课程9. 数据降维
- 维度灾难
- 奇异值分解
- SVD 变换
- SVD 的几何意义
- SVD分解应用示例
- 图像压缩
- 文本分析
- 推荐系统中的应用*
- 主成分分析
- PCA演示
- 使用 PCA 降低多元数据的维数
- PCA 说明单词的语义相似性
- t-SNE
维度灾难
机器学习和数据科学中的关键问题之一是数据高维性问题。我们已经遇到过这样的情况,描述样本对象的原始向量的维度可能达到数万,从长远来看,甚至达到数十万甚至数百万个坐标。我正在讨论使用 TF-IDF 方法进行文本向量化的一个例子(参见课程4)。
高数据维度会带来很多负面影响。有时这些效应的组合被称为“维度诅咒”,这个术语归功于理查德·贝尔曼。让我们讨论其中的一些,特别是依靠克里斯托弗·毕晓普在他的书“模式识别和机器学习”中给出的例子。
假设我们想要构建一些分类算法,将特征描述空间划分为一些规则单元。 规则单元是指将边与坐标轴平行的立方体推广到任意维度的空间。也就是说,在一维情况下,规则单元格将是一个线段,在二维情况下是一个正方形,在三维情况下是一个立方体,等等。每个单元格存储一组特定的数据,由一组落入该单元格的训练数据集点表示,并且每个单元格中的类别选择是通过对落入该单元格的所有对象进行投票来完成的。很容易看出,所描述的算法是决策树的变体。
还可以注意到,随着空间维数的增长,这种算法的构建复杂性及其使用将呈指数增长*(见图)。
- 算法复杂度是指计算机为实现该算法必须执行的基本算术运算 (⋅、/、+、-) 的数量
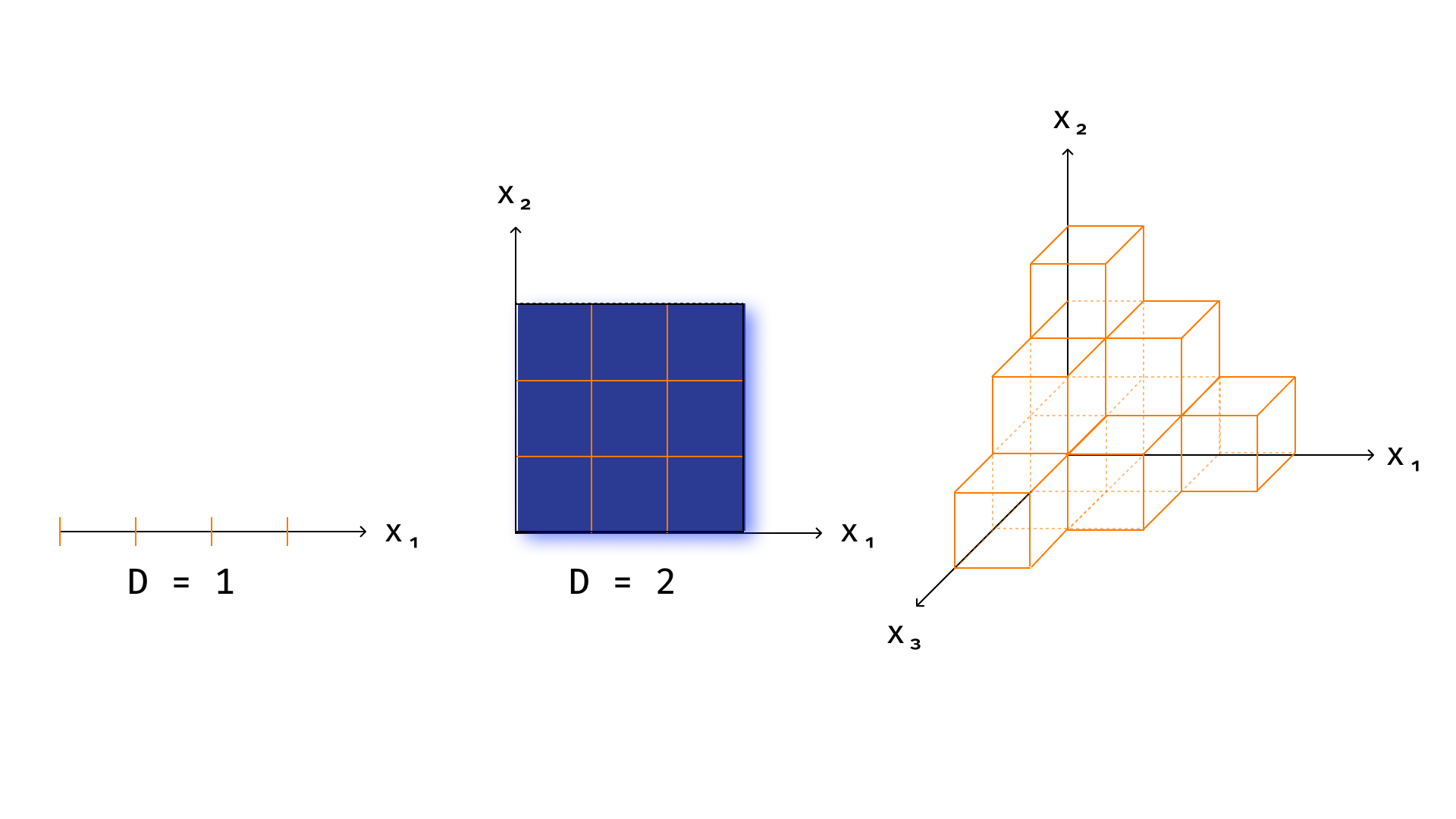
任何基于暴力破解 方法(brootforce,这就是通常所说的基于枚举并计算整个样本的一些统计数据的算法)的算法的复杂性也将呈指数级增长。我们在生活中并不总是使用这些算法,但是,首先,它们仍然经常遇到,其次,其他算法的复杂性增长率与 brootforce 复杂性的增长率成正比。
除了这个问题之外,还会出现以下问题:
-
当样本大小超过其中的对象数量时,算法不可避免地会出现过度训练。即使维数低于样本功率,过多的坐标也会导致过度拟合。
-
在许多算法中,我们借助于物体之间的距离的概念。额外的坐标会影响距离,但当它们不携带有用信息时,它们就代表了干扰物体之间测量距离的相关性的噪声。
因此,我们需要降低物体特征描述的维数。
也就是说,我们的任务是开发一个函数 F F F,它能够将维度 N × M N \times M N×M 的矩阵 X X X 转换为维度 N × K N \times K N×K 的矩阵 X ^ \hat{X} X^, M > K M>K M>K,并且不会造成显著的信息丢失。
例如,对于转换来说,信息损失不显著的要求可以表达如下:
F : R N × M → R N × K F: R^{N \times M} \rightarrow R^{N \times K} F:RN×M→RN×K
必定有一个逆变换:
F − 1 : R N × K → R N × M F^{-1}: R^{N \times K} \rightarrow R^{N \times M} F−1:RN×K→RN×M 使得 F − 1 ( F ( X ) ) ≈ X F^{-1}(F(X)) ≈ X F−1(F(X))≈X
今天我们将研究构建此类转换的流行方法。
奇异值分解
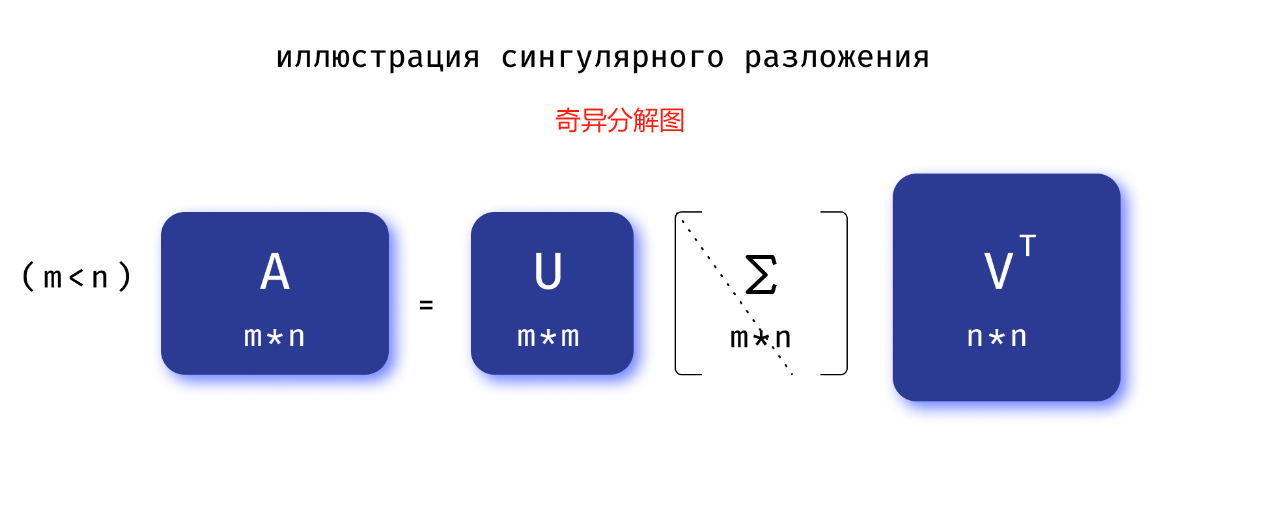
奇异值分解(简称 SVD)是将矩形矩阵表示为三个特殊类型矩阵的乘积
A = U Σ V T A = U ΣV^T A=UΣVT
矩阵 A A A 可以表示为以下矩阵的乘积:
- U U U ( U U T = I UU^{T}=I UUT=I,其中 I I I 是单位矩阵)) 是一个酉矩阵。
- V V V ( V V T = I VV^{T}=I VVT=I) 是一个酉矩阵。
- Σ \Sigma Σ 是一个矩形对角矩阵,也就是说,如果 i ≠ j i \neq j i=j,则 Σ i j = 0 \Sigma _{{ij}}=0 Σij=0。
矩阵 Σ \Sigma Σ 对角线上的元素称为 奇异值,用 σ i \sigma_i σi 表示。 奇异值是矩阵 A T A A^TA ATA的特征值的根,它们在降维问题中起着重要作用。
酉矩阵(简化定义,更多详情请参阅链接)是一个矩阵,其与转置矩阵相乘可得出单位矩阵。
让我们看看矩形矩阵 A A A 的 SVD 分解是什么样的。
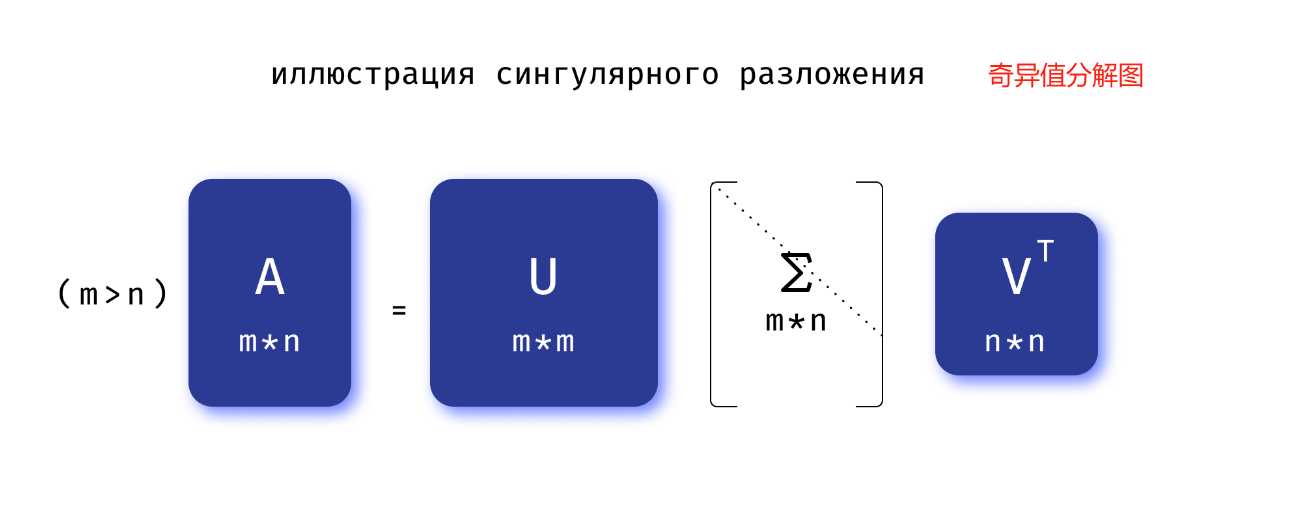
SVD分解的主要应用:
- 噪声过滤
- 识别数据中的线性相关性
- 降维
