Prompts输入大模型应用后,下一个重要的处理组件就是LLM或者Chat Model,在这里大模型根据提示语产生相应内容,本章主要介绍LLM。
LangChain不定义自己的LLMs,但是它提供标准接口。由其他的LLM提供商(比如OpenAI、Cohere、Hugging Face等)实现底层细节,LangChain设计的一系列标准化接口用于上层对这些LLM的调用和交互。
LLM的基本使用
LLM各个版本都是BaseLLM的子类,后者又是Runnable的后代,所以各个LLMs都是Runnable接口的实现。这既意味着各LLMs实现支持invoke/ainvoke,stream/astream,batch/abatch等调用(具体支持Runnable接口哪些方法可以查看这里的表格内容),也说明它可以使用LCEL语法。下面看简单示例:
from langchain_community.llms import Ollamallm = Ollama(model="llama3", temperature=0)print(llm.invoke("tell me a joke about bear."))打印LLM的返回:

自定义LLM
当我们需要封装自己的LLM类时,或者将LangChain支持的LLM进行其他不同的行为封装,这时候我们可以自定义LLM,以便使用自己的LLM的同时享受LangChain框架带来的便利。
实现自己的LLM,以下2个方法必须实现:
- _llm_type: 返回属性字符串,可以用在记录日志。
- _call: 供invoke方法使用,底层大模型的封装。接受的参数有:
- prompt:用于生成内容的提示。
- stop:生成时的停用词。模型的输出在首次出现停用子字符串时被截断,如果不支持停用词,建议抛出异常NotImplementedError。
- run_manager:回调管理器。
- **kwargs: 任意额外的关键字参数。这些通常传递给模型提供商的API调用。
from typing import Any, List, Optionalfrom langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLMclass CustomLLM(LLM):def _call(self,prompt: str,stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> str:if stop is not None:raise NotImplementedError("stop kwargs are not permitted.")return "Yeh! I know everything, but I don't want to tell you!"@propertydef _llm_type(self) -> str:return "my-custom-llm"llm = CustomLLM()
print(llm.invoke("Tell me a joke about bear"))
然后执行脚本,发现这是个很拽的LLM ^_^!

一些可选的实现接口方法:
- _acall:与_call类似,异步版,供ainvoke调用。
- _stream:逐个token地流式输出。
- _astream:stream的异步版。
- _identifying_params:@property修饰的属性,用于帮助识别模型并打印LLM,应返回一个字典。
缓存(Caching)
缓存技术应用广泛,其主要目的是提升响应速度。缓存了已知结果的数据,当下一次再查询时直接返回缓存里的内容,不经可以提升用户体验,还能节省api调用和token流量费用。
通过langchain.globals中的set_llm_cache方法将InMemoryCache对象实例保存在langchain的全局LLM缓存中。当每次通过LLM发送请求时langchain会查询全局缓存是否已有对应输入的缓存结果。如有,则将缓存的结果返回;否则调用LLM接口,并将结果缓存(LangChain代码看这里)。
import timefrom langchain.globals import set_llm_cache
from langchain_community.llms import Ollama
from langchain_community.cache import InMemoryCachellm = Ollama(model="llama3", temperature=0)# 设置缓存
set_llm_cache(InMemoryCache())start1 = time.time()
print(llm.invoke("Tell me a joke"))
print("elapsed time: ", time.time()-start1)start2 = time.time()
print(llm.invoke("Tell me a joke"))
print("elapsed time: ", time.time()-start2)上面代码中set_llm_cache(InMemoryCache())即完成了缓存设置。运行结果如下,可以看出第二次使用了缓存结果,时间大大缩短:

如果注释掉上面代码中的这句:set_llm_cache(InMemoryCache()),则可以发现两次调用时间相当:
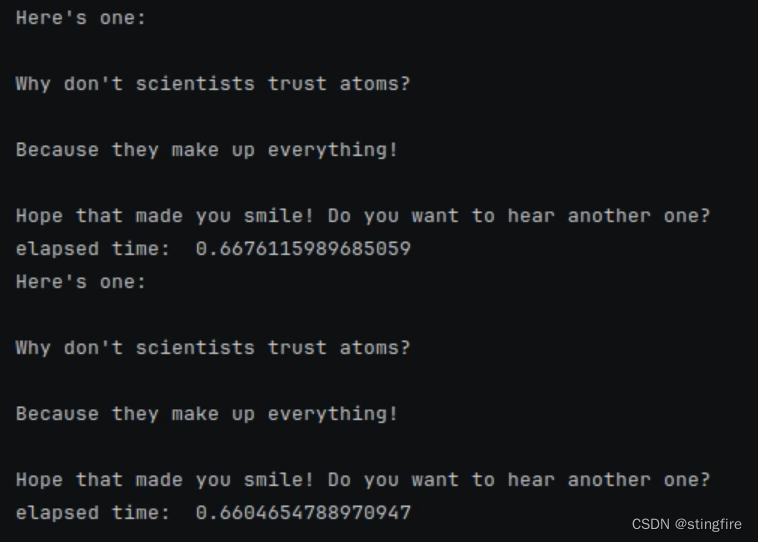
如果不用内存Cache,而是使用SQLite作为后台缓存,只要将前面的set_llm_cache(InMemoryCache())改为即可:
set_llm_cache(SQLiteCache(database_path=".langchain.db"))