当然是有的,没有我就不发这篇文章了.
论文名称KBLAM: KNOWLEDGE BASE AUGMENTED LANGUAGE MODEL
ICLR 2025的论文,MS系的
这篇论文介绍了一种名为 KBLAM(Knowledge Base augmented Language Model,知识库增强语言模型) 的新方法,用于将外部知识库(KB)高效地集成到预训练的大型语言模型(LLM)中,以提升其在特定任务中的表现,同时避免传统方法的局限性。
核心问题与背景
LLM虽然在知识和推理方面表现优异,但当需要处理超出其参数存储知识的外部信息时,往往需要额外的增强手段。传统方法包括:
1. 监督微调(Fine-tuning):通过更新模型权重来融入外部知识,但效率低,且可能导致“灾难性遗忘”(对通用任务性能下降)。
2. 检索增强生成(RAG):利用外部检索模块从文档中提取相关信息并拼接到输入中,虽然有效,但依赖独立的检索系统,增加了复杂性。
3. 下文学习(In-context Learning):直接将整个外部语料放入模型上下文,虽然简单,但计算和内存开销随上下文长度呈二次方增长,且难以动态更新,其实和rag一样他俩都是O2的计算复杂度,因为走的是文本为给大模型。
这些方法都又局限性,所以作者就提出一种新的解决方案:KBLAM。
KBLAM 的核心思想
KBLAM 的目标是通过将外部知识转化为结构化的“知识令牌”(knowledge tokens),并利用一种高效的“矩形注意力机制”(rectangular attention)将其融入预训练的 LLM 中。主要特点包括:
- 知识表示:将外部语料转化为知识三元组(<name>, <property>, <value>),如“Apple, founder, Steve Jobs”,并通过预训练的句子编码器(带线性适配器)将每个三元组编码为固定长度的键值向量对(key-value vector pairs),称为“知识令牌”。
- 注意力机制:使用矩形注意力结构,使输入提示(prompt)的查询(query)可以同时关注自身令牌和所有知识令牌,而知识令牌之间互不关注。这种设计使得计算复杂度随知识库大小呈线性增长(而非二次方),并支持动态更新。
- 训练方式:通过指令微调(instruction tuning)在合成数据上学习线性适配器(你就当整出来个lora就可以了),将编码器空间映射到 LLM 的嵌入空间,而无需微调整个模型。
注意力是这样的