矩阵奇异值分解的显著性质是它对任何矩阵都存在。然而,对于大型矩阵,使用近似矩阵分解,因为 SVD 分解相当慢。
接下来我们将只考虑 SVD 分解。
如果您想了解有关矩阵分解方法的更多信息并更深入地研究计算线性代数,您可以查看 Ivan Oseledets 和 Alexander Katrutsa 在教学平台上发布的课程材料 “数据分析数学”。
SVD 变换
奇异值分解允许人们通过仅从相应矩阵中取出前 k k k 列来从原始矩阵中获得近似矩阵。如果矩阵 Σ \Sigma Σ 的元素按非增序排列,则近似矩阵 A k A_{k} Ak 的表达式如下所示:
A k = U k Σ k V k T A_{k}=U_{k} \Sigma_{k} V_{k}^{T} Ak=UkΣkVkT
其中矩阵 U k U_k Uk、 Σ k \Sigma_{k} Σk 和 V k V_{k} Vk 是通过截断矩阵 A 奇异值分解中的相应矩阵到前 k k k 列得到的。
事实证明,这样的转换可以降低问题的维数,同时丢失最少的信息。通过丢弃矩阵 U U U 和 V V V 中与小奇异值相对应的元素,我们不仅不会丢失有意义的信息,甚至还可以消除数据中的噪声。
SVD 的几何意义
矩阵的 SVD 分解也有几何解释。如果我们想象矩阵 A A A 被分解为某个线性算子,这种解释就是有意义的。从解析几何或线性代数的基础课程中可知,坐标的线性变换可以用沿某些轴的旋转和延伸的组合来代替。在 SVD 分解的情况下,算子 U U U 和 V T V^T VT 表示旋转算子,而算子 Σ Σ Σ 及其对应的对角矩阵当然负责沿与矩阵 A A T AA^T AAT 的特征向量方向重合的轴进行拉伸。拉伸系数又与算子 A A A矩阵的奇异值相重合。
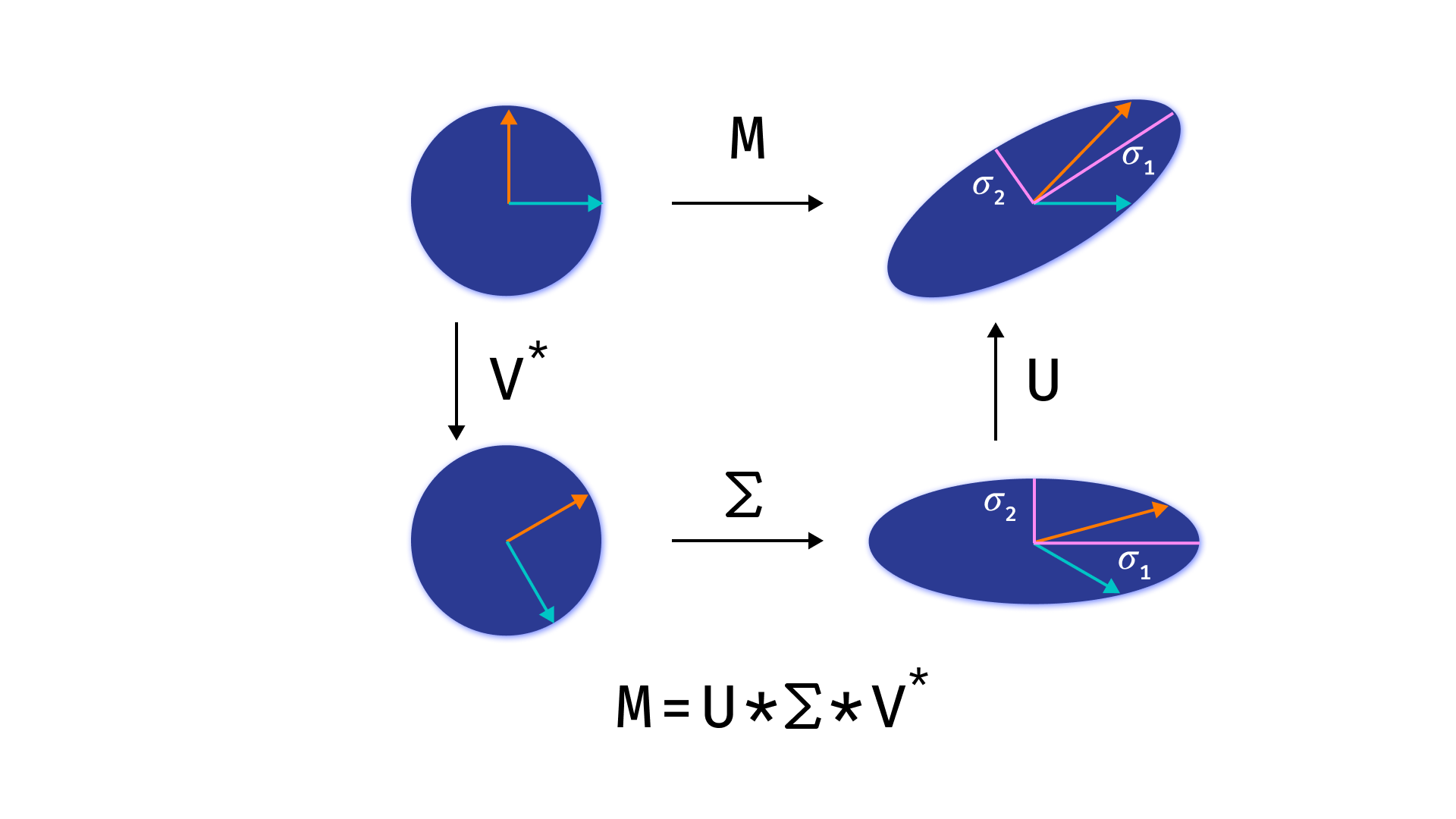
注意:
与非信息坐标的小奇异值的对应这一事实可能并不完全明显。可以从几何角度来看待这个问题:正如我们所发现的,SVD 分解是矩阵 A A T AA^T AAT 的特征向量分解,其系数等于奇异值。在这种情况下较小的奇异值大大低估了多维空间中向量相对于相应轴的偏差,这意味着可以丢弃这个轴。
另一方面,我们可以从数值的角度来解决这个问题:关键在于,将矩阵 Σ Σ Σ 的对角线上的 σ i σ_i σi 足够小的值归零,对重建矩阵 A ∗ A^* A∗ 和原始 A A A 之间的差异将产生很小的影响。如果我们将重建矩阵与原矩阵 ∣ ∣ A ∗ − A ∣ ∣ ||A^* - A|| ∣∣A∗−A∣∣的偏差范数作为信息损失的衡量标准,那么我们设置为零的 σ i σ_i σi值越小,我们实际损失的信息就越少。
关于小奇异值和信息损失之间的联系的更多可以查看网络。
SVD分解应用示例
图像压缩
SVD 分解最流行的应用之一是数据压缩。正如我们之前提到的,SVD 变换的设计方式是,通过丢弃与最小奇异值相关的分量,我们几乎不会丢失任何重要的信息,而且通常我们可能只会丢失对我们没有特别价值的噪声。因此,我们可以压缩各种对象,而不会严重降低其表示质量。这种方法最具代表性的例子之一就是图像压缩。
当然,图像本身并不是数学对象。图像的数字化可以将其表示为一组像素。这样的集合一般表示几个矩阵的集合(比如流行的RGB(红,绿,蓝)编码就存储了3个这样的矩阵,每个矩阵对应自己的颜色)。为了简单起见,我们将考虑只有一个矩阵的情况。当我们处理的图像是黑白的时候就会发生这种情况。那么我们需要存储其强度的唯一颜色就是灰色。也就是说,我们可以将黑白图像表示为灰度强度矩阵 A A A,然后我们可以对其应用 SVD 变换。
"""
使我们更轻松地使用 google-colab 的技术特性
"""
from IPython.display import display
from google.colab import output"""
先修模块
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt%matplotlib inline
# 从维基百科下载玫瑰的图片
! wget "https://upload.wikimedia.org/wikipedia/commons/d/db/Rosa_Peer_Gynt_1.jpg"
output.clear()
由于图像包含三个通道:红色(R)、绿色(G)、蓝色(B),我们将其转换为黑白图像,得到一个矩阵。
为此,我们将使用著名库 Python 图像库 (PIL) 的 .convert() 函数,该函数专为处理 Python 中的图形数据而设计。
from PIL import Imageget_ipython().__class__.__name__ = "ZMQInteractiveShell"filename = "Rosa_Peer_Gynt_1.jpg"
