
🎬慕斯主页:修仙—别有洞天
♈️今日夜电波:Blues in the Closet—ずっと真夜中でいいのに。
0:34━━━━━━️💟──────── 3:37
🔄 ◀️ ⏸ ▶️ ☰
💗关注👍点赞🙌收藏您的每一次鼓励都是对我莫大的支持😍
目录
实现大于256KB的内存块申请
申请操作的修改
释放操作的修改
使用定长内存池解除对new与delete的使用
解决释放对象需要传入对象大小的问题
解决获取对象与Span的线程安全问题
与malloc在多线程环境下的性能测试
利用基数树进行优化性能
实现大于256KB的内存块申请
申请操作的修改
前面我们实现的内存池实际上只支持申请256KB以下的内存,因为我们在RoundUp函数里面对超过256KB的内存申请操作设置了断言处理。当申请的内存小于256KB也就是32页时,我们可以向threadcache申请,如果申请的内存在32页-128页时,我们应该向pagecache申请,而如果大于128页了就需要向堆进行申请了。对此需要对RoundUp进行一定的修改:
// 整体控制在最多10%左右的内碎⽚浪费// [1,128] 8byte对⻬ freelist[0,16)// [128+1,1024] 16byte对⻬ freelist[16,72)// [1024+1,81024] 128byte对⻬ freelist[72,128)// [8*1024+1,641024] 1024byte对⻬ freelist[128,184)// [64*1024+1,256*1024] 8*1024byte对⻬ freelist[184,208)// 如何理解?实际上就是获取要得到的内存块大小// 如:bytes=16,align=8,则得到的结果是这样的:(16+(8-1))& ~(8-1) -> 0001 0111 & 1111 1000 -> 16static inline size_t _RoundUp(size_t bytes, size_t align){return (((bytes)+align - 1) & ~(align - 1));}// 对⻬⼤⼩计算static inline size_t RoundUp(size_t bytes){if (bytes<=128){return _RoundUp(bytes, 8);}else if (bytes <= 1024) {return _RoundUp(bytes, 16);}else if (bytes <= 8*1024) {return _RoundUp(bytes, 128);}else if (bytes <= 64 * 1024) {return _RoundUp(bytes, 1024);}else if (bytes <= 256 * 1024){return _RoundUp(bytes, 8 * 1024);}else{return _RoundUp(bytes, 1 << PAGE_SHIFT);}}我们需要对于内存申请模块进行一定的修改,当大于256KB时直接调用pagecache的申请接口即可,后续需要向堆进行申请的操作也是更改NewSPan这个接口即可:
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES) //申请大于256KB的内存{//计算出对齐后需要申请的页数size_t alignSize = SizeClass::RoundUp(size);size_t kPage = alignSize >> PAGE_SHIFT;//向page cache申请kPage页的spanPageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kPage);PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_pageId << PAGE_SHIFT);return ptr;}else{// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);}
}需要修改NewSPan,将之前的断言需要小于256KB的条件去掉,加入特别为大于128页需要找堆申请的选项给加上,当然前面ConcurrentAlloc申请超过128页时也是需要加锁的。
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0);if (k > NPAGES - 1) //大于128页直接找堆申请{void* ptr = SystemAlloc(k);Span* span = new Span;span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;_idSpanMap[span->_pageId] = span;return span;}//先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();//建立页号与span的映射,方便central cache回收小块内存时查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageId + i] = kSpan;}return kSpan;}//检查一下后面的桶里面有没有span,如果有可以将其进行切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;//在nSpan的头部切k页下来kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;//将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);//存储nSpan的首尾页号与nSpan之间的映射,方便page cache合并span时进行前后页的查找_idSpanMap[nSpan->_pageId] = nSpan;_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;//建立页号与span的映射,方便central cache回收小块内存时查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageId + i] = kSpan;}return kSpan;}}//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);//尽量避免代码重复,递归调用自己return NewSpan(k);
