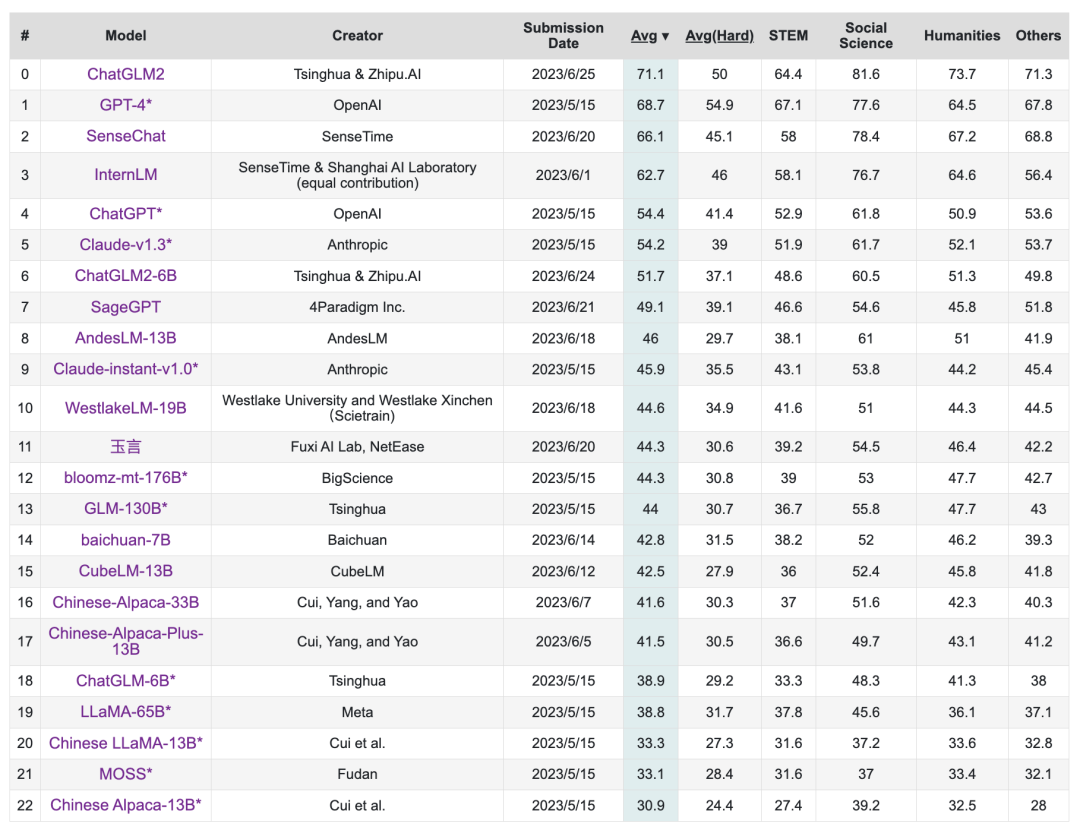
目录
一、引言
二、ChatGLM-6B 模型简介
ChatGLM-6B 的特点
三、DAMODEL 平台部署 ChatGLM-6B
1. 实例创建
2. 模型准备
3. 模型启动
四、通过 Web API 实现本地使用
1. 启动服务
2. 开放端口
3. 使用 PostMan 测试功能
4. 本地代码使用功能
五、总结
一、引言
ChatGLM-6B 作为一款强大的对话语言模型,在丹摩智算平台上的部署和使用能够为开发者和研究者带来诸多便利。
本文将详细介绍 ChatGLM-6B 在丹摩智算平台的部署与使用方法。
ChatGLM-6B 是由清华大学和智谱 AI 开源的一款对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。该模型凭借其强大的语言理解和生成能力、轻量级的参数量以及开源的特性,在学术界和工业界引起了广泛关注。
在人工智能领域,自然语言处理(NLP)技术正迅速发展,其中对话生成模型因其广泛的应用前景而备受关注。ChatGLM-6B 在丹摩智算平台的部署和使用,为开发者和研究者提供了一个强大的工具,可以实现多种对话场景的应用。无论是学术研究还是商业应用,ChatGLM-6B 都将为您的项目带来强大的 NLP 能力。
二、ChatGLM-6B 模型简介
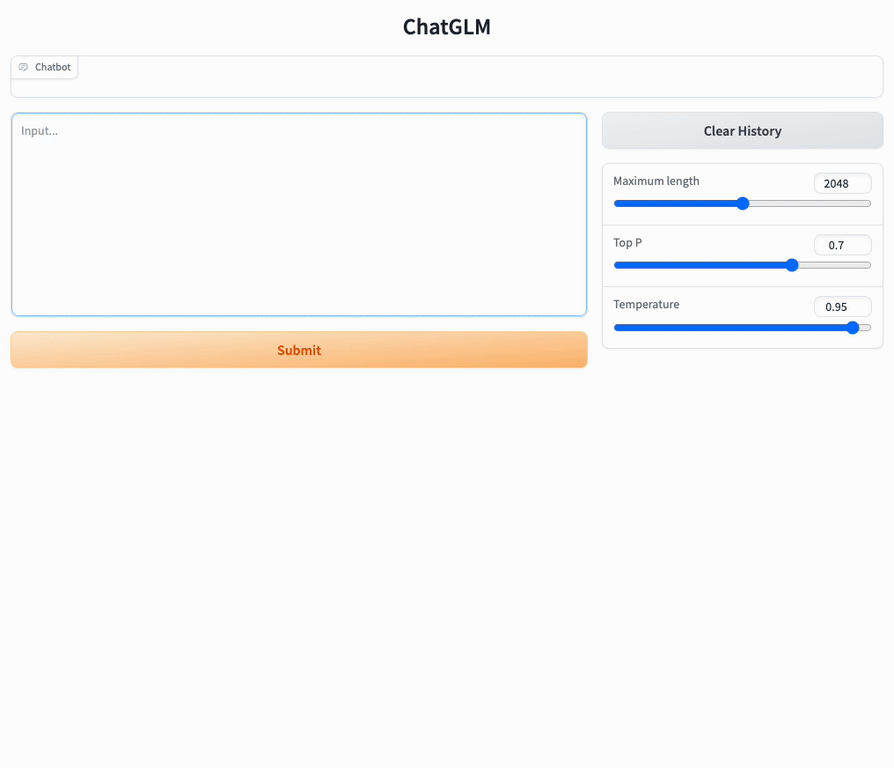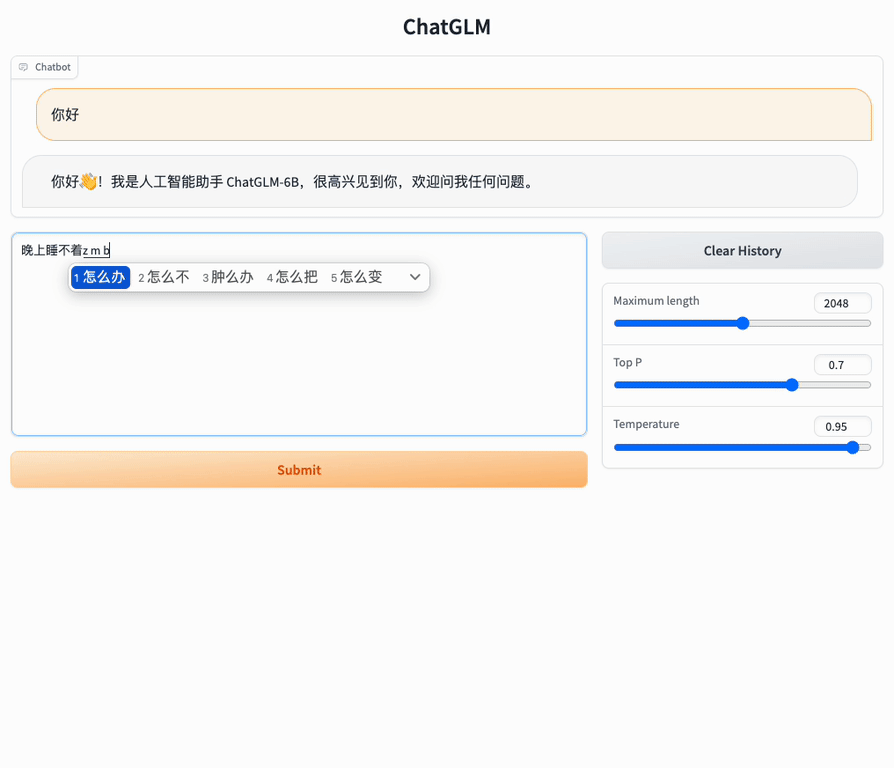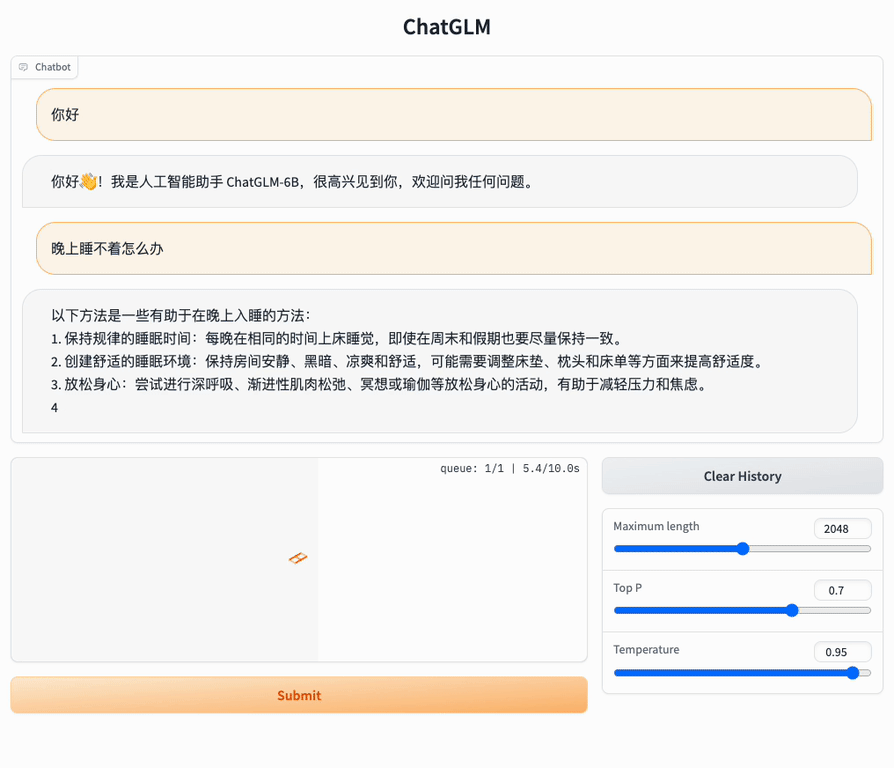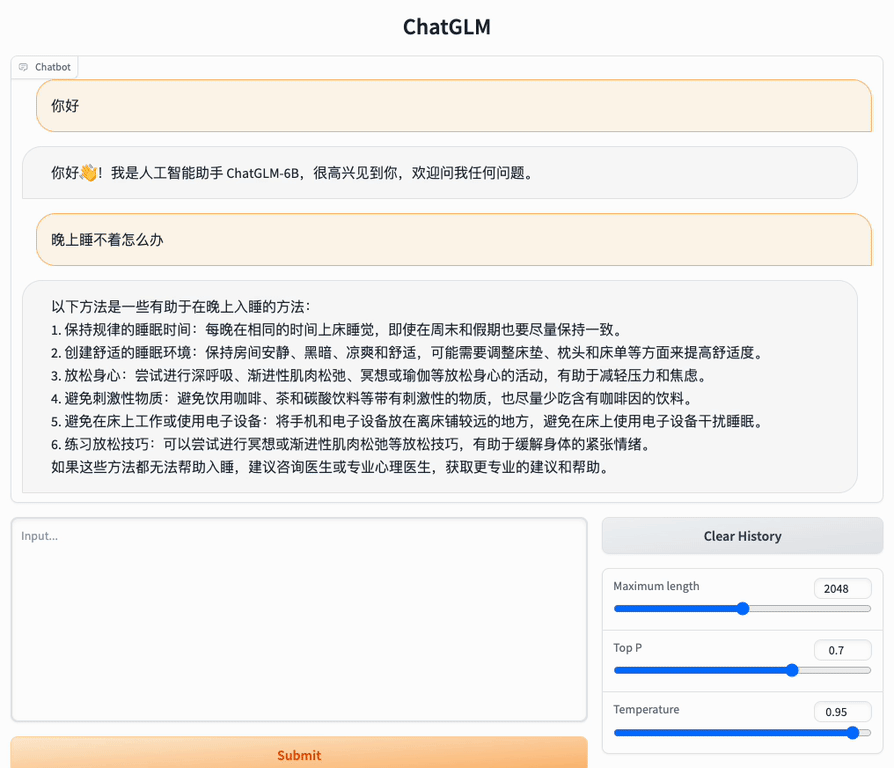
ChatGLM-6B 的特点
1.强大的语言理解与生成能力,能够理解和生成复杂的对话内容。
ChatGLM-6B 是一个基于 General Language Model (GLM) 架构的对话生成模型,具有 62 亿参数。该模型不仅具备优秀的语言理解能力,还能生成连贯、准确的回答,适用于多种对话场景。例如,在与用户的交互中,它能够理解用户的问题,并给出详细且准确的回复。
