文章目录
- 1 向量数据库技术架构剖析
- 什么是向量数据库
- 向量化表达的好处
- 数据如何检索
- 向量数据库整体架构
- 2 AI大模型离不开向量数据库技术侧剖析
- 大模型的 3 点局限性
- 大模型与向量数据的关系
- 利用向量数据库改进大模型
- 3 利用向量数据库构建企业知识库案例实战
- 构建智能客服整体架构设计
1 向量数据库技术架构剖析
什么是向量数据库
- 关系型数据库:MySQL
- 结构化数据精确匹配
- 非关系型数据库:NoSQL
- 非结构化数据精确匹配
那么,什么是向量数据库?——非结构化数据模糊匹配
- 向量数据库是一种以向量嵌入(高维向量)方式存储和管理费结构化数据的数据库。
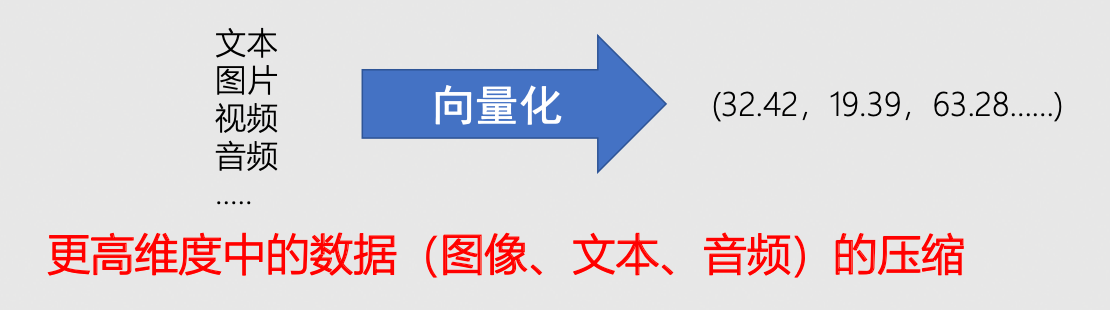
数据如何向量化表达?