}释放操作的修改
前面我们再申请操作的时候将内存的申请分为了小于等于32页向pagecache申请,32页-128页向pagecache申请,大于128页向堆直接申请,那么我们对应的释放操作也应该这么分类去释放。
static void ConcurrentFree(void* ptr, size_t size)
{if (size > MAX_BYTES) //释放大于256KB的内存{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}
如果要直接向堆释放,那么当然也需要对应的接口,在Windows环境下的接口为VirtualFree,对此进行封装一下,后续如果需要跨平台可进行操作:
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#else// sbrk unmmap等
#endif
}后续同前面NewSpan一样,我们需要对从pagecache释放内存块的ReleaseSpanToPageCache接口进行一定的修改:
void PageCache::ReleaseSpanToPageCache(Span* span)
{if (span->_n > NPAGES - 1)//大于128页直接释放给堆{void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);delete span;return;}// 对span前后的页,尝试进行合并,缓解内存碎片问题while (1){PAGE_ID prevId= span->_pageId - 1;auto ret = _idSpanMap.find(prevId);//前面的页号没有(还未向系统申请),停止向前合并if (ret == _idSpanMap.end()){break;}//前面的页号对应的span正在被使用,停止向前合并if (ret->second->_isUse == true){break;}//合并出超过128页的span无法进行管理,停止向前合并if (ret->second->_n + span->_n > NPAGES - 1){break;}span->_pageId = ret->second->_pageId;span->_n += ret->second->_n;_spanLists[ret->second->_n].Erase(ret->second);delete ret->second;}// 向后合并while (1){PAGE_ID nextId = span->_pageId + span->_n;auto ret = _idSpanMap.find(nextId);//后面的页号没有(还未向系统申请),停止向后合并if (ret == _idSpanMap.end()){break;}//后面的页号对应的span正在被使用,停止向后合并Span* nextSpan = ret->second;if (nextSpan->_isUse == true){break;}//合并出超过128页的span无法进行管理,停止向后合并if (nextSpan->_n + span->_n > NPAGES - 1){break;}//进行向后合并span->_n += nextSpan->_n;//将nextSpan从对应的双链表中移除_spanLists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}//将合并后的span挂到对应的双链表当中_spanLists[span->_n].PushFront(span);//建立该span与其首尾页的映射_idSpanMap[span->_pageId] = span;_idSpanMap[span->_pageId + span->_n - 1] = span;//将该span设置为未被使用的状态span->_isUse = false;
}
使用定长内存池解除对new与delete的使用
tcmalloc实际上就是为了在高并发的场景下替代malloc的,如果我们使用了new那么不还是没摆脱malloc的使用吗?(因为new底层封装了malloc)对此,我们可以使用之前实现的定长内存池来替换new,需要在几个使用了new的地方进行修改:
pagecache类中:
class PageCache
{
Span* PageCache::NewSpan(size_t k)
{
//Span* span = new Span;
Span* span = _spanPool.New();
//Span* kSpan = new Span;
Span* kSpan = _spanPool.New();
//Span* bigSpan = new Span;
Span* bigSpan = _spanPool.New();}private:
ObjectPool<Span> _spanPool;
};
void PageCache::ReleaseSpanToPageCache(Span* span)
{
//delete span;
_spanPool.Delete(span);
//delete ret->second;
_spanPool.Delete(ret->second);//delete nextSpan;
_spanPool.Delete(nextSpan);
}ConcurrentAlloc中,每个线程第一次使用threadcache时都是new出来的所以需要进行处理:
// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){//pTLSThreadCache = new ThreadCache;static std::mutex tcMtx;static ObjectPool<ThreadCache> tcPool;tcMtx.lock();pTLSThreadCache = tcPool.New();tcMtx.unlock();}SpanList中也用到了new,这里定义一个static类型的ObjectPool即可,注意两个头文件之间的互相包含,我们需要给前置声明。
