简介
DuckDB 是面向列的本地 OLAP 数据库,SQLite是面向行的本地 OLTP 数据库。duckdb是 数据分析师得力助手,可以很好的直接读取本地的各种结构化数据文件,速度显著快于主流的pandas等工具。
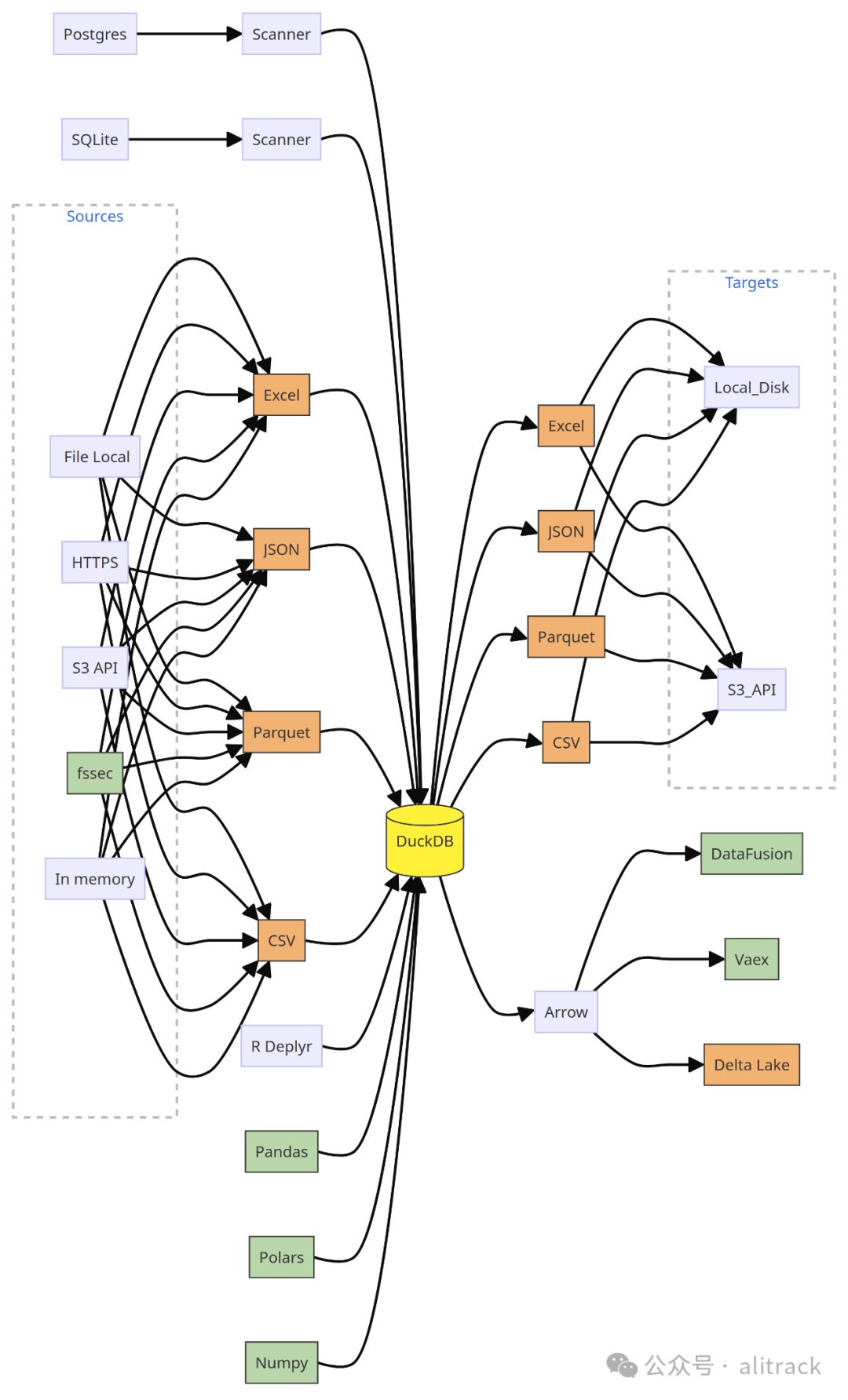
duckdb通过加载插件可以成为各种RDBMS数据库的中间通道,使任何不同种类的数据库进行跨库SQL查询成为可能。
python安装duckdb
pip install duckdb
本文所使用的duckdb为1.1.0版本。
基本使用
最直接的方式是使用duckdb.sql命令:
import duckdbduckdb.sql("SELECT 42 num").show()
查询结果可以先保存为变量,后续查询可以直接引用该变量名作为表名:
r1 = duckdb.sql("SELECT 22 num")
duckdb.sql("SELECT num*2 k FROM r1").show()
同时,DuckDB也可以直接查询Pandas DataFrames、Polars DataFrames和PyArrow表。例如:
import pandas as pd
pandas_df = pd.DataFrame({"a": [42]})
duckdb.sql("SELECT * FROM pandas_df")import polars as pl
polars_df = pl.DataFrame({"a": [42]})
duckdb.sql("SELECT * FROM polars_df")import pyarrow as pa
arrow_table = pa.Table.from_pydict({"a": [42]})
duckdb.sql("SELECT * FROM arrow_table")
注意:这些表只读,无法使用
INSERT或UPDATE语句进行操作。
支持读取本地常见的结构化数据文件(csv/json和parquet等):
duckdb.read_csv("data/csv/aws_locations.csv")
duckdb.read_parquet("example.parquet")
duckdb.read_json("example.json")
也可以使用sql语句直接读取:
duckdb.sql("select * from 'data/csv/aws_locations.csv'")
duckdb的查询结果可以转换为各种格式:
duckdb.sql("SELECT 42").fetchall() # Python原生数组对象
duckdb.sql("SELECT 42").df() # Pandas对象
duckdb.sql("SELECT 42").pl() # Polars对象
duckdb.sql("SELECT 42").arrow() # PyArrow表
duckdb.sql("SELECT 42").fetchnumpy() # NumPy数组
查询结果保存起来:
duckdb.sql("SELECT 42").write_parquet("out.parquet")
duckdb.sql("SELECT 42").write_csv("out.csv")
也可以使用COPY语法保存:
duckdb.sql("COPY (SELECT 42) TO 'out.parquet'")
将duckdb表持久化存储,还可以使用SQL语句的操作方式,只是这时需要创建连接:
with duckdb.connect("file.db") as con:con.sql("CREATE TABLE test (i INTEGER)")con.sql("INSERT INTO test VALUES (42)")con.table("test").show()
这样数据将持久化存储到file.db文件中。
前面的代码直接使用duckdb模块操作时,使用了全局内存数据库,duckdb.connect()传入特殊值:default:可获取此默认连接,不指定参数时则传递了:memory:,则创建一个使用内存数据库的连接。
传入:memory:conn3时,创建一个名称为conn3的内存连接,如果这个名称的连接已经创建将复用。使用不带名称的:memory:将始终创建一个新的单独的数据库实例。
如果传入的数据库是文件路径,则建立到持久数据库的连接。如果文件不存在,将创建该文件。多个Python进程希望同时访问同一个数据库文件时,可以使用只读模式:
con = duckdb.connect(database = "my-db.duckdb", read_only = False)
con = duckdb.connect(database = "my-db.duckdb", read_only = True)
加载扩展示例:
con = duckdb.connect()
con.install_extension("spatial")
con.load_extension("spatial")
扩展也可以加载到全局共享内存数据库:
import duckdb
duckdb.install_extension("spatial")
duckdb.load_extension("spatial")
要加载未签名的扩展,必须指定参数创建连接:
duckdb.connect(config = {"allow_unsigned_extensions": "true"})
加载远程数据库文件:
示例:
ATTACH 'https://blobs.duckdb.org/databases/stations.duckdb' AS stations_db;
SELECT count(*) AS num_stations
FROM stations_db.stations;
python调用duckdb的完整用法
API列表:http://duckdb.org/docs/api/python/reference/
数据读取与导入
duckdb读取文件常见的几种方式
duckdb读取csv,json,parquet,分别是使用read_csv,read_json,read_parquet函数,下面是示例。
读取单个文件:
duckdb.read_parquet("data/parquet-testing/leftdate3_192_loop_1.parquet")
通配符读取多个文件:
duckdb.read_csv("data/csv/glob/a*/*.csv")
通配符规则:
*匹配任意数量的任意字符,**匹配任意数量的子目录,?匹配任何单个字符,[abc]匹配括号中给定的一个字符,[a-z]匹配括号中给定范围内的一个字符。
从网络读取文件:
duckdb.read_parquet("https://some.url/some_file.parquet")
指定文件列表,读取多个文件:
duckdb.read_csv(["data/csv/glob/a1/a1.csv","data/csv/glob/a2/a2.csv", "data/csv/glob/a3/b1.csv"])
读取的多个文件列名不一致时,可以使用下面这两个参数:
duckdb.sql("SELECT * FROM read_csv('flights*.csv', union_by_name = true, filename = true)")
union_by_name表示按列名统一,filename用于添加一列标注数据来源哪个文件。后面会有完整参数介绍。
下面演示一下union_by_name的效果。
首先下载测试数据:
import duckdbflights3 = duckdb.read_csv('https://duckdb.org/data/flights3.csv')
flights4 = duckdb.read_csv('https://duckdb.org/data/flights4.csv')
flights3.to_csv("flights3.csv")
flights4.to_csv("flights4.csv")
flights3.show()
flights4.show()
数据结果如下:
┌────────────┬────────────────┬─────────────────┐
│ FlightDate │ OriginCityName │ DestCityName │
│ date │ varchar │ varchar │
├────────────┼────────────────┼─────────────────┤
│ 1988-01-01 │ New York, NY │ Los Angeles, CA │
│ 1988-01-02 │ New York, NY │ Los Angeles, CA │
└────────────┴────────────────┴─────────────────┘┌────────────┬───────────────┬────────────────┬─────────────────┐
│ FlightDate │ UniqueCarrier │ OriginCityName │ DestCityName │
│ date │ varchar │ varchar │ varchar │
├────────────┼───────────────┼────────────────┼─────────────────┤
│ 1988-01-03 │ AA │ New York, NY │ Los Angeles, CA │
└────────────┴───────────────┴────────────────┴─────────────────┘
duckdb.sql("SELECT * FROM read_csv('flights*.csv', union_by_name = true, filename = true)")
结果:
┌────────────┬────────────────┬─────────────────┬───────────────┬──────────────┐
│ FlightDate │ OriginCityName │ DestCityName │ UniqueCarrier │ filename │
│ date │ varchar │ varchar │ varchar │ varchar │
├────────────┼────────────────┼─────────────────┼───────────────┼──────────────┤
│ 1988-01-01 │ New York, NY │ Los Angeles, CA │ NULL │ flights3.csv │
│ 1988-01-02 │ New York, NY │ Los Angeles, CA │ NULL │ flights3.csv │
│ 1988-01-03 │ New York, NY │ Los Angeles, CA │ AA │ flights4.csv │
└────────────┴────────────────┴─────────────────┴───────────────┴──────────────┘
如果使用duckdb.read_csv直接传入该参数会报错:
duckdb.read_csv(['flights3.csv','flights4.csv'
], union_by_name=True)
报错信息:BinderException: Binder Error: COLUMN_TYPES error: Columns with names: "FlightDate","OriginCityName","DestCityName" do not exist in the CSV File
还可以直接从SQL中读取JSON文件:
duckdb.sql("SELECT * FROM 'example.json'")
直接在SQL语句中调用读取函数:
duckdb.sql("SELECT * FROM read_json('data/ducks.json')")
注意:调用读取函数可以指定特殊的参数,而直接指定文件,则使用默认的自动检测。
在基本使用中,我们演示了Pandas 、Polars 和PyArrow对象的变量名都可以作为duckdb的表名被读取。同时我们还可以自己主动注册这些对象为duckdb的表名:
import duckdb
import pandas as pdt = {}
t["test_df"] = pd.DataFrame({"i": [1, 2, 3, 4], "j": ["one", "two", "three", "four"]})
duckdb.register("test_df_view", t["test_df"])
duckdb.sql("SELECT * FROM test_df_view").show()
也可以通过这个对象创建持久化存储的表:
import duckdb
import pandas as pdtest_df = pd.DataFrame({"i": [1, 2, 3, 4], "j": ["one", "two", "three", "four"]})
with duckdb.connect("test.db") as con:con.execute("CREATE TABLE test_df_table AS SELECT * FROM test_df")con.execute("INSERT INTO test_df_table SELECT * FROM test_df")con.sql("select * from test_df_table").show()
注意:前面duckdb.register将表注册到了全局共享的内存数据库中,无法再新创建的连接中使用,要在新连接中使用,可以调用新连接对象
con的register函数。
如果是duckdb查询结果本身用变量保存,后续也可以作为表名被引用,例如:
rel = duckdb.sql("SELECT * FROM range(1_000_000) tbl(id)")
duckdb.sql("SELECT sum(id) FROM rel").show()
csv读取的参数
通过SQL语句指定参数的示例:
SELECT *
FROM read_csv('flights.csv',delim = '|',header = true,columns = {'FlightDate': 'DATE','UniqueCarrier': 'VARCHAR','OriginCityName': 'VARCHAR','DestCityName': 'VARCHAR'});
python的read_csv函数有很多参数,例如:
duckdb.read_csv("example.csv", header = False, sep = ",", dtype = ["int", "varchar"])
默认不指定参数时,使用自动检测,若显式设置 delim/sep, quote, escape, 或 header,则取消了参数的自动检测。
完整参数含义如下:
| 名称 | 描述 | 类型 | 默认 |
|---|---|---|---|
all_varchar | 跳过类型检测并假定所有列的类型都是VARCHAR。 | BOOL | false |
allow_quoted_nulls | 允许将带引号的值转换为NULL值 | BOOL | true |
auto_detect | 启用CSV参数的自动检测。 | BOOL | true |
auto_type_candidates | 自动检测的类型范围。例如['BIGINT', 'DATE']表示最终结果包含’BIGINT’, ‘DATE’, 'VARCHAR’三种类型。VARCHAR类型无论是否写入都会作为一个回退选项。 | TYPE[] | [‘SQLNULL’, ‘BOOLEAN’, ‘BIGINT’, ‘DOUBLE’, ‘TIME’, ‘DATE’, ‘TIMESTAMP’, ‘VARCHAR’] |
columns | 指定CSV文件各列的类型(例如,{'col1':'INTEGER','col2':'VARCHAR'})。使用此选项则不使用自动检测。 | STRUCT | |
compression | 文件的压缩类型。默认情况下,使用自动检测(例如,t.csv.gz将使用gzip,t.csv将使用none)。选项包括none、gzip、zstd。 | VARCHAR | auto |
dateformat | 解析日期时使用的日期格式。 | VARCHAR | |
decimal_separator | 数字的小数分隔符。 | VARCHAR | . |
delim 或 sep | 指定列的分隔符。sep是delim 的别名。 | VARCHAR | , |
escape | 指定应出现在与引号值匹配的的字符串,写在被匹配的引号之前。 | VARCHAR | " |
filename | 结果中是否包含额外的文件名列。 | BOOL | false |
force_not_null | 指定的列空值时,使用空字符串而不是null表示。 | VARCHAR[] | [] |
header | 是否包含标题行,其中包含每列的名称。 | BOOL | false |
ignore_errors | 是否忽略有错误的行。 | BOOL | false |
max_line_size | 以字节为单位的最大行大小。 | BIGINT | 2097152 |
names | 指定列的名称列表 | VARCHAR[] | |
new_line | 选项支持“\r”、“\n”或“\r\n”,但CSV解析器不区分“\r”和“\n”,仅区分单字符行分隔符和双字符行分隔符。 | VARCHAR | |
normalize_names | 指定列名是否应规范化,并从中删除任何非字母数字字符。 | BOOL | false |
null_padding | 如果启用,当行缺少列时,使用空值填充右侧的其余列。 | BOOL | false |
nullstr | 指定表示空值的字符串或列表。 | VARCHAR or VARCHAR[] | |
parallel | 是否使用并行CSV读取器。 | BOOL | true |
quote | 指定对数据值加引号时要使用的引号字符串。 | VARCHAR | " |
sample_size | 自动检测所使用的样本行数。 | BIGINT | 20480 |
skip | 跳过开头的行数。 | BIGINT | 0 |
timestampformat | 指定解析时间戳时使用的日期格式。 | VARCHAR | |
types 或 dtypes | 列的类型可以是列表(按位置)或结构(按名称)。 | VARCHAR[] or STRUCT | |
union_by_name | 同时读取多个csv文件时,按列名进行统一合并,对于没有特定列的文件填充NULL值。使用此选项会增加内存消耗。 | BOOL | false |
除此之外还有一个hive_partitioning的选项,默认值为false,启动时将使用分区表。
使用示例:
SELECT *
FROM read_csv('orders/*/*/*.csv', hive_partitioning = true);
将现有的表写出为分区表:
COPY orders
TO 'orders' (FORMAT CSV, PARTITION_BY (year, month));
支持对SQL查询结果写出:
COPY (SELECT *, year(timestamp) AS year, month(timestamp) AS month FROM services)
TO 'test' (PARTITION_BY (year, month));
详见:https://duckdb.org/docs/data/partitioning/hive_partitioning.html
读取存在错误的csv文件时,除了可以使用上面的 ignore_errors配置外,还可以使用store_rejects=true,下面是相关配置列表:
| 名称 | 描述 | 类型 | 默认 |
|---|---|---|---|
store_rejects | 跳过文件中的任何错误,并将其存储在默认拒绝临时表中。 | BOOLEAN | False |
rejects_scan | 存储有故障CSV文件的扫描信息的临时表的名称。 | VARCHAR | reject_scans |
rejects_table | 存储CSV文件的故障行信息的临时表的名称。 | VARCHAR | reject_errors |
rejects_limit | 错误记录数量上限,0表示无限制。 | BIGINT | 0 |
导入csv文件到表
以下示例使用flights.csv文件为例。
将CSV文件读入表中:
import duckdbduckdb.sql("""CREATE TABLE ontime (FlightDate DATE,UniqueCarrier VARCHAR,OriginCityName VARCHAR,DestCityName VARCHAR
);
COPY ontime FROM 'https://duckdb.org/data/flights.csv';""")
也可以直接根据查询结果创建表:
import duckdbduckdb.sql("""CREATE TABLE ontime ASSELECT * FROM 'https://duckdb.org/data/flights.csv';""")
其中的SELECT * 可以省略:
CREATE TABLE ontime AS FROM 'https://duckdb.org/data/flights.csv';
注意:创建表的语法
AS不能省略。
COPY 还有TO这种语法:
duckdb.sql("COPY ontime TO 'flights.csv' WITH (HEADER, DELIMITER '|');")
其中WITH表示指定写出的参数,分别是header=true和delimiter=‘|’。
也可以将SQL查询结果写入到文件中:
duckdb.sql("COPY (SELECT * FROM ontime) TO 'flights.csv';")
注意:COPY FROM语法指定参数不带WITH:
CREATE TABLE ontime (flightdate DATE, uniquecarrier VARCHAR, origincityname VARCHAR, destcityname VARCHAR);
COPY ontime FROM 'flights.csv' (DELIMITER '|', HEADER);
SELECT * FROM ontime;
读取json的一些参数
调用read_json函数读取json文件有很多参数:
duckdb.read_json("data/ducks.json", format='array')
一些较前面的csv中的参数比较特别的有:
| 名称 | 描述 | 类型 | 默认值 |
|---|---|---|---|
convert_strings_to_integers | 表示整数值的字符串是否转换为数值类型。 | BOOL | false |
format | 可以是 ['auto', 'unstructured', 'newline_delimited', 'array'] 之一。 | VARCHAR | 'auto' |
maximum_depth | 自动检测模式下,检测的最大嵌套深度。默认-1表示完全检测嵌套JSON类型 | BIGINT | -1 |
maximum_object_size | JSON对象的最大字节数 | UINTEGER | 16777216 |
records | 可以是 ['auto', 'true', 'false'] 之一 | VARCHAR | 'true' |
正常情况下并不需要指定format,因为默认会自动检测。下面指定参数是为了表达['unstructured', 'newline_delimited', 'array'] 这三种格式的区别。
示例文件records.json,内容如下:
{"key1":"value1", "key2": "value1"}
{"key1":"value2", "key2": "value2"}
{"key1":"value3", "key2": "value3"}
对于这种格式指定newline_delimited即可读取:
duckdb.read_json('https://duckdb.org/data/records.json',format='newline_delimited')
对于普通的json数组格式:
[{"key1":"value1", "key2": "value1"},{"key1":"value2", "key2": "value2"},{"key1":"value3", "key2": "value3"}
]
则指定array格式进行读取:
duckdb.read_json('https://duckdb.org/data/records-in-array.json',format='array')
对于非结构化的json,例如文件unstructured.json:
{"key1":"value1","key2":"value1"
}
{"key1":"value2","key2":"value2"
}
{"key1":"value3","key2":"value3"
}
可以使用unstructured读取:
duckdb.read_json('https://duckdb.org/data/unstructured.json',format='unstructured')
如果指定records = false,JSON读取器不会解压缩顶层对象,而是创建STRUCT:
duckdb.read_json('https://duckdb.org/data/records.json', records="false")
结果:
┌────────────────────────────────────┐
│ json │
│ struct(key1 varchar, key2 varchar) │
├────────────────────────────────────┤
│ {'key1': value1, 'key2': value1} │
│ {'key1': value2, 'key2': value2} │
│ {'key1': value3, 'key2': value3} │
└────────────────────────────────────┘
参数化执行SQL
占位符?将与传递的Python列表一一对应。占位符$可以根据编号或索引重用值。
占位符?用法示例:
import duckdbcon = duckdb.connect()
con.execute("CREATE TABLE items (item VARCHAR, value DECIMAL(10, 2), count INTEGER)")
con.execute("INSERT INTO items VALUES ('jeans', 20.0, 1), ('hammer', 42.2, 2)")
con.execute("INSERT INTO items VALUES (?, ?, ?)", ["laptop", 2000, 1])
con.executemany("INSERT INTO items VALUES (?, ?, ?)", [["chainsaw", 500, 10], ["iphone", 300, 2]])
con.execute("SELECT item FROM items WHERE value > ?", [400])
con.fetchall()
结果:
[('laptop',), ('chainsaw',)]
注意:duckdb作为一个分析型数据库,不适合使用executemany写入大量数据。使用sql语句
INSERT INTO或许是更好的方式,例如INSERT INTO dest_table SELECT * FROM test_df,而test_df可以是一个现成的pandas对象。
简单查询:
duckdb.execute("SELECT ?, ?, ?", ["duck", "duck", "goose"])
print(duckdb.fetchall())
结果:
[('duck', 'duck', 'goose')]
出现重复的参数,完全可以使用占位符$数字占位:
duckdb.execute("SELECT $1, $1, $2", ["duck", "goose"])
print(duckdb.fetchall())
能达到完全相同的效果。
命名参数使用示例:
import duckdbres = duckdb.execute("""SELECT$my_param,$other_param,$also_param""",{"my_param": 5,"other_param": "DuckDB","also_param": [42]}
).fetchall()
print(res)
结果:
[(5, 'DuckDB', [42])]
参数化执行一个最基本的好处就是,不需要自己转义,例如:
import pandas as pd
import duckdbdata = pd.DataFrame({"word": ["this's", "these's", "that's", "what's"], "num": range(1, 5)})
如果需要查询word="this's"的数据,不使用参数需要这样写:
duckdb.sql("select * from data where word='this''s'").df()
使用参数则省去的转义的麻烦:
duckdb.execute("select * from data where word=?", ["this's"]).df()
python的操作API
duckdb的python API提供了很多操作函数,下面简单介绍一下。
基本用法
aggregate用于聚合运算,duckdb将自动按非聚合的所有列进行分组:
import duckdbrel = duckdb.sql("SELECT * FROM range(1_000_000) tbl(id)")
rel.aggregate("id % 2 AS g, sum(id), min(id), max(id)")
结果:
┌───────┬──────────────┬─────────┬─────────┐
│ g │ sum(id) │ min(id) │ max(id) │
│ int64 │ int128 │ int64 │ int64 │
├───────┼──────────────┼─────────┼─────────┤
│ 1 │ 250000000000 │ 1 │ 999999 │
│ 0 │ 249999500000 │ 0 │ 999998 │
└───────┴──────────────┴─────────┴─────────┘
except_用于取差集,将第二个表从第一表中去除,这两张表的列必须相同:
r1 = duckdb.sql("SELECT * FROM range(1,8) tbl(id)")
r2 = duckdb.sql("SELECT * FROM range(4,10) tbl(id)")
r1.except_(r2).show()
结果:
┌───────┐
│ id │
│ int64 │
├───────┤
│ 3 │
│ 1 │
│ 2 │
└───────┘
intersect则用于取差集:
r1.intersect(r2).show()
filter用于过滤不满足条件的所有行:
rel = duckdb.sql("SELECT * FROM range(10) tbl(id)")
rel.filter("id > 5").show()
join(rel, condition, type = "inner")用于表连接:
r1 = duckdb.sql("SELECT * FROM range(5) tbl(id)").set_alias("r1")
r2 = duckdb.sql("SELECT * FROM range(10, 15) tbl(id)").set_alias("r2")
r1.join(r2, "r1.id + 10 = r2.id").show()
limit(n,offset=0)用于限制返回前N行,可以设置偏移量,例如rel.limit(3)。
order用于排序,例如rel.order("id DESC")。
project用于指定被查询的列:
rel = duckdb.sql("SELECT * FROM range(3) tbl(id)")
rel.project("id,id+10 id_plus_ten,id+25 id_plus_more").show()
┌───────┬─────────────┬──────────────┐
│ id │ id_plus_ten │ id_plus_more │
│ int64 │ int64 │ int64 │
├───────┼─────────────┼──────────────┤
│ 0 │ 10 │ 25 │
│ 1 │ 11 │ 26 │
│ 2 │ 12 │ 27 │
└───────┴─────────────┴──────────────┘
union用于合并两个表,例如r1.union(r2),相当于sql语句中union all。
select表达式
project能够实现的功能非常有限,完整列选择需要使用select,基本的表达式是ColumnExpression:
import duckdb
import pandas as pddf = pd.DataFrame({'a': [1, 2, 3, 4],'b': [True, None, False, True],'c': [42, 21, 13, 14]
})
rel = duckdb.from_df(df)
rel.select(duckdb.ColumnExpression('a')).show()
rel.select((duckdb.ColumnExpression('a') * 10).alias("a1"),duckdb.ColumnExpression('b').isnull().alias("b1"),(duckdb.ColumnExpression('c') + 5).alias("c1")
).show()
使用StarExpression,可以使用排除语法,例如不筛选b列,其他列都筛选:
star = duckdb.StarExpression(exclude = ['b'])
rel.select(star).show()
常量表达式ConstantExpression,示例:duckdb.ConstantExpression('hello')
Case表达式,语法示例:
from duckdb import (ConstantExpression,ColumnExpression,CaseExpression
)rel.select(ColumnExpression('b'),CaseExpression(condition=ColumnExpression('b') == False,value=ConstantExpression('world')).otherwise(ConstantExpression('hello')).alias("tag")
).show()
┌─────────┬─────────┐
│ b │ tag │
│ boolean │ varchar │
├─────────┼─────────┤
│ true │ hello │
│ NULL │ hello │
│ false │ world │
│ true │ hello │
└─────────┴─────────┘
case表达式对应SQL语句中的CASE WHEN (...) THEN (...) ELSE (...) END,默认else不指定时为NULL
函数表达式示例:
import duckdb
import pandas as pd
from duckdb import (ConstantExpression,ColumnExpression,FunctionExpression
)df = pd.DataFrame({'a': ['test', 'pest', 'text', 'rest']})
res = duckdb.df(df).select(FunctionExpression('ends_with', ColumnExpression('a'), ConstantExpression('est'))
).fetchall()
print(res)
个人觉得对于需要使用函数表达式的地方不如直接写SQL方便,上面的case表达式示例,使用SQL语句为:
duckdb.sql("select b,case when not b then 'world' else 'hello' end as tag from rel")
函数表达式示例:
duckdb.sql("select ends_with(a,'est') from df").fetchall()
Python创建DuckDB自定义函数UDF
来自官方的文档的一个基本示例:
import duckdb
from duckdb.typing import *
from faker import Fakerdef generate_random_name():fake = Faker()return fake.name()duckdb.create_function("random_name", generate_random_name, [], VARCHAR)
res = duckdb.sql("SELECT random_name()").fetchall()
print(res)
con.create_function(name, function, parameters, return_type)用于创建自定义函数,4个参数分别是注册的函数名,希望注册为UDF的Python函数,参数类型列表,返回值类型。前2个参数是必须填写的参数,后两个参数,在Python函数具有类型标注时一般也可以省略,它会隐式地将许多已知类型转换为DuckDB类型。
例如:
def my_function(x: int) -> str:return x
duckdb.create_function("my_func", my_function)
除了这4个基本参数以外还有一些可选参数:
type:默认为native使用Python内置类型,指定type='arrow'时使用PyArrow表类型。
null_handling:默认情况下,函数接收到空值时会直接返回空值,如果需要函数能够处理空值,需要将该参数设置为special。
exception_handling:将此参数设置为return_null,在Python函数出现异常时,程序不会停止,而是返回null。
side_effects:默认情况下,函数对相同的输入会缓存结果,导致相同的输入返回的结果都一样。对于上面的自定义函数,如果需要反复调用,应该设置side_effects=True。
对于上面创建的自定义函数,如果像下面这样反复调用:
duckdb.sql("SELECT id,random_name() FROM range(4) tbl(id)").show()
可以看到返回的结果都一样:
┌───────┬───────────────┐
│ id │ random_name() │
│ int64 │ varchar │
├───────┼───────────────┤
│ 0 │ Melissa Weeks │
│ 1 │ Melissa Weeks │
│ 2 │ Melissa Weeks │
│ 3 │ Melissa Weeks │
└───────┴───────────────┘
这时我们需要取消注册这个函数(调用remove_function方法),并重新创建:
duckdb.remove_function("random_name")
duckdb.create_function("random_name", generate_random_name,[], VARCHAR, side_effects=True)
duckdb.sql("SELECT id,random_name() FROM range(4) tbl(id)").show()
这次可以看到都是随机的姓名:
┌───────┬───────────────┐
│ id │ random_name() │
│ int64 │ varchar │
├───────┼───────────────┤
│ 0 │ Nathan Howard │
│ 1 │ Lisa Hunt │
│ 2 │ Angela Ramsey │
│ 3 │ Amanda Nelson │
└───────┴───────────────┘
案例:生成真实模拟数据
import duckdb
import faker