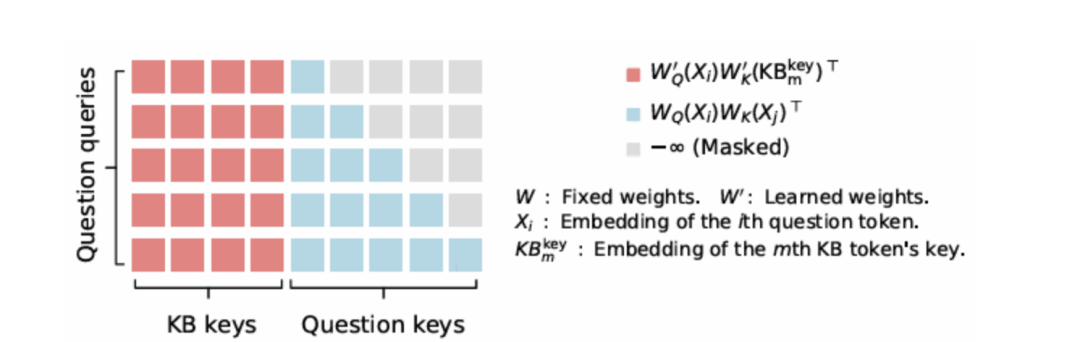
与现有方法的对比
- 对比 RAG:KBLAM 无需外部检索模块,所有知识通过注意力机制端到端融入模型。这么做肯定是降低延迟提升体验,降低故障点。
- 对比上下文学习:KBLAM 的内存和时间复杂度更低(线性 vs 二次方),且支持动态更新知识库,而无需重新计算整个上下文。
- 优势:KBLAM 可以在单张 A100 80GB GPU 上将超过 10,000 个三元组的知识库集成到仅 8,000 上下文窗口的 8B 参数 LLM 中,同时保持可解释性(通过注意力分数分析模型如何使用知识)。
如图:
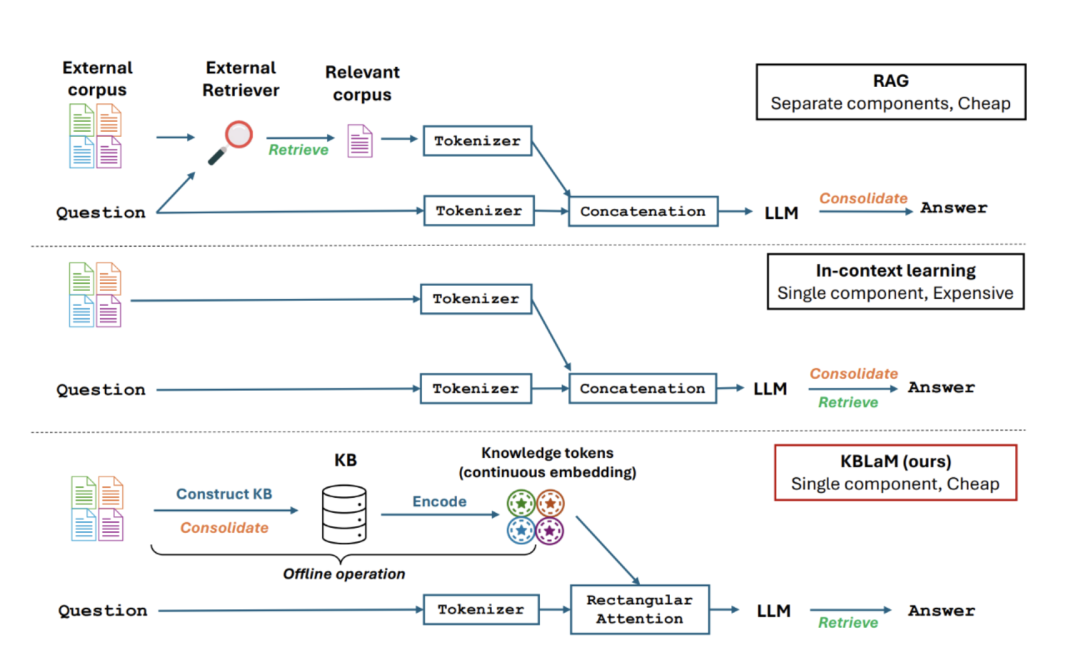
人话解释就是:
- SFT效果就很难好,其实这论文里说的只是一方面,最核心的是数据分布,加上专有知识领域就那么点东西,很难对parameter有什么好作用,要不就不行,要不就再难遗忘,过拟合
- RAG和prompt enginering+inconext-learning就没什么可说的了
- 咱们这个方案理解起来某种程度上其实有点复杂
为什么说复杂呢
我先问你rag送给llm的是啥?
是L2距离或者余弦距离比对的最短的那块吧,然后你也不是给向量表达,而是把对应最短的index的value也就是你对应的那段chunk文本+prompt一起发给LLM对不,说白了,你做的还时inconext-learning,区别只是给多给少罢了。
那咱们这个是什么呢?
你给的是整个的知识库转换的知识令牌(KBtokens)
啥是知识令牌呢?
以下进入抽象环节
=====================================================
知识令牌是外部知识库中每个知识三元组(例如,<name>, <property>, <value>,如 <Apple, founder, Steve Jobs>)的连续向量表示。具体生成过程如下:
- 键向量(key vector)
:通过预训练的句子编码器(带有线性适配器)将三元组中的 <name> 和 <property> 编码为一个固定长度的向量。
- 值向量(value vector)
:将 <value> 编码为另一个固定长度的向量。
-
这些键值向量对(key-value vector pairs)被称为 知识令牌,是在预处理阶段生成并存储的,而不是直接以文本形式存在。
这玩意有啥用呢?