template<class T>
class ObjectPool;
class SpanList
{
public:
SpanList(){_head = new Span;_head = _spanPool.New();}private:
static ObjectPool<Span> _spanPool;};解决释放对象需要传入对象大小的问题
这里就要提前面的Span结构体中定义的 size_t _objSize =0;//切好的小对象的大小变量。这个就是用于解决ConcurrentFree接口需要传入对象大小的问题。我们只需要在获取一个新的Span的同时传入这个Span的大小即可。后续可直接按照这个大小进行释放。这里主要有两个地方:一个是申请大于256KB的内存的时候,另外一个是centralcache从pagecache申请Span的时候,如下:
static void* ConcurrentAlloc(size_t size)
{//向page cache申请kPage页的spanPageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kPage);span->_objSize = size;
}Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));span->_objSize = size;
}然后我们的释放即可不需要插入对象大小了:
static void ConcurrentFree(void* ptr)
{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t size = span->_objSize;if (size > MAX_BYTES) //大于256KB的内存释放{PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}解决获取对象与Span的线程安全问题
_idSpanMap这个成员变量用于存储页号与span之间的映射关系,由于STL不是线程安全的,因此我们在访问_idSpanMap的时候会出现线程安全的问题,对此我们需要加锁:
Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT;std::unique_lock<std::mutex> lock(_pageMtx); //构造时加锁,析构时自动解锁auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else {assert(false);return nullptr;}
}与malloc在多线程环境下的性能测试
#include "ObjectPool.hpp"
#include "ConcurrentAlloc.hpp"
#inlcude <atomic>void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));//v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次malloc " << ntimes << "次: 花费:" << malloc_costtime << " ms\n";std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次free " << ntimes << "次: 花费:" << free_costtime << " ms\n";std::cout << nworks << "个线程并发malloc&free " << nworks * rounds * ntimes << "次,总计花费:" << (malloc_costtime + free_costtime) << " ms\n";/*printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime);printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);*/
}void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConcurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次concurrent alloc " << ntimes << "次: 花费:" << malloc_costtime << " ms\n";std::cout << nworks << "个线程并发执行" << rounds << "轮次,每轮次concurrent dealloc " << ntimes << "次: 花费:" << free_costtime << " ms\n";std::cout << nworks << "个线程并发concurrent alloc&dealloc " << nworks * rounds * ntimes << "次,总计花费:" << (malloc_costtime + free_costtime) << " ms\n";//printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime);//printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime);//printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
}int main()
{size_t n = 10000;cout << "==========================================================" <<endl;BenchmarkConcurrentMalloc(n, 3, 10);cout << endl << endl;BenchmarkMalloc(n, 3, 10);cout << "==========================================================" <<endl;return 0;
