
CatBoost(Categorical Boosting)是由Yandex(一家俄罗斯互联网企业,旗下的搜索引擎曾在俄国内拥有逾60%的市场占有率,同时也提供其他互联网产品和服务)开发的一种基于梯度提升的机器学习算法。CatBoost特别擅长处理类别特征,并且能够有效地避免过拟合和数据泄露问题。CatBoost的全称是“Categorical Boosting”,它的设计初衷是为了在处理包含大量类别特征的数据时表现得更好。
CatBoost的特点
-
处理类别特征:CatBoost可以直接处理类别特征而不需要进行额外的编码(如one-hot编码)。
-
避免过拟合:CatBoost采用了一种新的处理类别特征的方法,有效地减少了过拟合。
-
高效性:CatBoost在训练速度和预测速度方面都表现优异。
-
支持CPU和GPU训练:CatBoost既可以在CPU上运行,也可以利用GPU进行加速训练。
-
自动处理缺失值:CatBoost可以自动处理缺失值,无需额外的预处理步骤。
CatBoost的核心原理
CatBoost的核心原理基于梯度提升决策树(GBDT),但在处理类别特征和避免过拟合方面进行了创新。以下是一些关键的技术点:
-
类别特征处理:
-
CatBoost引入了一个称为“均值编码”的方法,基于类别的均值计算新特征。
-
使用一种称为“目标编码”的技术,将类别特征转化为数值特征时,通过使用目标值的平均值来减少数据泄露的风险。
-
在训练过程中,通过使用统计信息对数据进行处理,避免直接使用目标变量进行编码。
-
-
有序提升(Ordered Boosting):
-
为了防止数据泄露和过拟合,CatBoost在训练时对数据进行了有序处理。
-
有序提升通过在训练过程中随机打乱数据,并确保模型在某一时刻只看到过去的数据,而不会使用未来的信息进行决策。
-
-
计算优化:
-
CatBoost通过预计算和缓存的方式加速了特征的计算过程。
-
支持CPU和GPU训练,能够在大规模数据集上表现出色。
-
CatBoost的基本使用
以下是一个使用CatBoost进行分类任务的基本示例,我们使用Auto MPG(Miles Per Gallon)数据集,它是一个经典的回归问题数据集,常用于机器学习和统计分析。该数据集记录了不同型号汽车的燃油效率(即每加仑燃油行驶的英里数)以及其他多个相关特征。
数据集特征:
-
mpg: 每加仑燃油行驶的英里数(目标变量)。
-
cylinders: 气缸数量,表示发动机的气缸数。
-
displacement: 发动机排量(立方英寸)。
-
horsepower: 发动机功率(马力)。
-
weight: 车辆重量(磅)。
-
acceleration: 0到60英里每小时的加速度时间(秒)。
-
model_year: 车辆生产年份。
-
origin: 车辆产地(1=美国,2=欧洲,3=日本)。
数据集前几行:
mpg cylinders displacement horsepower weight acceleration model_year origin
0 18.0 8 307.0 130.0 3504.0 12.0 70 1
1 15.0 8 350.0 165.0 3693.0 11.5 70 1
2 18.0 8 318.0 150.0 3436.0 11.0 70 1
3 16.0 8 304.0 150.0 3433.0 12.0 70 1
4 17.0 8 302.0 140.0 3449.0 10.5 70 1代码示例:
import pandas as pd # 导入Pandas库,用于数据处理
import numpy as np # 导入Numpy库,用于数值计算
from sklearn.model_selection import train_test_split # 从sklearn库导入train_test_split,用于划分数据集
from sklearn.metrics import mean_squared_error, mean_absolute_error # 导入均方误差和平均绝对误差,用于评估模型性能
from catboost import CatBoostRegressor # 导入CatBoost库中的CatBoostRegressor,用于回归任务
import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
import seaborn as sns # 导入Seaborn库,用于绘制统计图# 设置随机种子以便结果复现
np.random.seed(42)# 从UCI机器学习库加载Auto MPG数据集
url = "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