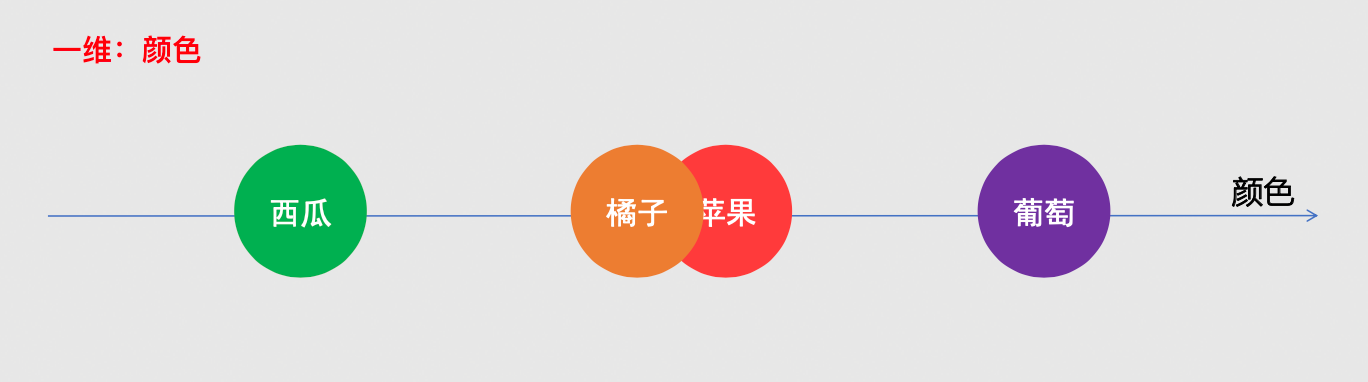


向量化表达的好处
- 图搜图、视频搜索、商品搜索、…
- 文本:相似问题,并找到问题解答
思考:如果把 ChatGPT 的对话(Prompt & Answer)向量化会怎么样?
数据如何检索
- 模糊匹配:从库中搜索和查询向量最为相似的向量
- 相似度计算:
- 夹角(余弦计算)
- 欧式距离
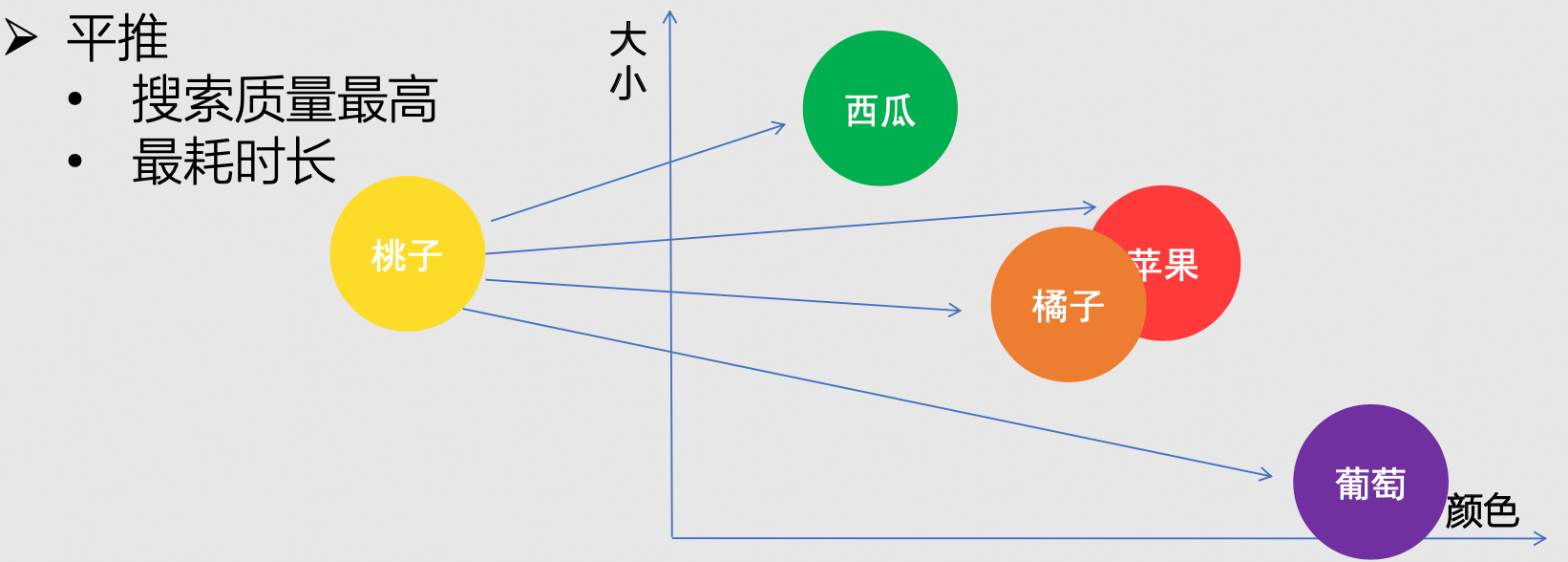
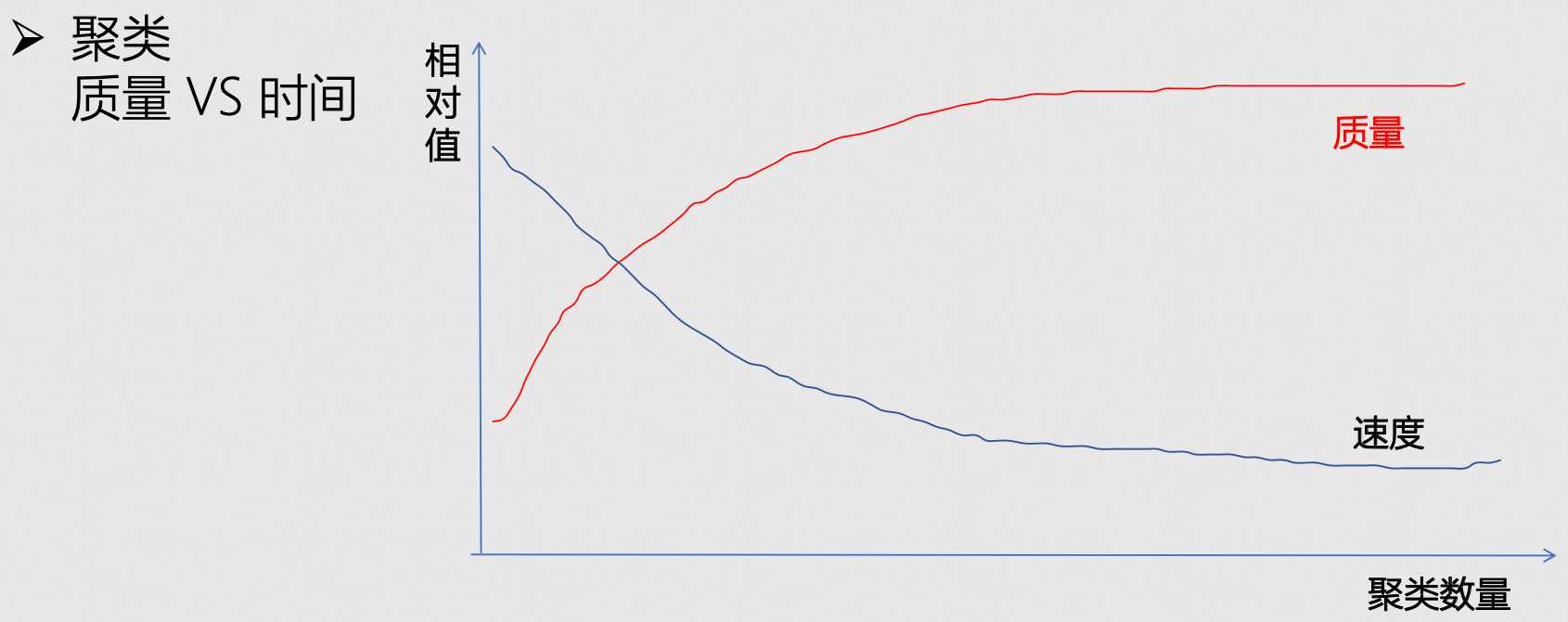
- 方式一:平推
- 搜索质量最高
- 最耗时长
- 方式二:聚类
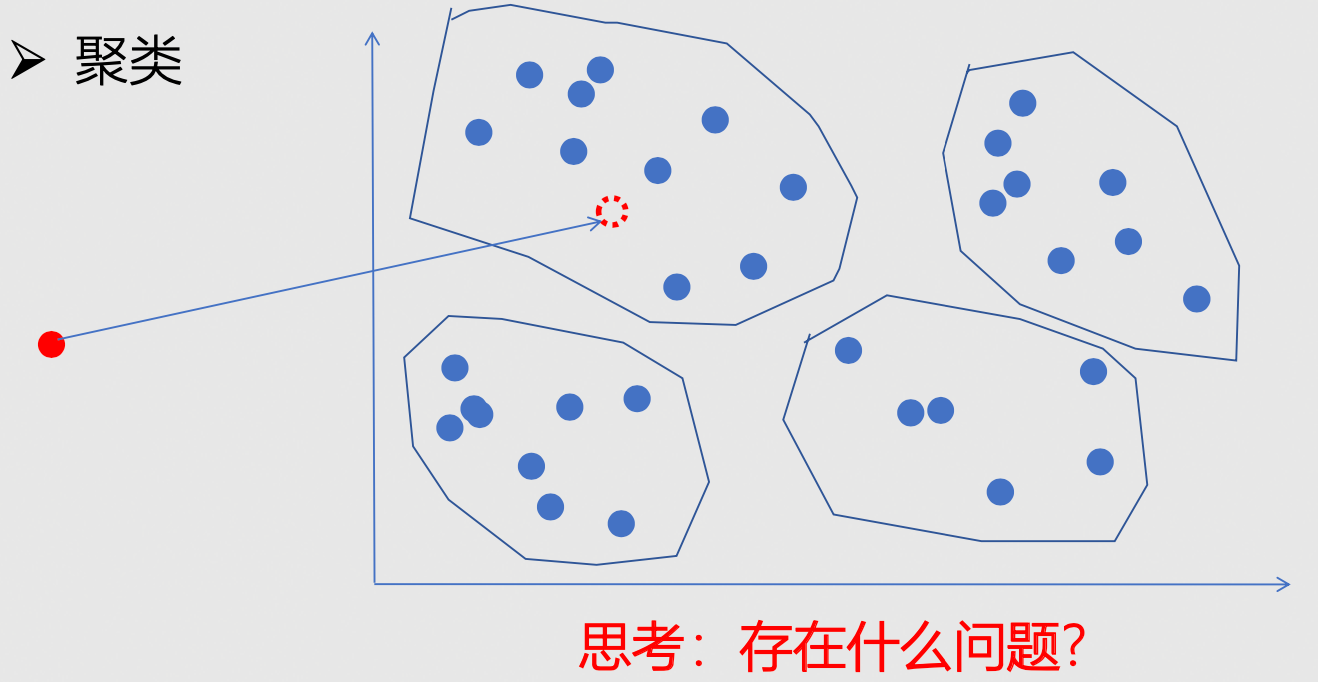
存在的问题?
