中文情感分析
中文情感分析的实质是文本分类问题,本项目分别采用CNN和BI-LSTM两种模型解决文本分类任务,并用于情感分析,达到不错的效果。
两种模型在小数据集上训练,在验证集的准确率、号回率及F1因子均接近90%
项目设计的目标可以接受不同语料的多种分类任务,只要语料按照特定格式准备好,就可以开始调参训练、导出、serving。
code environment
在 python3.6 & Tensorflow1.13 下工作正常
其他环境也许也可以,但是没有测试过。
还需要安装 scikit-learn package 来计算指标,包括准确率回召率和F1因子等等。
语料的准备
语料的选择为 谭松波老师的评论语料,正负例各2000。属于较小的数据集,本项目包含了原始语料,位于data/hotel_comment/raw_data/corpus.zip中
解压 corpus.zip 后运行,并在raw_data运行
python fix_corpus.py
将原本gb2312编码文件转换成utf-8编码的文件。
词向量的准备
本实验使用开源词向量chinese-word-vectors
选择知乎语料训练而成的Word Vector, 本项目选择词向量的下载地址为 https://pan.baidu.com/s/1OQ6fQLCgqT43WTwh5fh_lg ,需要百度云下载,解压,直接放在工程目录下
训练数据的格式
参考 data/hotel_comment/*.txt 文件
- step1
本项目把数据分成训练集和测试集,比例为4:1, 集4000个样本被分开,3200个样本的训练集,800的验证集。
对于训练集和验证集,制作训练数据时遵循如下格式:
在{}.words.txt文件中,每一行为一个样本的输入,其中每段评论一行,并用jieba分词,词与词之间用空格分开。
除了 地段 可以 , 其他 是 一塌糊涂 , 惨不忍睹 。 和 招待所 差不多 。
帮 同事 订 的 酒店 , 他 老兄 刚 从 东莞 回来 , 详细 地问 了 一下 他 对 粤海 酒店 的 印象 , 说 是 硬件 和 软件 : 极好 ! 所以 表扬 一下
在{}.labels.txt文件中,每一行为一个样本的标记
NEG
POS
本项目中,可在data/hotel_comment目录下运行build_data.py得到相应的格式
- step2
因为本项目用了index_table_from_file来获取字符对应的id,需要两个文件表示词汇集和标志集,对应于vocab.labels.txt和vocab.words.txt,其中每一行代表一个词或者是一行代表一个标志。
本项目中,可在data/hotel_comment目录下运行build_vocab.py得到相应的文件
- step3
由于下载的词向量非常巨大,需要提取训练语料中出现的字符对应的向量,对应本项目中的data/hotel_comment/w2v.npz文件
本项目中,可在data/hotel_comment目录下运行build_embeddings.py得到相应的文件
模型一:CNN