在 KBLAM 中,知识令牌与提示中的令牌通过 矩形注意力机制 进行联合计算。这种机制的核心思想是让提示中的令牌能够同时关注自身和其他提示令牌,以及所有知识令牌,而知识令牌之间不相互关注。具体过程如下:
矩形注意力机制的结构
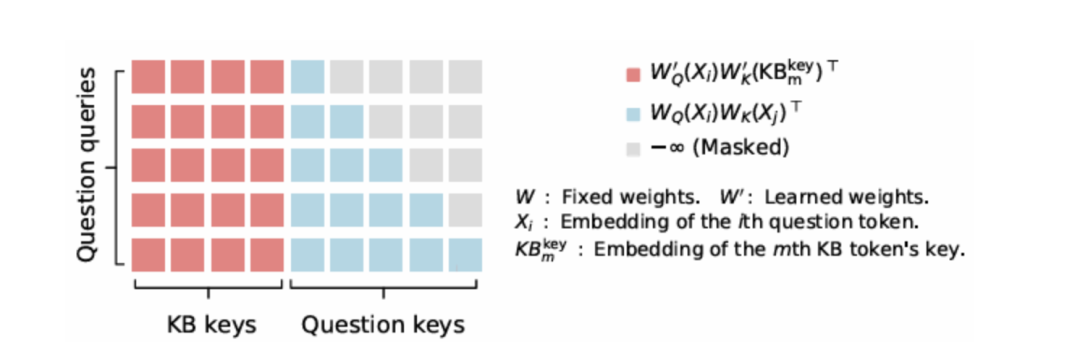
还是这个图
- 提示令牌的注意力
-
提示中所有先前令牌的键向量(key vector)。
-
所有知识令牌的键向量。
-
提示中的每个令牌生成一个查询向量(query vector),说白了就是QKV里的Q(你可以这么理解)他能关注到:
1- 提示中所有先前令牌的键向量(key vector)。
2- 所有知识令牌的键向量
-
通过计算注意力分数,提示令牌(prompt的token)可以从这些知识令牌的键向量对应的值向量(value vector)中获取信息,这不就相当于学到了吗?但是知识令牌之间是不做运算的,只有prompt的token和KB token做运算,知识令牌之间不相互关注,彼此独立。这种设计降低了计算复杂度。
-
对于提示中的第 n个令牌,在模型第L层的注意力输出计算如下:
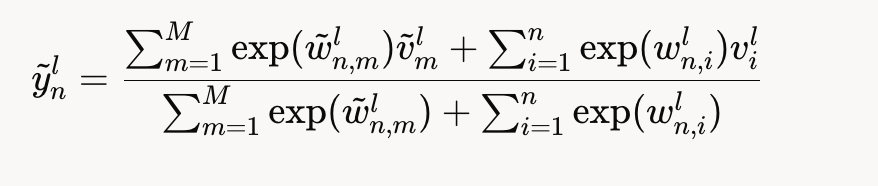

就是一顿softmax
计算过程解释
- 注意力分数
提示令牌的查询向量分别与提示中的键向量和知识令牌的键向量计算点积,得到注意力分数。
- 加权求和
根据注意力分数,对提示中先前令牌的值向量和所有知识令牌的值向量进行加权求和,生成最终的注意力输出。(另一个维度的QKV)
-
这最后就能实现往prompt tokens和知识库的KB tokens实现了信息融合,就相当于把外部知识给加载进来了。
知识令牌怎么加载的呢?
存储形式:知识令牌是以键值向量的形式存储的,而不是文本令牌。这些向量在预处理阶段生成并保存在内存中。
推理过程:
-
在推理时,提示中的文本令牌被输入到 LLM 中,生成对应的查询、键和值向量。
-
知识令牌的键值向量被直接加载到模型的注意力层,与提示令牌的键值向量一起参与计算。
-
效率优势:这种方式不仅减少了输入处理的开销,还支持动态更新——当知识库变化时,只需更新对应的知识令牌向量,而无需重新处理整个上下文
前面这些应该讲明白了,那你原生LLM怎么能认这些KB tokens啊?
就是我前面提的训练
- 训练目标
-
KBLAM 在训练时会学习如何将知识库中的三元组(比如 <名字>, <属性>, <值>)通过句子编码器和线性适配器映射到 LLM 的嵌入空间。
-
训练的目标不是让模型记住某个具体的知识库,而是学会一种通用的方法,能够处理各种不同的知识库。
-
- 知识令牌的生成
-
每个知识三元组会被独立编码成一个知识令牌(knowledge token),这些令牌是模型在推理时用来提取信息的。
-
- 动态更新
-
KBLAM 的设计支持知识库的动态更新。如果您想注入一个新的知识库,只需要将新知识库中的三元组生成对应的知识令牌,然后加载到模型中即可。
-
如果知识库内容有变化(比如添加、删除或修改三元组),只需更新对应的知识令牌,不需要重新训练整个模型。
-
那训啥呢?
