在大语言模型(LLM)蓬勃发展的今天,推理模型的性能提升成为了AI领域的关键议题。今天为大家解读的论文,带来了名为Seed-Thinking-v1.5的推理模型,它在多个任务上表现惊艳,还创新性地解决了不少难题,快一起来深入了解!
论文标题:Seed-Thinking-v1.5: Advancing Superb Reasoning Models with Reinforcement Learning
来源:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5/blob/main/seed-thinking-v1.5.pdf
文章核心
研究背景
随着大规模强化学习在大语言模型中的应用,推理模型发展迅猛,OpenAI的o1系列、DeepSeek的R1等先进模型不断涌现,推动该领域朝着更高效、更强大的方向迈进。
研究问题
- 训练数据问题:推理模型依赖思维链(CoT)数据进行训练,但传统用于监督微调(SFT)的非CoT数据过多会降低模型探索能力,现有数据处理方式难以满足高质量训练需求。
- RL算法不稳定:强化学习训练推理模型时稳定性欠佳,容易崩溃,不同训练轮次分数差异大,这对模型优化产生了严重阻碍。
- RL基础设施复杂:基于大语言模型的强化学习系统基础设施复杂,需要具备良好的可扩展性、可重复性和计算效率,以应对复杂的异构工作负载。
主要贡献
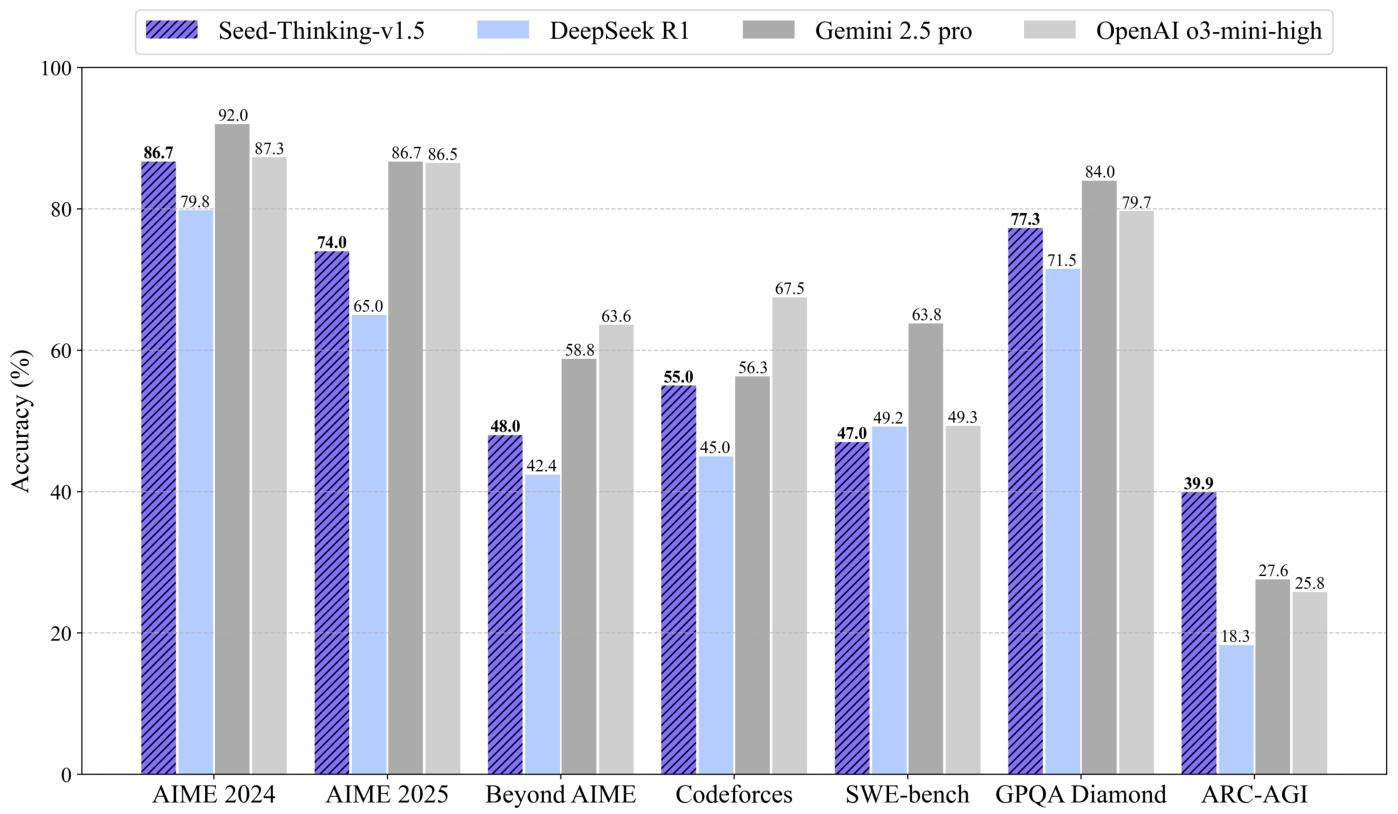
- 强大的推理模型:提出Seed-Thinking-v1.5模型,在数学推理、竞赛编程、科学等任务上成绩优异。例如在AIME 2024竞赛中取得86.7分,与OpenAI的o3-mini-high模型相当;在Codeforces竞赛编程任务中,pass@8指标达到55.0% ,优于DeepSeek R1;在GPQA科学任务上,准确率为77.3%,接近o3-mini-high水平 。在非推理任务上,相比DeepSeek R1,用户积极反馈率提升8%。
- 创新RL算法框架:首创VAPO和DAPO两个框架,分别针对演员 - 评论家(actor-critic)和策略梯度(policy-gradient)RL范式,有效解决了RL训练不稳定的问题,成为各自范式下的最优解。
- 构建新基准数据集:开发了BeyondAIME和Codeforces两个内部基准数据集,用于更精准地评估模型的泛化推理能力,并且这两个数据集都将公开,为后续研究提供支持。
- 优化RL基础设施:设计解耦的流式滚动输出架构(SRS),实现异步处理部分轨迹生成,迭代周期比同步框架快3倍;提出混合分布式训练框架,集成多种先进技术,显著提高了训练效率和可扩展性。
方法论精要