fake = faker.Faker("zh-cn")def generate_person():return {'name': fake.name(),'province': fake.province(),'city': fake.city(),'email': fake.email(),'job': fake.job(),'company': fake.company(),'birthdate': fake.date_of_birth(),'phone_number': fake.phone_number()}duckdb.create_function('generate_person', generate_person, [],duckdb.struct_type({'name': 'VARCHAR','province': 'VARCHAR','city': 'VARCHAR','email': 'VARCHAR','job': 'VARCHAR','company': 'VARCHAR','birthdate': 'DATE','phone_number': 'VARCHAR'}),side_effects=True
)
duckdb.sql("""CREATE OR REPLACE TABLE people AS
SELECT person.* FROM (SELECT generate_person() personFROM range(10)
)
""")
duckdb.sql("from people").show()

duckdb的SQL基本特殊语法
对于太常规的SQL语法不作介绍,下面介绍一下可能比较特殊的duckdb语法。
duckdb客户端的安装
为了测试方便,我们首先安装一个可以直接执行duckdb SQL语句的客户端,只需要命令行操作可以直接到官网安装:https://duckdb.org/docs/installation/index?version=stable&environment=cli&platform=win&download_method=direct&architecture=x86_64
这里可以选择适合自己电脑的客户端进行下载。
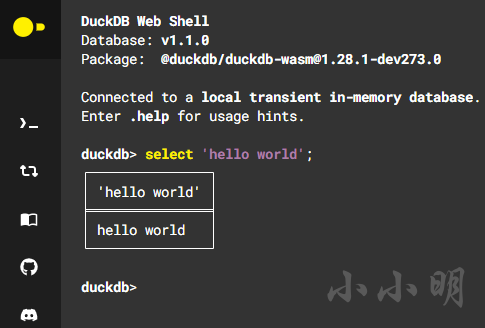
也可以直接使用官方提供的在线SQL执行器:https://shell.duckdb.org/
为了演示方便我建议使用图形化的客户端DBeaver,下载地址:https://dbeaver.io/download/
我选择了zip免安装版,解压后,双击dbeaver.exe打开。
打开后创建一个duckdb 的连接:
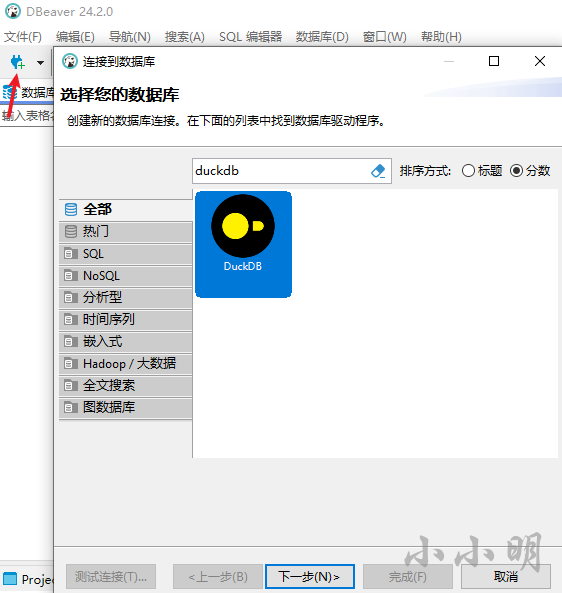
第一次使用需要下载JDBC驱动。数据库路径可以填入:memory:建立临时内存连接。
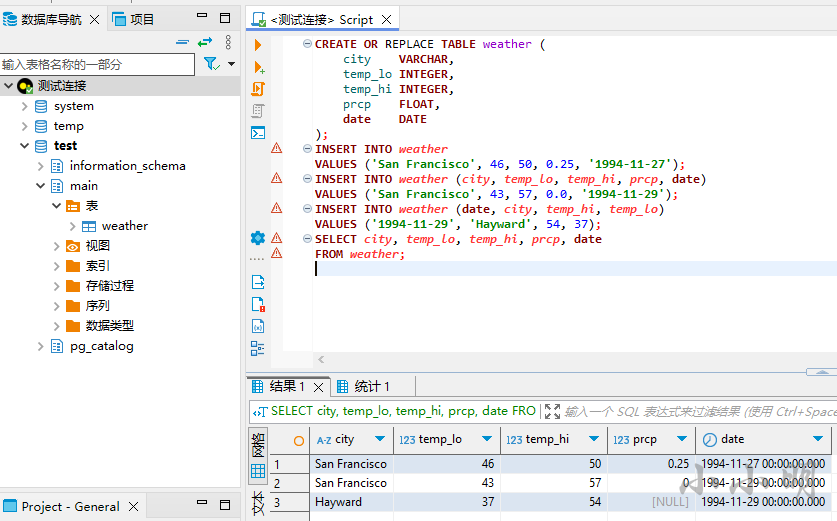
一切就绪就可以开始测试了:
SELECT查询语句的特别用法
从表tbl中选择第一列和第三列:
SELECT #1, #3 FROM tbl;
每行返回一个STRUCT对象:
SELECT d
FROM (SELECT 1 AS a, 2 AS b) d;
d |
----------+
{a=1, b=2}|
需要SELECT d.*解包为多列。
rowid伪列根据物理存储返回行标识符:
CREATE TABLE t (id INTEGER, content VARCHAR);
INSERT INTO t VALUES (42, 'hello'), (43, 'world');
SELECT rowid, id, content FROM t;
rowid|id|content|
-----+--+-------+0|42|hello |1|43|world |
选择除了city以外的列:
SELECT * EXCLUDE (city) FROM addresses;
EXCLUDE允许从*表达式中排除特定的列。
选择所有列,但city列替换为lower(city):
SELECT * REPLACE (lower(city) AS city) FROM addresses;
REPLACE允许用不同的表达式替换特定的列。
正则筛选需要的列:
SELECT COLUMNS('number\d+') FROM addresses;
COLUMNS表达式用于在多个列上执行相同的表达式。
支持LIKE语法筛选:
SELECT COLUMNS(c -> c LIKE '%num%')
FROM addresses;
在表的所有给定列上计算函数:
SELECT min(COLUMNS(*)), count(COLUMNS(*)) FROM numbers;
COLUMNS语句中的*表达式也可以包含EXCLUDE或REPLACE:
SELECTmin(COLUMNS(* REPLACE (number + id AS number))),count(COLUMNS(* EXCLUDE (number)))
FROM numbers;
COLUMNS表达式也可以在WHERE子句中使用,例如:WHERE COLUMNS(*) > 1;
COLUMNS支持类似Python的解包操作:
SELECT coalesce(*COLUMNS(*)) AS result
FROM (values (NULL, 42, true),
(NULL, 24, false),
(12, 4, true)) t(a,b,c);
对于上述sql,coalesce(*COLUMNS(*))相当于coalesce(a,b,c)
DISTINCT ON按指定列去重:
SELECT DISTINCT ON(country) city, population
FROM cities
ORDER BY population DESC;
子查询比较
ALL限定所有都满足,例如:
6 <= ALL (SELECT grade FROM grades)
要求grades表的所有grade字段都大于等于6.
ANY和SOME等价,任一一个满足则返回true:
5 >= ANY (SELECT grade FROM grades)
类型转换
常规语法使用CAST(expr AS TYPENAME),duckdb支持expr::TYPENAME:
SELECT i::VARCHAR AS i FROM generate_series(1, 3) tbl(i);
对于简单额情况可以使用TYPENAME expr语法进行转换:
SELECT DATE '2024-09-24';
SELECT Double '23';
不过这种形式的类型转换支持范围有限,后续无法接其他关键字,更适合在传入函数时使用这种语法。
有时候不确定能否转换成功时,可以使用TRY_CAST,转换失败时返回null,不置于转换失败时报错:
SELECT TRY_CAST('hello' AS INTEGER) AS i;
unnest解嵌套与聚合嵌套
解嵌套标量列表,生成3行((1, 10), (2, 11), (3, NULL)):
SELECT unnest([1, 2, 3]), unnest([10, 11]);
生成3行((1, 10), (2, 10), (3, 10)):
SELECT unnest([1, 2, 3]), 10;
可以将子查询结果解嵌套:
SELECT unnest(l) + 10 FROM (VALUES ([1, 2, 3]), ([4, 5])) tbl(l);
解嵌套结构体,将被展开到多列:
SELECT unnest({'a': 42, 'b': 84});
开启递归,处理多层嵌套:
SELECT unnest([[1, 2, 3], [4, 5]], recursive := true);
递归会先处理列表,再处理结构体:
SELECT unnest([{'a': 42, 'b': 84}, {'a': 100, 'b': NULL}], recursive := true);
a |b |
---+--+42|84|
100| |
对于下面的嵌套,无法解包结构体内部的列表:
SELECT unnest({'a': [1, 2, 3], 'b': 88}, recursive := true);
a |b |
-------+--+
[1,2,3]|88|
对于多层级的列表,可以通过max_depth设置最大解包深度,无需全部解包:
SELECT unnest([[[1, 2], [3, 4]], [[5, 6], [7, 8, 9], []], [[10, 11]]], max_depth := 2) AS x;
x |
-------+
[1,2] |
[3,4] |
[5,6] |
[7,8,9]|
[] |
[10,11]|
实现解嵌套的逆操作聚合嵌套可以使用list函数:
SELECT list(i order by i desc) arr
from (SELECT UNNEST(range(1,5))) tbl(i)
arr |
---------+
[4,3,2,1]|
COPY语句的用法
读取json导入lineitem表:
COPY lineitem FROM 'lineitem.json' (FORMAT JSON, AUTO_DETECT true);
()括号内的选项可以省略。
将names.csv的内容读入category表的name列,其他列将填充其默认值:
COPY category(name) FROM 'names.csv';
将lineitem表的数据写入到不带表头的TSV文件:
COPY lineitem TO 'lineitem.tsv' (DELIMITER '\t', HEADER false);
将查询结果写入Parquet文件:
COPY (SELECT l_orderkey, l_partkey FROM lineitem) TO 'lineitem.parquet' (COMPRESSION ZSTD);
将数据库db1的全部内容复制到数据库db2:
COPY FROM DATABASE db1 TO db2;
仅复制表结构,而不复制任何数据:
COPY FROM DATABASE db1 TO db2 (SCHEMA);
COPY ... TO的完整选项:https://duckdb.org/docs/sql/statements/copy.html#copy–to-options
COPY不支持表之间的复制,若要在表之间复制,可以使用:
INSERT INTO tbl2 FROM tbl1;
INSERT语句
向指定表的指定列插入值:
CREATE TABLE tbl (a INTEGER, b INTEGER);
INSERT INTO tbl (b, a)VALUES (5, 42),(6, DEFAULT),(7, 54);
也可以使用BY POSITION:
INSERT INTO tbl BY POSITION (b, a) VALUES (5, 42);
使用查询结果插入时,可以使用BY NAME语法:
CREATE or REPLACE TABLE tbl (a INTEGER, b INTEGER);
INSERT INTO main.tbl BY NAME (SELECT 42 AS b, 32 AS a);
INSERT INTO main.tbl BY NAME (SELECT 22 AS b);
SELECT * FROM main.tbl;
a |b |
--+--+
32|42||22|
冲突处理
冲突时不做任何事情:
INSERT OR IGNORE INTO tbl (i) VALUES (1);
冲突时使用新值更新表:
INSERT OR REPLACE INTO tbl (i) VALUES (1);
例如:
CREATE OR REPLACE TABLE tbl (i INTEGER PRIMARY KEY, j INTEGER);
INSERT INTO main.tbl VALUES (1, 42);
INSERT INTO main.tbl VALUES (1, 84);
第2条插入语句会导致主键冲突,可以改成INSERT OR REPLACE更新表,或者INSERT OR IGNORE忽略错误。
也可以使用ON CONFLICT子句,对于忽略下面两句SQL等价:
INSERT OR IGNORE INTO tbl VALUES (1, 84);
INSERT INTO main.tbl VALUES (1, 84) ON CONFLICT DO NOTHING;
对于冲突更新(upsert),下面两句SQL等价:
INSERT OR REPLACE INTO main.tbl VALUES (1, 84);
INSERT INTO tbl VALUES (1, 84)ON CONFLICT DO UPDATE SET j = EXCLUDED.j;
下面这些语句都是等价的:
INSERT OR REPLACE INTO tblVALUES (1, 84);
INSERT INTO tblVALUES (1, 84)ON CONFLICT DO UPDATE SET j = EXCLUDED.j;
INSERT INTO tbl (j, i)VALUES (84, 1)ON CONFLICT DO UPDATE SET j = EXCLUDED.j;
INSERT INTO tbl BY NAME(SELECT 84 AS j, 1 AS i)ON CONFLICT DO UPDATE SET j = EXCLUDED.j;
如果被插入的表本身存在重复的唯一列数据,使用冲突处理依然会报错,可以先对插入数据去重,例如:
SELECT DISTINCT ON(i) i, j FROM VALUES (1, 84), (1, 168) AS t (i, j)
这些就将数据表按i列去重。
定义冲突目标
一个表存在多个约束时:
CREATE OR REPLACE TABLE tbl (i INTEGER PRIMARY KEY, j INTEGER UNIQUE, k INTEGER);
INSERT INTO tblVALUES (1, 20, 300);
此时就需要指定按哪列判断冲突:
INSERT INTO tblVALUES (1, 20, 900)ON CONFLICT (j) DO UPDATE SET k = 5 * EXCLUDED.k;
SELECT * FROM tbl;
提供冲突目标时,可以使用WHERE子句进一步过滤此目标:
INSERT INTO tblVALUES (1, 40, 700)ON CONFLICT (i) DO UPDATE SET k = 2 * EXCLUDED.k WHERE k < 100;
返回被插入的数据
例如:
CREATE TABLE t2 (i INTEGER, j INTEGER);
INSERT INTO t2SELECT 2 AS i, 3 AS jRETURNING *, i * j AS i_times_j;
i|j|i_times_j|
-+-+---------+
2|3| 6|
示例2:
CREATE TABLE t3 (i INTEGER PRIMARY KEY, j INTEGER);
CREATE SEQUENCE 't3_key';
INSERT INTO t3SELECT nextval('t3_key') AS i, 42 AS jUNION ALLSELECT nextval('t3_key') AS i, 43 AS jRETURNING *;
由于SEQUENCE表生成的数据会不断变化,返回插入的数据,是比较方便的方式。
SEQUENCE表的基本示例:
CREATE SEQUENCE serial START 1;
SELECT nextval('serial') AS nextval;
SELECT currval('serial') AS currval;
完整参数示例:
CREATE SEQUENCE serial START WITH 10 INCREMENT BY 2 MAXVALUE 99 CYCLE;
参数说明:https://duckdb.org/docs/sql/statements/create_sequence.html#parameters
UPDATE语句
UPDATE基本的更新操作示例:
UPDATE tbl SET i = 0 WHERE i IS NULL;
UPDATE tbl SET i = 1, j = 2;
duckdb的update除了基本用法,还支持从其他表更新,下面演示其特殊用法。
首先准备测试数据:
CREATE OR REPLACE TABLE original AS
SELECT UNNEST([1,2,3]) as key, UNNEST(['original value','original value 2','original value 3']) as value;CREATE OR REPLACE TABLE new AS
FROM (values (1,'new value'),(2,'new value 2'),(4,'new value 4')) new(key, value);SELECT * FROM original;
SELECT * FROM new;
两张表的数据为:
key|value |
---+----------------+1|original value |2|original value 2|3|original value 3|key|value |
---+-----------+1|new value |2|new value 2|4|new value 4|
下面我们要使用new表的数据更新original表的数据:
UPDATE original
SET value = new.value
FROM new
WHERE original.key = new.key;
SELECT * FROM original;
key|value |
---+----------------+1|new value |2|new value 2 |3|original value 3|
可以看到对应键的值都被新表的值替换。
被替换的值可以额外处理:
UPDATE original
SET value = new.value || ' a change!'
FROM new
WHERE original.key = new.key;
SELECT * FROM original;
key|value |
---+--------------------------+1|new value a change! |2|new value 2 a change! |3|original value 3 a change!|
PIVOT透视
传统的SQL实现透视/逆透视都非常麻烦,但是duckdb本身支持透视/逆透视的语法,轻松实现动态行列转换。
首先创建测试数据:
CREATE or replace TABLE Cities (Country VARCHAR, Name VARCHAR, Year INTEGER, Population INTEGER
);
INSERT INTO Cities VALUES('NL', 'Amsterdam', 2000, 1005),('NL', 'Amsterdam', 2010, 1065),('NL', 'Amsterdam', 2020, 1158),('US', 'Seattle', 2000, 564),('US', 'Seattle', 2010, 608),('US', 'Seattle', 2020, 738),('US', 'New York City', 2000, 8015),('US', 'New York City', 2010, 8175),('US', 'New York City', 2020, 8772);
FROM Cities;
测试按国家分组合并透视:
PIVOT Cities
ON Year
USING sum(Population)
GROUP BY Country;
Country|2000|2010|2020|
-------+----+----+----+
NL |1005|1065|1158|
US |8579|8783|9510|
默认情况下,不指定GROUP BY,则按照ON或USING子句中未指定的所有列:
PIVOT Cities ON Year USING first(Population);
Country|Name |2000|2010|2020|
-------+-------------+----+----+----+
NL |Amsterdam |1005|1065|1158|
US |Seattle | 564| 608| 738|
US |New York City|8015|8175|8772|
ON子句可以使用IN表达式指定仅创建指定的列:
PIVOT Cities
ON Year IN (2000, 2010)
USING sum(Population)
GROUP BY Country;
Country|2000|2010|
-------+----+----+
US |8579|8783|
NL |1005|1065|
ON子句指定多个列,可以通过||自定义连接符:
PIVOT Cities ON Country || ':' || Name USING sum(Population);
多个USING子句:
PIVOT Cities
ON Year
USING sum(Population) total, max(Population) max
GROUP BY Country;
可以将多个PIVOT语句结果连接起来:
FROM (PIVOT Cities ON Year USING sum(Population) GROUP BY Country) year_pivot
JOIN (PIVOT Cities ON Name USING sum(Population) GROUP BY Country) name_pivot
USING (Country);
UNPIVOT逆透视
语法总结:
UNPIVOT ⟨dataset⟩
ON ⟨column(s)⟩
INTONAME ⟨name-column-name⟩VALUE ⟨value-column-name(s)⟩
ORDER BY ⟨column(s)-with-order-direction(s)⟩
LIMIT ⟨number-of-rows⟩;
相对PIVOT的逆操作就是UNPIVOT,首先生成测试数据:
CREATE OR REPLACE TABLE monthly_sales(empid INTEGER, dept TEXT, Jan INTEGER, Feb INTEGER, Mar INTEGER, Apr INTEGER, May INTEGER, Jun INTEGER);
INSERT INTO monthly_sales VALUES(1, 'electronics', 1, 2, 3, 4, 5, 6),(2, 'clothes', 10, 20, 30, 40, 50, 60),(3, 'cars', 100, 200, 300, 400, 500, 600);
FROM monthly_sales;
empid|dept |Jan|Feb|Mar|Apr|May|Jun|
-----+-----------+---+---+---+---+---+---+1|electronics| 1| 2| 3| 4| 5| 6|2|clothes | 10| 20| 30| 40| 50| 60|3|cars |100|200|300|400|500|600|
基本用法示例:
UNPIVOT monthly_sales
ON jan, feb, mar, apr, may, jun
INTO NAME month VALUE sales;
对应的标准语法:
FROM monthly_sales UNPIVOT (salesFOR month IN (jan, feb, mar, apr, may, jun)
);
empid|dept |month|sales|
-----+-----------+-----+-----+1|electronics|Jan | 1|1|electronics|Feb | 2|1|electronics|Mar | 3|1|electronics|Apr | 4|1|electronics|May | 5|1|electronics|Jun | 6|2|clothes |Jan | 10|2|clothes |Feb | 20|2|clothes |Mar | 30|2|clothes |Apr | 40|2|clothes |May | 50|2|clothes |Jun | 60|3|cars |Jan | 100|3|cars |Feb | 200|3|cars |Mar | 300|3|cars |Apr | 400|3|cars |May | 500|3|cars |Jun | 600|
上面的写法需要手动指定被堆叠的列,但duckdb也支持动态列的语法:
UNPIVOT monthly_sales
ON COLUMNS(* EXCLUDE (empid, dept))
INTO NAME month VALUE sales;
对应的标准语法:
FROM monthly_sales UNPIVOT (salesFOR month IN (columns(* EXCLUDE (empid, dept)))
);
这样可以使用排除语法,将除了empid, dept以外的列都作为被堆叠的列。
同时还可以堆叠时分组:
UNPIVOT monthly_sales
ON (jan, feb, mar) AS q1, (apr, may, jun) AS q2
INTO NAME quarter
VALUE m1_sales, m2_sales, m3_sales;
标准语法:
FROM monthly_sales
UNPIVOT ((month_1_sales, month_2_sales, month_3_sales)FOR quarter IN ((jan, feb, mar) AS q1,(apr, may, jun) AS q2)
);
empid|dept |quarter|m1_sales|m2_sales|m3_sales|
-----+-----------+-------+--------+--------+--------+1|electronics|q1 | 1| 2| 3|1|electronics|q2 | 4| 5| 6|2|clothes |q1 | 10| 20| 30|2|clothes |q2 | 40| 50| 60|3|cars |q1 | 100| 200| 300|3|cars |q2 | 400| 500| 600|
指定列时支持表达式(分组内的组内字段不支持):
UNPIVOT monthly_sales
ON jan*3 Jan3, feb*5 Feb5, COLUMNS(* EXCLUDE (empid,dept,Jan,Feb))
INTO NAME month VALUE sales
limit 5;
empid|dept |month|sales|
-----+-----------+-----+-----+1|electronics|Jan3 | 3|1|electronics|Feb5 | 10|1|electronics|Mar | 3|1|electronics|Apr | 4|1|electronics|May | 5|
WITH子句-CTE
基本示例:
WITHcte1(i) AS (SELECT 42),cte2(x) AS (SELECT i * 100 FROM cte1)
SELECT * FROM cte2;
如果一个cte需要反复被使用,而且查询开销很大,可以使用MATERIALIZED关键字将其物化,仅查询一次:
WITH t(x) AS MATERIALIZED (⟨complex_query⟩)
SELECT *
FROMt AS t1,t AS t2,t AS t3;
WITH RECURSIVE允许定义可以引用自身的CTE,比如计算前十个斐波那契数:
WITH RECURSIVE FibonacciNumbers (n, num, next_num) AS (SELECT0 AS n,0 AS num,1 AS next_numUNION ALLSELECTfib.n + 1 AS n,fib.next_num AS num,fib.num + fib.next_num AS next_numFROMFibonacciNumbers fibWHEREfib.n + 1 < 10)