- 搜索准确度下降
- 与查询向量最近的应该在聚类D里,但结果现在只能返回聚类B中最近的向量
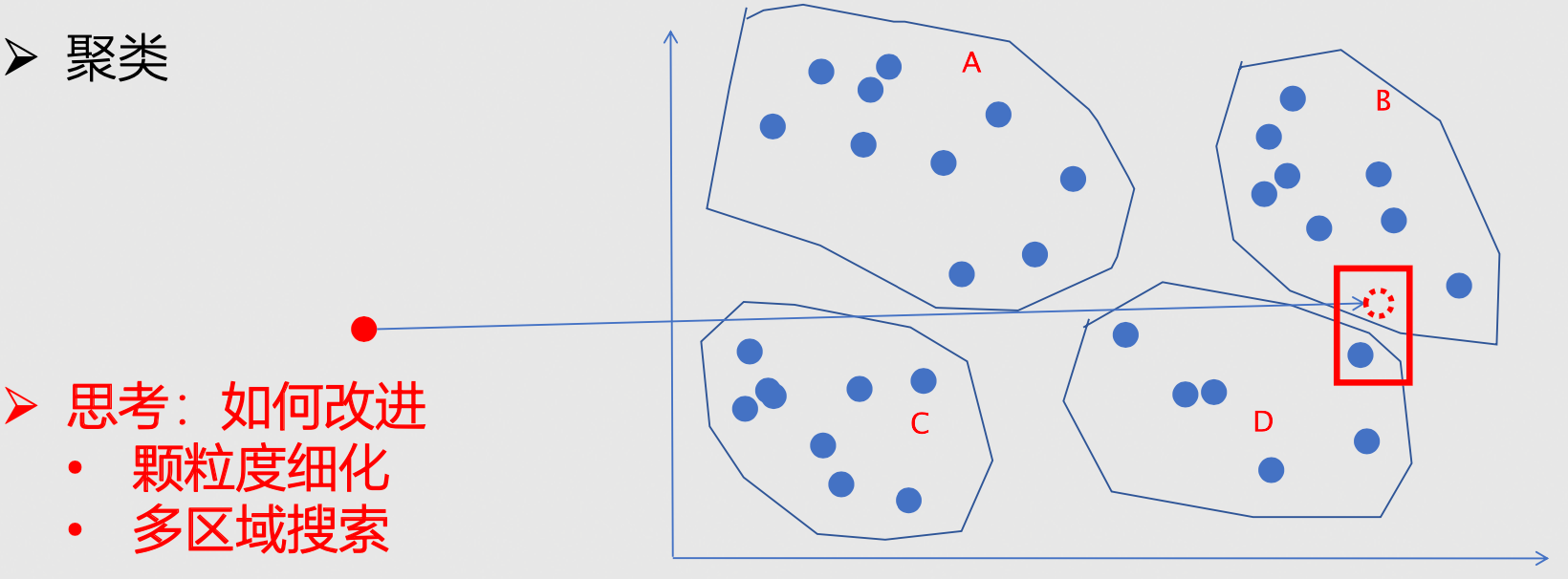
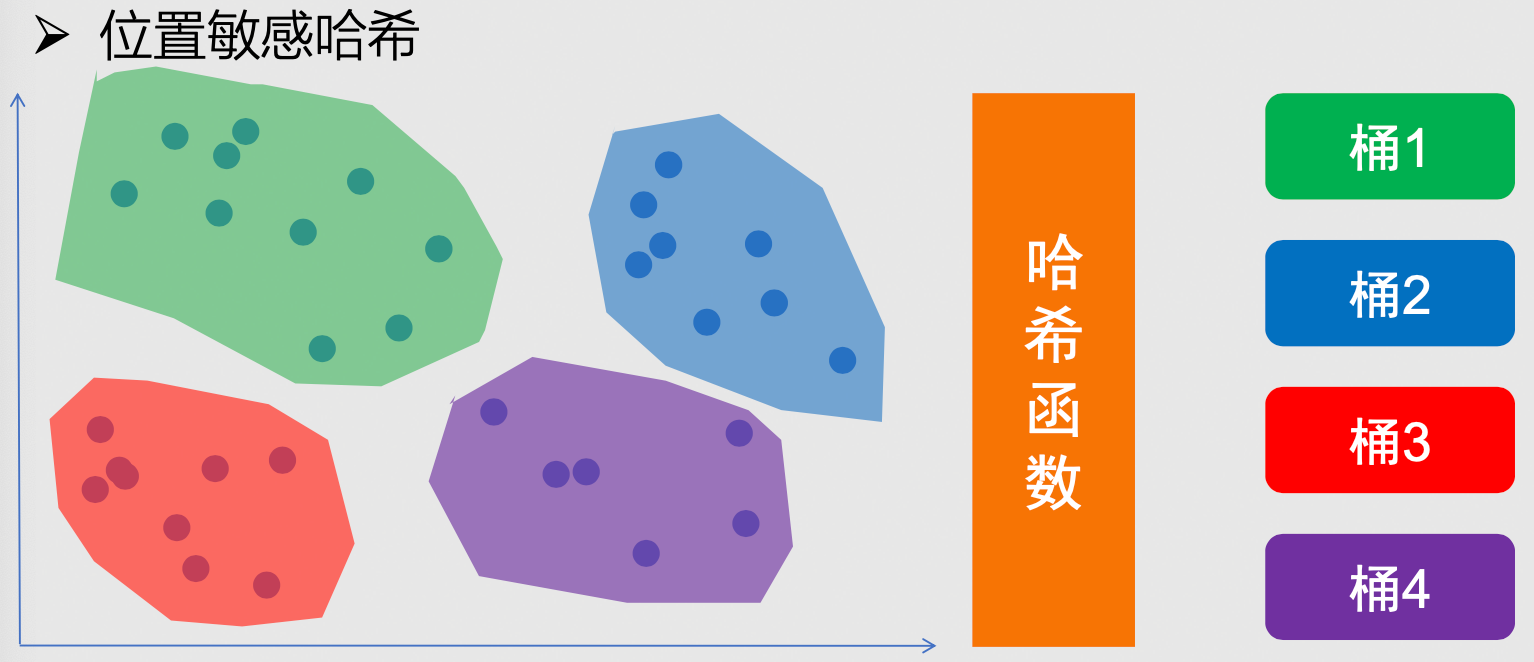
- 方式三:位置敏感哈希

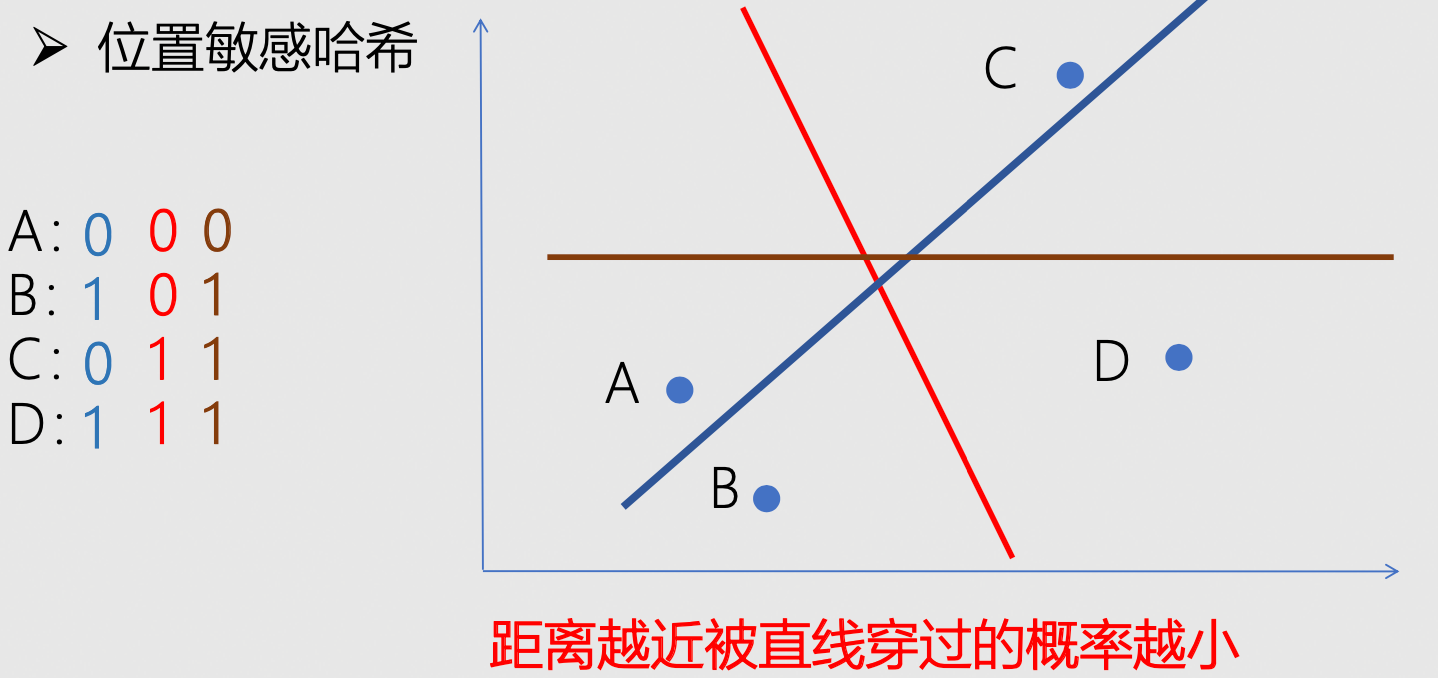
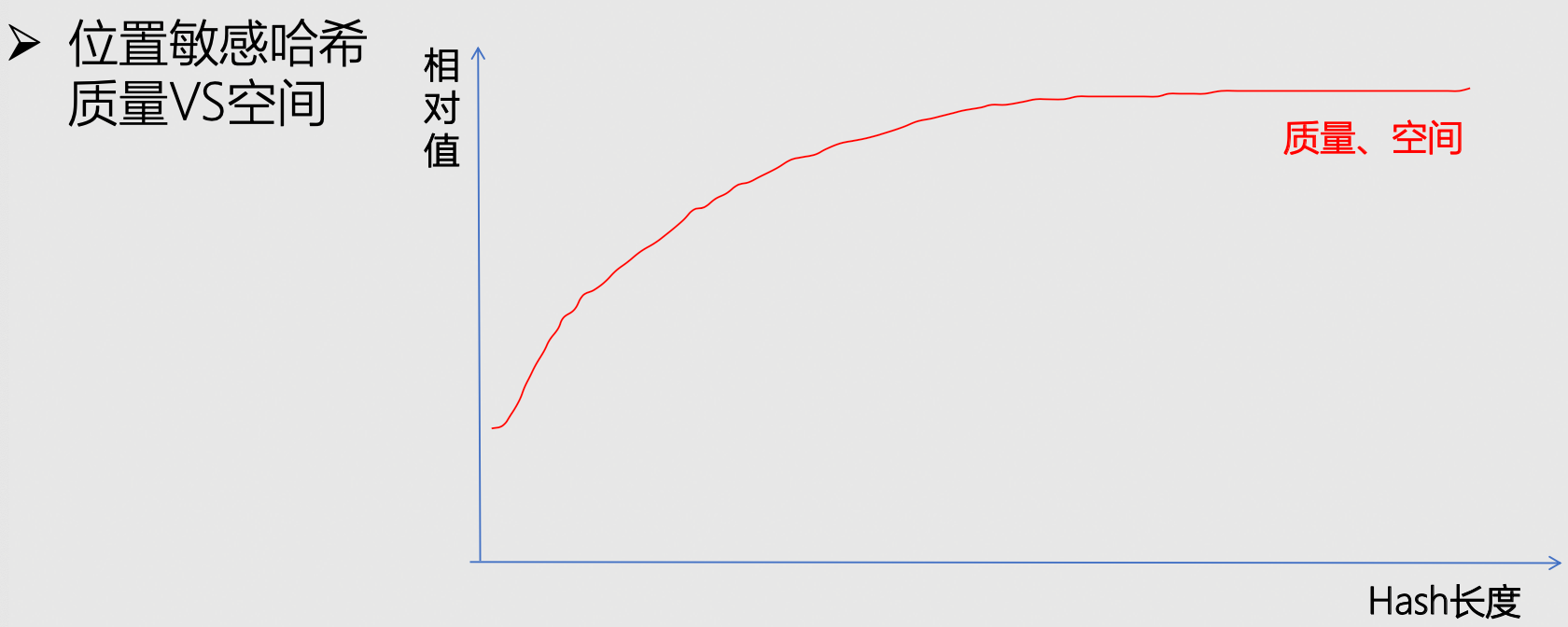
向量数据库整体架构