- 核心算法/框架:采用混合专家(Mixture-of-Experts,MoE)模型架构,借助统一的强化学习框架融合多领域数据进行训练。训练过程中,运用VAPO和DAPO框架提升训练稳定性。
- 关键参数设计原理:监督微调阶段,将每个训练实例截断为32,000个令牌(tokens),采用余弦退火学习率调度,峰值学习率设为(2×10{-5}) ,并逐渐衰减至(2×10{-6}) 。强化学习阶段,运用多种技术调整参数,如Value-Pretraining让价值模型与策略对齐;Decoupled-GAE通过采用不同的广义优势估计(GAE)参数,实现价值模型无偏更新,策略独立平衡偏差和方差。
- 创新性技术组合:通过模型合成、人工标注和拒绝采样的迭代流程,生成高质量长思维链(CoT)响应;在强化学习中,融合可验证数据、通用数据以及结合验证器与奖励模型分数的混合数据;利用Online Data Distribution Adaptation方法,将固定的提示分布转换为自适应分布,减少数据域间干扰。
- 实验验证方式:使用多个公开数据集和自研数据集进行实验。数学推理任务采用AIME 2024、AIME 2025和BeyondAIME数据集;竞赛编程任务使用Codeforces数据集;科学任务选用GPQA数据集等。对比基线选取当前先进的推理模型,如DeepSeek R1、OpenAI o3-mini、Grok 3 Beta、Gemini 2.5 pro等,通过对比评估模型性能。
实验洞察
- 性能优势:在AIME 2024竞赛中,Seed-Thinking-v1.5得分86.7,与OpenAI的o3-mini-high持平,超过DeepSeek R1(79.8);在Codeforces竞赛编程任务中,pass@8指标达到55.0% ,优于DeepSeek R1(45.0%),接近Gemini 2.5 Pro(56.3%);在GPQA任务中,准确率为77.3%,高于DeepSeek R1(71.5%),接近o3-mini-high水平。在非推理任务的人类评估中,相比DeepSeek R1,整体胜率提升8% 。
- 效率突破:通过SRS架构实现异步处理部分轨迹生成,迭代周期比同步框架快3倍。在训练系统中,采用组合TP/EP/CP与完全分片数据并行(FSDP)、KARP算法平衡序列长度、内存优化等多种并行策略和优化技术,有效提高了训练效率。
- 消融研究:对预训练模型进行消融实验发现,使用拒绝微调(RFT)初始化的预训练模型在训练中饱和更快,但最终性能低于未使用RFT训练的模型。如在AIME平均得分(avg@32)指标上,基线模型为58%,使用RFT的模型仅为54% ,证明RFT对模型性能提升没有积极作用。
本文由AI辅助完成。