img = Image.open(filename).convert("L")
print(img.size)
输出:(1600, 1503)
scale = 0.3
display(img.resize((int(img.width * scale), int(img.height * scale))))
输出:

img_array = np.asarray(img)
img_array.shape
输出:(1503, 1600)
所以其大小为:
1503*1600
输出:2404800
plt.rcParams["font.size"] = 12
fg_color = "black"
bg_color = "white"fig = plt.figure(figsize=(10, 10))
fig.set_facecolor(bg_color)
im = plt.imshow(img_array, cmap="gray", vmin=0, vmax=255)
fig.suptitle("Rosa Peer Gynt", color=fg_color)
im.axes.tick_params(color=fg_color, labelcolor=fg_color)
输出:

因此,我们已经弄清楚了如何将图像表示为数组。目前图像存储在img_array变量中。现在是时候了解如何进行 SVD 变换了。
U, D, V = np.linalg.svd(img_array)
U.shape[0]*U.shape[1] + D.shape[0] + V.shape[0]*V.shape[1]
输出:4820512
def svd_transformation(A, n_comps):# 可以使用 np.linalg.svd() 模块函数进行 SVD 分解U, D, V = np.linalg.svd(A)# 根据 svd 变换的定义,我们将截断相应的矩阵U_cuted = U[:, :n_comps]D_cuted = np.diag(D[:n_comps])V_cuted = V[:n_comps, :]print(f'N comp: {n_comps}, Total number of parameters: {U_cuted.shape[0]*U_cuted.shape[1] + D_cuted.shape[0] + V_cuted.shape[0]*V_cuted.shape[1]}')# 然后我们执行它们的矩阵乘法transformed = U_cuted.dot(D_cuted).dot(V_cuted)return transformed
现在我们尝试通过将原始矩阵的维数压缩为 50、100、150 和 200 个分量来获取图像。
for n_comps in [50, 100, 150, 200]:# SVD 变换reconst_img = svd_transformation(img_array, n_comps)# 绘制结果print()fig = plt.figure(figsize=(5, 5))im = plt.imshow(reconst_img, cmap="gray", vmin=0, vmax=255)fig.suptitle(f"Rosa Peer Gynt, n_comps = {n_comps}", color=fg_color)fig.set_facecolor(bg_color)im.axes.tick_params(color=fg_color, labelcolor=fg_color)
输出:
N comp: 50, Total number of parameters: 155200
N comp: 100, Total number of parameters: 310400
N comp: 150, Total number of parameters: 465600
N comp: 200, Total number of parameters: 620800




img_array
输出:

很容易注意到一个明显的趋势:图像质量随着组件数量的增加而提高。然而,即使组件数量极低n_comp = 50,通过压缩原始图像获得的图像仍然相当易读,尽管不是很清楚。
文本分析
让我们也考虑一下文章文本分析的典型例子。让我们看一下 4 个不同主题的 4 篇文章。让大家知道每篇文章中用到了哪些词语。
我们有 4 个主题:
- 滑雪板
- 曲棍球
- 花样滑冰
- 游泳
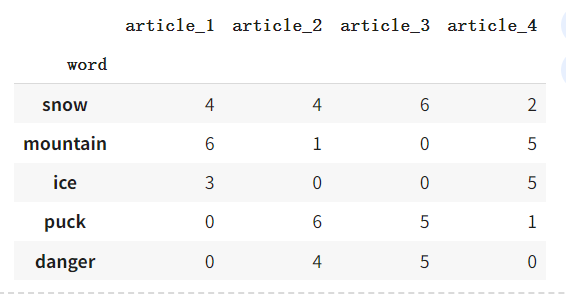
