1 项目介绍
1.1 研究目的和意义
在电子商务日益繁荣的今天,精准预测商品销售数据成为商家提升运营效率、优化库存管理以及制定营销策略的关键。为此,开发了一个基于深度学习的商品销售数据预测系统,该系统利用Python编程语言与Django框架,实现了从数据收集、模型训练到预测结果展示的全流程自动化。
系统首先通过Django框架构建的Web界面,收集并预处理历史销售数据。预处理步骤包括数据清洗、标准化以及特征工程,旨在提升后续模型训练的效率和准确性。接着,利用Python的深度学习库(如ARIMA),系统构建并训练了适用于销售数据预测的深度学习模型。这些模型能够自动学习历史数据中的复杂模式,从而准确预测未来一段时间内的销售趋势。
完成模型训练后,系统会将预测结果以直观的图表或表格形式展示给用户。商家可以通过Web界面轻松查看预测的销售量、销售额等关键指标,并根据这些信息进行库存调整、促销策略制定等决策分析。此外,系统还提供了丰富的数据可视化功能,帮助商家更直观地理解销售数据的变化趋势和规律。
本系统具有多项优势。首先,深度学习模型的引入使得预测结果更加准确可靠;其次,Django框架的采用使得系统具有良好的可扩展性和用户友好性;最后,系统还支持多数据源接入,能够处理不同来源、不同格式的销售数据,满足商家多样化的需求。
基于深度学习的商品销售数据预测系统为商家提供了一个高效、准确且易于使用的销售预测工具。通过该系统,商家可以更加精准地把握市场变化,优化库存管理和营销策略,从而在激烈的市场竞争中脱颖而出。
1.2 系统技术栈
Python
MySQL
Django
LSTM
Scrapy
Echart
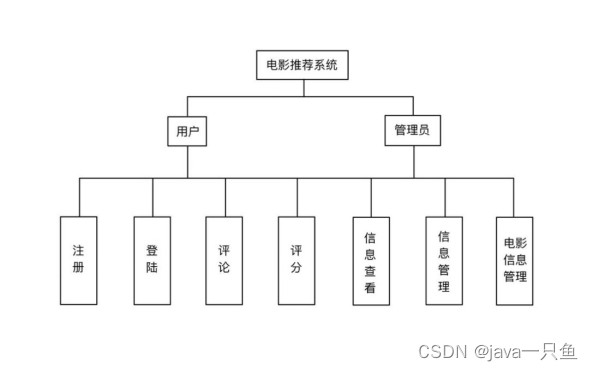
1.3 系统角色
管理员
用户
1.4 算法描述
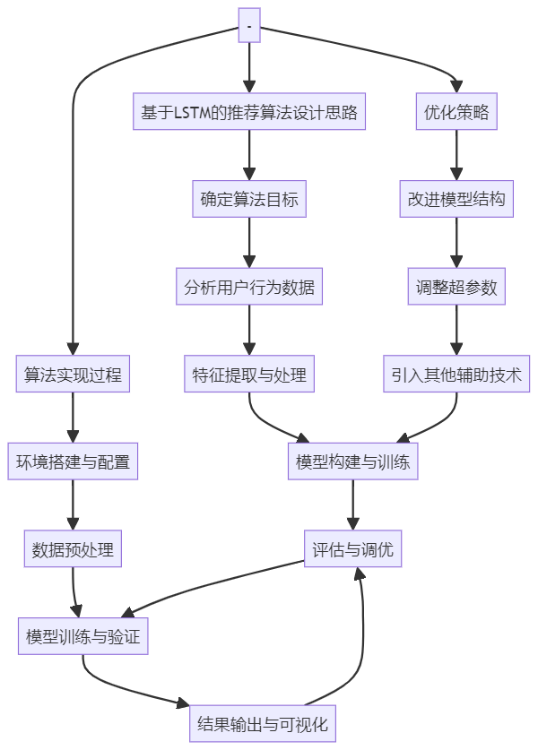
在构建基于深度学习的电影推荐系统时,推荐算法的设计与实现是至关重要的一环。LSTM(长短时记忆)算法作为深度学习领域的一种重要技术,因其出色的序列数据处理能力而被广泛应用于各种推荐场景中。本节将详细介绍基于LSTM的推荐算法设计思路、实现过程以及优化策略。
首先,需要明确LSTM算法在推荐系统中的作用。LSTM是一种特殊的循环神经网络(RNN),它能够有效地捕捉序列数据中的长期依赖关系。在电影推荐系统中,用户的观影历史可以视为一种时间序列数据,LSTM能够学习用户观影行为的时间序列特征,从而预测用户未来的观影偏好。
在设计基于LSTM的推荐算法时,首先需要准备相应的数据集。这包括用户观影历史数据、电影特征数据等。其中,用户观影历史数据是核心,它记录了用户在不同时间点的观影行为。通过预处理这些数据,可以将其转换为适合LSTM模型输入的格式。
接下来是LSTM模型的构建。在构建模型时,需要考虑多个因素,如模型的层数、隐藏单元的数量、激活函数的选择等。这些参数的设置将直接影响模型的性能和训练效率。通过多次实验和调整,可以找到一组合适的参数配置。
在模型构建完成后,需要进行模型的训练。训练过程中,采用反向传播算法来优化模型的参数。通过不断地迭代训练,模型可以逐渐学习到用户观影行为中的潜在规律。为了提高训练效率,还可以采用一些优化技巧,如批量训练、学习率调整等。