在 KBLAM 的推理过程中,以下几个部分是需要通过训练来学习的:
- 线性适配器(Linear Adapters)
- 键适配器 WK
将知识三元组的键向量(从 <name> 和 <property> 编码生成)映射到 LLM 的键向量空间。
- 值适配器 WV
将知识三元组的值向量(从 <value> 编码生成)映射到 LLM 的值向量空间。
- 作用
线性适配器负责将句子编码器生成的知识令牌向量映射到 LLM 的嵌入空间。具体来说:
句子编码器和 LLM 的向量空间天然是不同的。如果不训练线性适配器,知识令牌的向量无法与 LLM 的内部表示对齐,导致注意力机制无法正确识别和利用这些知识。
- 键适配器 WK
- 查询头(Query Head, WQ)
- 作用
KBLAM 在 LLM 的每个注意力层中引入了一个额外的查询头,用于生成提示令牌的查询向量(query vector)。这些查询向量与知识令牌的键向量进行注意力计算,从而决定提示令牌关注哪些知识令牌。
-
未经训练的查询头无法生成合适的查询向量,提示令牌就无法准确地从知识令牌中提取相关信息。例如,如果查询头参数是
是随机的,注意力机制可能会关注错误的知识令牌,导致答案不准确。
- 作用
这些所有要被训练的东西,我们叫
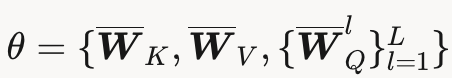
其他的什么原始模型的QKV啊,FFN啊,你都不用训,都是冻结的。
然后你这些整个KB tokens是不是要加载啊,比如你放在外面,你和rag有什么区别?这个时候的主要区别就是rag是text,需要外置查询,我这个放外面也是一堆tokens,而且rag因为你要从走一遍transformer的逻辑,所以还是O2的复杂度,而我这个是O
第二点,我这东西比起整个rag还是小的,举个例子
- 每个知识令牌的内存需求
假设使用的是像 Llama 3 8B 这样的模型,嵌入维度 D=4096。每个知识令牌包含一个键向量和一个值向量,每个向量占用 4096×4 字节(float32 格式),即 16 KB。因此,一个知识令牌的总占用约为2×16 KB=32 KB。 - 总内存占用估算
如果知识库包含 M=10,000 个三元组,那么加载所有知识令牌所需的显存为:10,000×32 KB=320 MB对于现代 GPU(例如 NVIDIA A100 80GB),320 MB 仅占显存的极小部分。即使知识库规模扩大到 100,000 个三元组,也不过需要约 3.2 GB 显存,仍然远低于 A100 的容量。 - 实际验证
KBLAM 的论文中提到,它可以在单张 A100 80GB GPU 上处理超过 10,000 个三元组的知识库,并将其集成到仅 8,000 个上下文窗口的 8B 参数语言模型中。这表明,对于中等规模的知识库,将所有知识令牌加载到显存中是完全可行的。
实验与结果
- 任务:包括问答(Q&A)和开放式推理。
- 表现:在合成数据集上,KBLAM 与上下文学习性能相当,但在内存占用更低的情况下能扩展到更大规模的知识库;在 Enron(真实数据集)上性能略有下降,但仍优于零样本基线。
- 可解释:注意力矩阵显示模型能准确检索相关知识三元组。
- 抗幻觉:KBLAM 能在知识库中无答案时拒绝回答,减少幻觉现象。
局限性与未来工作
- 合成数据质量:当前使用合成数据训练,面对分布外数据(如 Enron)时性能下降,未来可改进合成数据的多样性。
- 信息压缩:知识令牌固定长度可能丢失细节(如精确数字),可考虑可调压缩率。
- 复杂推理:未来可探索支持多跳推理或思维链(chain-of-thought)等任务。
KBLAM 提供了一种高效、可扩展且可解释的方法,将结构化知识库融入 LLM,避免了传统方法的计算瓶颈和动态性不足。论文还开放了代码和数据集(https://github.com/microsoft/KBLaM),为后续研究奠定了基础。
好了,今天的课就到这里,再见吧👋