前言
如此文《七月论文审稿GPT第3.2版和第3.5版:通过paper-review数据集分别微调Mistral、gemma》所讲
Google作为曾经的AI老大,我司自然紧密关注,所以当Google总算开源了一个gemma 7b,作为有技术追求、技术信仰的我司,那必须得支持一下,比如用我司的paper-review数据集微调试下,彰显一下gemma的价值与威力
后来我司考虑到毕竟llama的生态更完善、迭代速度更快,故之后更多是微调llama,然后Google到底是不甘落后,24年6.27,在时隔4个月之后,Google终于推出了gemma的升级版:gemma2,我其实想说,如果是前几年的AI时代,这个速度可以了,但如今是大模型时代,还是太慢了
- 不过既然推出了,加之我司把论文审稿的数据弄成7方面review之后,llama2、llama3都还没pk赢过gpt4(若弄成4方面review,则早已赢过了GPT4-1106)
- 那可以让情况4的早7数据,微调下gemma2呢,过程中保持“微调的prompt用的是potential,与阿荀给的数据格式一致”,包括推理的prompt
预期是:开源模型得在7方面review的表现,类似4方面review那样,也是可以超过gpt4的
如此,便有了本文(且把之前关于gemma1的介绍也从上面那篇文章 《通过paper-review数据集分别微调Mistral、gemma》中脱离出来,归纳到本文)