}
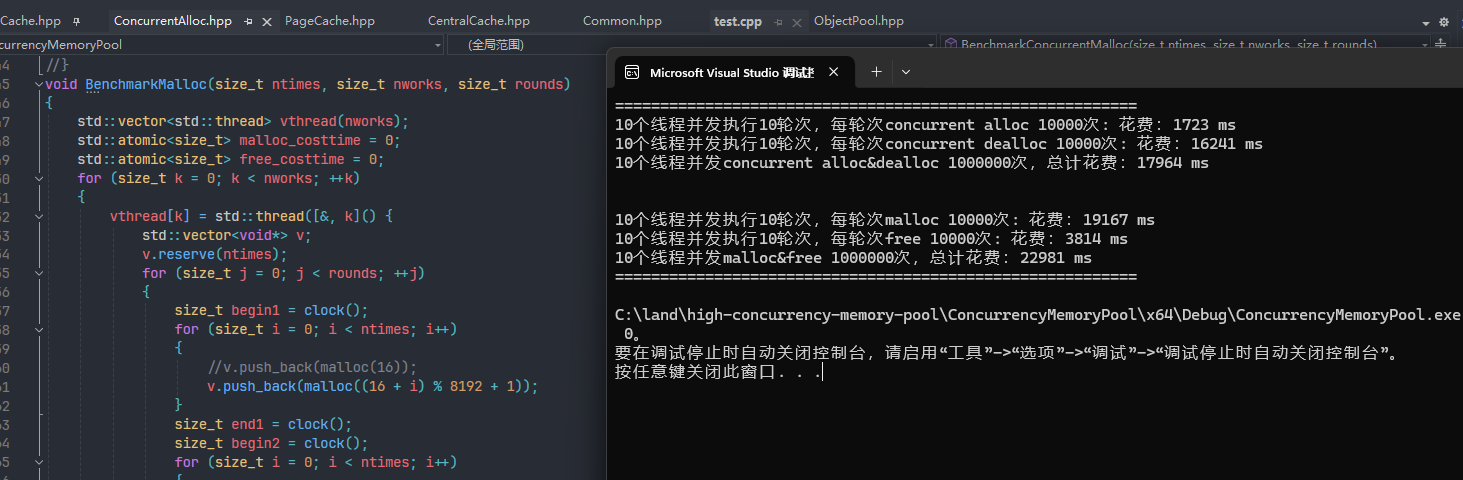
较为分散的情况下进行内存申请,可以看到我们在多线程环境下,我们的concurrent alloc申请内存确实是比malloc快,但是在释放内存的时候我们却比malloc还慢了许多???而整体花费的时间还更多?导致这个的原因实际上就是因为锁的竞争。

当我们较为集中的申请内存时,可以发现我们的concurrent alloc申请内存比malloc快了10倍多,虽然释放空间速度还是很慢,但是整体是比malloc要快的:
利用基数树进行优化性能
上面也提到了,导致我们性能欠缺的原因就是锁的竞争导致的,因此当前项目的瓶颈点就在锁竞争上面。我们需要解决如上的问题,那么最简单的方法就是读写分离,利用基数树可以做到如上的功能。
基数树(Radix Tree),也称为紧凑前缀树(Compact Prefix Tree)或Patricia树(Patricia Tree),是一种在计算机科学中用于存储和检索字符串键值的高效数据结构。它是对Trie树(前缀树)的一种优化,通过压缩公共前缀来减少节点的数量,从而节省存储空间。实际上就是一个分层的哈希表,根据所分层数不同可分为单层基数树、二层基数树、三层基数树等等以下是基数树的详细解释:
对于单层基数树:采用的就是直接定址法,每个页号对应一个span的地址,也就是如下我们使用set接口传入的页号以及span的首地址来做到的,而根据页号则可以得到对应span的首地址,既如下的get接口,需要注意的是:如下的模版参数BITS我们应该传入什么呢?在32位下的话,假设一页为8KB,那么我们需要传入32-13也就是19,这个19既为2的指数次幂的上标,那么我们储存32位下的所有页号就最多只需要19位,既我们要传入的为存储页号的最大位数。又因为32为下指针大小为4位,那么需要2^9*4=2M。但是,如果是在64为下,则需要2^51*8=2^54=2^24G。显然一层是不够的,此时我们需要3层基数树。
//单层基数树
template <int BITS>
class TCMalloc_PageMap1
{
public:typedef uintptr_t Number;explicit TCMalloc_PageMap1(){size_t size = sizeof(void*) << BITS; //需要开辟数组的大小size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT); //按页对齐后的大小array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT); //向堆申请空间memset(array_, 0, size); //对申请到的内存进行清理}void* get(Number k) const{if ((k >> BITS) > 0) //k的范围不在[0, 2^BITS-1]{return NULL;}return array_[k]; //返回该页号对应的span}void set(Number k, void* v){assert((k >> BITS) == 0); //k的范围必须在[0, 2^BITS-1]array_[k] = v; //建立映射}
private:void** array_; //存储映射关系的数组static const int LENGTH = 1 << BITS; //页的数目
};
对于二层基数树,以32位为例,我们可以让前面提到的需要的19个比特位分两次来进行映射,比如:取出前5个比特位作为第一层的映射,后14位作为第二层的映射。这样带上每个指针4位的条件,我们第一层占用4*2^5=128B,而第二层最多2^14*4*2^15=2M。使用二层基数树的好处就在于:一层基数树一开始就把2M空间开辟出来了,但是第二层只需要在要用的时候再开辟空间即可。这样不就大大的节省了空间吗?同理的,如果我们要使用64位下的基数树映射,那么使用三层基数树就会更加节省空间:
//二层基数树
template <int BITS>
class TCMalloc_PageMap2
{
private:static const int ROOT_BITS = 5; //第一层对应页号的前5个比特位static const int ROOT_LENGTH = 1 << ROOT_BITS; //第一层存储元素的个数static const int LEAF_BITS = BITS - ROOT_BITS; //第二层对应页号的其余比特位static const int LEAF_LENGTH = 1 << LEAF_BITS; //第二层存储元素的个数//第一层数组中存储的元素类型struct Leaf{void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; //第一层数组
public:typedef uintptr_t Number;explicit TCMalloc_PageMap2(){memset(root_, 0, sizeof(root_)); //将第一层的空间进行清理PreallocateMoreMemory(); //直接将第二层全部开辟}void* get(Number k) const{const Number i1 = k >> LEAF_BITS; //第一层对应的下标const Number i2 = k & (LEAF_LENGTH - 1); //第二层对应的下标if ((k >> BITS) > 0 || root_[i1] == NULL) //页号值不在范围或没有建立过映射{return NULL;}return root_[i1]->values[i2]; //返回该页号对应span的指针}void set(Number k, void* v){const Number i1 = k >> LEAF_BITS; //第一层对应的下标const Number i2 = k & (LEAF_LENGTH - 1); //第二层对应的下标assert(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v; //建立该页号与对应span的映射}//确保映射[start,start_n-1]页号的空间是开辟好了的bool Ensure(Number start, size_t n){for (Number key = start; key <= start + n - 1;){const Number i1 = key >> LEAF_BITS;if (i1 >= ROOT_LENGTH) //页号超出范围return false;if (root_[i1] == NULL) //第一层i1下标指向的空间未开辟{//开辟对应空间static ObjectPool<Leaf> leafPool;Leaf* leaf = (Leaf*)leafPool.New();memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}key = ((key >> LEAF_BITS) + 1) << LEAF_BITS; //继续后续检查}return true;}void PreallocateMoreMemory(){Ensure(0, 1 << BITS); //将第二层的空间全部开辟好}
};
对于三层基数树:层数的增加很大程度上节省了空间。
//三层基数树
template <int BITS>
class TCMalloc_PageMap3
{
private:static const int INTERIOR_BITS = (BITS + 2) / 3; //第一、二层对应页号的比特位个数static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS; //第一、二层存储元素的个数static const int LEAF_BITS = BITS - 2 * INTERIOR_BITS; //第三层对应页号的比特位个数static const int LEAF_LENGTH = 1 << LEAF_BITS; //第三层存储元素的个数struct Node{Node* ptrs[INTERIOR_LENGTH];};struct Leaf{void* values[LEAF_LENGTH];};Node* NewNode(){static ObjectPool<Node> nodePool;Node* result = nodePool.New();if (result != NULL){memset(result, 0, sizeof(*result));}return result;}Node* root_;
public:typedef uintptr_t Number;explicit TCMalloc_PageMap3(){root_ = NewNode();}void* get(Number k) const{const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS); //第一层对应的下标const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1); //第二层对应的下标const Number i3 = k & (LEAF_LENGTH - 1); //第三层对应的下标//页号超出范围,或映射该页号的空间未开辟if ((k >> BITS) > 0 || root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL){return NULL;}return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3]; //返回该页号对应span的指针}void set(Number k, void* v){assert(k >> BITS == 0);const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS); //第一层对应的下标const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1); //第二层对应的下标const Number i3 = k & (LEAF_LENGTH - 1); //第三层对应的下标Ensure(k, 1); //确保映射第k页页号的空间是开辟好了的reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v; //建立该页号与对应span的映射}//确保映射[start,start+n-1]页号的空间是开辟好了的bool Ensure(Number start, size_t n){for (Number key = start; key <= start + n - 1;){const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS); //第一层对应的下标const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1); //第二层对应的下标if (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH) //下标值超出范围return false;if (root_->ptrs[i1] == NULL) //第一层i1下标指向的空间未开辟{//开辟对应空间Node* n = NewNode();if (n == NULL) return false;root_->ptrs[i1] = n;}if (root_->ptrs[i1]->ptrs[i2] == NULL) //第二层i2下标指向的空间未开辟{//开辟对应空间static ObjectPool<Leaf> leafPool;Leaf* leaf = leafPool.New();if (leaf == NULL) return false;memset(leaf, 0, sizeof(*leaf));root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node*>(leaf);}key = ((key >> LEAF_BITS) + 1) << LEAF_BITS; //继续后续检查}return true;}void PreallocateMoreMemory(){}