训练完成后,可以将LSTM模型应用于推荐系统中。在实际应用中,根据用户的观影历史数据,通过LSTM模型预测用户未来的观影偏好,并据此为用户推荐相应的电影。为了提高推荐的准确性,还可以结合其他技术,如基于内容的推荐、协同过滤等,形成混合推荐策略。
此外,针对LSTM模型的优化也是不可忽视的一环。在实际应用中,可能会遇到一些挑战,如模型过拟合、训练不稳定等。为了解决这些问题,可以采取一系列优化策略,如正则化、Dropout技术、梯度裁剪等。这些策略可以有效地提升模型的泛化能力,从而提高推荐系统的性能。
因此,基于LSTM的推荐算法设计与实现是一个复杂而富有挑战性的过程。通过精心地设计模型结构、选择合适的参数配置、采用有效的训练和优化策略,可以构建出高性能的电影推荐系统,为用户提供更加精准和个性化的观影体验。
1.5 系统功能框架图
1.6 推荐算法流程图
2 系统功能实现截图
2.1 用户功能模块实现
2.1.1 登录

2.1.2 电影库
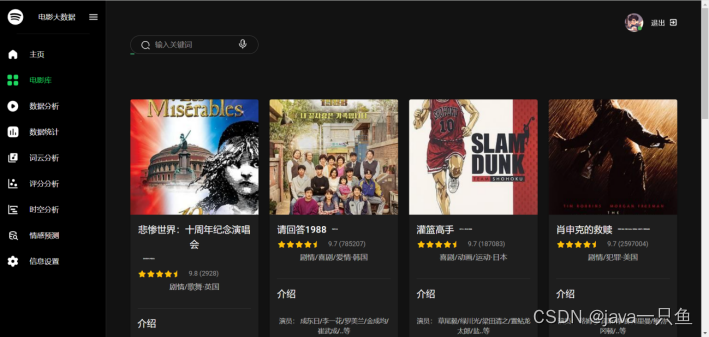
核心代码如下:
@movieBp.route('/get', methods=["GET"])
def get():
res = ResMsg()
keyword = request.args.get('keyword')
if keyword is None:
keyword = ""
# print(keyword)
result = db.session.query(Movie).filter(Movie.name.like('%' + keyword + '%')).order_by(Movie.douban_score.desc()).all()[:8]
data = movie_schema.dump(result)
res.update(code=ResponseCode.SUCCESS, data=data)
return res.data
2.1.3 数据分析
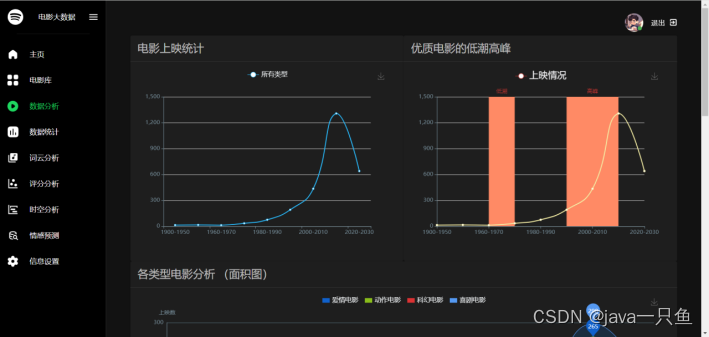
核心代码如下:
def getChart1():
res = ResMsg()
all = []
dz = []
kh = []
aq = []
xj = []
ranges = [('1900', '1950'), ('1950', '1960'), ('1960', '1970'), ('1970', '1980'), ('1980', '1990'),
('1990', '2000'), ('2000', '2010'), ('2010', '2020'), ('2020', '2030')]
for r in ranges:
cnt = db.session.query(Movie).filter(Movie.year >= r[0], Movie.year < r[1]).count()
dzcnt = db.session.query(Movie).filter(Movie.genres.like('%动作%'), Movie.year >= r[0], Movie.year < r[1]).count()
