导读:,很多人会问数据血缘核心的是那种颗粒度实体是什么呢,从数据颗管理颗粒度划分来看,我们可以将数据血缘分为三种实体,即数据库血缘,数据表血缘,字段血缘,如图1所示。
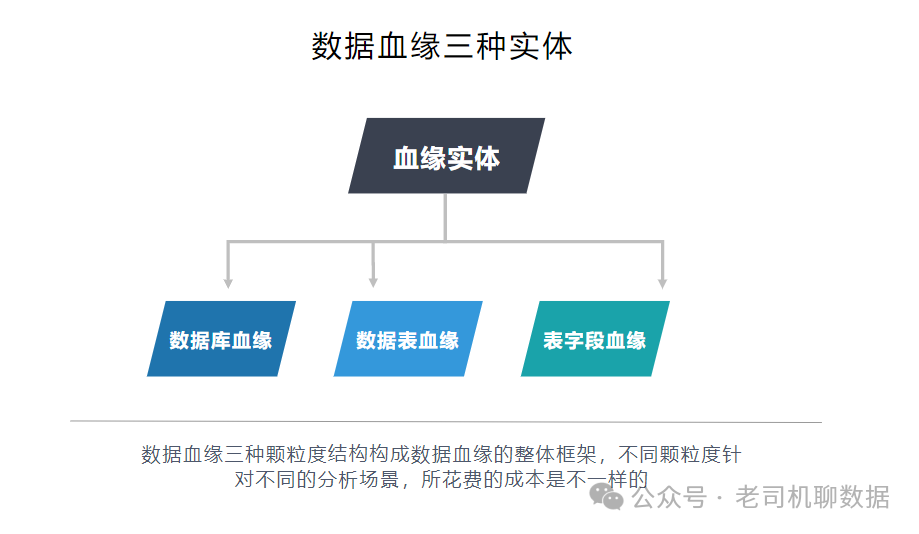
库级别的血缘、表级别的血缘该、字段级别血缘构成关系如表1所示。
表1三种级别血缘构成关系
| 类型 | 库级别血缘 | 表级别血缘 | 字段级别血缘 |
| 组成 | 源数据库 | 源表 | 源列(字段) |
| 目标数据库 | 目标表 | 目标列 | |
| 库地址 | |||
| SQL语句(模型中称之为PROCESS) | SQL语句(模型中称之为PROCESS) | SQL语句(模型中称之为PROCESS) | |
| 它们之间的关系 | 它们之间的关系 | 它们之间的关系 |
数据血缘关系组可能包含了这些内容:table表,view视图,resultset结果集,relation关系,arget element源,source element目标,process 处理过程(SQL statement),column列字段,variable变量:scalar、cursor、record,procedure存储过程:argument参数,path路径,error错误等内容。
一、数据库血缘
1)数据库定义:数据库顾名思义就是存放数据的仓库,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。它的存储空间很大,大大小小可以存放百万条、千万条、上亿条数据,但数据库的存储并不是随意将数据进行存放,它必须符合一定的规则,否则查询的效率会很低。常用的数据库有MySQL、Oracle、SqlServer、SQLite、INFORMIX、Redis、MongoDB、HBase、Neo4J、CouchDB,SAP推出的HANA数据库等。
2)数据库级别血缘:数据存放在不同的位置,数据库也循序渐进,先后经历了层次数据库、网状数据库和关系型数据库等各个阶段的发展,数据库技术即存储在各个方面得到快速发展。在某一个项目中我们基础会遇到数据库的迁移。如某个灾备环境,为了防止数据的丢失,基础使用整个数据库的迁移,那如何对应到这些数据库,这就是我们所属的灾备对应。在我们信息化系统实现前,为了模拟数据真实性,我们设置不同的环境,通过一些仿真的数据来测试我们开发的一些应用对于数据的使用是否能够支撑。如下图三个对应数据库中的从左往右,分别是Oracle,DB2,MySQL通过数据抽取或API的方式将数据同步到不同的库,形成数据库之间的血缘关系。如图2所示。
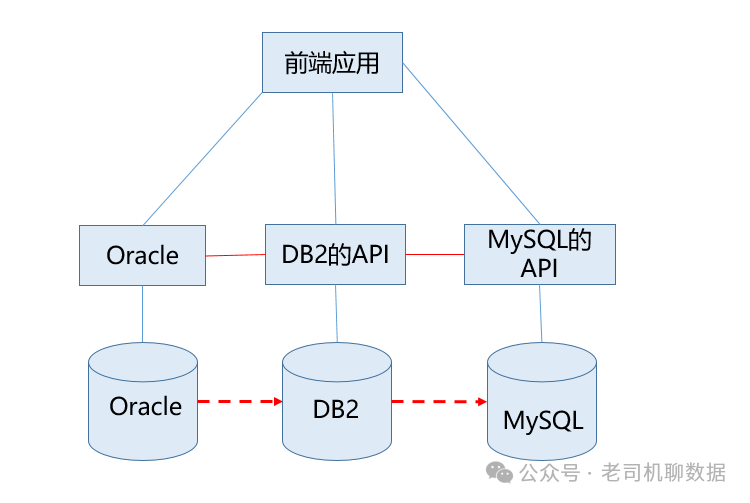
图2数据库之间的血缘关系
二、数据表血缘
1)数据表定义:表定义为列的集合。与电子表相似,数据在表中式按行和列的格式组织排列的。表中的每一列都设计为存储某种类型的信息(例如日期、名称、美元金额或数字)。表上有几种控制(约束、规则、默认值和自定义用户数据类型)用于确保数据的有效性。在关系数据库中,数据库表是一系列二维数组的集合,用来代表和储存数据对象之间的关系。它由纵向的列和横向的行组成;
