今天给大家介绍一个超强的开源OCR工具Surya,目前GitHub收藏人数超过1万。 Surya以具有普遍视野的印度教太阳神命名。新版本的Surya使用了新的架构,性能优于当前的SoTA开源模型 Table Transformer。
主要功能包括
-
识别表格行、列和单元格和具体的字符
-
识别复杂的布局(标题、图像等等)和旋转的表格(图2)
-
支持包括中文在内的90多种语言
-
可在本地运行,提供API
该模型是从头开始训练的,可用于商业用途。但如果你的公司收入或筹集资金超过500万美元,则会受到一些限制。
相关链接
-
代码链接:https://github.com/VikParuchuri/surya
- 托管API:https://www.datalab.to/
-
适用于 PDF、图像、Word 文档和 Powerpoint
-
一致的速度,无延迟峰值
-
高可靠性和正常运行时间
-
效果展示
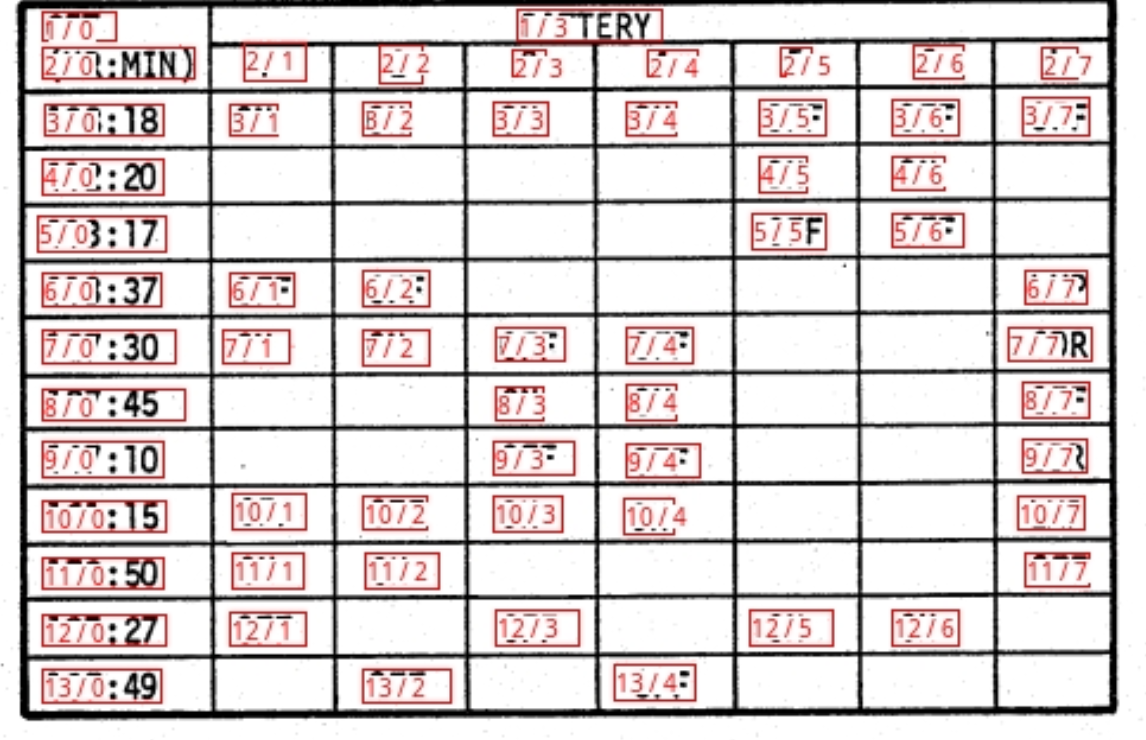
检测

光学字符识别

布局

阅读顺序

表格识别
基准测试
光学字符识别
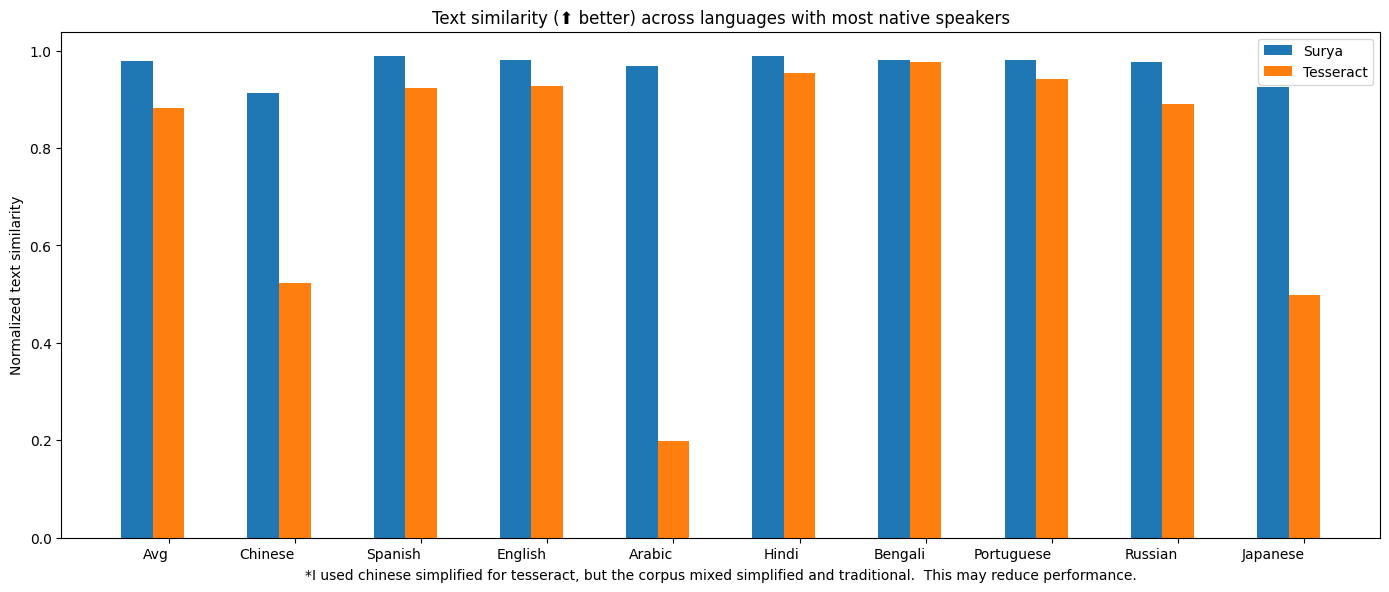
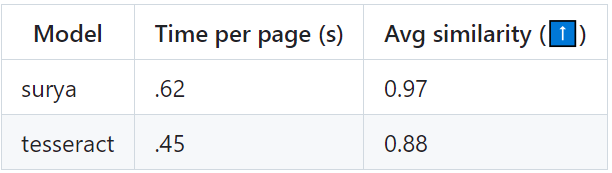
Google Cloud Vision
将OCR与Google Cloud vision进行了基准测试,因为它的语言覆盖范围与Surya相似。