2 AI大模型离不开向量数据库技术侧剖析
大模型的 3 点局限性
- 缺乏领域特定信息:利用向量数据库建立知识库,扩展LLM的认知边界
- 容易产生幻觉:利用向量数据库投喂知识
- 无法获取最新的信息/知识:利用向量数据库为大模型建立记忆,及时更新
大模型与向量数据的关系

利用向量数据库改进大模型
给大模型构建知识库
- Embedding Model 是将非结构化数据映射到高维空间的工具
- 使用合适的Embedding Model,向量的近似度代表语义的近似度
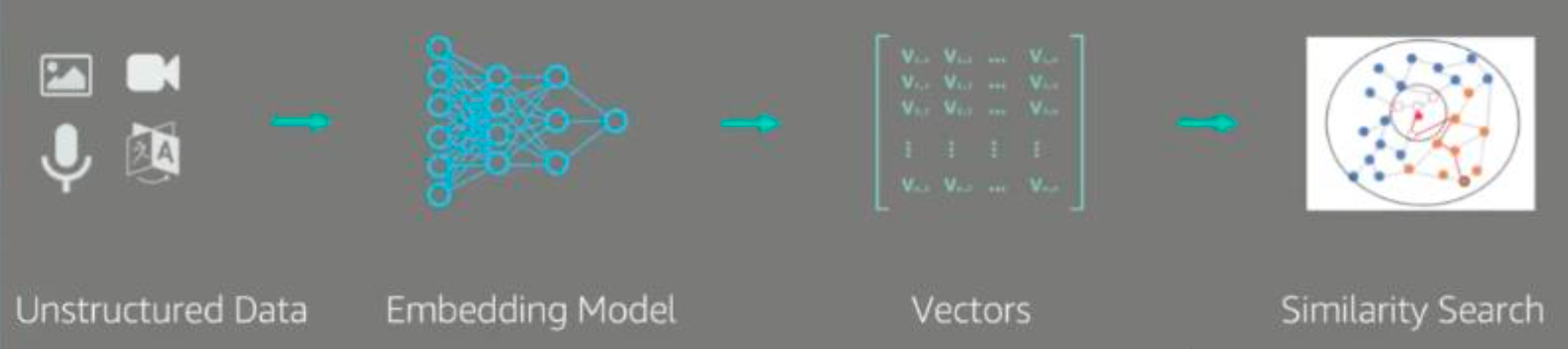
给大模型构建知识库
- 将私有知识库向量化存储
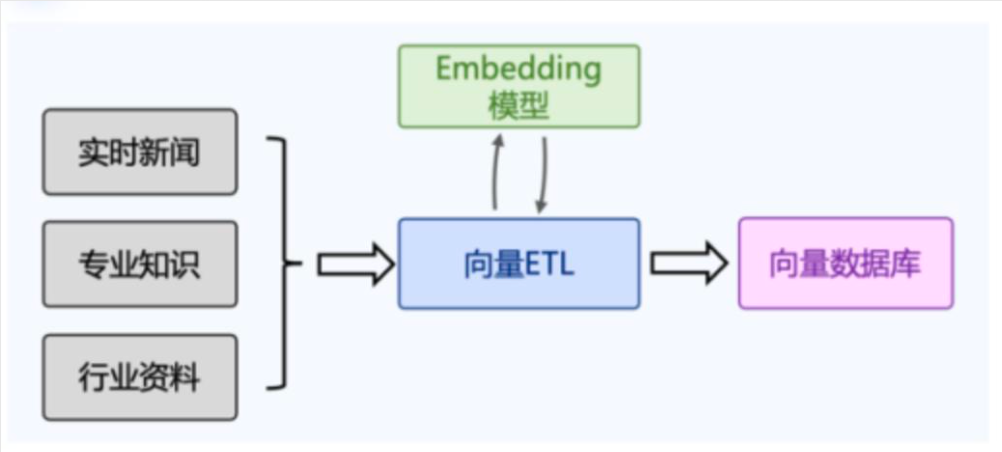
给大模型构建知识库
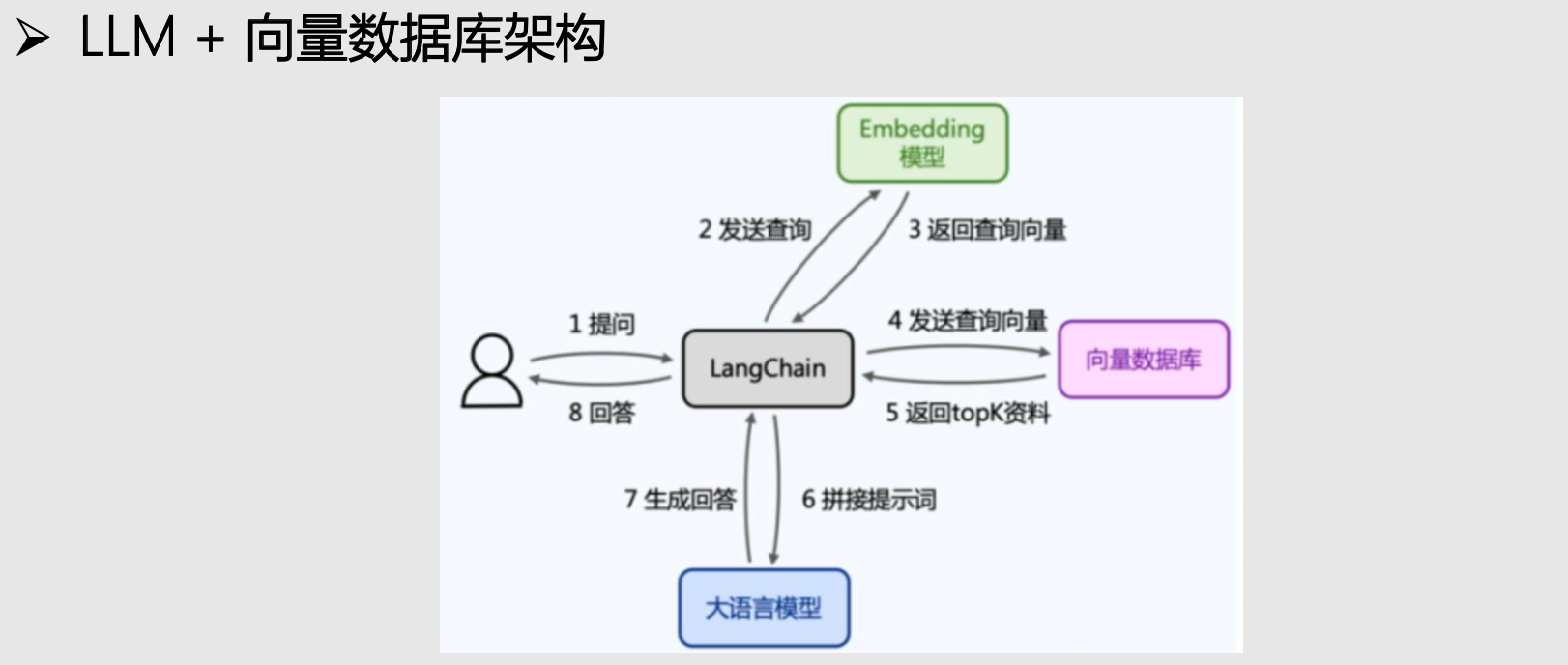
- 文档检索增强:利用提前构建好的知识库,通过检索与 Query 相关的知识片段来增强大模型回答效果
- 容易管理
- 更精确
- 传统优化技术可复用
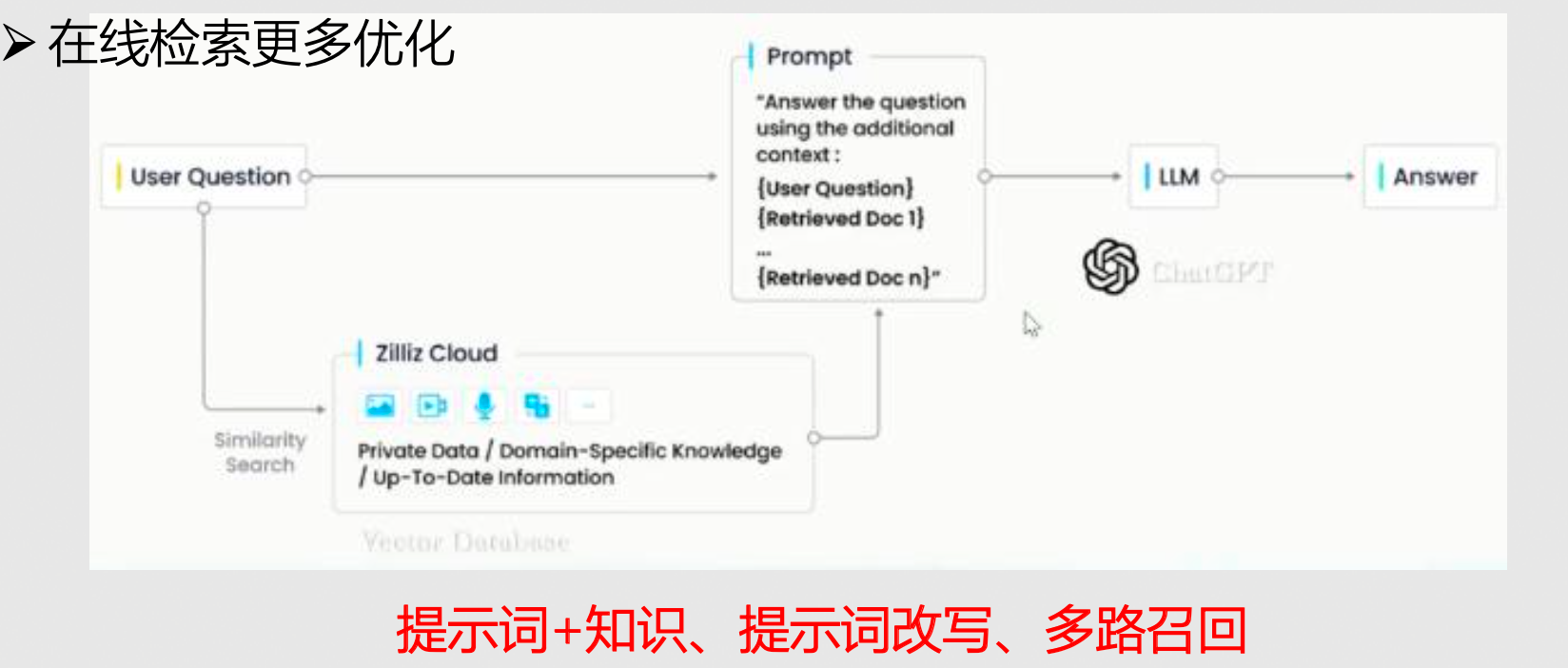