2.轻量级的参数量,便于部署和应用。
相较于其他大型模型,ChatGLM-6B 具有更少的参数量,便于部署和应用。在 FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8)和 6GB(INT4),使得 ChatGLM-6B 可以部署在消费级显卡上。
3.开源特性,开发者可以自由地使用和修改。
模型的开源特性使得开发者可以自由地使用和修改,以适应特定的应用需求。ChatGLM-6B 的开源地址为 https://github.com/THUDM/ChatGLM-6B。开发者可以根据自己的需求对模型进行微调和部署,为研究和应用开发提供了便利。
三、DAMODEL 平台部署 ChatGLM-6B
1. 实例创建
在丹摩智算平台上部署 ChatGLM-6B 的第一步是创建 GPU 云实例。具体步骤如下:
- 进入 DAMODEL 控制台,选择 “资源 - GPU 云实例”,点击 “创建实例”。

- 在实例配置中,选择付费类型为按量付费,然后选择单卡启动,例如 NVIDIA GeForce RTX 4090。这样的配置能够满足 ChatGLM-6B 的运行需求,该 GPU 型号拥有强大的计算能力和较大的显存,为模型的运行提供了良好的硬件基础。

- 接着配置数据硬盘大小,一般情况下,可以根据实际需求进行选择。这里可以考虑选择一个合适的大小,以确保有足够的空间存储模型文件和相关数据。同时,选择一个合适的启动框架,如 PyTorch 等,为模型的运行提供稳定的软件环境。

2. 模型准备
创建好实例后,就可以开始准备模型了。
- 使用 git 克隆 ChatGLM-6B 项目。如果遇到 GitHub 连接问题,可以选择 gitcode 站点或者离线下载并上传到项目中。例如,可以在终端执行命令cd /home/aistudio/work/git clone GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型成功克隆项目后成功克隆项目后,会显示如下文件夹:

- 进入项目文件夹后,使用 pip 安装项目依赖。执行命令pip install -r requirements.txt,可以看到 DAMODEL 平台环境依赖的下载安装速度非常快。等待片刻,当显示 “Successfully installed” 时,说明依赖安装完成。

- 依赖安装成功后,需要引入模型文件。DAMODEL 平台提供了数据上传功能,用户有 20GB 免费存储空间,该空间被挂载到实例的 /root/shared-storage 目录,跨实例共享。可以先下载 Hugging Face 上的 ChatGLM-6B 预训练模型,也可以进入魔塔社区选择相关文件进行下载。然后将下载下来的模型文件及配置进行上传并解压,上传时尽量保持界面首页显示,等待上传成功后再进行下一步操作。
3. 模型启动
模型文件准备好后,就可以启动模型了。
- 修改 cli_demo.py 和 web_demo.py 文件,将模型加载路径改为本地路径。这样可以确保模型从本地加载而不是通过网络下载,提高模型的启动速度和稳定性。

- 在终端输入python cli_demo.py或python web_demo.py启动模型。cli_demo.py是使用命令行进行交互,用户可以输入文本与模型进行对话,或输入 “clear” 清空对话历史并清除屏幕,或输入 “stop” 退出程序。而web_demo.py是使用本机服务器进行网页交互,但由于 Jupyter 的限制,无法直接打开访问服务器的 127.0.0.1:7860 网页端交互界面,这里可以利用 MobaXterm 建立 ssh 隧道,实现远程端口到本机端口的转发。首先打开 tunneling,新建 SSH 通道,填入 ssh 的相关配置,并将 7860 通道内容转发到本机,点击 start 开始转发,转发成功后,就可以成功在网页与模型进行交互了。

四、通过 Web API 实现本地使用
1. 启动服务