例如一个有关客户信息的名为Custom的表中,每个列包含的是所有客户的某个特定类型的信息,比如“姓氏”,而每行则包含了某个特定作者的所有信息:姓、名、住址等等。
对于特定的数据库表,列的数目一般事先固定,各列之间可以由列名来识别。而行的数目可以随时、动态变化,每行通常都可以根据某个(或某几个)列中的数据来识别,称为候选键。
表的架构(即结构)可以用列和约束表示。使用DataColumn对象以及 ForeignKeyConstraint 和UniqueConstraint 对象定义DataTable的架构。表中的列可以映射到数据源中的列、包含从表达式计算所得的值、自动递增它们的值,或包含主键值。按名称引用表中的列、关系和约束是区分大小写的。因此,一个表中可以存在两个或两个以上名称相同(但大小写不同)的列、关系或约束。例如,您可以有Col1和col1。
2)数据表级别血缘:数据表血缘是常用的血缘关系,在项目实施过程中,比如在不同的数据表之间的关联,特别在一体化的整体系统建设之下,很多平台为了保证数据拉通统一,都在一个数据库下做数据协作,源表到不同的子表就需要知道其来源。在数据处理过程中,需要知道目标表的字段是来源于哪张源始表。对于简单的SQL来说我们很容易可以知道目标表的来源,但是复杂的SQL,想得到原始表不就那么容易,所以需要⼀个方法来便捷的导到目标表和来源表,一般会使用标识符来直接识别。
我们来看这样的一个数据迁移案例:某银行企业以银行的核心系统从旧系统切换至新核心系统中,并对数据做验证处理。在数据迁移过程中我们建立了对应的表,分别为异构系统源表、数据源抽取表,数据中间表,数据目标表。异构系统源即老系统,表中的数据是初始数据的来源;数据源表用于抽取老系统的源数据,该表需要保证数据完整的抽取到源表中;数据中间表作为数据源表流转至正式表的过渡表,用于存储按照新规则和要求处理过的有效数据;数据目标表用于中间表处理成为合格数据好之后,最终转移到目标系统。(如图3所示)
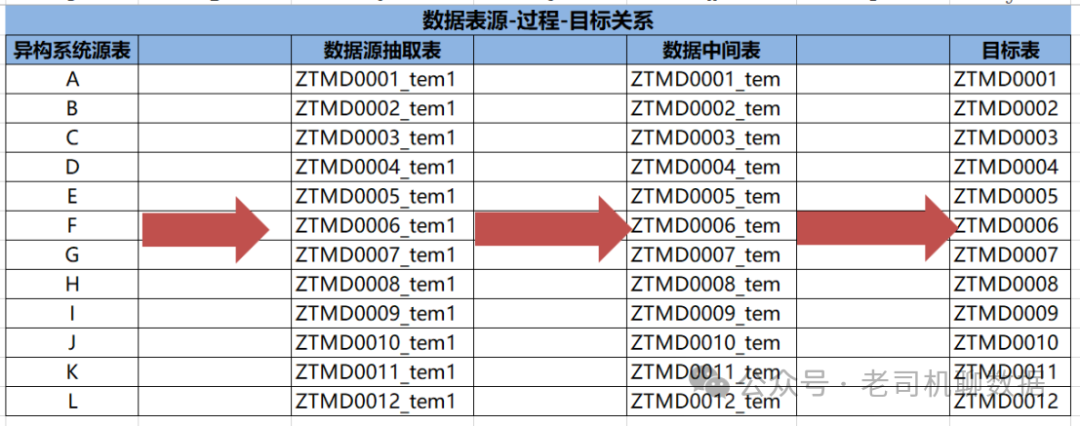
图3数据表源-过程-目标关系
数据表级别血缘关系需要遵循的规则:
1)确保最终目标数据准确性:根据迁移规则,核对源表中间表、中间表目标表的数据准确性,直接迁移或映射的字段对比字段值,有加工规则的按规则加工后核对。对于源表、目标表字段类型不一致的,关注类型转换是否正确。对于源表、目标表长度不一致的,关注是否出现截取造成数据失真。
2)数据传过程中的数据准确性:嵌入前后的元数据和目标业务数据之间的一致性,比如各表之间的数据差异性,那些数据是转换过来的,哪些数据是直抽取的,都许哟啊明确清楚,包括存款、内部资金、现金、重空等不同储种、币种、产品的余额、积数移入前后是否具备一致。
3)确保数据合法合规性:检核迁移数据的合法性,对迁入目标表的迁移数据进行检核,保证迁移数据在新系统的表中的合法性。这里包含了符合国家法律规定的数据,也包含符合公司审计管理的制度、章程、规范的数据。做好数据各表之间的血缘能够保证在生产切换时,降低业务系统切换风险,是在数字化过程中整个迁移方案中最基础的环节,利用好数据血缘表级别的方法,能够快速定位迁移过程中遇到的各表数据问题,为系统成功上线保驾护航。
三、字段级别血缘
