简介:本文章要介绍的YOLOv1算法,它与之前的目标检测算法如R-CNN等不同,R-NN等目标检测算法是一种两阶段(two-stage)算法,步骤为先在图片上生成候选框,然后利用分类器对这些候选框进行逐一的判断;而YOLOv1算法是一阶段(one-stage)算法,是一种端到端的算法,它把目标检测看成回归问题,并把图片输入到单一的神经网络,然后就得到了图片中要识别物体的边界框以及分类概率等信息。
在这里就会有疑问了,什么是端到端的算法呢?
就是指输入原始数据,输出的直接就是最后的结果。原来的输入端不是直接的原始数据,而是在原始数据中提取的特征。端到端通过减少人工预处理和后续的一些处理,尽可能地使模型从原始输入到最后的输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
一、论文摘要部分

我们提出了一个新的目标检测方法YOLO。以前的目标检测工作是用分类器进行检测的。相反,本篇文章将目标检测表示为空间分离的边界框和相关的分类概率的回归问题。在一次评估中,使用单个神经网络从整个图像中预测边界框以及分类概率。由于整个的检测管道为单一神经网络,因此可以被优化为直接对端到端的性能检测。
我们的架构非常快。基本的YOLO模型以每秒45帧速度实时处理图像。一个更小版本的网络,快速YOLO,处理速度每秒155帧的同时mAP(mean average precision)可达其它实时探测器的两倍。相比于其它的检测系统,YOLO会产生更多的定位错误,但是不太可能会预测假阳性(比如人脸识别项目时,把鞋子上的图案误认为人脸也对其进行打框)。最后,YOLO学习了目标的非常泛化的表示。当把自然图像泛化到其他领域,像艺术品,它胜过其它检测方法,包括DPM,R-CNN。
二、YOLO模型主要优点
1、总结为:YOLO实现实施目标检测非常快速,不需要复杂的通道。

2、YOLO在进行预测时,对图像做全局预测。YOLO在进行训练和测试时查看的是整个图像,因此
隐式地编码上下文信息关于类别和其外观一样。

3、YOLO学习目标的一般化表示,即相比于其它的目标检测算法,YOLO具有更好的泛化性。

三、Unifed Decetion统一检测(预测阶段)
我们将目标网络的独立部分整合到单个神经网络中。网络使用整个图像特征预测每个边界框。这意味着我们的网络对整张图和图像中的所有目标进行全局推理。YOLO设计可以实现端到端训练和实时的速度,同时保持较高的平均精度。
我们的是系统将输入的图像分成S×S的网络,若果目标的中心落入某个网络单元(grid cell)中,那么该网络单元就会负责检测该目标。
每个网络单元都会预测B个边界框和每个框对应的置信度分数(confidence scores),这些置信度分数反映了该模型对于那个框内是否包含目标,以及它对自己边界框预测的准确度。我们将置信度定义为![]() ,如果该单元不存在目标,则Pr(Object)=0,相应的置信度分数也为0,否则的话为1,我们希望置信度分数等于预测框与真实标签框之间联合部分的交集(IOU)。
,如果该单元不存在目标,则Pr(Object)=0,相应的置信度分数也为0,否则的话为1,我们希望置信度分数等于预测框与真实标签框之间联合部分的交集(IOU)。
每个网格单元还预测了C类的条件概率,Pr(Classi|Object)。这些概率是以包含目标的网格单元为条件的。我们只预测每个网格单元的一组类别概率,而不考虑框B的数量。
在测试时,我们将条件类概率和单个框的置信度预测相乘:
![]()
这给我们提供了每个框的特定类别的置信度分数,这些分数既是对该类出现在框里的编码,又是对预测的框与目标匹配程度的编码。
思想
我们的系统把输入图像划分为S×S的网格,对于每个网格单元(grid cell),会预测B个边界框,每个框均有一个置信度分数,对于这些框要求生成框的中心点需要在grid cell内。
详细介绍
对于每个边界框由5个预测组成:x, y, w, h, confidence。
1、x, y代表的是边界框(bounding box)的预测框中心坐标相对于其所在的网格左上角的偏移量,取值范围在0-1之间。

