- 下载语言库:tessdata语言库
- 下载好后,记住在本地路径:如: D:\tessdate\tessdata-main

- 添加 maven
<!--基于 Tesseract-OCR 封装的 OCR 识别 jar-->
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>5.8.0</version>
</dependency>- 识别代码:(识别一些简单的文字)
public static void main(String[] args) {// 需要识别的图片路径String imagePath = "C:/Users/Dell/Desktop/cc.jpg"; // 使用Tesseract进行OCRTesseract tesseract = new Tesseract();// 设置Tesseract数据路径 上面下载的本地路径tesseract.setDatapath("D:\\tessdate\\tessdata-main");// 设置语言库 中文tesseract.setLanguage("chi_sim"); try {// 进行文字识别String result = tesseract.doOCR(new File(imagePath));System.out.println("OCR结果:");System.out.println(result);} catch (TesseractException e) {e.printStackTrace();}}识别结果如下
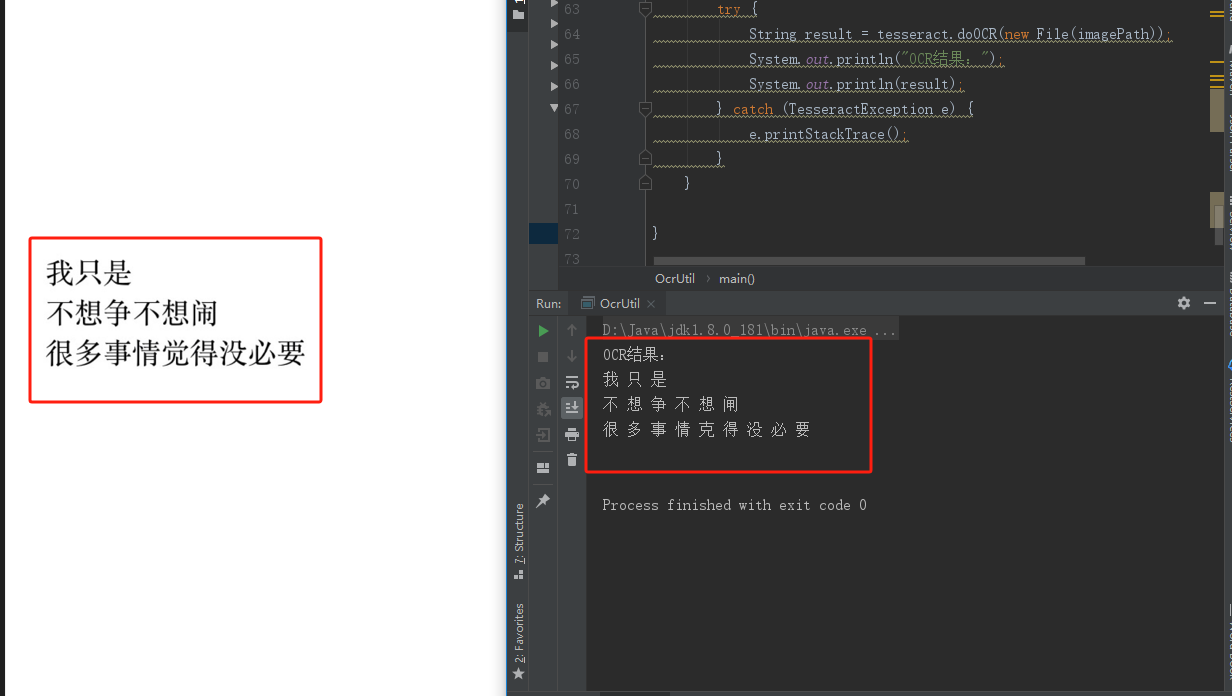
这样只能识别一些简单的文字,还可能会识别出错,想识别复杂一点的减少出错率需要配合上opencv 使用--如下:
- 添加maven
<dependency><groupId>org.bytedeco</groupId><artifactId>opencv-platform</artifactId><version>4.5.1-1.5.5</version></dependency>处理图像(根据情况修改里面的参数,找到识别率最高的参数组。注:有的参数有最小最大值或单数双数限制,不正确时会报错,从错误信息就可以看出来):
public static Mat preprocessImage(String imagePath) {// 1. 读取图像文件// 使用 OpenCV 的 imread 函数从指定路径读取图像,返回一个 Mat 对象。// Mat 是 OpenCV 中用于存储图像的基本数据结构。Mat src = opencv_imgcodecs.imread(imagePath);// 2. 转换为灰度图像// 使用 cvtColor 函数将读取的图像从 BGR 格式转换为灰度图像。// BGR 是 OpenCV 中默认的颜色格式,而灰度图像只有单一通道。Mat gray = new Mat();opencv_imgproc.cvtColor(src, gray, opencv_imgproc.COLOR_BGR2GRAY);// 3. 去噪// 使用 fastNlMeansDenoising 函数进行快速非局部均值去噪,主要用于减少图像中的噪声。// 这个步骤可以提高图像的清晰度,尤其是在灰度图像的情况下。Mat denoised = new Mat();opencv_photo.fastNlMeansDenoising(gray, denoised);// 4. 