因此,在这些文章中发现了一组词:“雪”、“山”、“冰”、“冰球”、“危险”。
让我们制作一个表格,其中每一列对应一篇特定的文章,每一行对应一个单词。该表 a i j a_{ij} aij 中索引为 i,j 的元素表示单词 i i i 在文章 j j j 中出现的次数。这是描述文本语料库的相当标准的方式之一。
*注意:我们在这里不使用来自真实文章的例子,因为结果不会那么具有代表性,但对我们来说,展示方法的思想很重要。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 文章 1 - 关于单板滑雪
# 文章 2 - 关于曲棍球
# 文章 3 - 关于花样滑冰
# 文章 4 - 关于游泳c_names = ["article_1", "article_2", "article_3", "article_4"]
words = ["snow", "mountain", "ice", "puck", "danger"]
post_words = pd.DataFrame([[4, 4, 6, 2], [6, 1, 0, 5], [3, 0, 0, 5], [0, 6, 5, 1], [0, 4, 5, 0]],index=words,columns=c_names,
)
post_words.index.names = ["word"]
post_words
输出:
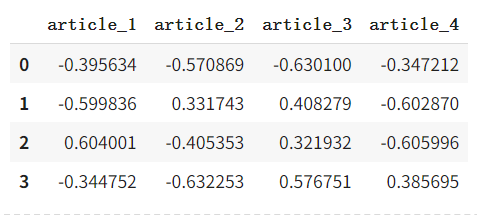
奇异值分解矩阵 U U U 和 V V V 在某种意义上可以看作是源文本的向量表示。例如,当前矩阵 V V V 相当清晰地给出了第 3 篇文章和第 4 篇文章的相似性。这样的向量有时被称为 嵌入。
U, D, V = np.linalg.svd(post_words)
V_df = pd.DataFrame(V, columns=c_names)
V_df
输出:
在分析分解组件的信息内容时(组件本质上是指变换后的特征描述的坐标),我们可以依赖与它们对应的奇异值。奇异值 σ i σ_i σi越大,该成分的信息量越大。通常使用以下标准:
让我们考虑关系 E m = ∑ i = 1 m σ i ∑ j = 1 N σ j E_m = \frac{∑\limits_{i=1}^mσ_i}{∑\limits_{j=1}^Nσ_j} Em=j=1∑Nσji=1∑mσi
其中N是特征空间的原始维数。
如果 E m E_m Em 足够大,我们可以丢弃所有后续组件,因为即使是 m m m 个部分也足以详尽地描述数据。
请注意,在我们的例子中,前两个组件承载主要信息,其余组件承载可以丢弃的次要信息。
*注意:有时会考虑另一个值: E m = ∑ i = m N σ i ∑ j = 1 N σ j E_m = \frac{∑\limits_{i=m}^Nσ_i}{∑\limits_{j=1}^Nσ_j} Em=j=1∑Nσji=m∑Nσi。在这种情况下, E m E_m Em 的急剧下降以及 m m m 的增加将作为后续组件无信息性的信号。然后就可以丢弃它们了。该标准通常被称为陡坡标准。
D
E1 = np.sum(D[:1]) / np.sum(D)
E1
E2 = np.sum(D[:2]) / np.sum(D)
E2
输出:
array([13.3221948 , 9.2609512 , 2.41918664, 1.37892883])
np.float64(0.5049870271086724)
np.float64(0.8560298007265911)
我们仅使用 SVD 分解中每个矩阵的前 2 2 2 列来找到近似矩阵 A A A。
n_approx = 2
A_approx = svd_transformation(post_words, n_approx) #np.matrix(U[:, :n_approx]) * np.diag(sigma[:n_approx]) * np.matrix(V[:n_approx, :])pd.DataFrame(A_approx, index=words, columns=c_names)
输出:
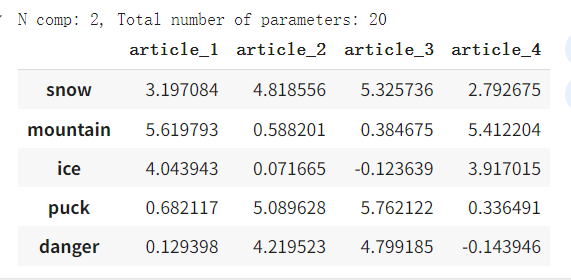
让我们估计相对于原始矩阵 A A A 的误差
(post_words - A_approx)/(post_words)
输出:
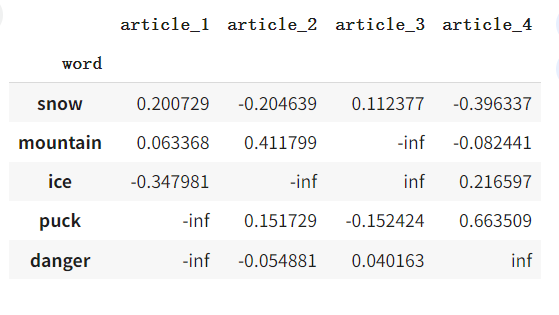
基于矩阵 V V V的值,甚至可以得出关于文本与主题的隶属关系的某些结论。
为了清楚起见,让我们把数字形象化,并看看线条
%matplotlib inline