首先,进入 ChatGLM-6B 项目所在的目录,运行 api.py 文件,即可启动 FastAPI 服务。这个服务接收 HTTP POST 请求,请求体包含文本生成所需的参数,如 prompt(提示文本)、history(对话历史)、max_length(生成文本的最大长度)、top_p(采样时的累积概率阈值)和 temperature(采样时的温度参数,影响生成文本的随机性)。在终端中执行以下命令:
cd ChatGLM-6B
python api.py启动成功后,服务器将准备好响应请求。
2. 开放端口
在 DAMODEL 平台上,为了实现本地访问 API 服务,需要开放对应的端口。首先点击访问控制,进入端口开放页面,然后点击添加端口,输入端口号,并点击确定开放。平台会给出访问链接,将其复制以便后续测试和调用。
3. 使用 PostMan 测试功能
打开 PostMan,新建一个 Post 请求,将平台生成的访问链接粘贴到 URL 栏,并在 Body 中填入相应的内容。示例请求体如下:
{
"prompt":"你好,你是谁?",
"max_length":512,
"top_p":0.9,
"temperature":0.7
}点击 send 后,如果显示成功的 response,状态码为 200,则说明 API 服务正常运行。
4. 本地代码使用功能
在本地开发中,可以通过编写代码调用部署好的 API 服务。以下是一个基础的单轮对话功能示例代码:
import requests
import jsonapi_url = "http://your-api-url"
data = {
"prompt":"你好,你是谁?",
"max_length":500,
"top_p":0.9,
"temperature":1.0
}response = requests.post(api_url, json=data)
if response.status_code == 200:result = response.json()print("Response:", result['response'])