形态学操作去除背景纹路// 使用 getStructuringElement 创建一个形态学操作的核 (kernel),它是一个 2x2 的矩形。// 在形态学处理中,核用于在图像上执行膨胀、腐蚀等操作。Mat morphKernel = opencv_imgproc.getStructuringElement(opencv_imgproc.MORPH_RECT, new Size(2, 2));// 使用 morphologyEx 进行形态学关闭操作 (MORPH_CLOSE),这是一种先膨胀后腐蚀的操作。// 这种操作可以消除图像中的小空洞或细小的黑色区域,平滑图像中的边缘。Mat morph = new Mat();opencv_imgproc.morphologyEx(denoised, morph, opencv_imgproc.MORPH_CLOSE, morphKernel);// 5. 自适应阈值处理(二值化)// 使用 adaptiveThreshold 将形态学处理后的图像转换为二值图像。// 自适应阈值会根据图像局部区域的亮度自动调整阈值,从而对亮度不均的图像效果更好。// 参数说明:// 255 是最大值,表示超过阈值的像素值将设为 255(白色)。// ADAPTIVE_THRESH_GAUSSIAN_C 表示采用高斯滤波的方式来计算阈值。// THRESH_BINARY 表示二值化处理,像素值要么为 0(黑色),要么为 255(白色)。// 3 是 blockSize,表示用于计算阈值的邻域大小。// 2 是一个常数,会从计算出来的阈值中减去,用来调整结果。Mat binary = new Mat();opencv_imgproc.adaptiveThreshold(morph, binary, 255, opencv_imgproc.ADAPTIVE_THRESH_GAUSSIAN_C, opencv_imgproc.THRESH_BINARY, 3, 2);// 6. 返回处理后的二值图像return binary;
}
使用方法:
public static void main(String[] args) {// 识别的图片路径String imagePath = "C:/Users/Dell/Desktop/ee.jpeg";// 获取处理后的图片Mat processedImage = preprocessImage(imagePath);// 保存预处理后的图像以便检查File outputDir = new File("output");if (!outputDir.exists()) {outputDir.mkdirs(); // 创建目录及所需的父目录}// 保存处理后的图片 处理后的新图片路径opencv_imgcodecs.imwrite("output/processed_image.jpg", processedImage);Tesseract tesseract = new Tesseract();tesseract.setDatapath("D:\\tessdate\\tessdata-main");tesseract.setLanguage("chi_sim");try {// 识别保存处理后的图片String result = tesseract.doOCR(new File("output/processed_image.jpg"));System.out.println("OCR结果:");System.out.println(result);} catch (TesseractException e) {e.printStackTrace();}}