import matplotlib.pyplot as pltplt.xticks(range(len(c_names)))
plt.yticks(range(len(words)))
plt.ylim([len(words) - 1.5, -0.5])
ax = plt.gca()
ax.set_xticklabels(c_names)
ax.xaxis.label.set_color("black")
ax.yaxis.label.set_color("black")
ax.set_yticklabels(range(1, len(words) + 1))
plt.title("$V$")
plt.imshow(V, cmap="autumn")
plt.colorbar();
输出:
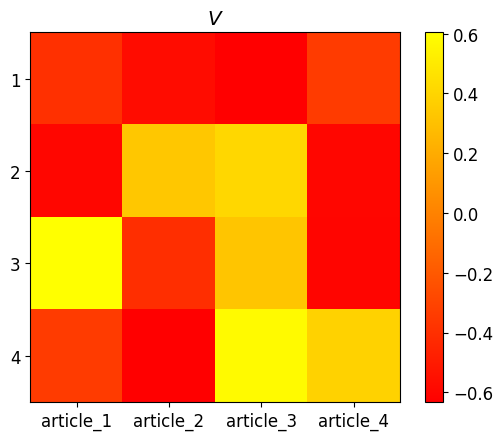
可以清楚地看到,不同单词出现的次数不同,主题也不同。
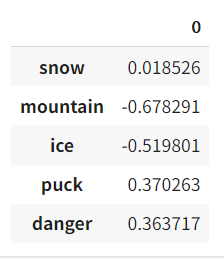
pd.DataFrame(U[:,1], index=words)
输出:
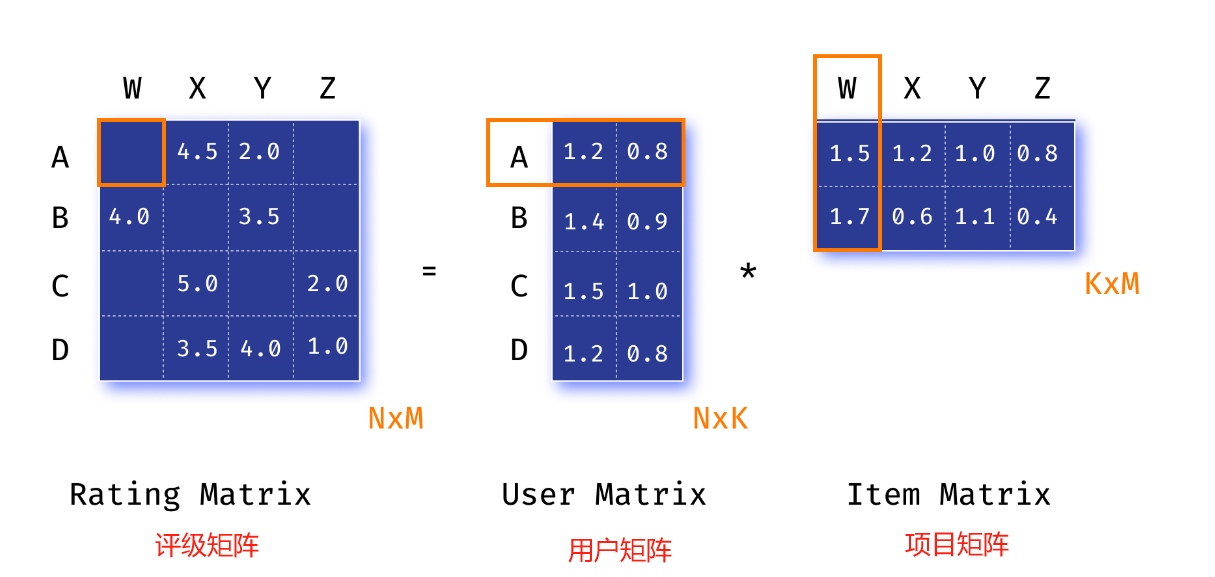
推荐系统中的应用*
矩阵分解在推荐系统中被广泛使用。当然,现在已经开发出更复杂的算法,其中许多是基于神经网络的。
然而,优秀的旧“经典”有时也会在实践中使用,例如 YouTube、Kinopoisk、Netflix 上的视频推荐算法。
用于评估推荐算法的最著名数据集之一是 MovieLens。
在后面的课程中,您将了解有关推荐系统的更多信息。
在这种情况下,我们将寻找一个近似矩阵 A ∗ A^* A∗,其形式为两个矩阵 U ′ U' U′ 和 V ′ V' V′ 的乘积:
A ∗ ∼ U ′ V ′ T A^* \sim U' V'^{T} A∗∼U′V′T
SVD分解的误差将按如下方式估计:
e i , j = A i , j − A i , j ∗ e_{i,j} = A_{i,j} - A^*_{i,j} ei,j=Ai,j−Ai,j∗
我们使用矩阵的已知值来最小化以下平方和。让我们在误差中添加额外的项,乘以 γ \gamma γ——这种方法称为正则化。当我们需要指定我们想要找到的解决方案的某些属性时使用它:
m i n ( ∑ i , j ( e i , j ) 2 + γ ( ∑ i , j ( u i , j ) 2 + ∑ i , j ( v i , j ) 2 ) ) min(\sum_{i,j} ({e_{i,j}})^2 + \gamma ( \sum_{i,j} ({u_{i,j}})^2 + \sum_{i,j} ({v_{i,j}})^2 )) min(i,j∑(ei,j)2+γ(i,j∑(ui,j)2+i,j∑(vi,j)2))
如果不进行正则化, u i , j u_{i,j} ui,j和 v i , j v_{i,j} vi,j的值可能会出现爆炸式增长。
为了找到矩阵 U ′ U' U′和 V ′ V' V′的值,使用了一种迭代算法——梯度下降法。
主成分分析
主成分分析(PCA)是机器学习中用于数据降维的主要方法之一。降维用于在替代特征空间中寻找最重要的特征。
主成分分析由卡尔·皮尔逊于1901年提出。卡尔·皮尔逊是研究数理统计最著名的科学家之一。他提出的定量测量两个或多个随机变量之间的统计关系的方法广为人知:皮尔逊相关系数,或简称为相关系数。
PCA 本质上是一种无监督算法,这意味着它不需要任何初步的数据标记。
PCA不仅用于数据降维,还用于数据可视化、噪声过滤、特征提取和新特征生成。
但在本讲座中我们将考虑降维的情况。
在PCA框架中,我们采用一个相当直观的假设,即对象特征描述空间中某个子空间的信息内容由数据投影到该子空间的方差来描述。
主成分方法找到数据在低维空间上的投影,最大限度地保留数据的方差。
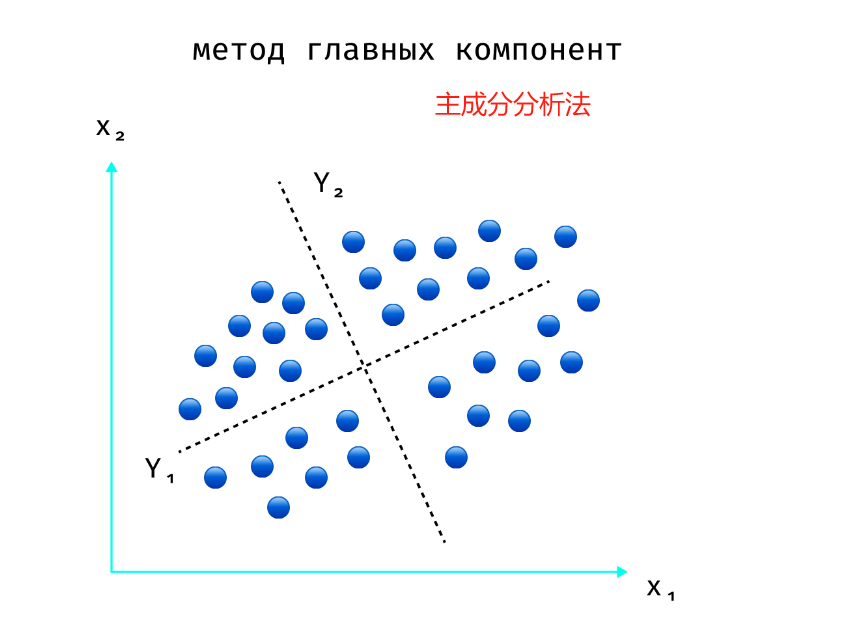
为了更好地理解PCA,我们设想以下情况:
令因子 X 1 X_1 X1 描述汽车的最大速度,因子 X 2 X_2 X2 描述其发动机的容积。某机构进行了一项研究,发现了以下两种模式:
-
没有人会制造发动机大但最高速度低的汽车,反之亦然。通常,发动机排量与最高速度相关。
-
先前的结论可以通过以下事实来解释:昂贵的汽车在两个因素上都具有更好的特性,而便宜的汽车在两个因素上都具有更差的特性。与该模式存在细微的偏差,但大多数偏差在统计上并不显著。
所描述的情况如上图所示。
现在想象一下,我们正在建立一个模型,根据这两个因素来预测汽车的价格。我们是否需要考虑这两个因素才能得出有关汽车价值的结论?