落地中可能遇到的问题
- 查询性能
- 准确度
3 利用向量数据库构建企业知识库案例实战
构建智能客服整体架构设计
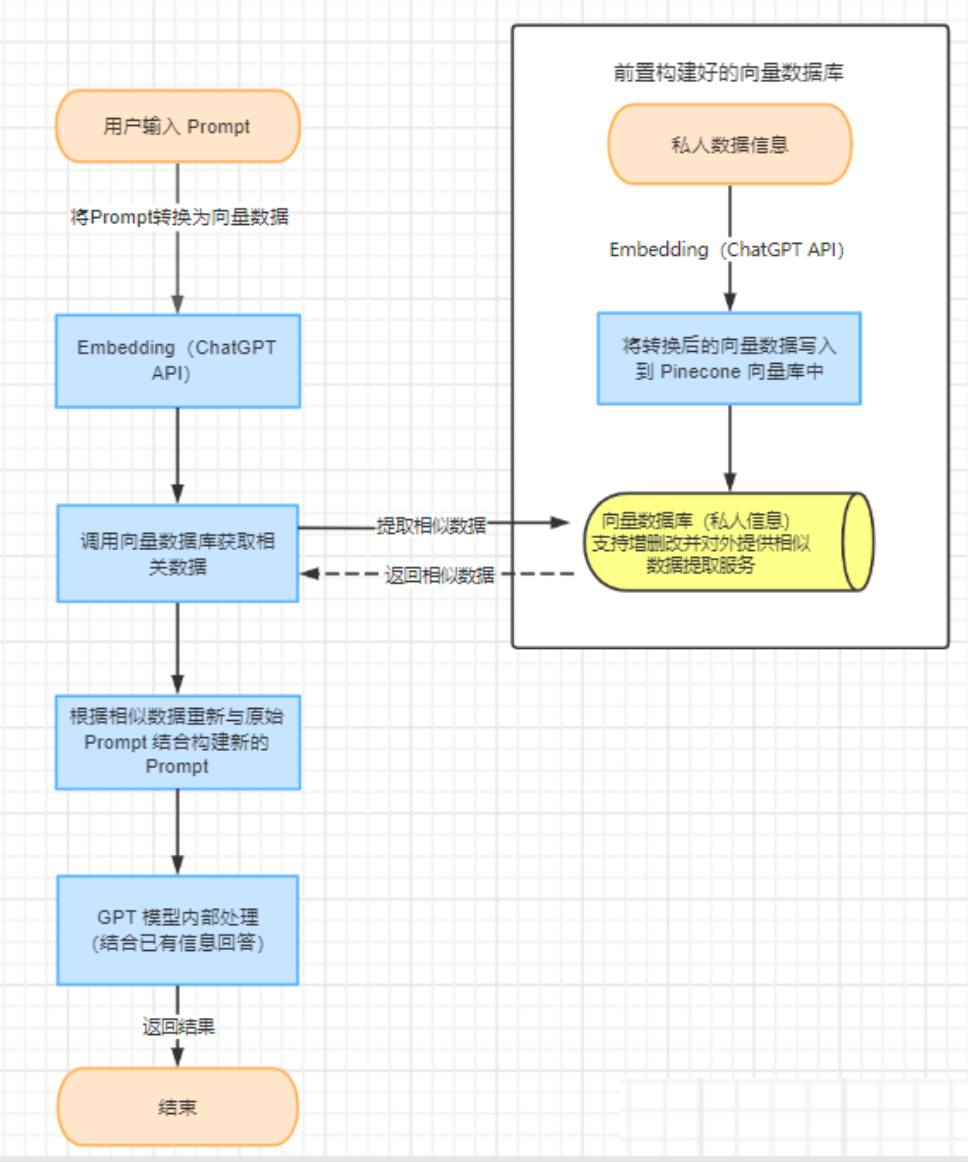
整体流程
- 将私人数据转换为向量数据,并写入到向量数据库中
- 根据 Prompt 从向量数据库中提取相似数据
- 结合相似数据重新组装 Prompt,让 ChatGPT 生成回答
向量数据库选型
- 推荐 Pinecone 向量数据库:https://www.pinecone.io/
