Sharding-JDBC从入门到精通(2)- Sharding-JDBC 介绍
一、概述-分库分表所带来的问题
1、分库分表带来的问题
分库分表能有效的缓解了单机和单库带来的性能瓶颈和压力,突破网络 IO、硬件资源、连接数的瓶颈,同时也带来了一些问题。
2、分库分表带来的问题 :事务一致性问题
由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题。
3、分库分表带来的问题 :跨节点关联查询
1)在没有分库前,我们检索商品时可以通过以下 SQL 对店铺信息进行关联询
SELECT P.*,r.[地理区域名称],5.[店铺名称],s.[信誉]FROM「商品信息]P
LEFT J0IN[地理区域]r ON p.[产地]=r.[地理区域编码]LEFT JOIN[店铺信息]s ON p.id = s.[所属店铺]WHERE...ORDER BY...LIMIT...
2)但垂直分库后[商品信息]和[店铺信息]不在一个数据库,甚至不在一台服务器,无法进行关联查询。
3)可将原关联查询分为两次查询,第一次查询的结果集中找出关联数据 id, 然后根据 id 发起第二次请求得到关联数据,最后将获得到的数据进行拼装。
4、分库分表带来的问题 :跨节点分页、排序函数
1)跨节点多库进行查询时,limit 分页、order by 排序等问题,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。
2)如,进行水平分库后的商品库,按 ID 倒序排序分页,取第一页:
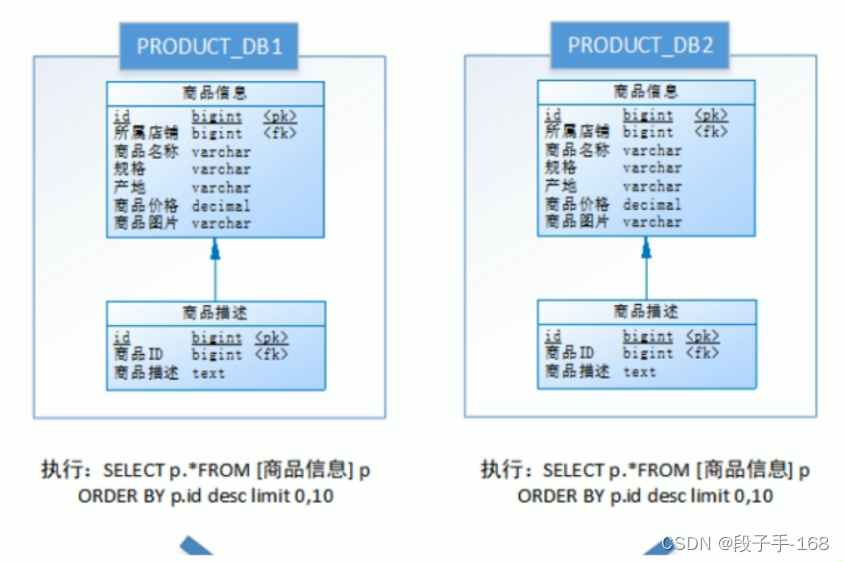
3)以上流程是取第一页的数据,性能影响不大,但由于商品信息的分布在各数据库的数据可能是随机的,如果是取第 N 页,需要将所有节点前 N 页数据都取出来合并,再进行整体的排序,操作效率可想而知。所以请求页数越大,系统的性能也会越差。
4)在使用 Max、Min、Sum、Count 之类的函数进行计算的时候,与排序分页同理,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回。
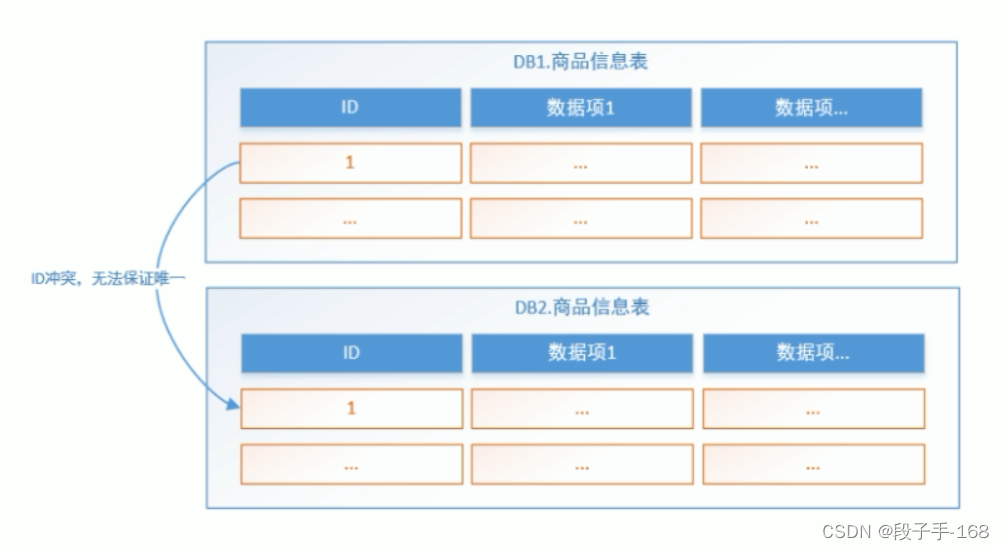
5、分库分表带来的问题 :主键避重
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库生成的 ID 无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。
6、分库分表带来的问题 :公共表
1)实际的应用场景中,参数表、数据字典表等都是数据量较小,变动少,而且属于高频联合查询的依赖表。电商业务例子中地理区域表也属于此类型。
2)可以将这类表在每个数据库都保存一份,所有对公共表的更新操作都同时发送到所有分库执行。
3)由于分库分表之后,数据被分散在不同的数据库、服务器。因此,对数据的操作也就无法通过常规方式完成,并且它还带来了一系列的问题。好在,这些问题不是所有都需要我们在应用层面上解决,市面上有很多中间件可供我们选择,其中 Sharding-JDBC 使用流行度较高。
二、概述-Sharding-JDBC 介绍
1、sharding-JDBc 介绍
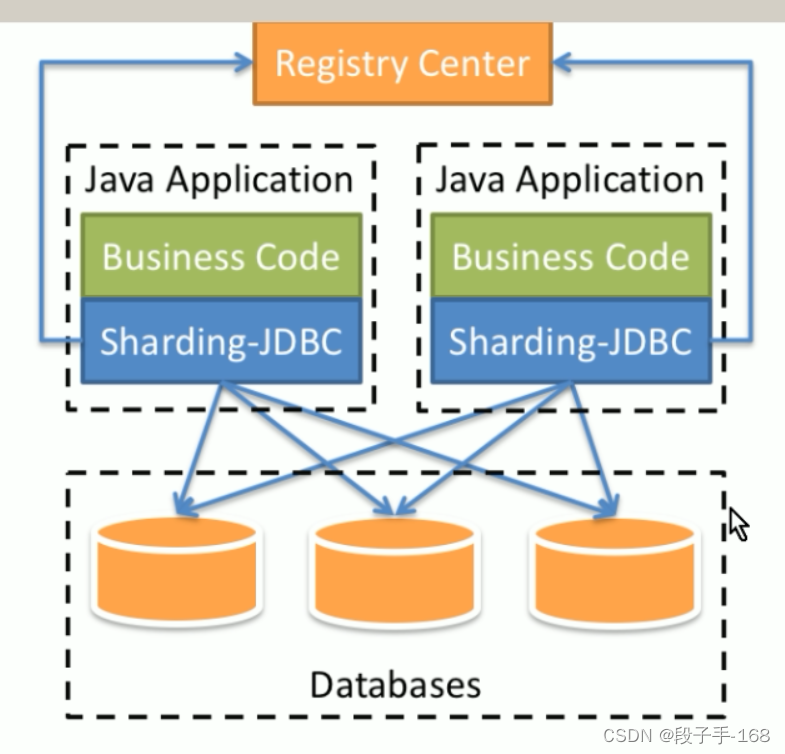
Sharding-JDBC, 它定位为轻量级 java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
1)sharding-JDBc 是当当网研发的开源分布式数据库中间件,从 3.0 开始 Sharding-JDBC 被包含在 shardingSphere 中,之后该项目进入进入 Apache 孵化器,4.0 版本之后的版本为 Apache 版本。
2)ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar (计划中)这3款相互独立的产品组成。