第一部分 Google推出gemma,试图与llama、Mistral形成三足鼎立之势
Google在聊天机器人这个赛道上,可谓被双向夹击
- 闭源上被OpenAI的ChatGPT持续打压一年多(尽管OpenAI用的很多技术比如transformer、CoT都是Google发明的,尽管Google推出了强大的Gemini)
- 开源上则前有Meta的llama,后有Mistral的来势汹汹
终于在24年2.21,按耐不住推出了开源模型gemma(有2B、7B两个版本,这是其技术报告,这是其解读之一),试图对抗与llama、Mistral在开源场景上形成三足鼎立之势

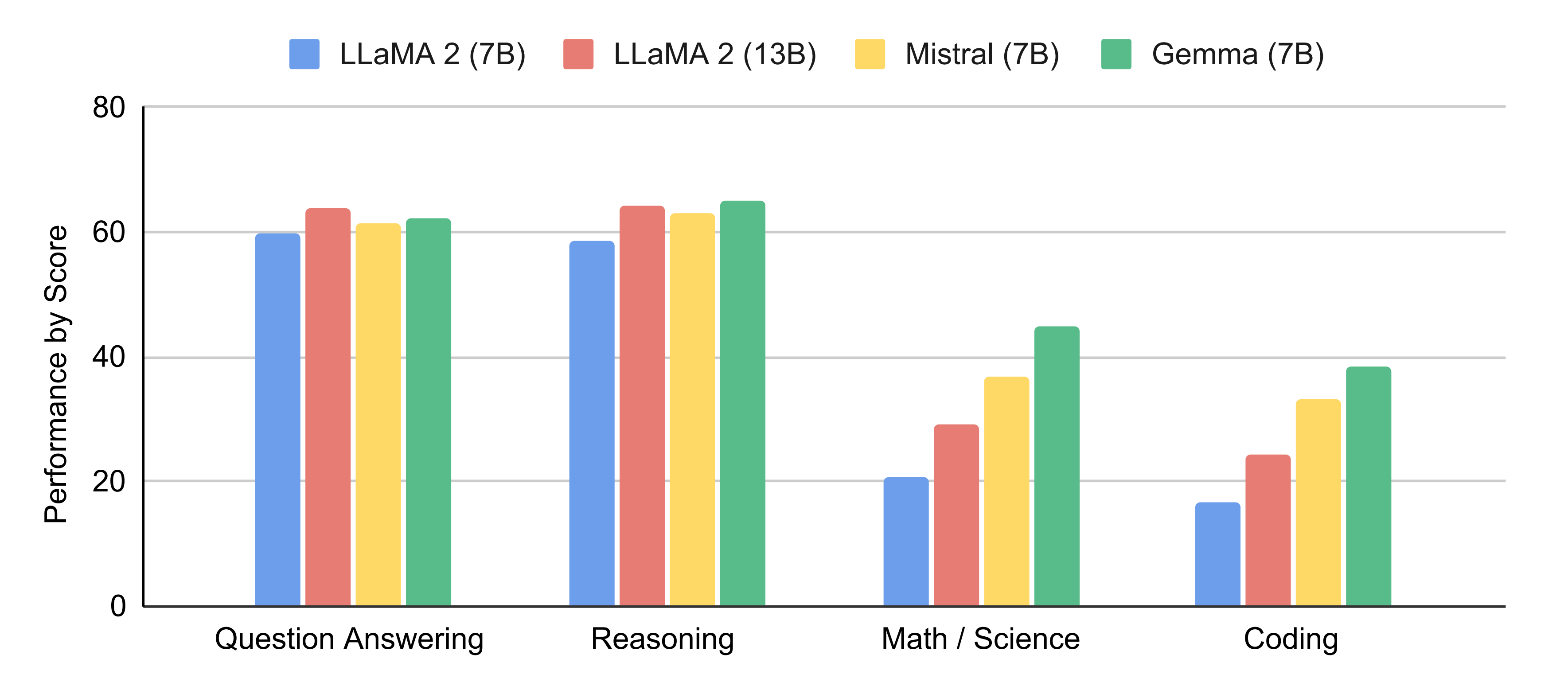
1.1 gemma 7B的性能:比肩Mistral 7B、超越llama 7B
Gemma 7B在 18 个基于文本的任务中的 11 个上优于相似参数规模的开放模型,例如除了问答上稍逊于llama 13B,其他诸如常识推理、数学和科学、编码等任务上的表现均超过了llama2 7B/13B(关于llama2的介绍请看此文的第三部分)、Mistral 7B
1.2 模型架构:基于Transformer解码器、多头/多查询注意力、RoPE、GeGLU、RMSNorm
1.2.1 基于Transformer解码器:上下文8192、词表256K、训练数据集6万亿token
