前言
当前BEV的研究大都基于深度学习的方法,从组织BEV特征信息的方式来看,主流方法分属两类:自底向上方法和自顶向下方法。
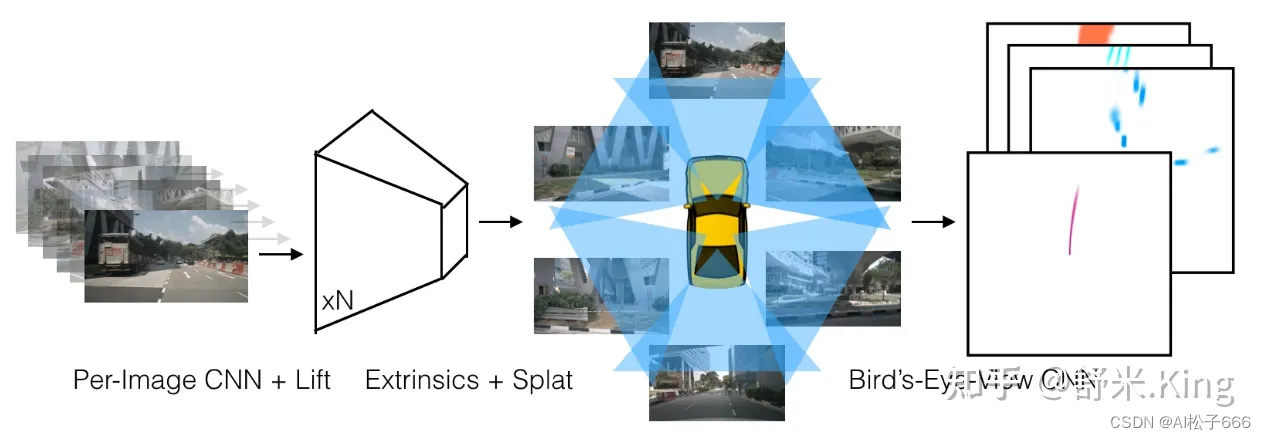
自底向上方法比较早的代表工作是LSS,后来BEVDet、BEVDepth等也是基于LSS的框架来进行优化。自底向上方法核心是:Lift——对各相机的图像显性地估计像平面下采样后特征点的深度分布,得到包含图像特征的视锥(点云);Splat——结合相机内外参把所有相机的视锥(点云)分配到BEV网格中,对每个栅格中的多个视锥点进行sum-pooling计算,形成BEV特征图;Shoot——用task head处理BEV特征图,输出感知结果。本文就是通过解读LSS和BEVDepth两篇论文,来深度剖析自底向上构建BEV方法。
自顶向下方法的典型代表是Tesla用Transformer构建BEV,2020年10月发布的FSD Beta软件视觉感知模块已开始应用此方法,在2021年Tesla AI-Day上Andrej Karparthy披露了更多技术思想,核心是:先预定义待生成的BEV特征图,利用Transformer全局感知能力在多个视角图像的特征中多次查询相应信息,并把信息融合更新到BEV特征图中。上海AILab团队做了类似的技术实现,并以BEVFormer公布了相关工作。
BEV网格
在自车周围俯视平面x-y方向划分n个网格,每个网格表示特定物理距离d米。如200200的BEV网格,每格代表0.5米,这个网格就表示100米100米的平面范围。如果恰好自车中心(自动驾驶的的车辆中心一般指后轴中心)在网格中心位置,那么网格就表示自车前、后和左、右各50米的范围。注意这里强调用网格划分平面空间,并不涉及网格内放什么内容。

BEV特征图
在BEV网格的所有格子中都填充C个通道的特征值作为内容(contex),就组成了BEV特征图。注意,为了让BEV特征图保留BEV网格x-y方向距离的意义,这里每个格子中C通道特征值都要来自格子所对应空间的特征信息,而不是胡乱地填充其它地方的特征信息。
形象地解释,假如某个格子所对应空间有个锥桶,那么这个格子里填充的一定是用来描述这个锥桶的特征值,而不是远方天空或红绿灯的特征值。
无论是自顶向下还是自底向上方法,核心目标是:为BEV网格中每个格子组织并填充合适的特征信息,得到BEV特征图。
本文解读BEV自底向上方法的两篇重要论文:LSS和BEVDepth。LSS提出了一整套自底向上构建BEV Representation的框架(ECCV2020),为后续很多相关工作奠定了系统性基础。BEVDepth在保持LSS框架的基础上,重点围绕如何获取更准确的深度估计进行优化,另外还提出了高效计算Voxel Pooling过程的方法,引入了多帧融合,这些工作使BEVDepth取得了不错的提升效果。
1. 自底向上方法框架-LSS
参考如下:
原文:Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
视锥点云和Lift操作
用单目相机进行距离、尺寸类的感知,关键是如何恢复图像中的深度信息。
2D图像中每个像素点可以理解成世界空间中某点到相机中心的一条射线,仅利用图像不能确定此像素具体来自射线上哪个位置(也就是不知道该像素的深度值),如下图3中的P,投影到P^{'},丢失了深度信息Z。

有了视锥点云,以及每个点所对应的空间位置,那么如何获得每个点的有效特征信息呢?这就由Lift-2“给每个点生成特征值(contex)”来实现。
视锥点云的特征(Context)