如图5所示,绿色虚线框覆盖掉黑色网格的代表grid cell,坐标代表该grid cell的左上角坐标为(0,0);红色和蓝色框分别代表该grid cell所包含的两个bounding box,红色和蓝色分别表示这两个bounding box的中心坐标。有一点很重要,bounding box的中心坐标一定要在该grid cell的内部,因此红色和蓝色坐标可以归一化为0-1之间,分别以(0.5,0.5)和(0.9,0.9)为例。
2、w, h分别指的是该bounding box的宽和高,表示相比于原始图像的宽和高(448*448像素),但也归一化到了0-1之间,若该像素宽和高分别为44.8和44.8,则归一化之后为w=h=0.1。
所以,对于当前的红色框,其对应的x = 0.8,y = 0.5,w = 0.1,h = 0.2。

3、对于每个网格(grid cell),不管有多少个Bounding(B),都只负责预测一个目标,预测C个条件概率的类别(物体属于每一种类别的可能性)。综上,如图7所示,每个图像有S×S个网格,每个网格要预测B个Bounding box,且每个框要有5个参数,同时还要预测C个类别的可能性,合并这些就是一个张量(S × S × (B * 5 + C))。

四、网络设计(design network)
我们将此模型作为卷积神经网络来实现,并在Pascal VOC检测数据集[9]上进行评估。网络的初始卷积层从图像中提取特征,而全连接层负责预测输出概率和坐标。
YOLO V1有24层卷积层,后面是2个全连接层;一些卷积层交替使用1x1的reduction层以减少特征图的深度。对于最后一个卷积层,它的输出为一个形状为(7, 7, 1024)的tensor,然后tensor展开,使用2个全连接层作为线性回归的形式,全连接层最后一层的输出为7*7*30的参数量,然后reshape为一个(7,7,30)的张量Tensor,也就是说YOLO V1的网络结构对于一张图像的检测最终输出的是一个7*7*30的 Tensor 张量,其中Tensor包括 SxSx(Bx5+C),B表示每个网格单元使用的边界框数目,C表示数据集中要分类的类别概率的数目,针对论文中提出的每个输入图像别分为7x7的网格,每个网格使用2个边界框去检测目标物体,同时针对Pascal voc数据集的类别数目为20。
网络中的激活函数皆选择的Leaky Relu激活函数,避免了Relu激活函数带来的Dead Area的情况出现,同时在大于0的区间达到了Relu的同等效果,可以使得网络很快的收敛,也很好的避免了梯度的消失。
网络中更多的使用了1x1和3x3的小卷积核,避免了大卷积带来的巨大的参数数目,加快了网络的训练,同时也使得预测的速度得到了大大的提升。
YOLOv1的基本网络架构图:

五、损失函数
目标检测的损失函数主要是由三部分组成,分别为分类损失、定位损失、边界框置信度损失。
1、分类损失
若检测到目标,则每个单元格的分类损失是每个类别的条件类别概率的平方误差:
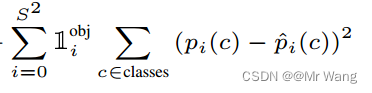
其中,![]() 表示是否目标出现在单元(cell)i中,pi(c)表示为第i个网格分类的概率,
表示是否目标出现在单元(cell)i中,pi(c)表示为第i个网格分类的概率,![]() 表示网格i中出现c类的概率。
表示网格i中出现c类的概率。
2、定位损失
定位损失测量预测的边界框位置和大小的误差,并且只计算负责检测的边界框。

其中,![]() 表示第i个网格中第j个边界框预测其是否负责相关检测;(xi,yi,wi,hi)中的(x,y)表示第i个网格单元中框的中心位置坐标,(w, h)则表示边界框的宽度和高度。
表示第i个网格中第j个边界框预测其是否负责相关检测;(xi,yi,wi,hi)中的(x,y)表示第i个网格单元中框的中心位置坐标,(w, h)则表示边界框的宽度和高度。
此外,在每张图像中,许多网格单元不包含任何对象。这使得这些单元格的“置信度”得分趋近于零,往往压倒了包含对象的单元格的梯度。这可能导致模型不稳定,导致训练在早期出现分歧。
为了解决这个问题,我们增加了边界框坐标预测的损失,减少了不包含对象的框的置信度预测的损失。我们使用两个参数,λcoord和λnoobj来实现这一点。设λcoord = 5, λnoobj =0.5。
3、边界框置信度损失
如果在框中检测到目标,则置信度损失为下面两个式子中的上者,若在框中未检测到目标,则置信度损失为下者。

综上,最后YOLOv1算法的总损失为三部分的总和。
Reference
[1]http://t.csdnimg.cn/KIqRm
http://t.csdnimg.cn/KIqRm 论文
[2]http://t.csdnimg.cn/KIqRm