- 免费、秒审通过
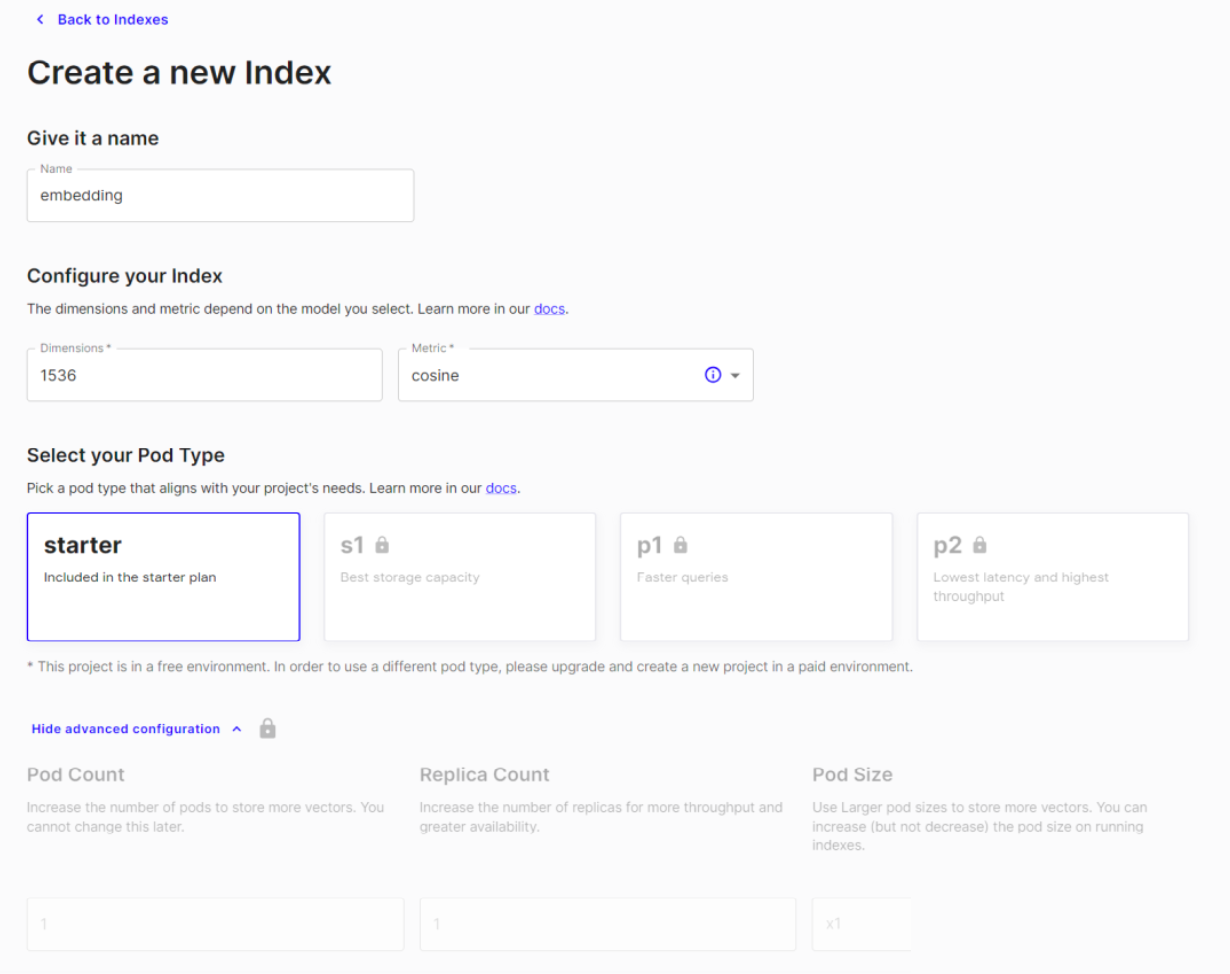
- 核心三个参数
- 索引名称:满足规范
- 特征维度:向量维度,OpenAI转化为 1536 维
- 度量距离指标:提供了 3 种,推荐 cosine
写入向量数据库(离线索引)
- 安装对应的 Python 库:pip install pinecone-client
- 写入新量数据(采用读取文件形式)
- 将所有数据从文档中读取出来