SELECTfn.n,fn.num
FROMFibonacciNumbers fn;
结果:
n|num|
-+---+
0| 0|
1| 1|
2| 1|
3| 2|
4| 3|
5| 5|
6| 8|
7| 13|
8| 21|
9| 34|
注意:必须确保终止的方式,否则可能会陷入无限循环。
案例:使用WITH RECURSIVE遍历数
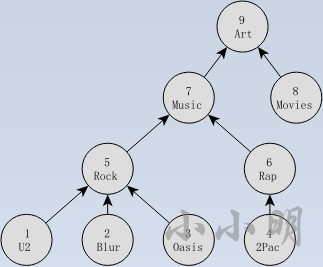
有下面这样一颗树:
数据:
CREATE TABLE tag (id INTEGER, name VARCHAR, subclassof INTEGER);
INSERT INTO tag VALUES(1, 'U2', 5),(2, 'Blur', 5),(3, 'Oasis', 5),(4, '2Pac', 6),(5, 'Rock', 7),(6, 'Rap', 7),(7, 'Music', 9),(8, 'Movies', 9),(9, 'Art', NULL);
下面遍历出到根’Art’的每条路径:
WITH RECURSIVE tag_hierarchy(id, source, path) AS (SELECT id, name, name AS pathFROM tagWHERE subclassof IS NULL
UNION ALLSELECT tag.id, tag.name, tag.name||'->'||tag_hierarchy.pathFROM tag join tag_hierarchyon tag.subclassof = tag_hierarchy.id
)
SELECT * FROM tag_hierarchy;
id|source|path |
--+------+-----------------------+9|Art |Art |7|Music |Music->Art |8|Movies|Movies->Art |5|Rock |Rock->Music->Art |6|Rap |Rap->Music->Art |1|U2 |U2->Rock->Music->Art |2|Blur |Blur->Rock->Music->Art |3|Oasis |Oasis->Rock->Music->Art|4|2Pac |2Pac->Rap->Music->Art |
这样成功查询到自己指向的路径。
QUALIFY筛选窗口函数的结果
having子句可以筛选聚合后的结果,而QUALIFY可以筛选窗口函数的计算结果,无需使用子查询二次筛选。
SELECT DISTINCT schema_name,function_name,DENSE_RANK() OVER (PARTITION BY schema_name ORDER BY function_name) AS function_rank
FROM duckdb_functions()
QUALIFY function_rank < 4;
schema_name|function_name |function_rank|
-----------+----------------+-------------+
main |!~~ | 2|
pg_catalog |current_database| 2|
main |!~~* | 3|
pg_catalog |current_query | 3|
pg_catalog |col_description | 1|
main |!__postfix | 1|
window子句可以被定义复用:
SELECT DISTINCT schema_name,function_name,DENSE_RANK() OVER w1 AS function_rank
FROM duckdb_functions()
window w1 as (PARTITION BY schema_name ORDER BY function_name)
QUALIFY DENSE_RANK() OVER w1 < 4;
FILTER 筛选子句
FILTER子句作用在SELECT语句中的聚合函数之后,使聚合函数只聚合满足条件的行。
首先准备测试数据:
CREATE TEMP TABLE stacked_data AS
SELECTi,CASE WHEN i <= 250 THEN 2022WHEN i <= 500 THEN 2023WHEN i <= 750 THEN 2024WHEN i <= 875 THEN 2025ELSE NULLEND AS year
FROM generate_series(1, 1000) tbl(i);
要统计每年的行数,在不使用groupy By聚合的情况下,常规的实现如下:
SELECTcount(if(year=2022,i,null)) AS "2022",count(if(year=2023,i,null)) AS "2023",count(if(year=2024,i,null)) AS "2024",count(if(year=2025,i,null)) AS "2025",count(if(year is null,i,null)) AS "NULLs"
FROM stacked_data;
如果使用FILTER 语法:
SELECTcount(i) FILTER (year = 2022) AS "2022",count(i) FILTER (year = 2023) AS "2023",count(i) FILTER (year = 2024) AS "2024",count(i) FILTER (year = 2025) AS "2025",count(i) FILTER (year IS NULL) AS "NULLs"
FROM stacked_data;
FILTER 语法对于fisrt之类的函数更有优势:
SELECTfirst(i) FILTER (year = 2022) AS "2022",first(i) FILTER (year = 2023) AS "2023",first(i) FILTER (year = 2024) AS "2024",first(i) FILTER (year = 2025) AS "2025",first(i) FILTER (year IS NULL) AS "NULLs"
FROM stacked_data;
集合运算相关语句
竖向合并:duckdb除了常规的UNION和UNION ALL语句外,还支持UNION BY NAME和UNION ALL BY NAME
UNION相对UNION ALL会额外去重,UNION BY NAME可以按照列名进行合并,而无需被合并的表列名完全一致。
基本示例:
from (VALUES ('Amsterdam', 'NL'),('Berlin', 'Germany')) capitals(city, country)
UNION BY NAME
from (VALUES ('Amsterdam', 10, '2022-10-14'),('Seattle', 8, '2022-10-12')) weather(city, degrees, date);
city |country|degrees|date |
---------+-------+-------+----------+
Amsterdam| | 10|2022-10-14|
Amsterdam|NL | | |
Seattle | | 8|2022-10-12|
Berlin |Germany| | |
UNION ALL相当于竖向合并,duckdb还支持通过位置连接进行横向合并:
CREATE or replace TABLE t1 (x INTEGER);
CREATE or replace TABLE t2 (s VARCHAR);
INSERT INTO t1 VALUES (1), (2), (3);
INSERT INTO t2 VALUES ('a'), ('b');SELECT * FROM t1 POSITIONAL JOIN t2;
x|s|
-+-+
1|a|
2|b|
3| |
交集,示例:
SELECT unnest([5, 5, 6, 6, 6, 6, 7, 8]) AS x
INTERSECT
SELECT unnest([5, 6, 6, 7, 7, 9]);
x|
-+
5|
7|
6|
如果需要包含重复项,使用INTERSECT ALL。
差集:从第一个表中去除第二个表的内容,示例:
SELECT unnest([5, 5, 6, 6, 6, 6, 7, 8, 8]) AS x
EXCEPT
SELECT unnest([5, 6, 6, 7, 7, 9]);
x|
-+
8|
使用EXCEPT ALL不会先去重:
SELECT unnest([5, 5, 6, 6, 6, 6, 7, 8, 8]) AS x
EXCEPT ALL
SELECT unnest([5, 6, 6, 7, 7, 9]);
x|
-+
6|
6|
8|
8|
5|
分组TOP N
示例数据:
CREATE OR REPLACE table t1 as
SELECT UNNEST(['a','a','b','b','b','b']) grp,UNNEST([2,1,5,4,3,6]) val;
SELECT * FROM t1;
grp|val|
---+---+
a | 2|
a | 1|
b | 5|
b | 4|
b | 3|
b | 6|
如果需要获取每组最大的3个值,只需:
SELECT grp, UNNEST(max(val, 3)) val FROM t1 GROUP BY grp
order by grp,val;
grp|val|
---+---+
a | 1|
a | 2|
b | 4|
b | 5|
b | 6|
duckdb的一些函数语法
duckdb的函数都支持点语法调用,一个函数调用fn(arg1, arg2, arg3, ...)可以写成 arg1.fn(arg2, arg3, ...)。
例如:
SELECT replace(goose_name, 'goose', 'duck') AS duck_name
FROM unnest(['African goose', 'Faroese goose', 'Hungarian goose', 'Pomeranian goose']) breed(goose_name);
可以写成:
SELECT goose_name.replace('goose', 'duck') AS duck_name
FROM unnest(['African goose', 'Faroese goose', 'Hungarian goose', 'Pomeranian goose']) breed(goose_name);
可以通过duckdb_functions()查询当前内置到系统中的函数列表:
SELECT DISTINCT ON(function_name)function_name,function_type,return_type,parameters,parameter_types,description
FROM duckdb_functions()
WHERE function_type = 'scalar'AND function_name LIKE 'b%'
ORDER BY function_name;
完整的函数介绍请查看:https://duckdb.org/docs/sql/functions/overview
下面介绍一部分函数的用法:
时间日期函数
将日期/时间戳转换为字符串:
SELECT strftime('2024-09-24'::date, '%Y年%m月%d日');
SELECT strftime(TIMESTAMP '2024-09-24 20:32:45', '%Y-%m-%d %H:%M');
将字符串解析为时间戳:
SELECT strptime('02/03/1998', '%d/%m/%Y');
使用try_strptime函数可以在转换失败时返回null。
完整的时间日期格式化符号:https://duckdb.org/docs/sql/functions/dateformat#format-specifiers
日期支持直接进行加减:
SELECT '2022-03-22'::DATE + 5;
SELECT '2022-03-22'::DATE - '2022-03-15'::DATE;
SELECT '2022-03-22'::DATE - INTERVAL 7 DAY;
上述第一个sql的+5等价于+ INTERVAL 5 DAY
日期函数示例:
current_date和today()获取当前日期
date_add(DATE '1992-09-15', INTERVAL 2 MONTH)
date_diff('month', DATE '1992-09-15', DATE '1992-11-14')
date_sub('month', DATE '1992-09-15', DATE '1992-11-14')
date_part等价于extract,提取指定部分:
date_part('year', DATE '1992-09-20')结果1992
截断至指定精度:date_trunc('month', DATE '1992-03-07')结果1992-03-01
greatest获取较大值,least获取较小值:
greatest(DATE '1992-09-20', DATE '1992-03-07')结果1992-09-20
last_day(DATE '1992-02-15')可以获取对应月份最后一天,例如1992-09-30
make_date(1992, 9, 20)根据年月日创建日期类型数据