他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、容器、云原生等各种多样化的应用场景。
3)ShardingSphere 官方地址 :
https://shardingsphere.apache.org/document/current/cn/overview/
4)Sharding-JDBC 的核心功能为数据分片和读写分离,通过 Sharding:JDBc,应用可以透明的使用 Jdbc 访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
- 适用于任何基于 java 的 ORM 框架,如:Hibernate,Mybatis,SpringJDBC Template 或直接使用 JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0,BoneCP, Druid, HikariCp 等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL
2、Sharding-JDBC 的工作方式
使用 Sharding-Jdbc 前需要人工对数据库进行分库分表,在应用程序中加入 Sharding-Jdbc 的 jar 包,应用程序通过 Sharding-Jdbc 操作分库分表后的数据库和数据表,由于 Sharding-Jdbc 是对 Jdbc 驱动的增强,使用 Sharding-JDBC 就像使用 JDBC 驱动一样,在应用程序中是无需指定具体要操作的分库和分表的。
三、概述-Sharding-JDBC 介绍-与 jdbc 性能对比
1、Sharding-JDBC 与 jdbc 性能对比:性能损耗测试
服务器资源充足、并发数相同,比较 JDBC 和 Sharding-JDBC 性能损耗,Sharding-JDBC 相对 IDBC 损耗不超过 7%。
基准测试性能对比
| 业务场景 | JDBC | Sharding-JDBC1.5.2 | sharding-JDBC1.5.2/JDBC损耗 | |
|---|---|---|---|---|
| 单库单表查询 | 493 | 470 | 4.7% | |
| 单库单表更新 | 6682 | 6303 | 5.7% | |
| 单库单表插入 | 6855 | 6375 | 7% | |
| 业务场景 | 业务平均响应时间(ms) | 业务TPS | ||
|---|---|---|---|---|
| JDBC单库单表查询 | 7 | 493 | ||
| Sharding-JDBC 1.5.2单库单表查询 | 8 | 470 | ||
2、性能对比测试:
服务器资源使用到极限,相同的场景 JDBC 与 Sharding-JDBC 的吞吐量相当。
3、性能对比测试:
服务器资源使用到极限,Shtrding-JDBC 采用分库分表后,Sharding-JDBC 吞吐量较 JDBC 不分表有接近 2 倍的提升。
4、JDBC 单库两库表与 Sharding-JDBC 两库各两表对比
| 业务场景 | JDBC单库两表 | Sharding-JDBC两库各两表 | 性能提升至 | |
|---|---|---|---|---|
| 查询 | 1736 | 3331 | 192% | |
| 更新 | 9170 | 17997 | 196% | |
| 插入 | 11574 | 23043 | 199% | |
5、JDBC 单库单表与 Sharding-JDBC 两库各一表对比
| 业务场景 | JDBC单库单表 | Sharding-JDBC两库各一表 | 性能提升至 | |
|---|---|---|---|---|
| 查询 | 1586 | 2944 | 185% | |
| 更新 | 9548 | 18561 | 194% | |
上一节关联链接请点击
# Sharding-JDBC从入门到精通(1)- 概述-分库分表