else:print("Failed to get response from the API. Status code:", response.status_code)print(response.text)在此基础上,我们可以实现一个基于 ChatGLM-6B 模型的简单对话系统,在本地通过命令行与 DAMODEL 部署好的模型进行交互。多轮对话示例代码如下:
import requests
import jsonapi_url = "http://your-api-url"
conversation_history = []while True:query = input("\n用户:")if query.strip().lower() == "stop":breakprompt = querydata = {"prompt": prompt,"history": conversation_history,"max_length": 5000,"top_p": 0.9,"temperature": 0.9}response = requests.post(api_url, json=data)if response.status_code == 200:result = response.json()print("Response:", result['response'])conversation_history = result['history']else:print("Error:", response.status_code)五、总结
丹摩智算平台为 ChatGLM-6B 的部署和使用提供了强大的支持,使得开发者能够轻松地利用这一先进的语言模型进行各种应用开发。
通过本文的介绍,您可以了解到从实例创建、模型准备到模型启动以及通过 Web API 实现本地使用的全过程。
无论是进行学术研究还是开发商业应用,ChatGLM-6B 与丹摩智算平台的结合都将为您提供强大的自然语言处理能力,帮助您实现更多的创新和价值。
希望本文能为您在使用 ChatGLM-6B 模型时提供有益的参考,让您在人工智能领域的探索中更加顺利。
本文完。