date_part、date_diff和date_trunc函数都涉及提取部分,支持的提取部分包含:
‘century’、‘day’、‘hour’、‘milliseconds’、‘minute’、‘month’、‘quarter’、‘second’、‘year’
其中quarter表示季度,century表示世纪。
List相关函数
duckdb支持Lambda函数,例如:
list_transform([4, 5, 6], x -> x + 1) -- [5, 6, 7]
list_filter([4, 5, 6], x -> x > 4) -- [5, 6]
list_filter([1, 3, 1, 5], (x, i) -> x > i); -- [3, 5]
list_reduce([4, 5, 6], (x, y) -> x + y) -- 15
示例1:
SELECT list_transform(list_filter([0, 1, 2, 3, 4, 5], x -> x % 2 = 0),y -> y * y);
[0, 4, 16]
SELECT list_transform([5, NULL, 6], x -> coalesce(x, 0) + 1);
[6, 1, 7]
示例2:
SELECT list_reduce(['DuckDB', 'is', 'awesome'], (x, y) -> concat(x, ' ', y));
DuckDB is awesome
示例3:
SELECT #1,list_filter([1, 2, 3, 4], x -> x > #1) FROM range(4);
range|list_filter(main.list_value(1, 2, 3, 4), (x -> (x > #1)))|
-----+---------------------------------------------------------+0|[1,2,3,4] |1|[2,3,4] |2|[3,4] |3|[4] |
上面的示例都是操作List的函数,List相关的完整函数列表请参考:https://duckdb.org/docs/sql/functions/list
list的简化操作符:
| 操作符 | 描述 | 示例 | 结果 |
|---|---|---|---|
&& | 等价于list_has_any函数 | [1, 2, 3, 4, 5] && [2, 5, 5, 6] | true |
@> | 等价于list_has_all函数 | [1, 2, 3, 4] @> [3, 4, 3] | true |
<@ | 等价于list_has_all函数,只不过左边的list对象是子列表 | [1, 4] <@ [1, 2, 3, 4] | true |
| ` | ` | 等价于list_concat函数 | |
<=> | 等价于list_cosine_distance函数,计算两个列表之间的余弦距离 | [1, 2, 3] <=> [1, 2, 5] | 0.007416606 |
<-> | 等价于list_distance函数,计算欧几里得距离 | [1, 2, 3] <-> [1, 2, 5] | 2.0 |
duckdb中也支持Python的列表生成式的语法,例如:
SELECT [upper(x) FOR x IN strings IF len(x) > 0] AS strings
FROM (VALUES (['Hello', '', 'World'])) t(strings);
strings |
-----------------+
['HELLO','WORLD']|
python中往往使用enumerate获取元素的位置,duckdb则可以直接获取列表位置,例如:
SELECT [4, 5, 6] as l,[i FOR _, i IN l] as t, [x FOR x, i IN l IF i != 2] filtered;
l |t |filtered|
-------+-------+--------+
[4,5,6]|[1,2,3]|[4,6] |
可以看到duckdb列表的起始位置从1开始。
duckdb的range函数与Python一致,同时duckdb还提供了generate_series函数,相对range(start, stop, step)的区别在于,generate_series的stop函数会被包含,例如:
SELECT generate_series(2, 5);
[2, 3, 4, 5]
generate_subscripts(arr, dim)函数的作用是沿数组的第dim个维度生成索引:
SELECT generate_subscripts([4, 5, 6], 1) AS i;
i|
-+
1|
2|
3|
第二个参数,目前的版本1.1.0可以写死1忽略即可,因为超过1的维度还没有实现不支持。
同时range和generate_series函数还能针对日期进行生成,例如:
SELECT year(x) "year"
FROM generate_series(DATE '2020-01-01', DATE '2024-01-01', INTERVAL '1' year) t(x);
year|
----+
2020|
2021|
2022|
2023|
2024|
duckdb的数组和列表都支持类似Python的切片语法。
对列表进行聚合可以使用list_aggregate函数:
SELECT list_aggregate([2, 4, 8, 42], 'sum');
SELECT list_aggregate([2, 4, 8, 42], 'string_agg', '|');
注意:
list_aggregate可以简写为list_aggr
不过几乎都有list_*的语法,但是不支持多余的参数,上面两个语法可以写成:
SELECT list_sum([2, 4, 8, 42]); -- 56
SELECT list_string_agg([2, 4, 8, 42]); -- 2,4,8,42
list_string_agg无法指定分割符,但是可以使用array_to_string函数:
SELECT array_to_string([2, 4, 8, 42], '|');
list内部聚合函数有: list_avg, list_var_samp, list_var_pop, list_stddev_pop, list_stddev_samp, list_sem, list_approx_count_distinct, list_bit_xor, list_bit_or, list_bit_and, list_bool_and, list_bool_or, list_count, list_entropy, list_last, list_first, list_kurtosis, list_kurtosis_pop, list_min, list_max, list_product, list_skewness, list_sum, list_string_agg, list_mode, list_median, list_mad 和 list_histogram
列表排序使用list_sort:
SELECT list_sort([1, 3, NULL, 2], 'DESC', 'NULLS FIRST');
[NULL, 3, 2, 1]
倒序也可以使用list_reverse_sort:
SELECT list_reverse_sort([1, 3, NULL, 2], 'NULLS LAST');
[3, 2, 1, NULL]
flatten用于拉平数组,与Python一致。
模式匹配函数
DuckDB主要提供了三种模式匹配方法:传统的SQL的LIKE操作符、SIMILAR TO操作符 和 POSIX风格的正则表达式。其中SIMILAR TO操作符可以理解为就是全匹配的正则表达式。
传统的like语法就是_表示一个字符,%表示任意字符,示例:
SELECT 'abc' LIKE 'a%' ; -- true
SELECT 'abc' LIKE '_b_'; -- true
SELECT 'abc' LIKE 'c'; -- false
SELECT 'abc' LIKE 'c%' ; -- false
SELECT 'abc' LIKE '%c'; -- true
SELECT 'abc' NOT LIKE '%c'; -- false
如果需要不区分大小写,可以使用ILIKE:
SELECT 'ABC' ILIKE '%c'; -- true
如果搜索模式中存在% 或 _,则必须使用 ESCAPE 指定转义字符,例如:
SELECT 'a%c' LIKE 'a$%c' ESCAPE '$'; -- true
SELECT 'a%c' LIKE 'a^%c' ESCAPE '^'; -- true
SELECT 'azc' LIKE 'a$%c' ESCAPE '$'; -- false
duckdb的like兼容PostgreSQL的符号,下面是替代表:
| LIKE风格 | PostgreSQL风格 |
|---|---|
| LIKE | ~~ |
| NOT LIKE | !~~ |
| ILIKE | ~~* |
| NOT ILIKE | !~~* |
SIMILAR TO的示例:
SELECT 'abc' SIMILAR TO 'a'; -- false
SELECT 'abc' SIMILAR TO '.*(b|d).*'; -- true
SELECT 'abc' SIMILAR TO '(b|c).*'; -- false
SELECT 'abc' NOT SIMILAR TO 'abc'; -- false
可以看到SIMILAR TO要求对应的正则必须是全匹配,使用regexp_matches函数只需要部分匹配即可:
SELECT regexp_matches('abc', 'a'); -- true
SELECT regexp_matches('abc', '^a$'); -- false
SELECT regexp_matches('abc', '.*(b|d).*'); -- true
SELECT regexp_matches('abc', '(b|c).*'); -- true
SELECT regexp_matches('abc', '^(b|c).*'); -- false
SELECT regexp_matches('abc', '(?i)A'); -- true
SELECT regexp_matches('abc', 'A', 'i'); -- true
其中最后一个正则的第三个参数i表示不区分大小写,还可以指定s模式让.可以匹配换行符。
指定c模式区分大小写匹配,如果可能,duckdb会将regexp_matches表达式优化为LIKE等常规语句,但对于基本的模式匹配需求,我们可以自行使用like。
同时duckdb还支持正则替换和正则抽取等等。
使用regexp_replace的一些示例:
SELECT regexp_replace('abc', '(b|c)', 'X'); -- aXc
SELECT regexp_replace('abc', '(b|c)', 'X', 'g'); -- aXX
SELECT regexp_replace('abc', '(b|c)', '\1\1\1\1'); -- abbbbc
SELECT regexp_replace('abc', '(.*)c', '\1e'); -- abe
SELECT regexp_replace('abc', '(a)(b)', '\2\1'); -- bac
regexp_extract函数可以使用组参数提取模式内的特定捕获组。如果未指定group,则默认为0提取整个模式:
SELECT regexp_extract('abc', '.b.'); -- abc
SELECT regexp_extract('abc', '([a-z])(b)', 1); -- a
SELECT regexp_extract('abc', '([a-z])(b)', 2); -- b
如果需要同时提取多个组的内容,可以传入name_list参数:
SELECT regexp_extract('2023-04-15', '(\d+)-(\d+)-(\d+)', ['y', 'm', 'd']);
{y=2023, m=04, d=15}
如果name_list参数的数量少于分组数量,则只返回对应的前几组,若大于实际分组数量,则会报错。
duckdb的Extensions扩展
DuckDB允许动态加载扩展,支持更多的功能。要查看当前的扩展,可以使用duckdb_extensions:
SELECT * FROM duckdb_extensions();
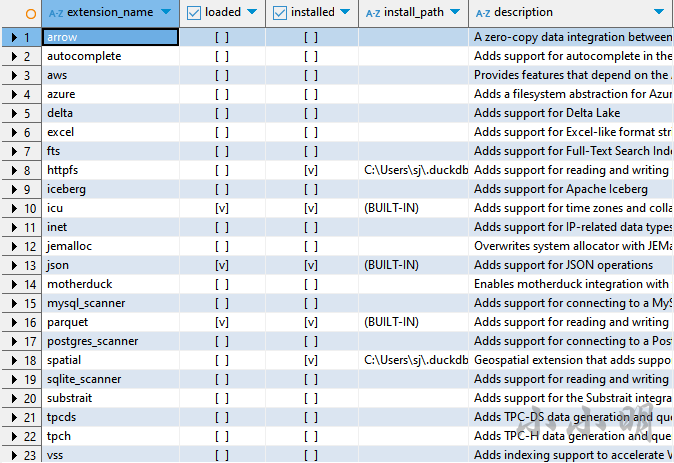
此列表显示哪些扩展可用,安装了哪些扩展,版本,安装位置等。该列表包括大多数,完整列表可以查看:https://duckdb.org/docs/extensions/core_extensions.html
扩展的基本概念
扩展安装是将下载的扩展和一些元数据存储在本地目录中。然后,DuckDB可以在需要时从该目录加载扩展。
扩展加载是将二进制文件动态加载到DuckDB实例中的过程。DuckDB将在本地扩展目录中搜索已安装的扩展,然后加载它以使其功能可用。每次重启DuckDB时,都需要重新加载所有使用的扩展。
显式安装和加载扩展,使用LOAD和INSTALL语句,例如:
INSTALL excel;
LOAD excel;
对于许多核心扩展,DuckDB使用自动加载机制,例如执行下面的语句时:
SELECT *
FROM 'https://raw.githubusercontent.com/duckdb/duckdb-web/main/data/weather.csv';
DuckDB将自动安装并加载httpfs扩展,完成对目标文件的下载。