khcnt = db.session.query(Movie).filter(Movie.genres.like('%科幻%'), Movie.year >= r[0], Movie.year < r[1]).count()
aqcnt = db.session.query(Movie).filter(Movie.genres.like('%爱情%'), Movie.year >= r[0], Movie.year < r[1]).count()
xjcnt = db.session.query(Movie).filter(Movie.genres.like('%喜剧%'), Movie.year >= r[0], Movie.year < r[1]).count()
chart = dict(name=r[0] + '-' + r[1], value=cnt)
all.append(chart)
chart2 = dict(name=r[0] + '-' + r[1], value=dzcnt)
dz.append(chart2)
chart3 = dict(name=r[0] + '-' + r[1], value=khcnt)
kh.append(chart3)
chart4 = dict(name=r[0] + '-' + r[1], value=aqcnt)
aq.append(chart4)
chart5 = dict(name=r[0] + '-' + r[1], value=xjcnt)
xj.append(chart5)
# data = chart_data.dump(result)
res.update(code=ResponseCode.SUCCESS, data=dict(all=all, kh=kh, dz=dz, aq=aq, xj=xj))
return res.data
2.1.4 数据统计
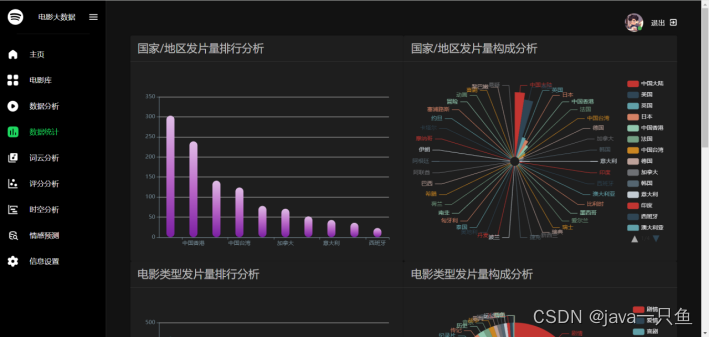
核心代码如下:
@movieBp.route('/getTypeRank', methods=["GET"])
def getTypeRank():
res = ResMsg()
types = ['惊悚', '古装', '武侠', '冒险', '喜剧', '恐怖', '犯罪', '历史', '歌舞', '纪录片', '动画', '科幻', '西部', '战争', '家庭', '传记', '悬疑',
'儿童', '灾难', '奇幻', '剧情', '同性', '动作', '运动', '音乐', '情色', '爱情']
datas = []
for t in types:
cnt = db.session.query(Movie).filter(Movie.genres.like('%' + t + '%')).count()
chart = dict(name=t, value=cnt)
datas.append(chart)
datas = sorted(datas, key=operator.itemgetter('value'), reverse=True)
res.update(code=ResponseCode.SUCCESS, data=dict(datas=datas))
return res.data