结构:
- 中文词Embedding
- 多个不同长度的定宽卷积核
- 最大池化层,每个滤波器输出仅取一个最大值
- 全连接
图来源于论文 https://arxiv.org/abs/1408.5882 ,但与论文不同的是,论文中采取了一个pre-train 的embeddings和一个没有训练的embeddings组成了类似图像概念的双通道。本项目中只采用了一个预训练embeddings的单通道。
CNN模型的训练,在cnn目录底下运行
python main.py
CNN模型训练时间
在GTX 1060 6G的加持下大概耗时2分钟
CNN模型的训练结果
在model目录底下运行
python score_report.py cnn/results/score/eval.preds.txt
输出:
precision recall f1-score supportPOS 0.91 0.87 0.89 400NEG 0.88 0.91 0.89 400micro avg 0.89 0.89 0.89 800macro avg 0.89 0.89 0.89 800
weighted avg 0.89 0.89 0.89 800模型二: BI-LSTM
- 中文词Embedding
- bi-lstm
- 全连接
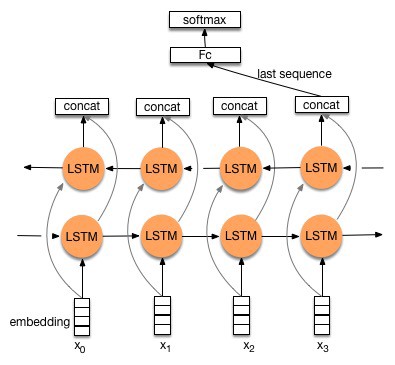
BI-LSTM模型的训练,在lstm目录底下运行
python main.py
BI-LSTM模型训练时间
在GTX 1060 6G的加持下大概耗时5分钟
BI-LSTM模型的训练结果
在model目录底下运行
python score_report.py lstm/results/score/eval.preds.txt
输出:
precision recall f1-score supportPOS 0.90 0.87 0.88 400NEG 0.87 0.91 0.89 400micro avg 0.89 0.89 0.89 800macro avg 0.89 0.89 0.89 800
weighted avg 0.89 0.89 0.89 800模型的导出和serving(BI-LSTM为例)
模型导出
在lstm目录底下运行
python export.py
导出estimator推断图,可以用作prediction。本项目已上传了saved_model,可以不通过训练直接测试。
在model/lstm目录底下运行 python serve.py可以利用导出的模型进行实体识别。详情见代码。
测试结果
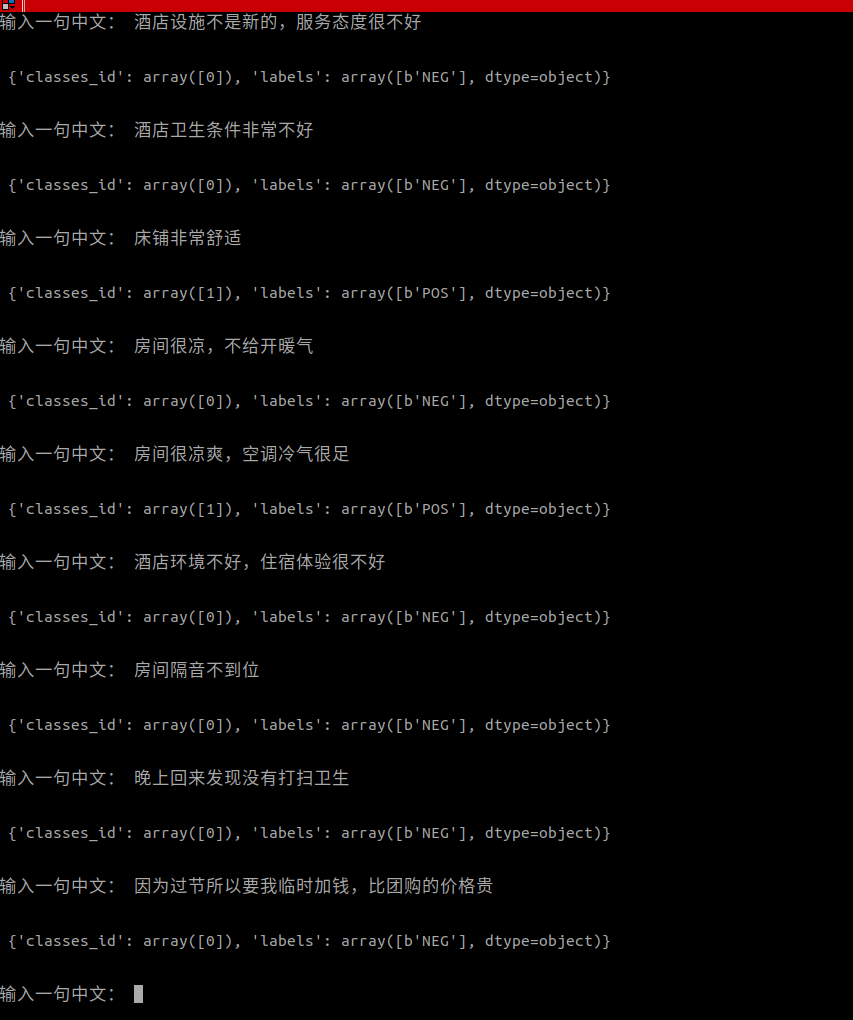
虽然模型由真实评论数据训练而成,这些数据长短不一(有的分词后长度超过1000),但由上图可得,模型对短评论表现尚可。
参考
[1] http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/
[2] https://arxiv.org/abs/1408.5882
如需要源码,请私信联系