小罗碎碎念
本期主题:词云图
这一期推文介绍一个非常具有实用价值的图——词云图,正好最近在准备开题答辩的PPT,顺手写一期推文,和大家分享一下。
R语言和Python的代码都准备了一份,其中Python的版本就是我用自己开始写推文以来所有推荐的期刊作为数据源,挑选了频率最高的20个期刊做的演示,大家也可以替换为自己的数据,去定制自己词云图!!


一、定义
词云(亦称为标签云或加权列表)是文本数据的可视化呈现。通常,词云中的词汇为单个词语,每个词语的重要性通过字体大小或颜色来展示。
以下是一个示例,展示了著名法国说唱艺术家Nekfeu在其几首歌曲中最常使用的词汇。
这段代码首先导入了所需的库,然后从GitHub加载了一个数据集。接下来,它过滤掉了不需要的单词,如数字、特殊字符和一些常见的停用词。然后,它使用wordcloud2库创建了一个词云图,显示了特定艺术家(nekfeu)的30个最低频单词。词云图的背景颜色为白色,单词颜色为#69b3a2。
# 导入所需的库
library(tidyverse) # 数据处理和可视化
library(hrbrthemes) # 用于美化ggplot2图形
library(tm) # 文本挖掘
library(proustr) # 提供普鲁斯特停用词列表# 从GitHub加载数据集
data <- read.table("https://raw.githubusercontent.com/holtzy/data_to_viz/master/Example_dataset/14_SeveralIndepLists.csv", header=TRUE)
to_remove <- c("_|[0-9]|\\.|function|^id|script|var|div|null|typeof|opts|if|^r$|undefined|false|loaded|true|settimeout|eval|else|artist")
# 过滤掉不需要的单词
data <- data %>% filter(!grepl(to_remove, word)) %>% filter(!word %in% stopwords('fr')) %>% filter(!word %in% proust_stopwords()$word)# 使用wordcloud2库创建词云
library(wordcloud2)# 准备一个包含最常见单词的列表(前50个)
mywords <- data %>%filter(artist=="nekfeu") %>%dplyr::select(word) %>%group_by(word) %>%summarize(freq=n()) %>%arrange(freq) %>%tail(30) # 只保留频率最低的30个单词# 创建词云图
wordcloud2(mywords, minRotation = -pi/2, maxRotation = -pi/2,backgroundColor = "white", color="#69b3a2")

二、用途
词云用于快速识别最突出的术语,并通过字母顺序定位某个术语以确定其相对重要性。它广泛应用于媒体领域,并为公众所熟知。
然而,词云作为一种信息传达方式,因其缺乏准确性而受到高度批评。这主要是由于以下两个主要原因:
面积作为数值的隐喻,对于人眼来说难以准确感知。因此,读者难以将单词的大小转换为精确的频率。
由于较长单词由更多字母组成,因此在构造上显得更大。这种偏差使得词云的准确性进一步降低。
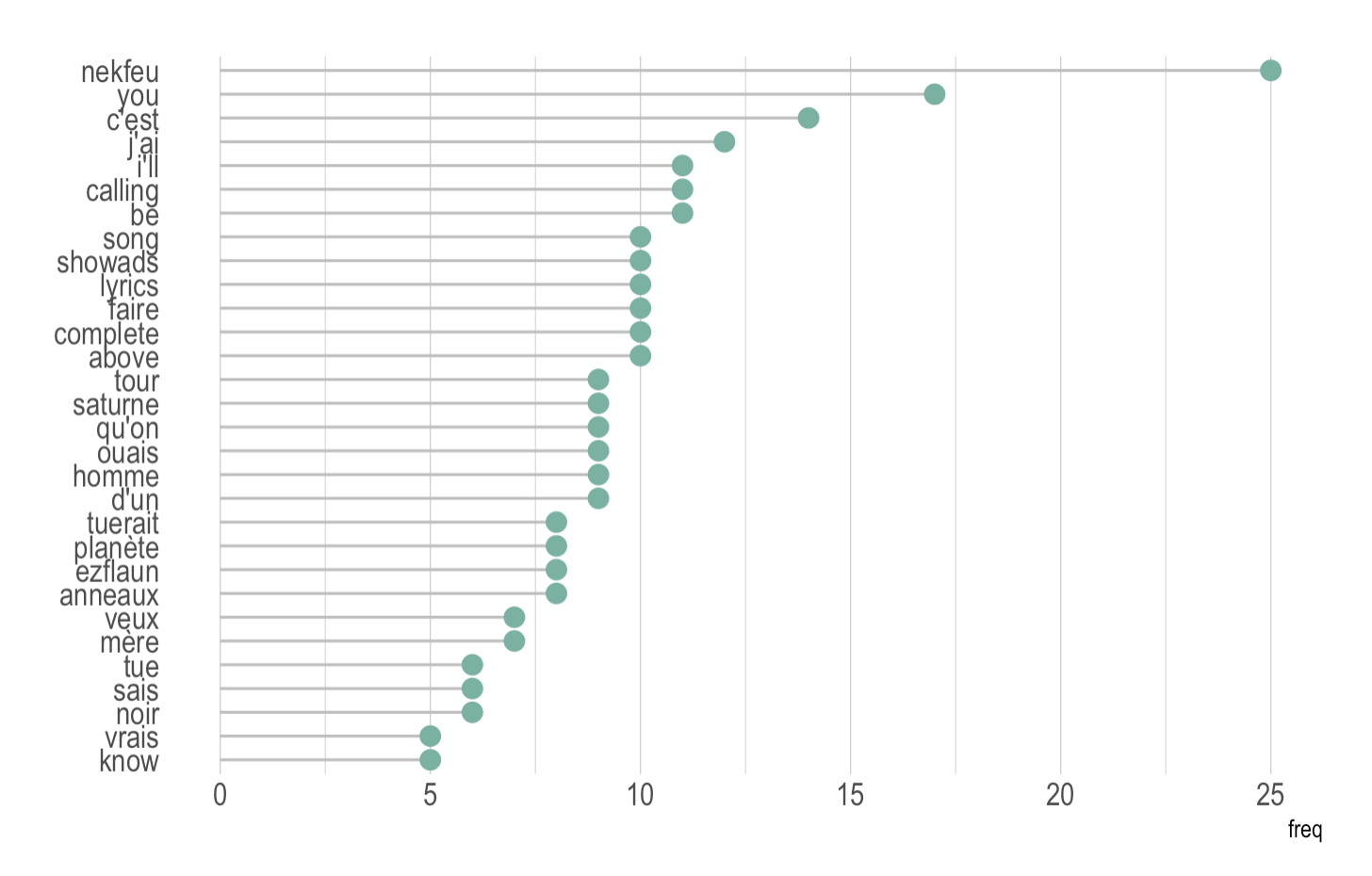
一个有效的解决方案是使用条形图或棒棒糖图来替代。以下是一个使用与前一个图表相同数据的示例:
这段代码首先筛选出特定艺术家(nekfeu)的数据,然后计算每个单词的频率,并选择频率最低的30个单词。接下来,它使用ggplot2库创建了一个条形图,显示了这些单词及其频率。条形图的背景颜色为默认值,单词颜色为#69b3a2。通过应用theme_ipsum()主题,图形的外观得到了美化。最后,移除了次要和主要的网格线以及图例,并将x轴标签设置为空。
# 准备一个包含最常见单词的列表(前30个)
data %>%filter(artist=="nekfeu") %>% # 筛选特定艺术家的数据dplyr::select(word) %>% # 选择单词列group_by(word) %>% # 按单词分组summarize(freq=n()) %>% # 计算每个单词的频率arrange(freq) %>% # 按频率排序tail(30) %>% # 选择频率最低的30个单词mutate(word=factor(word, word)) %>% # 将单词转换为因子,以便在ggplot中正确显示ggplot( aes(x=word, y=f5)) + # 使用ggplot创建图形,设置x轴为单词,y轴为频率geom_segment( aes(x=word ,xend=word, y=0, yend=freq), color="grey") + # 添加垂直线段,表示单词的频率geom_point(size=3, color="#69b3a2") + # 添加点,表示单词的频率coord_flip() + # 将x轴和y轴互换,使单词在水平方向上排列theme_ipsum() + # 应用hrbrthemes库中的主题theme(panel.grid.minor.y = element_blank(), # 移除次要网格线panel.grid.major.y = element_blank(), # 移除主要网格线legend.position="none" # 移除图例) +xlab("") # 设置x轴标签为空
三、变体
词云存在多种变体。形状常常被改变,有时会使用与主题相关的物体形状。此外,还可以调整文本的方向、字体、大小、颜色等。
这段代码首先筛选出特定艺术家(nekfeu)的数据,然后计算每个单词的频率,并选择频率最高的前200个单词。接下来,它使用wordcloud2库创建了一个词云图,显示了这些单词及其频率。词云图的形状为星形,背景颜色为白色,单词颜色为#69b3a2。
为了将词云图保存为图片,代码使用了webshot库。首先,它将词云图保存为一个临时的HTML文件。然后,使用webshot函数将HTML文件转换为PNG图片。图片的宽度、高度和延迟时间分别设置为700像素、700像素和5秒。
# 准备一个包含最常见单词的列表(前200个)
mywords <- data %>%filter(artist=="nekfeu") %>% # 筛选特定艺术家的数据dplyr::select(word) %>% # 选择单词列group_by(word) %>% # 按单词分组summarize(freq=n()) %>% # 计算每个单词的频率arrange(desc(freq)) %>% # 按频率降序排序head(200) # 选择频率最高的前200个单词# 创建词云图
library(webshot) # 导入webshot库,用于将HTML图形转换为图片
#webshot::install_phantomjs() # 安装PhantomJS,用于渲染HTML图形(如果尚未安装)# 生成词云图
my_graph=wordcloud2(mywords, size=0.6, shape = 'star', backgroundColor = "white", color="#69b3a2")library("htmlwidgets") # 导入htmlwidgets库,用于保存HTML图形
