10", train=False, transform=torchvision.transforms.ToTensor(),download=True)
# 创建一个dataloader,批大小为4,每一个epoch重新洗牌,不舍弃不能被整除的批次
test_dataloader = DataLoader(dataset=test_dataset, batch_size=4, shuffle=True, drop_last=False)
2.3.2读取数据
在获取数据集时已使用transform=torchvision.transforms.ToTensor()参数进行归一化处理,故获取到的样本数据是Tensor类型。在获取数据时,可同时读取数据以及对应的标签:
img, label = test_dataloader.dataset[0]
print(type(img))
print(img.shape, label)
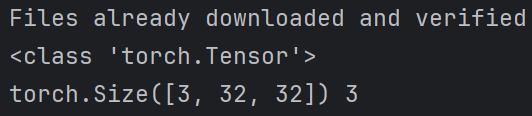
可看到图片已被转化为Tensor对象,共三个通道,大小为32x32。事实上,在经过DataLoader加载后,所有数据及其标签会被打包并封装在了dataset属性,并且同一批次的数据及其标签都会打包成新的对象,即:
- 同一批次的所有图片对象进行打包,形成一个对象,我们叫它imgs。
- 同一批次的所有的标签进行打包,形成一个对象,我们叫它targets

可通过for循环来取出imgs、targets对象,其个数等于数据集中对象个数/batch_size,本例中为10000/4=2500个对象。遍历代码:
# loader中对象
for data in test_dataloader.dataset:imgs, targets = dataprint(imgs.shape)print(targets)# dataloader中对象个数(与batch_size相关)
print(len(test_dataloader))
# 打印数据集中图片数量
print(len(test_dataset))

2.3.2可视化drop_last作用
修改batch_size=64,设置drop_last=True,此时最后一个批次所获取的数据只有16个,模型加载器会自动舍去而无法获取。使用torch.utils.tensorboard下的SummaryWriter查看这一过程:
import torchvision.datasets
# 导入dataloader的包
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 获取测试数据集
test_dataset = torchvision.datasets.CIFAR10(root="CIRFA10", train=False, transform=torchvision.transforms.ToTensor(),download=True)
# 创建一个dataloader,批大小为4,每一个epoch重新洗牌,不舍弃不能被整除的批次
test_dataloader = DataLoader(dataset=test_dataset, batch_size=4, shuffle=True, drop_last=True)writer = SummaryWriter("log")
#loader中对象
step = 0 #表示训练批次
for data in test_dataloader:imgs,targets = datawriter.add_images("loader",imgs,step)step+=1
writer.close()

此时不再含有最后的16张图片。
2.3.3可视化shuffle作用
每一轮epoch之后就是分配完了一次数据,而shuffle决定了是否在新一轮epoch开始时打乱所有图片的属性进行分配。
import torchvision.datasets
# 导入dataloader的包
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 获取测试数据集
test_dataset = torchvision.datasets.CIFAR10(root="./CIRFA10", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 创建一个dataloader,批大小为4,每一个epoch重新洗牌,不舍弃不能被整除的批次
test_dataloader = DataLoader(dataset=test_dataset, batch_size=4, shuffle=True, drop_last=True)writer = SummaryWriter("log")for epoch in range(2):step = 0for data in test_dataloader:imgs, targets = datawriter.add_images("Epoch:{}".format(epoch), imgs, step)step += 1writer.close()

可见数据已被打乱。
三、Transforms
Transform是torchvision下的一个模块,其中定义很很多用于图像预处理的类,如归一化(Normalize类),尺寸变化(Resize类),转换为tensor格式(ToTensor类),通过实例化该工具类,可以方便地对图像进行各种变换操作。事实上,所有 TorchVision 数据集都有两个参数:用于处理图像数据的转换transform和用于处理标签数据的target_transform。在Transforms 模块中提供了几种常用的转换方式可供直接调用。
3.1transforms.ToTensor()
将PIL图像或Ndarray图像转化为Tensor,并对图像像素进行归一化处理,即放缩到[0,1]。并且,若原始的图像形状为(HxWxC),则通过transforms.ToTensor()处理后图像形状变为(CxHxW),即将通道数提前。
import cv2
import numpy as np
import torch
from torchvision import transforms
# 定义数组Ndarray型图像,要求是unit8类型(此时像素范围为[0,255])
data = np.array([[[1,1,1],[1,1,1],[1,1,1],[1,1,1],[1,1,1]],[[2,2,2],[2,2,2],[2,2,2],[2,2,2],[2,2,2]],[[3,3,3],[3,3,3],[3,3,3],[3,3,3],[3,3,3]],[[4,4,4],[4,4,4],[4,4,4],[4,4,4],[4,4,4]],[[5,5,5],[5,5,5],[5,5,5],[5,5,5],[5,5,5]]],dtype='uint8')# 定义数组
print('data.shape=',data.shape)
#实例化ToTensor对象
toTensor=transforms.ToTensor()
data = toTensor(data)
print(data)
print(data.shape)