事实证明,我们只需一个标志就可以解决。例如,总和 X 1 X_1 X1 + X 2 X_2 X2 会告诉我们很多信息,因为对于昂贵的汽车来说它会很大,而对于便宜的汽车来说它会很小。但是特征 X 1 − X 2 X_1 - X_2 X1−X2 将完全没有信息量,因为对于昂贵的汽车和便宜的汽车来说,由于第一次观察,这个值会很低。
也就是说,我们从特征 X 1 X_1 X1 和 X 2 X_2 X2 转向特征 Y 1 = X 1 + X 2 Y_1 = X_1 + X_2 Y1=X1+X2 和 Y 2 = X 1 − X 2 Y_2 = X_1 - X_2 Y2=X1−X2,其中我们只对特征 X 1 X_1 X1 感兴趣。我们为什么对他感兴趣?因为我们的样本既包括廉价汽车(对于它来说 Y 1 Y_1 Y1 较小),也包括昂贵汽车(对于它来说 Y 1 Y_1 Y1 较大),所以沿着 Y 1 Y_1 Y1 轴的值会有很大分布。但 Y 2 Y_2 Y2 则不然,它对于两种类型的汽车以及任何中间类型的汽车来说都很小,并且几乎没有携带任何信息。从几何学上讲,这种变换意味着在原空间中旋转其坐标,大致如图所示。这正是 PCA 所做的——它找到一种变换,使我们能够根据沿新坐标轴的值的传播来估计每个新特征的信息内容。
PCA演示
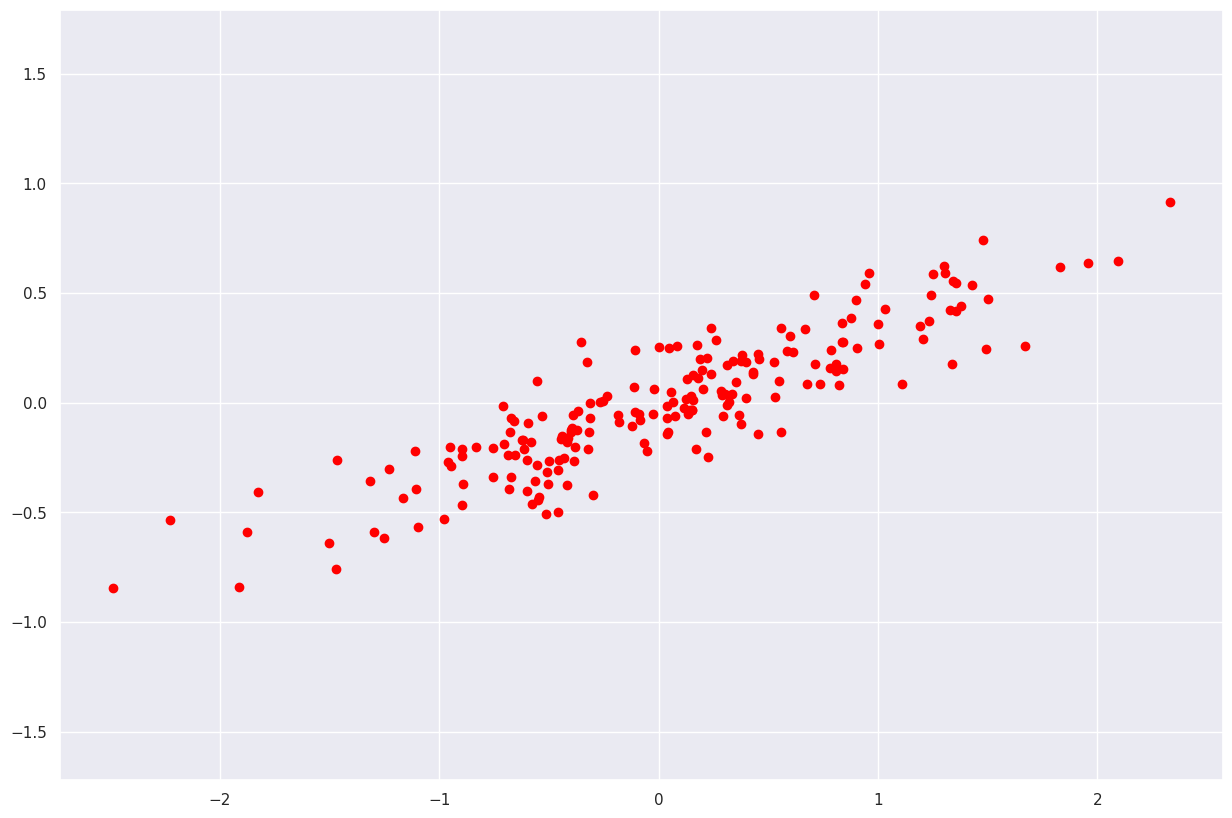
首先,让我们形成一个合成样本,以便在其上演示 PCA 的操作。
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme()rst = np.random.RandomState(1)
plt.figure(figsize=(15,10))
X = np.dot(rst.rand(2, 2), rst.randn(2, 200)).T
plt.scatter(X[:, 0], X[:, 1], color="red")
plt.axis('equal')
输出:
PCA 算法在 sklearn 库的 decomposition 模块中实现。
作为一个参数,PCA 期望n_components——我们想要保留的组件数量,即我们正在进入的空间的维数。
PCA 是一种数据转换算法,因此要使用它,您可以使用转换器的标准 sklearn 语法,即调用 .fit() 和 .transform() 函数。
from sklearn.decomposition import PCApca = PCA(n_components=2)
pca.fit(X)
输出:

让我们通过参考以下“PCA”属性来看看主成分是什么样的:
components- 与新坐标系对应的向量explained_variance- 对应于沿给定方向的样本方差的向量长度
print(pca.components_)
print(pca.explained_variance_)
输出:
[[ 0.94446029 0.32862557]
[-0.32862557 0.94446029]]
[0.7625315 0.0184779]
让我们想象一下这个结果
import seaborn as sns
import matplotlib.pyplot as pltdef draw_vector(v0, v1, ax=None):ax = ax or plt.gca()arrowprops=dict(arrowstyle='->',linewidth=2,shrinkA=0,shrinkB=0,color='black')ax.annotate('', v1, v0, arrowprops=arrowprops)plt.figure(figsize=(15,10))
plt.scatter(X[:, 0], X[:, 1], alpha=0.5, color="red")
for length, vector in zip(pca.explained_variance_, pca.components_):v = vector * 3 * np.sqrt(length)draw_vector(pca.mean_, pca.mean_ + v)
plt.axis('equal');
输出:
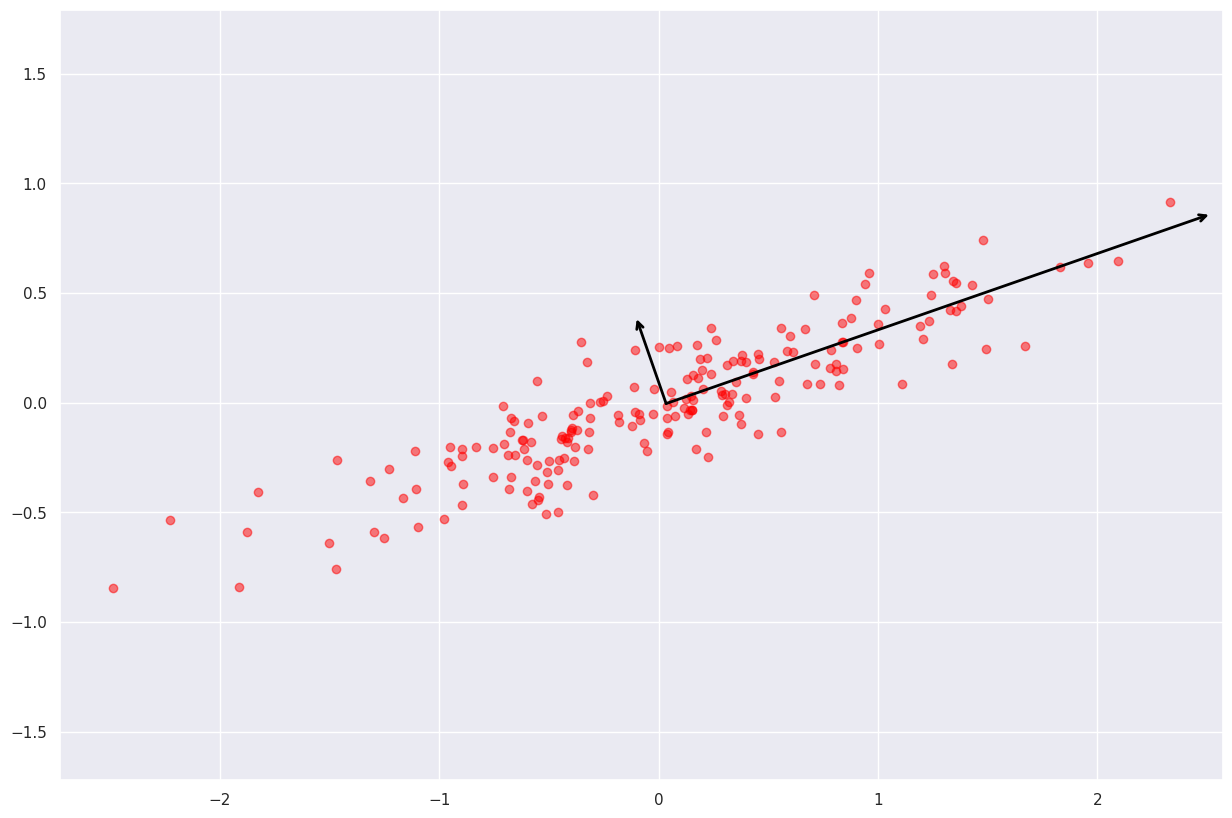
得到的向量表示数据中的主要“轴”,向量的长度表示该轴在描述数据分布方面的“重要性”。更准确地说,它是数据投影到该轴上的分散(散射)的度量。
每个数据点在主轴上的投影就是数据的“主成分”,因此称为主成分分析。
接下来,我们将看到如何使用 PCA 来降低数据维数的示例。
使用 PCA 降低多元数据的维数
如果我们大幅降低特征描述的维数(比如从几万维到十维),您是否认为分类质量会显著下降?
这个问题的答案是模棱两可的;在不同的任务、不同的算法、不同的数据集的情况下,一切都会有所不同。
然而,我们要确保在某些情况下,如此大幅度的降维不会导致算法的绝对失败。
作为示例,让我们以 sklearn 中已经熟悉的新闻文章数据集为例。