Gemma 模型架构基于 Transformer 解码器
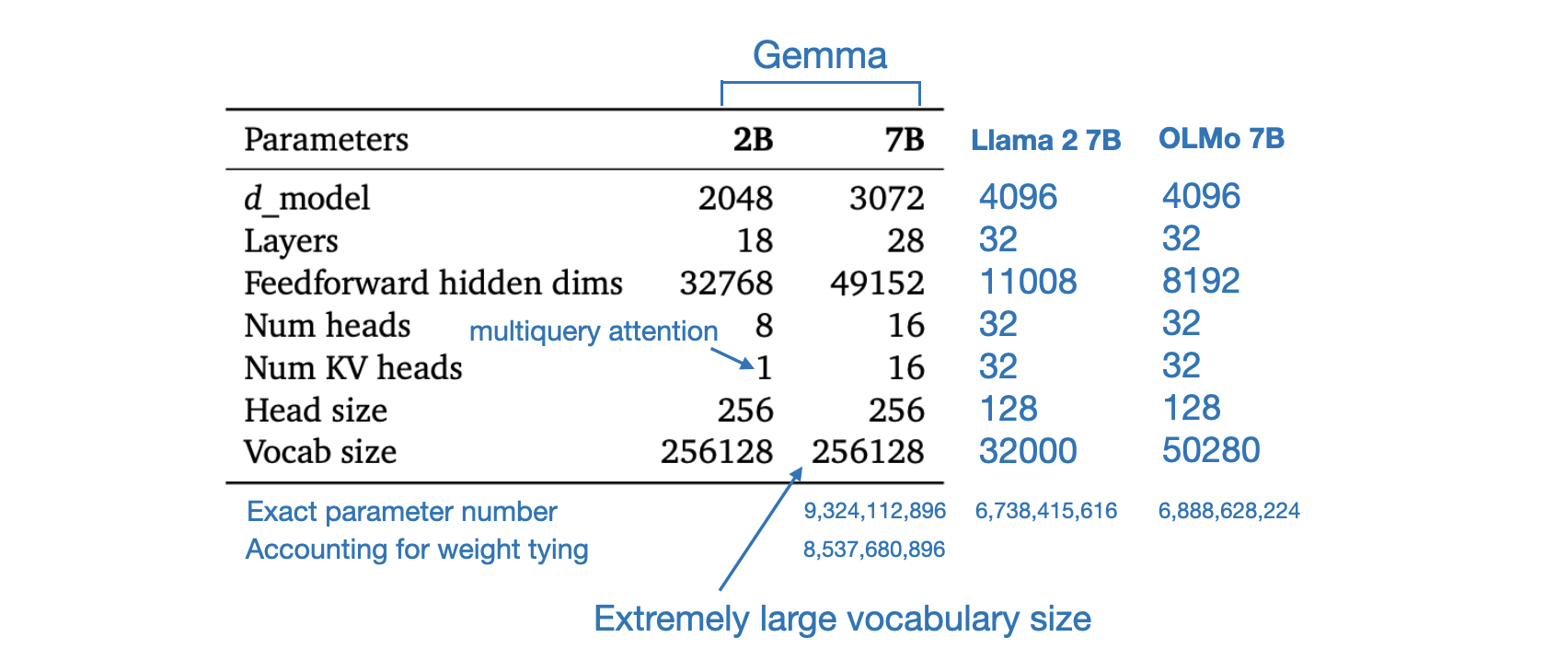
- 模型训练的上下文长度为 8192 个 token
- 其词表则比llama2 所用的32K大太多了,为 256k个token(导致我们微调gemma 7b时,在论文审稿所需要的理想长度12K之下且在已经用了qlora和flash attention的前提之下,48g显存都不够,详见此文)
- 至于训练数据集达到6万亿个token(即We trained Gemma models on up to 6T tokens of text,而llama2的训练集只有2万亿个token)
1.2.2 7B/2B模型使用多头注意力/多查询注意力、RoPE、GeGLU、RMSNorm
此外,gemma还在原始 transformer 论文的基础上进行了改进,改进的部分包括:
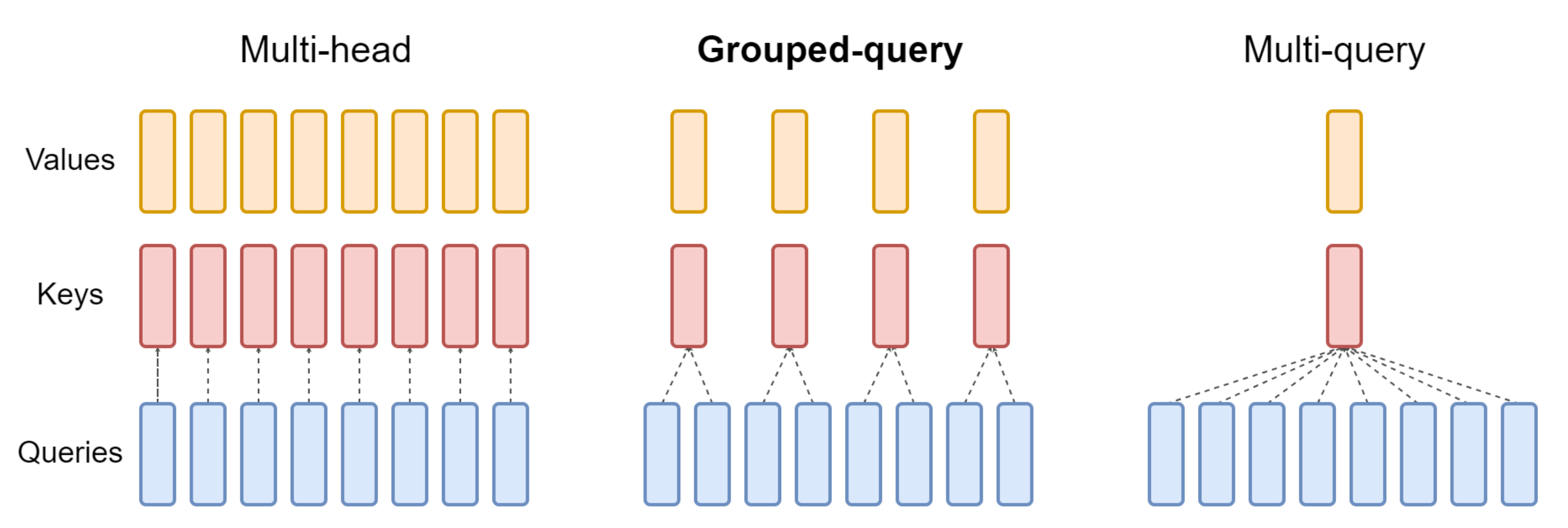
- 多查询注意力:7B 模型使用多头注意力(即MHA,如下图左侧所示),而 2B 检查点使用多查询注意力「即MQA,如下图右侧所示,𝑛𝑢𝑚_𝑘𝑣_ℎ𝑒𝑎𝑑𝑠 = 1,关于GQA的更多介绍,请参见《一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA》」