- 通过 OpenAI Embedding 转换为对应的向量化数据
- 将向量化数据存储到 Pinecone 创建的 index 中
- 在 Pinecone 网站查看这份数据
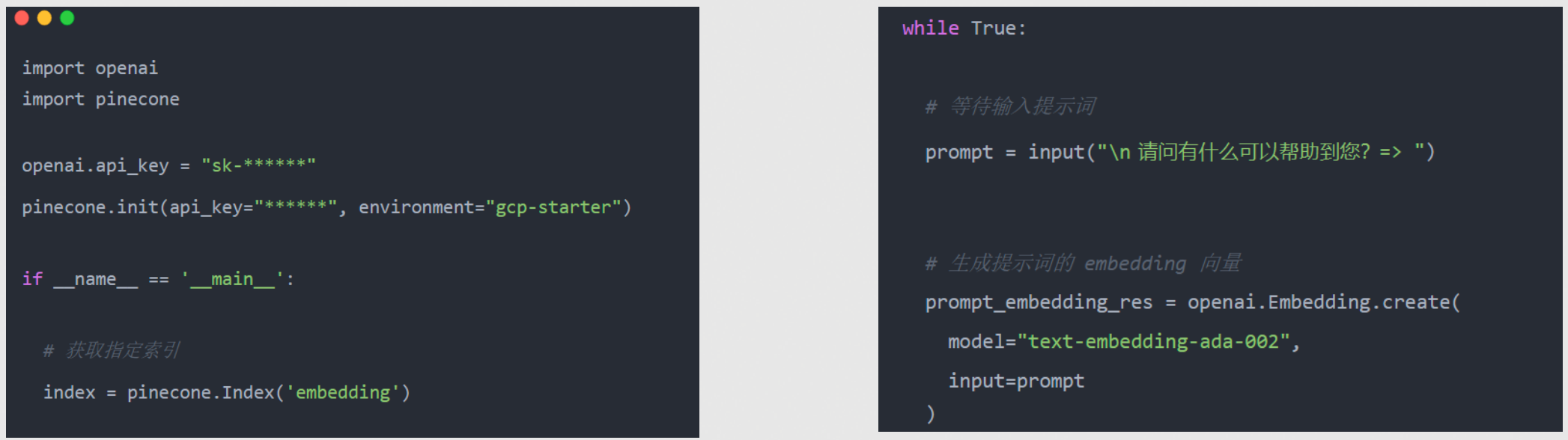
使用向量数据库(在线检索)
- 从 Pinecone 获取指定的索引
- 将 Prompt 转换为向量数据,从向量数据库提取相似数据
- 将提取的数据与 Prompt 重新构建输入,发送给 ChatGPT
- ChatGPT 整理内容后输出结果