这是我的第351篇原创文章。
一、引言
LSTM在1990年代被提出,用以解决循环神经网络(RNN)的梯度消失问题。LSTM在多种领域取得了成功,但随着Transformer技术的出现,其地位受到了挑战。如果将LSTM扩展到数十亿参数,并利用现代大型语言模型(LLM)的技术,同时克服LSTM的已知限制,我们能在语言建模上走多远?
论文介绍了两种新的LSTM变体:sLSTM(具有标量记忆和更新)和mLSTM(具有矩阵记忆和协方差更新规则),并将它们集成到残差块中,形成xLSTM架构。
sLSTM:引入了指数门控和新的存储混合技术,允许LSTM修订其存储决策。
mLSTM:将LSTM的记忆单元从标量扩展到矩阵,提高了存储容量,并引入了协方差更新规则,使得mLSTM可以完全并行化。
xLSTM架构:通过将sLSTM和mLSTM集成到残差块中,构建了xLSTM架构。
二、实现过程
2.1 加载数据
data = pd.read_csv('data.csv', usecols=[1], engine='python')
dataset = data.values.astype('float32')2.2 归一化处理
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)2.3 划分数据集
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]trainX, trainY = create_dataset(train, seq_len)
testX, testY = create_dataset(test, seq_len)# Create data loaders
train_dataset = TensorDataset(trainX, trainY)
test_dataset = TensorDataset(testX, testY)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.4 构建模型
models = {"xLSTM": xLSTM(input_size, head_size, num_heads, batch_first=True, layers='msm'),"LSTM": nn.LSTM(input_size, head_size, batch_first=True, proj_size=input_size),"sLSTM": sLSTM(input_size, head_size, num_heads, batch_first=True),"mLSTM": mLSTM(input_size, head_size, num_heads, batch_first=True)
}2.5 训练模型
定义训练函数:
def train_model(model, model_name, epochs=20, learning_rate=0.01):criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)train_losses = []for epoch in tqdm(range(epochs), desc=f'Training {model_name}'):model.train()epoch_loss = 0for i, (inputs, targets) in enumerate(train_loader):optimizer.zero_grad()outputs, _ = model(inputs)outputs = outputs[:, -1, :]loss = criterion(outputs, targets)loss.backward()optimizer.step()epoch_loss += loss.item()train_losses.append(epoch_loss / len(train_loader))plt.plot(train_losses, label=model_name)plt.title(f'Training Loss for {model_name}')plt.xlabel('Epochs')plt.ylabel('MSE Loss')plt.legend()plt.show()return model, train_losses开始训练:
trained_models = {}
all_train_losses = {}
for model_name, model in models.items():trained_models[model_name], all_train_losses[model_name] = train_model(model, model_name)绘制所有模型的损失函数曲线:
plt.figure()
for model_name, train_losses in all_train_losses.items():plt.plot(train_losses, label=model_name)# Plot all model losses compared
plt.title('Training Losses for all Models')
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.legend()
plt.show()
2.6 预测评估
预测:
def evaluate_model(model, data_loader):model.eval()predictions = []with torch.no_grad():for inputs, _ in data_loader:outputs, _ = model(inputs)predictions.extend(outputs[:, -1, :].numpy())return predictionstest_predictions = {}
for model_name, model in trained_models.items():test_predictions[model_name] = evaluate_model(model, test_loader)预测结果可视化:
# Plot predictions for each model
for model_name, preds in test_predictions.items():# Inverse transform the predictions and actual valuespreds = scaler.inverse_transform(np.array(preds).reshape(-1, 1))actual = scaler.inverse_transform(testY.numpy().reshape(-1, 1))plt.figure()plt.plot(actual, label='Actual')plt.plot(preds, label=model_name + ' Predictions')plt.title(f'{model_name} Predictions vs Actual')plt.legend()plt.show()# Plot all model predictions compared
plt.figure()
plt.plot(actual, label='Actual')
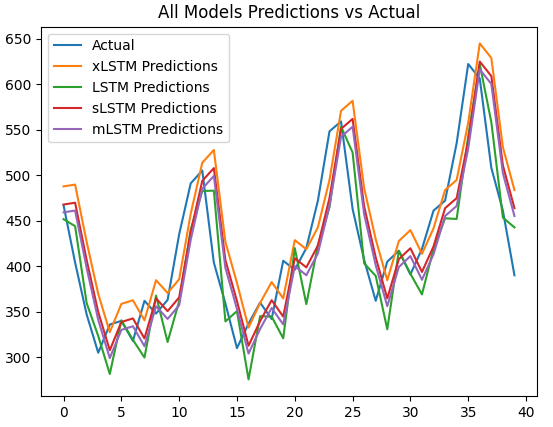
for model_name, preds in test_predictions.items():# Inverse transform the predictionspreds = scaler.inverse_transform(np.array(preds).reshape(-1, 1))plt.plot(preds, label=model_name + ' Predictions')plt.title('All Models Predictions vs Actual')
plt.legend()
plt.show()结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。