1)字段定义:数据表中的字段又称之为列,我们把表中的每一行叫做一个“记录”,每一个记录包含这行中的所有信息,就像在人员信息数据库中某个人全部的属性(如图4所示),记录在数据库中并没有专门的记录名,常常用它所在的行数表示这是第几个记录。字段是比记录更小的单位,字段集合组成记录,每个字段描述文献的某一特征,即数据项,并有唯一的能让自己算识别的表示符号,称之为key值。对于字段的定义在数据库表中常见的字段类型有二进制数据类型、字符数据类型、数字数据类型等如下所示:
-
二进制数据类型 :Binary、Varbinary、Image;
-
字符数据类型:Char,Varchar和 Text;
-
Unicode数据类型:包括Nchar,Nvarchar和Ntext;
-
日期和时间数据类型:包括Datetime,Smalldatetime,Date, TimeStamp;
-
数字数据类型:数字数据类型包括正数和负数、小数和整数;
-
货币数据类型:表示正的或者负的货币数量;
-
特殊数据类型:特殊的数据类型有3种,即Timestamp、Bit 和 Uniqueidentifier。
在数据库表中,我们也将表的“列”称为“字段” ,每个字段包含某一专题特定的信息。就像“通讯录”数据库中,“姓名”、“联系电话”这些都是表中所有行共有的属性,所以把这些列称为“姓名”字段和“联系电话”字段。其中id,name,email就是字段。
图4数据库关系图
2)字段级别血缘:数据血缘中字段是最重要和核心的血缘关系,也是企业数据分析的重点:字段数据血缘分析在应用中是最常见的。如某字段的来源,来源客户管理系统,该客户数据就会同步到不同的下游系统,可能序列是A 向下游系统传输是出现A1、A2、A3、......A n,所有数据的来源都是A ,这样寻找的血缘关系我们称为数据字段血缘关系。
数据血缘字段要求规范
1)单字段检核注意事项。检查常用数据字段,固定字段的取值范围和格式,例如:
日期合法性检核:日期格式合法。如日期的格式几种情况要统一。
缺省字段的检查:如表的必填字段不允许为空。
标准参数的检核:如币种、账户状态、客户类型、凭证种类等。
值域标准检查:字段中的标准值域,元数据的检查。
2)多字段检核注意事项。检查表中多个字段间关联和约束关系,例如:
-
表字段中冻结止付金额有值:则检查冻结止付状态是否生效。
-
销户日期有数据:则检查销户日期大于等于开户日期,状态为销户。
-
活期利息:则检查利息=积数*利率。
-
建筑面积:检查建筑面积=地上建筑面积+地下建筑面积。
3)多表间数据关联与约束性检核。例如:
-
检查机构号是否存在机构信息表中;
-
检查柜员是否存在机构柜员表中;
-
凭证种类是否存在凭证种类登记薄中;
-
账户冻结是否存在冻结解冻登记薄中;
-
账户止付是否存在止付解付登记薄中;
-
产品码是否存在产品信息表中。
总结:数据字段级别的血缘是数据血缘分析中最核心的部分,而字段级别的管理同样是数据资产管理必不可少的一部分,如果字段级血缘需要手工梳理,这是一件工作量极大的事情,并且对于一些非关键的字段,梳理的价值也不是很高,梳理起来会费时费力,只有将数据血缘字段实现工具自动化收集,才能解决以上问题,这样梳理的工作量才能极大降低,将有效提升企业数据资产管理的能力。