3.2transforms.Normalize()
用于将Tensor格式的图像进行归一化处理,且不支持PIL格式、Ndarray格式的Image。如果不对图像进行归一化,可能会导致深度学习模型的训练过程出现问题。事实上,深度学习模型的权重是随机初始化的,而图像像素值的范围通常是 [0, 255],输入的图像数据的值域过大,就会超出了模型的初始权重所能处理的范围。为了避免这种情况,我们需要对图像进行归一化操作,将图像像素值缩放到一个较小的范围内,例如 [0, 1] 或者 [-1, 1]。这样可以避免在训练过程中出现梯度爆炸或者梯度消失的问题。
初始化函数:
def __init__(self,mean,std,inplace=False):super().__init__()_log_api_usage_once(self)self.mean=meanself.std=stdself.inplace=inplace
故在创建Normalize对象时应当指定平均数、标准差。
import cv2
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformswriter = SummaryWriter("logs")img = cv2.imread("Wulanyin.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # cv2读入图像为BGR,转换成RGB# transforms使用
trans_tensor = transforms.ToTensor() # ToTensor类,实例化一个ToTensor工具
tensor_img = trans_tensor(img)#分别将三个通道归一化
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 归一化
norm_img = trans_norm(tensor_img)writer.add_image("ants_img", norm_img, 2)writer.close()
transforms.Normalize()常常与transforms.ToTensor()配合使用,后者将数据归一化到了[0,1]之间,使用transforms.Normalize()时图像最小值0就变为(0-0.5)/0.5=-1,图像像素最大值变为(1-0.5)/0.5=1,此时像素统一到[0,1]。事实上,数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。
3.3
二、自动求导
梯度是函数在某一点、某一方向上的变化率,在模型训练过程中,梯度可告诉我们如何调整模型的参数以使损失函数最小化。Pytorch框架提供了一种自动求导机制,允许我们定义模型时无需手动推导梯度计算公式,由对应函数自动执行。Pytorch框架提供了两种求解梯度的方式:
Tensor.backward():求解梯度,并将结果保存在Tensor对象的grad属性中。torch.autograd.grad()
在计算梯度之前需要设置张量属性requires_grad=True表示当前张量需要计算梯度并追踪上的所有操作。
2.1backward()、torch.autograd.grad()案例
2.1.1backward()
求 f ( x ) = x 2 + 2 x + 3 f(x)=x^2+2x+3 f(x)=x2+2x+3在 x = − 2 x=-2 x=−2处的导数:
import numpy as np
import torch# 标量Tensor求导
# 求 f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor(-2.0, requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a * torch.pow(x, 2) + b * x + c # f(x)=x2+2x+3 ,f'(x)=2x+2
y.backward() # backward求得的梯度会存储在自变量x的grad属性中
print('x=-2处的导数为:', x.grad)
2.1.2torch.autograd.grad()
使用torch.autograd.grad()获取指定点处导数时可设置create_graph是否允许创建更高阶的导数,当不设置时求更高阶导数会报错:
import torch# 求 f(x) = a*x**4 + b*x + c 的导数
x = torch.tensor(1.0, requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a * torch.pow(x, 4) + b * x + c
# create_graph设置为True,允许创建更高阶级的导数
# # 求一阶导
dy_dx = torch.autograd.grad(y, x, create_graph=True)[0]
# # 求二阶导
dy2_dx2 = torch.autograd.grad(dy_dx, x)[0] # 无法求三阶导数
print(dy_dx.data, dy2_dx2.data)

2.2Pytorch动态图机制
事实上,Pytorch提供了动态图机制,在计算过程中自动生成动态图以保存各个计算节点的梯度信息,方便进行反向传播。图中只有数据(Tensor)和运算(Operation)两种元素:
- 运算(Operation):包括加减乘除、开方、幂指对、三角函数等可求导运算。
- 数据(Tensor):数据分为叶子节点与非叶子节点。
- 叶子节点:反向传播结束后,叶子节点的梯度值会被保存。
- 非叶子节点:反向传播结束后,非叶子节点的梯度会被释放,可通过retain_grad()方法保存梯度。
张量Tensor对象的相关属性:
- requires_grad:设置是否可求导。
- grad_fn:运算名称。
- is_leaf:是否为叶子节点。
- grad:导数值。