BEV Pillar和Splat操作
有了视锥点云(包含空间位置和特征),就可以根据视锥点的空间位置把每个视锥点的特征(contex)放到BEV网格中的合适位置,组成BEV特征图。
BEV网格由200x200个格子(BEV Pillar)组成,每个格子对应物理尺寸为0.5米x0.5米。即BEV网格对应车辆前、后和左、右各50m,且高度不限的3维空间。
上面通过相机的内外参,已经把视锥点云转换到车辆坐标系下的空间位置。排除掉BEV网格所表示空间范围(以自车为中心100mx100m范围)以外的点,就可以把剩余有效的视锥点云分配到每个BEV Pillar里。
注意,这里存在同一个BEV Pillar可能分配多个视锥点的情况,这是由两个原因引起:
1.单张2D图像不同的像素点可能投影在俯视图中的同一个位置,例如垂直于地面的电线杆,它成像的多个像素点可能投到同一个BEV Pillar。
2.相邻两相机有部分成像区域重叠,相机图像中的不同像素点投影在同一个BEV Pillar。例如不同相机画面中的同一个目标。
对于一个BEV Pillar分配多个视锥点,作者使用了sum-pooling的方法,把视锥点的特征相加,最后得到了200x200xC的BEV特征图,源码中C取64。
Shoot: Motion Planning
Lift-Splat已经输出了由N个相机图像编码的BEV features,接下来就是再接上Head来实现特定的任务,这部分由Shoot来实现。
LSS的关键是可以仅使用图像就可以实现端到端的运动规划。在测试时,用推理输出cost map进行规划的实现方法是:”Shoot”输出多种轨迹,并对各个轨迹的cost进行评分,然后根据最低cost轨迹来控制车辆运动。这部分的核心思想来自《End-to-end Interpretable Neural Motion Planner》。
pipeline
论文中对方法实现描述不清楚,把方法实现的pipeline整理到如下几个部分:

cumsum_trick(): 池化累积求和技巧
模型中使用Pillar累积求和池化,“累积求和”是通过bin id 对所有点进行排序,对所有特征执行累积求和,然后减去 bin 部分边界处的累积求和值来执行求和池化。无需依赖 autograd 通过所有三个步骤进行反向传播,而是可以导出整个模块的分析梯度,从而将训练速度提高 2 倍。 该层被称为“Frustum Pooling”,因为它将 n 个图像产生的截锥体转换为与摄像机数量 n 无关的固定维度 CxHxW 张量。
计算原理的过程示意图:

2. 出于蓝胜于蓝的自底向上方法BEVDepth
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
BEVDepth在保持LSS框架的基础上,重点围绕如何获取更准确的深度估计进行优化,另外还提出了高效计算Voxel Pooling过程的方法,引入了多帧融合,这些工作使BEVDepth取得了显著提升效果。
Motivation
近期基于视觉的自动驾驶技术中,包括自底向上的BEV方法,非常依像素赖深度估计。虽然这些方法非常受欢迎,但自然而然地还是会有疑问:这些方法中深度估计的质量和效率怎么样?已经满足了高精、高效的3D目标检测任务要求了吗?
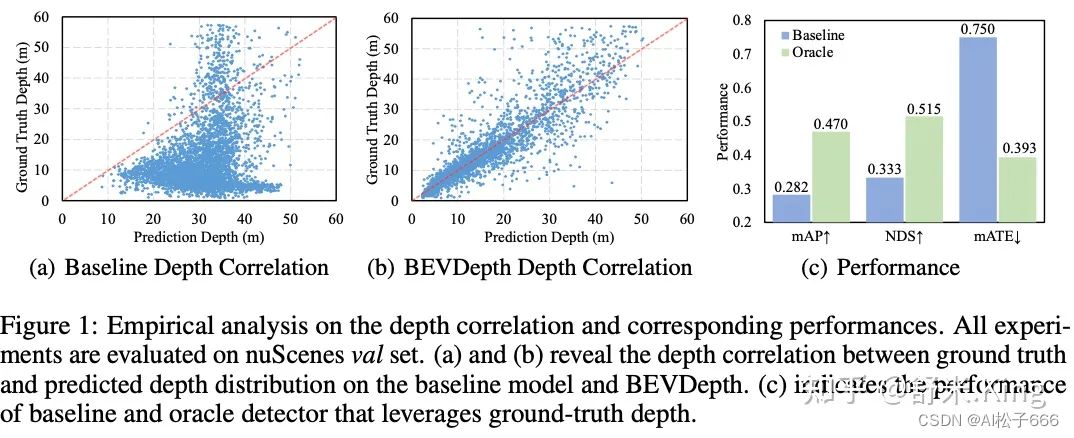
BEVDepth论文工作中从定量和定性两方面分析了深度估计。BEVDet的深度估计和真值之间的关系如图7(a)所示,会发现深度估计准确性非常不充分。这么差的深度估计对3D目标检测的影响有多大呢?作者把BEVDet中视角转换用到的深度预测值换成了深度真值,对比结果如图7©所示,采用深度真值后mAP和NDS分别提高了18.8%和18.2%。另外,translation erro(mATE)从0.750大幅下降至0.393。这些现象表明,优化深度估计质量是提升多视角3D目标检测的关键。图7(b)中展示了BEVDepth的主要工作效果,对深度估计进行修正后,深度预测值分布非常接近真值。
Methods
本文提出利用具有鲁棒性的显性深度监督(Explicit Depth Supervision)来优化深度估计,具体实现还包括深度修正(Depth Correction)和具有相机感知能力的深度估计(Camera-aware Depth Prediction)。另外,还提出了高效体素池化(Efficient Voxel Pooling)来加速BEVDepth方法,以及多帧融合(Multi-frame Fusion)来提高目标检测效果和运动速度估计。BEVDepth方法的概览如图8所示。




