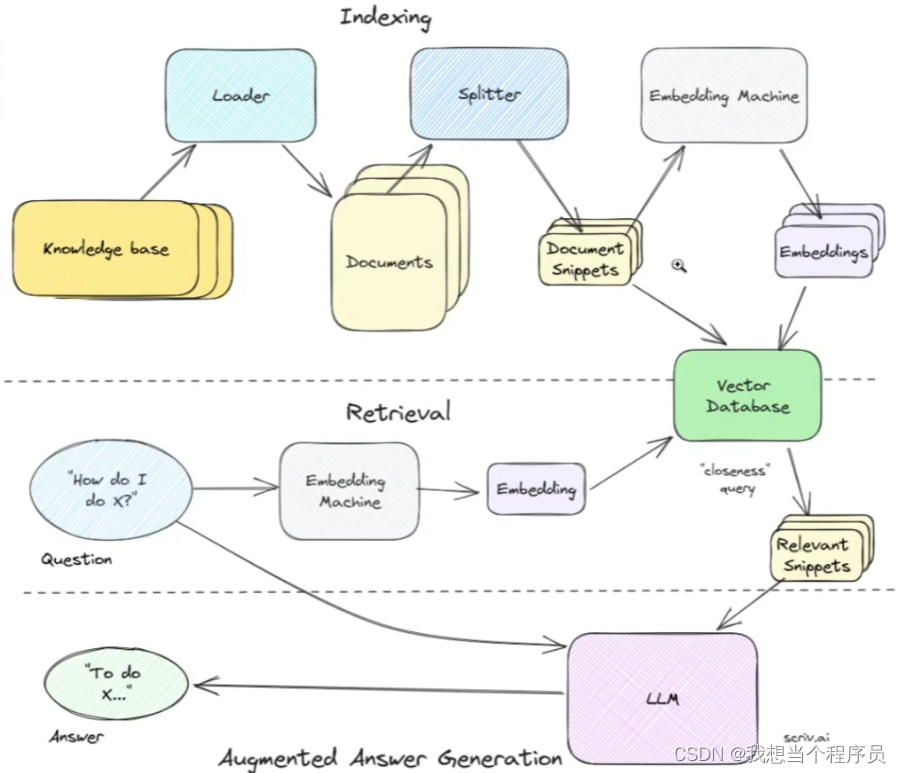
RAG的基本流程:
- 用一个loader把knowledge base里的知识做成一个个的document,然后把document切分成snippets,把snippets通过embedding(比如openai的embedding模型或者huggingface的)向量化,存储到vectordb向量数据库,以供后续相关性检索。至此便完成了私域数据集的索引indexing。
- 第二部分是retrieval检索,主要是先把自己的问题query向量化,然后在vectordb中进行相似度检索,得到相关的snippets。
- 最后一部分是把原问题和相关的snippets拼合起来组成prompt,一起送到LLM中,从而得到最想要的答案。
下面用notebook来做一个小demo:
from langchain.chat_models import ChatOpenAI
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessagechat = ChatOpenAI(model='deepseek-chat',openai_api_key="sk-f8f1fab675ea4d2d9e565877d354d464",openai_api_base='https://api.deepseek.com',max_tokens=1024
)
from langchain.schema import(SystemMessage,HumanMessage,AIMessage
)messages = [SystemMessage(content="You are a helpful assistant."),HumanMessage(content="Do you know GPT-4?")
]
res = chat(messages=messages)
print(res.content)
创建一个RAG对话模型
1.加载数据(以GPT-4论文为例)
! pip install pypdf #一个pdf解析器
from langchain.document_loaders import PyPDFLoaderloader = PyPDFLoader("https://arxiv.org/pdf/2303.08774")pages = loader.load_and_split()
pages[0]
2.知识切片 将文档分割成均匀的块,每个块是一段原始文本
from langchain.text_splitter import RecursiveCharacterTextSplittertext_spliter = RecursiveCharacterTextSplitter(chunk_size = 500, #最大500为一段chunk_overlap = 50 #最多重叠50
)
docs = text_spliter.split_documents(pages)
len(docs)
3.用embedding模型把切片向量化,存储到向量数据库中,方便下次问问题的时候进行相关性检索
from langchain.embeddings.openai import OpenAIEmbeddings #embedding模型用的openai的达芬奇模型,收费且deepseek没有开发,所以不用
#! pip install sentence-transformers #我们用免费的sentence-transformers
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma #向量库chromamodel_name = '.cache/huggingface/hub/models--sentence-transformers--sentence-t5-large/snapshots/7f77100e0c564a5c2faeebd3cac0e5c1771b257e'
embedding = HuggingFaceEmbeddings(model_name=model_name)
vectorstore_hf = Chroma.from_documents(documents=docs, embedding=embedding,collection_name="test_LangchainRAG_hf_embed")
4.通过向量相似度检索和问题最相关的k个文档
query = "How large is GPT-4 vocabulary"
result = vectorstore_hf.similarity_search(query=query, k=2)
5.原始query和检索得到的文本组合起来输入语言模型,得到最终的输出
def augment_prompt(query: str):#获取top3的文本片段result3 = vectorstore_hf.similarity_search(query=query,k=3)source_knowledge = "\n".join([x.page_content for x in result3])#构建prompt#这里是一个f-string的用法,允许在字符串中嵌入表达式,运行的时候表达式会被其value代替augment_prompt = f"""Using the contexts below, answer the query. contexts:{source_knowledge}query: {query}"""return augment_prompt
print(augment_prompt(query))
#创建prompt
prompt = HumanMessage(content=augment_prompt(query=query)
)messages.append(prompt)
res_afteraug = chat(messages=messages)
print(res.content)