column_names = ['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year', 'origin']
data = pd.read_csv(url, names=column_names, na_values='?', comment='\t', sep=' ', skipinitialspace=True)# 查看数据集的前几行
print(data.head())# 处理缺失值
data = data.dropna()# 特征和目标变量
X = data.drop('mpg', axis=1) # 特征变量
y = data['mpg'] # 目标变量# 将类别特征转换为字符串类型(CatBoost可以直接处理类别特征)
X['cylinders'] = X['cylinders'].astype(str)
X['model_year'] = X['model_year'].astype(str)
X['origin'] = X['origin'].astype(str)# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义CatBoost回归器
model = CatBoostRegressor(iterations=1000, # 迭代次数learning_rate=0.1, # 学习率depth=6, # 决策树深度loss_function='RMSE', # 损失函数verbose=100 # 输出训练过程信息
)# 训练模型
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50)# 进行预测
y_pred = model.predict(X_test)# 评估模型性能
mse = mean_squared_error(y_test, y_pred) # 计算均方误差
mae = mean_absolute_error(y_test, y_pred) # 计算平均绝对误差# 打印模型的评估结果
print(f'Mean Squared Error (MSE): {mse:.4f}')
print(f'Mean Absolute Error (MAE): {mae:.4f}')# 绘制真实值与预测值的对比图
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--k') # 绘制对角线
plt.xlabel('True Values') # X轴标签
plt.ylabel('Predictions') # Y轴标签
plt.title('True Values vs Predictions') # 图标题
plt.show()# 特征重要性可视化
feature_importances = model.get_feature_importance() # 获取特征重要性
feature_names = X.columns # 获取特征名称plt.figure(figsize=(10, 6))
sns.barplot(x=feature_importances, y=feature_names) # 绘制特征重要性条形图
plt.title('Feature Importances') # 图标题
plt.show()# 输出
'''
mpg cylinders displacement horsepower weight acceleration \
0 18.0 8 307.0 130.0 3504.0 12.0
1 15.0 8 350.0 165.0 3693.0 11.5
2 18.0 8 318.0 150.0 3436.0 11.0
3 16.0 8 304.0 150.0 3433.0 12.0
4 17.0 8 302.0 140.0 3449.0 10.5 model_year origin
0 70 1
1 70 1
2 70 1
3 70 1
4 70 1
0: learn: 7.3598113 test: 6.6405869 best: 6.6405869 (0) total: 1.7ms remaining: 1.69s
100: learn: 1.5990203 test: 2.3207830 best: 2.3207666 (94) total: 132ms remaining: 1.17s
200: learn: 1.0613606 test: 2.2319632 best: 2.2284239 (183) total: 272ms remaining: 1.08s
Stopped by overfitting detector (50 iterations wait)bestTest = 2.21453232
bestIteration = 238Shrink model to first 239 iterations.