saveWidget(my_graph,"tmp.html", selfcontained = F) # 将词云图保存为临时HTML文件# 将HTML图形转换为PNG图片
webshot("tmp.html","IMG/fig_1.png", delay =5, vwidth = 700, vheight=700)

四、Python版本
4-1:方形版本
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 读取Excel文件
file_path = '/Users/luoxiaoluotongxue/Desktop/master_record/科研绘图/每日科研绘图/24-09/期刊统计.xlsx' # 替换为你的Excel文件路径
df = pd.read_excel(file_path)# 确保数据只有一列
if df.shape[1] != 1:raise ValueError("Excel文件必须只包含一列数据")# 获取频率最高的十个值
top_ten = df.iloc[:, 0].value_counts().head(20) # 确保选择正确的列# 将频率最高的十个值转换为字符串形式
top_ten_str = ' '.join([f"{word} {freq}" for word, freq in top_ten.items()])# 生成词云图
wordcloud = WordCloud(width=800, height=400, background_color='white', max_words=20).generate(top_ten_str)# 显示词云图
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 不显示坐标轴
plt.show()# 保存词云图
wordcloud.to_file('wordcloud.png')

4-2:圆形版本
import numpy as np
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image# 读取Excel文件
file_path = '/Users/luoxiaoluotongxue/Desktop/master_record/科研绘图/每日科研绘图/24-09/期刊统计.xlsx' # 替换为你的Excel文件路径
df = pd.read_excel(file_path)# 确保数据只有一列
if df.shape[1] != 1:raise ValueError("Excel文件必须只包含一列数据")# 获取频率最高的十个值
top_ten = df.iloc[:, 0].value_counts().head(20) # 确保选择正确的列# 将频率最高的十个值转换为字符串形式
top_ten_str = ' '.join([f"{word} {freq}" for word, freq in top_ten.items()])# 创建一个圆形的二值图像
x, y = np.ogrid[:800, :400]
mask = (x - 400) ** 2 + (y - 200) ** 2 > 200 ** 2
mask = 255 * mask.astype(int)# 生成圆形词云图
wordcloud = WordCloud(width=800, height=400, background_color='white', max_words=20, mask=mask).generate(top_ten_str)# 显示词云图
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 不显示坐标轴
plt.show()# 保存词云图
wordcloud.to_file('circular_wordcloud.png')