- RoPE 嵌入:Gemma 在每一层中使用旋转位置嵌入,而不是使用绝对位置嵌入;此外,Gemma 还在输入和输出之间共享嵌入,以减少模型大小
- GeGLU 激活:GeGLU 激活函数(其对应的论文为Google发的这篇《GLU Variants Improve Transformer》),取代传统的 ReLU 非线性函数
GeGLU是GeLU(Gaussian Error Linear Unit) 的门线性单元变体,而GeLU与ReLU不允许负值不同,其允许为负输入值执行梯度传播总之,GeGLU 的激活被分割为两部分,分别是 sigmoid 单元和线性映射单元(它与 sigmoid 单元的输出逐元素相乘),使得其与Llama 2和Mistral等用的SwiGLU极其类似(关于SwiGLU的细致介绍请看此文《LLaMA的解读与其微调:Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙/LLaMA 2》的1.2.3节:SwiGLU替代ReLU)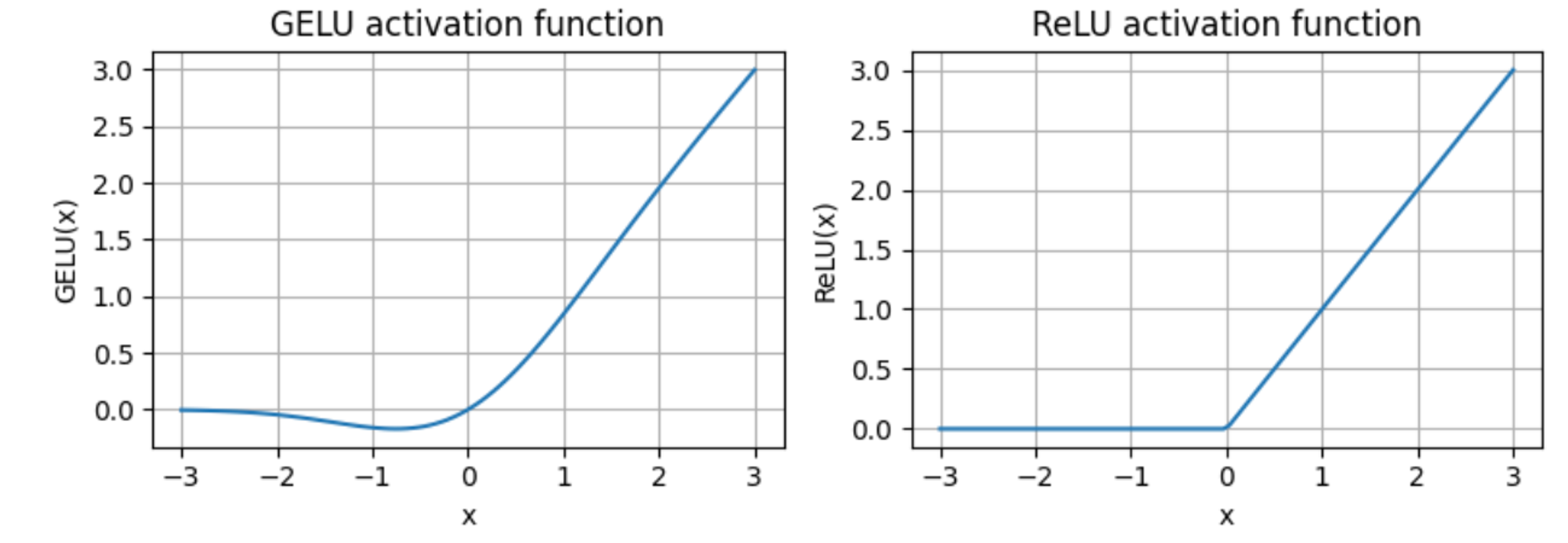
唯一的区别是 GeGLU 使用的基础激活函数是 GeLU 而不是 Swish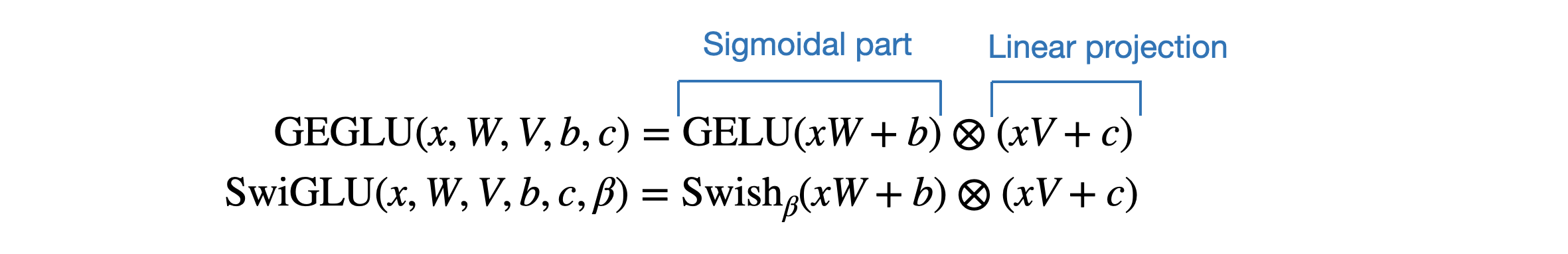