要确保当前安装的所有扩展都是最新版本,可以调用:
UPDATE EXTENSIONS;
只更新特定的扩展:
UPDATE EXTENSIONS (httpfs, azure);
默认情况下,扩展安装在用户的主目录下:~/.duckdb/extensions/⟨duckdb_version⟩/⟨platform_name⟩/
例如本人电脑当前版本的DuckDB的扩展安装在C:\Users\xxm\.duckdb\extensions\v1.1.0\windows_amd64
要更改DuckDB存储其扩展的默认位置,可以使用extension_directory配置选项:
SET extension_directory = '/path/to/your/extension/directory';
注意:相同DuckDB版本的客户端API之间会共享扩展,例如在Java客户端中安装的Excel扩展,可以直接在Python客户端中加载。
加载未签名的扩展需要在启动连接时设置参数allow_unsigned_extensions为true。
扩展存储库
默认的存储库是core,指向http://extensions.duckdb.org
官方还提供了 core_nightly存储库,指向http://nightly-extensions.duckdb.org,可以在正式发布之前尝试扩展中的新功能。
从尝鲜库安装扩展,示例:
INSTALL spatial FROM core_nightly;
或:
INSTALL spatial FROM 'http://nightly-extensions.duckdb.org';
社区扩展community指向http://community-extensions.duckdb.org
若需要调整默认存储库的位置,可以设置custom_extension_repository:
SET custom_extension_repository = 'http://nightly-extensions.duckdb.org';
要强制重新下载扩展,使用FORCE INSTALL,例如:
FORCE INSTALL spatial FROM core_nightly;
可用于用另一个存储库中具有相同名称的扩展覆盖当前扩展。
要开发自定义扩展,可以参考:https://github.com/duckdb/extension-template/
注意:扩展一旦加载,就无法重新安装,无法卸载扩展。
使用sqllite扩展
首先下载并加载sqllite扩展:
INSTALL sqlite;
LOAD sqlite;
最直接的查询方法是使用sqlite_scan函数:
SELECT * FROM sqlite_scan('sakila.db', 'city');
下面,我使用官方提供的一份数据文件测试,下载测试文件:https://github.com/duckdb/sqlite_scanner/raw/main/data/db/sakila.db
下载后加载这份数据:
ATTACH 'D:/data/sakila.db' (TYPE SQLITE);
USE sakila;
查看表:
show tables;
name |
----------------------+
actor |
address |
category |
city |
country |
customer |
customer_list |
film |
film_actor |
film_category |
film_list |
film_text |
inventory |
language |
payment |
rental |
sales_by_film_category|
sales_by_store |
staff |
staff_list |
store |
测试查询这个数据库中的数据:
SELECTcat.name AS category_name,sum(ifnull(pay.amount, 0)) AS revenue
FROM category cat
LEFT JOIN film_category flm_catON cat.category_id = flm_cat.category_id
LEFT JOIN film filON flm_cat.film_id = fil.film_id
LEFT JOIN inventory invON fil.film_id = inv.film_id
LEFT JOIN rental renON inv.inventory_id = ren.inventory_id
LEFT JOIN payment payON ren.rental_id = pay.rental_id
GROUP BY cat.name
ORDER BY revenue DESC
LIMIT 5;
category_name|revenue |
-------------+-----------------+
Sports |5314.209999999848|
Sci-Fi | 4756.97999999987|
Animation |4656.299999999864|
Drama |4587.389999999876|
Comedy |4383.579999999895|
由于DuckDB是强类型的数据库,而SQLite是弱类型的数据库,部分在SQLite有效的SQL在DuckDB中无法执行。设置sqlite_all_varchar选项可以避免此错误:
SET GLOBAL sqlite_all_varchar = true;
设置此选项后,会始终将SQLite列转换为VARCHAR列。
通过duckdb创建SQLite数据库示例:
ATTACH 'new_sqlite_database.db' AS sqlite_db (TYPE SQLITE);
CREATE TABLE sqlite_db.tbl (id INTEGER, name VARCHAR);
INSERT INTO sqlite_db.tbl VALUES (42, 'DuckDB');
使用MySQL扩展
首先安装并加载MySQL扩展:
INSTALL mysql;
LOAD mysql;
访问MySQL数据库:
ATTACH 'host=localhost user=root password=123456 port=3306 database=test' AS mysqldb (TYPE MYSQL);
USE mysqldb;
这样就已连接成功,查看表:
show tables;
正常执行。
连接成功后,可以正常在MySQL数据库中创建表:
CREATE TABLE mysqldb.tbl (id INTEGER, name VARCHAR);
INSERT INTO mysqldb.tbl VALUES (42, 'DuckDB');
但是duckdb并不能执行所有MySQL支持语法,要执行任意MySQL查询语法,可以使用mysql_query函数:
SELECT * FROM mysql_query('mysqldb', 'SELECT * FROM employees LIMIT 3');
如果需要执行任意增删改查语句,可以使用mysql_execute:
CALL mysql_execute('mysqldb', 'CREATE TABLE my_table (i INTEGER)');
DuckDB缓存了表的名称和列等信息,执行函数mysql_clear_cache可以清除内部缓存:
CALL mysql_clear_cache();
实现多数据库间的交互
比如分别有MySQL、Postgres和SQLite三个数据库:
ATTACH 'sakila.db' AS sqlite (TYPE SQLITE);
ATTACH 'host=localhost port=5432 dbname=ps' AS postgres (TYPE postgres);
ATTACH 'user=root database=mysqlscanner' AS mysql (TYPE MYSQL);
将film表复制到 MySQL,将actor表复制到 Postgres:
CREATE TABLE mysql.film AS FROM sqlite.film;
CREATE TABLE postgres.actor AS FROM sqlite.actor;
现在跨数据库连接找到所有出演Ace Goldfinger的演员:
SELECT first_name, last_name
FROM mysql.film
JOIN sqlite.film_actor ON (film.film_id = film_actor.film_id)
JOIN postgres.actor ON (actor.actor_id = film_actor.actor_id)
WHERE title = 'ACE GOLDFINGER';
spatial扩展实现Excel读写
首先需要安装并加载spatial扩展:
INSTALL spatial;
LOAD spatial;
layer参数允许指定Excel工作表的名称:
SELECT * FROM st_read('test_excel.xlsx', layer = 'Sheet1');
spatial扩展底层使用GDAL库执行XLSX解析,还有些配置项可以'KEY=VALUE'字符串列表的形式传递给open_options参数。
选项HEADERS支持FORCE,DISABLE和AUTO三个值。FORCE将第一行视为标题,DISABLE将第一行视为一行数据,AUTO则表示自动检测。总之可以设置第一行是否为标题,或者让引擎自动检测。
FIELD_TYPE选项,可以设置2个值,默认为AUTO表示自动检测字段类型,还可以设置为STRING,所有字段都作为字符串加载。
例如,要将第一行视为标题并将所有列类型都视为字符串:
SELECT *
FROM st_read('test_excel.xlsx',layer = 'Sheet1',open_options = ['HEADERS=FORCE', 'FIELD_TYPES=STRING']
);
要导出Excel可以使用COPY命令:
COPY tbl TO 'output.xlsx' WITH (FORMAT GDAL, DRIVER 'xlsx');
可惜现在的GDAL只支持单工作表的导出,没有多表导出到一个工作薄的选项,只能完成简单的导出任务。
Python读写Excel测试
下面使用一份24MB的Excel文件进行测试,文件下载地址:https://archive.ics.uci.edu/dataset/352/online+retail
点击右上角DOWNLOAD按钮,得到一份压缩文件,解压后得到Online Retail.xlsx
使用pandas直接读取:
import pandas as pdfile_path = "D:\data\Online Retail.xlsx"
df = pd.read_excel(file_path)
jupyter lab显示耗时55.73s
然后我们试试calamine引擎,使用pip install python-calamine安装
对于pandas 2.0 以上的版本可以使用如下代码,让pandas使用calamine引擎:
import pandas as pd
from python_calamine.pandas import pandas_monkeypatch
pandas_monkeypatch()
file_path = "D:\data\Online Retail.xlsx"
df = pd.read_excel(file_path, engine="calamine")
耗时仅10.48s
当然对于pandas 2.2以上的版本,只不需要调用pandas_monkeypatch函数,直接指定calamine引擎。
还可以直接使用calamine引擎读取后,再转换为pandas对象,这样兼容任何pandas版本,速度也最快:
import pandas as pd
from python_calamine import CalamineWorkbookfile_path = "D:\data\Online Retail.xlsx"
workbook = CalamineWorkbook.from_path(file_path)
sheet = workbook.get_sheet_by_index(0)
data = sheet.to_python()
df = pd.DataFrame(data[1:], columns=data[0])
耗时仅6.22s
下面我们使用duckdb进行读取:
import duckdbduckdb.install_extension("spatial")
duckdb.load_extension("spatial")
file_path = "D:\data\Online Retail.xlsx"
df = duckdb.execute("SELECT * FROM st_read(?)", [file_path]).df()
耗时达到15.34s
这样看来,读取Excel使用python-calamine直接读取是最快的。
再看看Excel文件的导出,pandas直接保存:
df.to_excel("out1.xlsx", sheet_name='df', index=False)
耗时竟然达到1m 38.71s
再使用duckdb保存Excel:
import duckdbduckdb.install_extension("spatial")
duckdb.load_extension("spatial")
duckdb.sql("COPY df TO 'out2.xlsx' WITH (FORMAT GDAL, DRIVER 'xlsx')")
耗时仅14.43s。
但是duckdb底层使用 GDAL XLSX driver导出Excel,仅支持将一个表导入到一个Excel文件中,sheet_name为表名。