from sklearn import datasets
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import sklearn
import numpy as npnewsgroups = datasets.fetch_20newsgroups(subset='all',categories=['alt.atheism', 'sci.space'])
y = newsgroups.target
X_train, x_test, y_train, y_test = train_test_split(newsgroups.data, y, test_size=0.3)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train)
x_test = vectorizer.transform(x_test)
y = newsgroups.target
X_train.shape
输出:(1250, 24131)
我们可以看到,该数据集包含大约 30,000 个特征。我们将它们压缩为 10。
from sklearn.decomposition import PCA
import xgboost as xgb
from sklearn.metrics import accuracy_scoren_comp = 10
pca = PCA(n_components=n_comp)
X_tr = pca.fit_transform(X_train.toarray())
x_te = pca.transform(x_test.toarray())clf = xgb.XGBClassifier().fit(X_tr, y_train)
X_tr.shape
输出:(1250, 10)
clf.score(X_tr, y_train)
输出:1.0
acc = accuracy_score(clf.predict(x_te), y_test)
acc
输出:0.9701492537313433
如果在完整样本上训练分类器会发生什么?
clf_full = xgb.XGBClassifier().fit(X_train, y_train)
acc = accuracy_score(clf_full.predict(x_test), y_test)
acc
输出:0.9328358208955224
质量差异仅为6%。
这并不是说这种差异不明显,但考虑到空间维数减少了 3000 倍,这个结果也许令人印象深刻。
PCA 说明单词的语义相似性
我们已经遇到过一种文本向量化的方法,称为 tf-idf。这是一个好方法,但也有其缺点。首先,它们在于所得向量的高维性;其次,这些向量没有考虑到单词之间的语义联系。也就是说,我们将无法根据生成的向量来区分同义词和彼此不相关的词。为了解决第二个问题,我们采用基于语言假设的方法:
“通过词语的来龙去脉,你就能了解一个词语的含义”(c)J.R. Firth,1957
其背后的想法是,语义上彼此相关的词语经常出现在相同的上下文中,也就是说,它们出现在相同词语的“陪伴”中。
基于这个想法,我们提出了以下词向量化方法,或者用 NLP 术语来说,组成嵌入:
1)我们计算每对单词在同一个句子中出现的频率。我们得到一个共生矩阵
2)使用 PCA 将此矩阵转换为低维矩阵
texts = ['Mars has an atmosphere', "Saturn 's moon Titan has its own atmosphere", "Mars has two moons", "Saturn has many moons", "Io has cryo-vulcanoes"]
让我们编写一个函数来创建共生矩阵
import numpy as np
def make_cooccurrence_matrix(teexts):# 让我们定义一个词典和单词的成对共现频率vocabulary = set(texts[0].split())for t in texts[1:]:vocabulary = vocabulary.union(set(t.split()))vocabulary=list(vocabulary)N = len(vocabulary)# 让我们做一个共生矩阵cooccurrence = np.zeros((N,N))for i in range(N):for j in range(i, N):if i == j:continuefor t in texts:if vocabulary[i] in t.split() and vocabulary[j] in t.split():cooccurrence[i][j]+=1cooccurrence[j][i]+=1return cooccurrence, vocabulary
c, v = make_cooccurrence_matrix(texts)
让我们看一下字典和结果矩阵:
v
输出:

c
输出:

让我们用 n_components = 2 来定义 PCA,以便在二维平面上绘制结果
from sklearn.decomposition import PCA
p = PCA(n_components=2)
pca = p.fit_transform(c)
import seaborn as sns
import matplotlib.pyplot as pltplt.figure(figsize=(15,8))
ax = plt.gca()
for i,c in enumerate(pca):ax.annotate(text = v[i], xy = (c[0] + np.random.randn()/15, c[1]+ np.random.randn()/15))
plt.scatter(pca[:,0], pca[:,1])
输出:
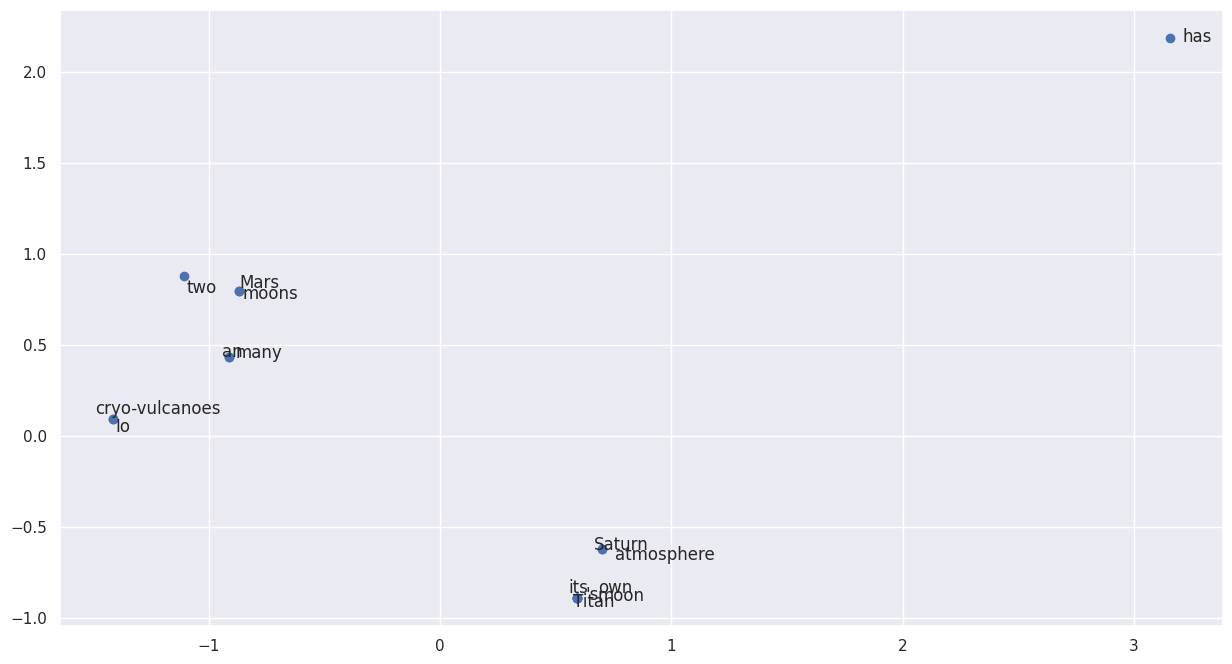
可以看出,很多原本出现在原文同一语境中的表达,经过转换之后,就变成了接近的点。
例如,“Io” и "Cryo-vulcanoes"这些词在坐标平面上几乎重合,“Mars”, “two” и “moons"也是如此,还有"Saturn”, “Titan”, “moon” и “atmosphere”。本质上,我们原来的句子被分解成某种集群。
t-SNE
该算法在保留大部分原始信息的同时,降低了多维数据的维数。这个想法是当投影到低维空间时尝试保留原始空间中点之间的成对距离。例如,这会保留集群结构,从而允许有效地使用 t-SNE,例如,用于可视化多维数据。原始多维空间中的每个点(点是数据中原始对象的特征描述)要么被平移到平面上的点,要么被平移到三维空间中的点。
降维时,数据中的聚类被保留,对象之间的距离没有被保留,但保留了以下属性:近的物体保持近,远的物体保持远。
t-SNE 算法由 Geoffrey Hinton 和 Laurens van der Maaten 于 2008 年提出(文章链接)。
让我们考虑一个在二维平面上可视化 MNIST 数据集中的手写数字图像的示例。
让我们使用方便的“sklearn”库中的 t-SNE 实现。实现该算法的“TSNE”类可以在“sklearn.manifold”模块中找到。
%matplotlib inlinefrom sklearn.datasets import load_digits
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.manifold import TSNE
mnist = load_digits()
pd.DataFrame(mnist.data).head()
输出:
fig, axes = plt.subplots(2, 10, figsize=(16, 6))
for i in range(20):axes[i//10, i %10].imshow(mnist.images[i], cmap='gray');axes[i//10, i %10].axis('off')axes[i//10, i %10].set_title(f"target: {mnist.target[i]}")plt.tight_layout()

原始图像看起来是这样的。我们的任务是将它们简化到二维空间,同时不丢失集群结构。
X = mnist.data
X.shape
输出:(1797, 64)
y = mnist.target
y
输出:array([0, 1, 2, …, 8, 9, 8])
让我们预先规范化数据。
standardized_data = StandardScaler().fit_transform(X)
print(standardized_data.shape)
输出:(1797, 64)
让我们用适当的参数定义 t-SNE 并可视化结果。
tsne = TSNE(random_state = 42, n_components=2, verbose=0, perplexity=40, n_iter=300).fit_transform(X)
plt.figure(figsize=(15,10))plt.scatter(tsne[:, 0], tsne[:, 1], s= 5, c=y, cmap='Spectral')
plt.gca().set_aspect('equal', 'datalim')
plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(10))
plt.title('Visualizing the MNIST dataset with t-SNE', fontsize=24);
输出:
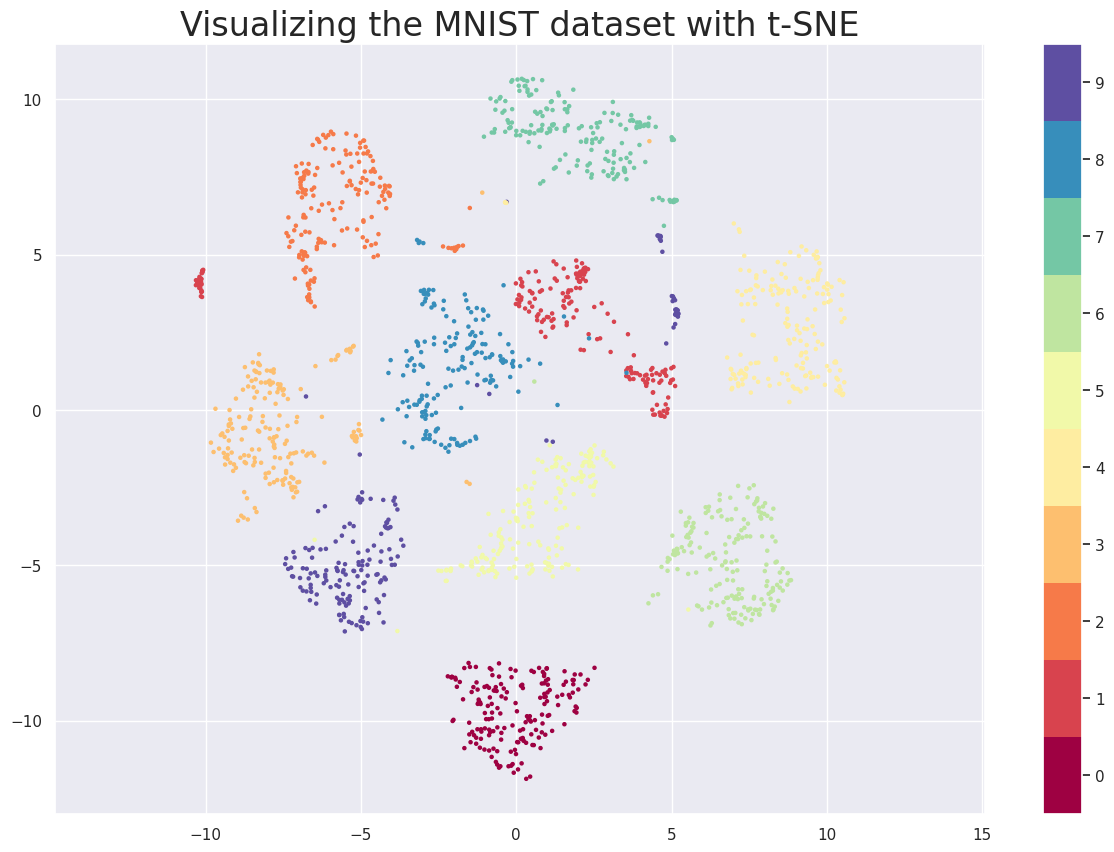
实际上,有很多不同的方法可以降低数据的维数。其中许多方法都是基于神经网络的使用。本讲座中提出的方法代表了解决降维问题的相当有效且简单的经典算法。
另一个复杂的问题是如何选择新特征空间的维度,以便在转换过程中不丢失太多信息。这个问题目前处于科学的前沿。