- 归一化:Gemma 对每个 transformer 子层的输入和输出进行归一化,这与仅对其中一个或另一个进行归一化的标准做法有所不同,另,gemma使用RMSNorm 作为归一化层
如国外一开发者Sebastian Raschka所说,“At first glance, it sounds like Gemma has an additional RMSNorm layer after each transformer block. However, looking at the official code implementation, it turns out that Gemma just uses the regular pre-normalization scheme that is used by other LLMs like GPT-2, Llama 2(Gemma 仅仅使用了 GPT-2、Llama 2 等其他 LLM 使用的常规预归一化方案), and so on, as illustrated below”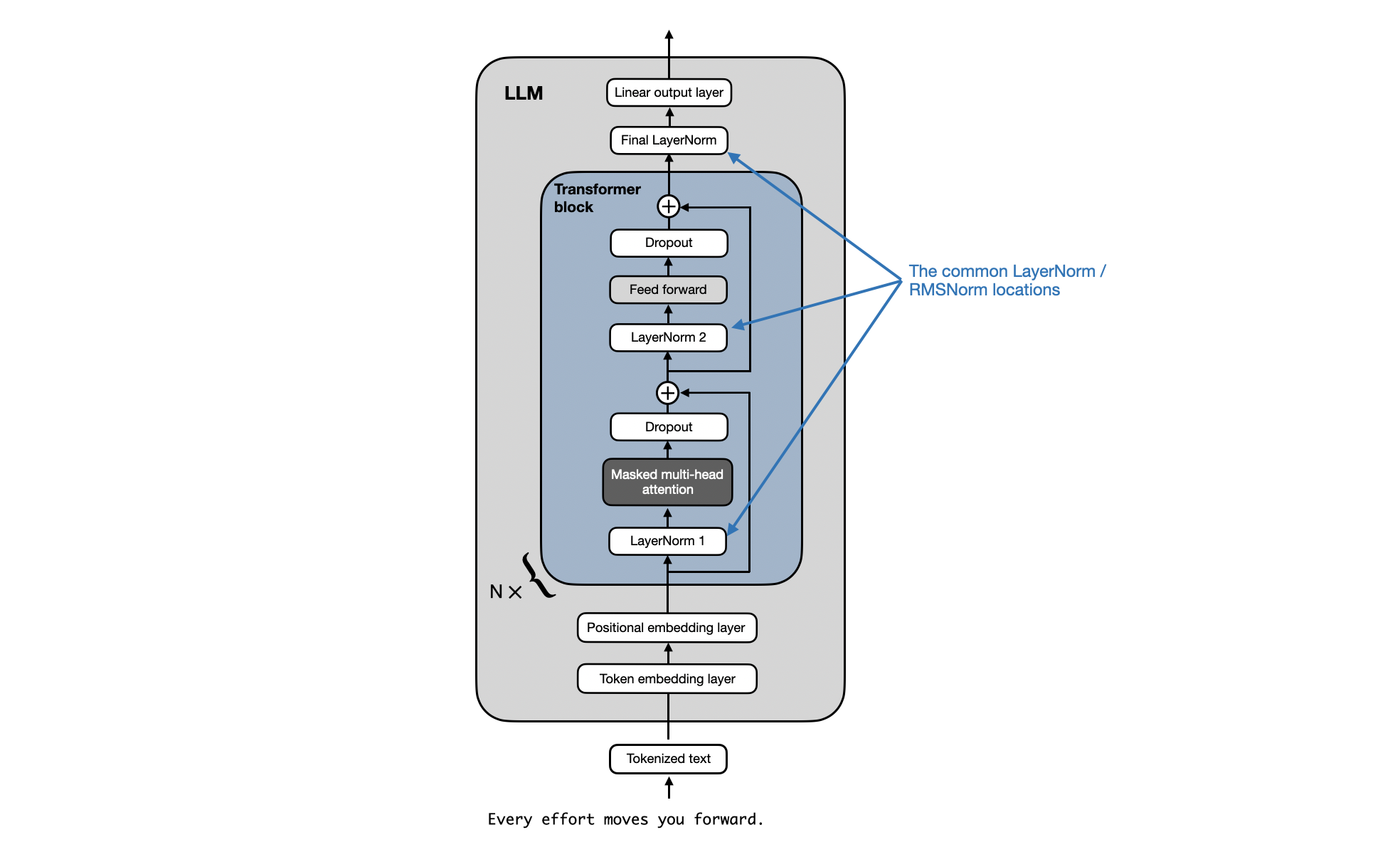
1.2.3 预训练、指令调优、RLHF、监督微调
对于 7B 模型,谷歌在 16 个pod(共计4096 个TPUv5e)上训练模型,他们通过 2 个pod对2B模型进行预训练,总计 512 TPUv5e