使用了 tesseract 和 surya 的 PDF 中的参考线 bbox,来评估 OCR 质量。对于 Google Cloud,将 Google Cloud 的输出与真实情况进行了调整。我不得不跳过 RTL 语言,因为它们不能很好地对齐。
文本行检测
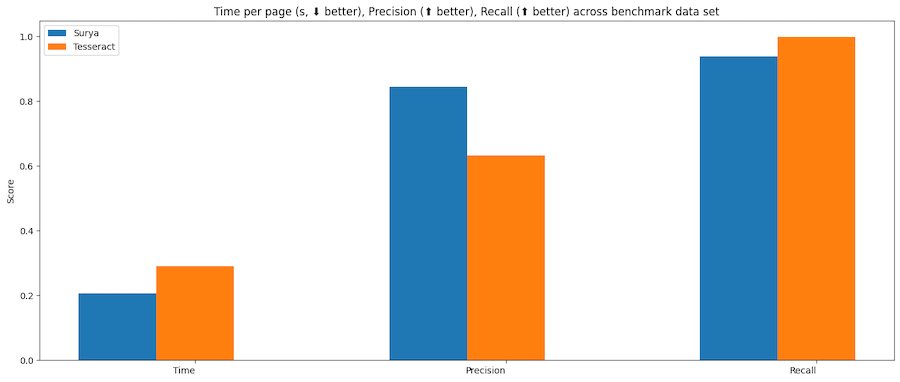
Tesseract是基于CPU的,surya是CPU或GPU。在配备 A10 GPU 和 32 核 CPU 的系统上运行了基准测试。
-
tesseract - 32 个 CPU 核心,或 8 个工作线程,每个工作线程使用 4 个核心
-
surya - 36 个批量大小,用于 16GB VRAM 使用
安装
需要 python 3.9+ 和 PyTorch。如果不用 Mac 或 GPU 机器,需要先安装 CPU 版本的 torch。第一次运行 surya 时,模型权重将自动下载。
pip install surya-ocr
互动应用程序
Streamlit 应用程序,可让以交互方式在图像或 PDF 文件上尝试 Surya:
pip install streamlit
surya_gui
OCR(文字识别)
此命令将写出一个包含检测到的文本和 bbox 的 json 文件:
surya_ocr DATA_PATH
-
DATA_PATH可以是图像、pdf 或图像/pdf 文件夹
-
langs是一个可选(但推荐)参数,指定用于 OCR 的语言。您可以用逗号分隔多种语言。使用此处的语言名称或两个字母的 ISO 代码。 Surya 支持 90 多种语言surya/languages.py。
-
lang_file如果您想对不同的 PDF/图像使用不同的语言,您可以选择在文件中指定语言。格式是 JSON 字典,键是文件名,值是列表,例如{"file1.pdf": ["en", "hi"], "file2.pdf": ["en"]}.
-
images将保存页面图像和检测到的文本行(可选)
-
results_dir指定保存结果的目录而不是默认目录
-
max如果您不想处理所有内容,则指定要处理的最大页数
-
start_page指定开始处理的页码
该results.json文件将包含一个 json 字典,其中键是不带扩展名的输入文件名。每个值将是一个字典列表,输入文档的每一页一个。每页词典包含:
-
text_lines- 每行检测到的文本和边界框
-
text- 行中的文本
-
confidence- 模型在检测到的文本中的置信度 (0-1)
-
polygon- (x1, y1)、(x2, y2)、(x3, y3)、(x4, y4) 格式的文本行的多边形。这些点从左上角开始按顺时针顺序排列。
-
bbox- (x1, y1, x2, y2) 格式的文本行的轴对齐矩形。 (x1, y1) 是左上角,(x2, y2) 是右下角。
-
languages- 为页面指定的语言
-
page- 文件中的页码
-
image_bbox- (x1, y1, x2, y2) 格式图像的 bbox。 (x1, y1) 是左上角,(x2, y2) 是右下角。所有行 bbox 都将包含在该 bbox 中。