Mean Squared Error (MSE): 4.9042
Mean Absolute Error (MAE): 1.6381<Figure size 1000x600 with 1 Axes>
<Figure size 1000x600 with 1 Axes>
'''
Mean Squared Error (MSE): 均方误差,表示预测值与实际值之间的平均平方差异。值越小,模型性能越好,在这里MSE的值是4.9042。
Mean Absolute Error (MAE): 平均绝对误差,表示预测值与实际值之间的平均绝对差异。值越小,模型性能越好,在这里MAE的值是1.6381。
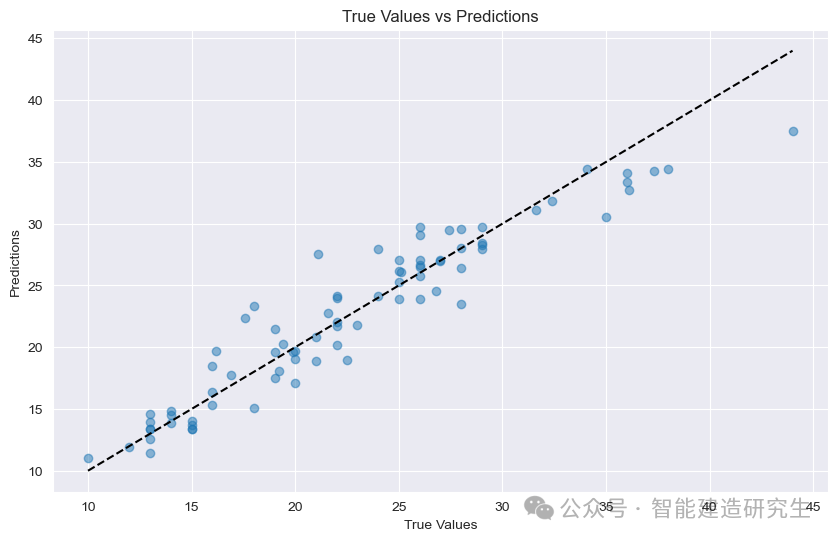
-
散点图:图中的每个点表示一个测试样本。横坐标表示该样本的真实值(MPG),纵坐标表示模型的预测值(MPG)。
-
对角线:图中的黑色虚线是45度对角线,表示理想情况下的预测结果,即预测值等于真实值。
-
点的分布:
-
靠近对角线:表示模型的预测值与真实值非常接近,预测准确。
-
远离对角线:表示预测值与真实值有较大差距,预测不准确。
-
通过图中的点可以看到大部分点都集中在对角线附近,这表明模型的预测性能良好,但也有一些点离对角线较远,表示这些样本的预测值与真实值存在一定的差距。
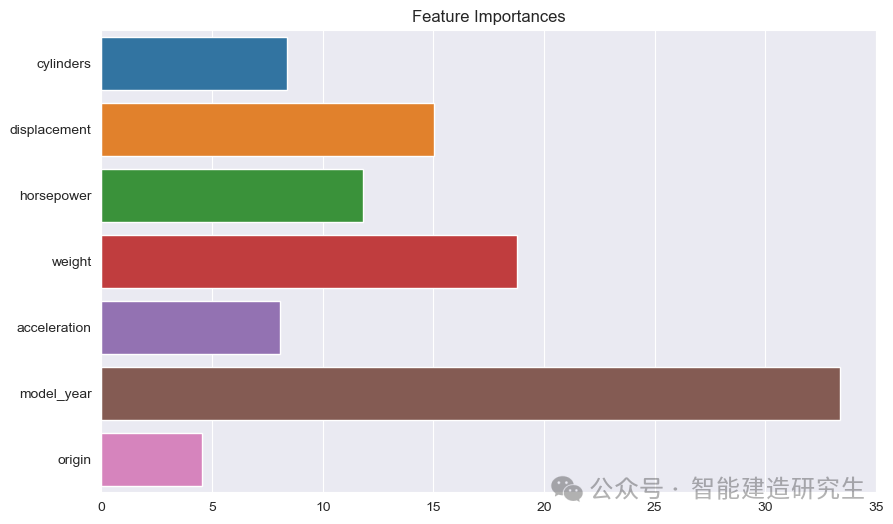
-
条形图:每个条形表示一个特征在模型中的重要性。条形越长,表示该特征对模型预测的贡献越大。
-
特征名称:在Y轴上列出了所有特征的名称。
-
特征重要性值:在X轴上显示了每个特征的相对重要性值。
从图中可以看到:
-
model_year:在所有特征中最重要,表示汽车的生产年份对预测燃油效率有很大的影响。
-
weight:汽车的重量是第二重要的特征,对燃油效率也有显著影响。
-
displacement 和 horsepower:发动机的排量和功率对燃油效率也有较大的贡献。
在实例中,我们使用CatBoost处理Auto MPG数据集,其主要目的是构建一个回归模型,以预测汽车的燃油效率(即每加仑燃油行驶的英里数,MPG)。
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!