在一个 pod 中,谷歌对 7B 模型使用 16 路模型分片和 16 路数据复制,对于 2B 模型,只需使用 256 路数据复制
优化器状态使用类似 ZeRO-3 的技术进一步分片。在 pod 之外,谷歌使用了 Pathways 方法通过数据中心网络执行数据复制还原
- 预训练
Gemma 2B 和 7B 分别在来自网络文档、数学和代码的 2T 和 6T 主要英语数据上进行训练。与 Gemini 不同的是,这些模型不是多模态的,也不是为了在多语言任务中获得最先进的性能而训练的
为了兼容,谷歌使用了 Gemini 的 SentencePiece tokenizer 子集。它可以分割数字,不删除多余的空白,并对未知 token 进行字节级编码 - 指令调优与RLHF
谷歌通过在仅文本、仅英语合成和人类生成的 prompt 响应对的混合数据上进行监督微调即SFT,以及利用在仅英语标记的偏好数据和基于一系列高质量 prompt 的策略上训练的奖励模型进行人类反馈强化学习即RLHF,对 Gemma 2B 和 Gemma 7B 模型进行微调
具体而言 gemma根据基于 LM 的并行评估结果来选择自己的混合数据,以进行监督微调。给定一组留出的(heldout) prompt, 让测试模型生成response,并让基线模型生成相同prompt下的response,然后让规模更大的高性能模型来预测哪个response更符合人类的偏好
第二部分 gemma2
// 待更