};
后续需要对于代码的优化:我们只需要将pagecache层中的std::unordered_map<PAGE_ID, Span*> _idSpanMap;给替换成基数树即可,如下为32位平台下的示例:随便使用几层基数树都可以的,如下:
//std::unordered_map<PAGE_ID, Span*> _idSpanMap;TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap;需要建立映射的时候,我们就调用set函数:
_idSpanMap.set(span->_pageId, span);需要读取映射的时候,就需要调用get函数:
(Span*)_idSpanMap.get(nextId);pagecache的更改:
#pragma once
#include "Common.hpp"
#include "ObjectPool.hpp"
#include "PageMap.hpp"
// 1.page cache是⼀个以⻚为单位的span⾃由链表
// 2.为了保证全局只有唯⼀的page cache,这个类被设计成了单例模式
class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}Span* NewSpan(size_t k);//获取从对象到span的映射Span* MapObjectToSpan(void* obj);std::mutex _pageMtx;void ReleaseSpanToPageCache(Span* span);
private:SpanList _spanLists[NPAGES];ObjectPool<Span> _spanPool;PageCache(){}PageCache(const PageCache&) = delete;static PageCache _sInst;//std::unordered_map<PAGE_ID, Span*> _idSpanMap;TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap;};PageCache PageCache::_sInst;// 获取一个K页的span
//Span* PageCache::NewSpan(size_t k)
//{
// assert(k > 0 && k < NPAGES);
//
// // 先检查第k个桶里面有没有span
// if (!_spanLists[k].Empty())
// {
// return _spanLists[k].PopFront();
// }
//
// // 检查一下后面的桶里面有没有span,如果有可以把他它进行切分
// for (size_t i = k + 1; i < NPAGES; ++i)
// {
// if (!_spanLists[i].Empty())
// {
// Span* nSpan = _spanLists[i].PopFront();
// Span* kSpan = new Span;
//
// // 在nSpan的头部切一个k页下来
// // k页span返回
// // nSpan再挂到对应映射的位置
// kSpan->_pageId = nSpan->_pageId;
// kSpan->_n = k;
//
// nSpan->_pageId += k;
// nSpan->_n -= k;
//
// _spanLists[nSpan->_n].PushFront(nSpan);
//
//
// return kSpan;
// }
// }
//
// // 走到这个位置就说明后面没有大页的span了
// // 这时就去找堆要一个128页的span
// Span* bigSpan = new Span;
// void* ptr = SystemAlloc(NPAGES - 1);
// bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
// bigSpan->_n = NPAGES - 1;
//
// _spanLists[bigSpan->_n].PushFront(bigSpan);
//
// return NewSpan(k);
//}// 获取一个K页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0);// 大于128 page的直接向堆申请if (k > NPAGES-1){void* ptr = SystemAlloc(k);//Span* span = new Span;Span* span = _spanPool.New();span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;//_idSpanMap[span->_pageId] = span;_idSpanMap.set(span->_pageId, span);return span;}// 先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();// 建立id和span的映射,方便central cache回收小块内存时,查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; ++i){//_idSpanMap[kSpan->_pageId + i] = kSpan;_idSpanMap.set(kSpan->_pageId + i, kSpan);}return kSpan;}// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分for (size_t i = k+1; i < NPAGES; ++i){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();//Span* kSpan = new Span;Span* kSpan = _spanPool.New();// 在nSpan的头部切一个k页下来// k页span返回// nSpan再挂到对应映射的位置kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);// 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时// 进行的合并查找//_idSpanMap[nSpan->_pageId] = nSpan;//_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;_idSpanMap.set(nSpan->_pageId, nSpan);_idSpanMap.set(nSpan->_pageId + nSpan->_n - 1, nSpan);// 建立id和span的映射,方便central cache回收小块内存时,查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; ++i){//_idSpanMap[kSpan->_pageId + i] = kSpan;_idSpanMap.set(kSpan->_pageId + i, kSpan);}return kSpan;}}// 走到这个位置就说明后面没有大页的span了// 这时就去找堆要一个128页的span//Span* bigSpan = new Span;Span* bigSpan = _spanPool.New();void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);return NewSpan(k);
}Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);/*std::unique_lock<std::mutex> lock(_pageMtx);auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}*/auto ret = (Span*)_idSpanMap.get(id);assert(ret != nullptr);return ret;
}void PageCache::ReleaseSpanToPageCache(Span* span)
{// 大于128 page的直接还给堆if (span->_n > NPAGES-1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);//delete span;_spanPool.Delete(span);return;}// 对span前后的页,尝试进行合并,缓解内存碎片问题while (1){PAGE_ID prevId = span->_pageId - 1;//auto ret = _idSpanMap.find(prevId);前面的页号没有,不合并了//if (ret == _idSpanMap.end())//{// break;//}auto ret = (Span*)_idSpanMap.get(prevId);if (ret == nullptr){break;}// 前面相邻页的span在使用,不合并了Span* prevSpan = ret;if (prevSpan->_isUse == true){break;}// 合并出超过128页的span没办法管理,不合并了if (prevSpan->_n + span->_n > NPAGES-1){break;}span->_pageId = prevSpan->_pageId;span->_n += prevSpan->_n;_spanLists[prevSpan->_n].Erase(prevSpan);//delete prevSpan;_spanPool.Delete(prevSpan);}// 向后合并while (1){PAGE_ID nextId = span->_pageId + span->_n;/*auto ret = _idSpanMap.find(nextId);if (ret == _idSpanMap.end()){break;}*/auto ret = (Span*)_idSpanMap.get(nextId);if (ret == nullptr){break;}Span* nextSpan = ret;if (nextSpan->_isUse == true){break;}if (nextSpan->_n + span->_n > NPAGES-1){break;}span->_n += nextSpan->_n;_spanLists[nextSpan->_n].Erase(nextSpan);//delete nextSpan;_spanPool.Delete(nextSpan);}_spanLists[span->_n].PushFront(span);span->_isUse = false;//_idSpanMap[span->_pageId] = span;//_idSpanMap[span->_pageId+span->_n-1] = span;_idSpanMap.set(span->_pageId, span);_idSpanMap.set(span->_pageId + span->_n - 1, span);
}
可以看到我们在读取映射关系的时候都是没有加锁的,为什么基数数对于其它的哈希表如:map、unordered_map不一样,不需要加锁呢?因为,基数树的空间一旦开辟好了就不会发生变化,因此无论什么时候去读取某个页的映射,都是对应在一个固定的位置进行读取的。并且对于同一个页,我们不会同时进行读取映射以及建立映射,为什么呢?因为只有在释放对象的时候才需要读取映射,而建立映射的操作都是在pagecache中进行的。什么意思呢?读取的都是对应span的_useCount不等于0的页,建立映射是都是建立span的_useCount等于0的页。
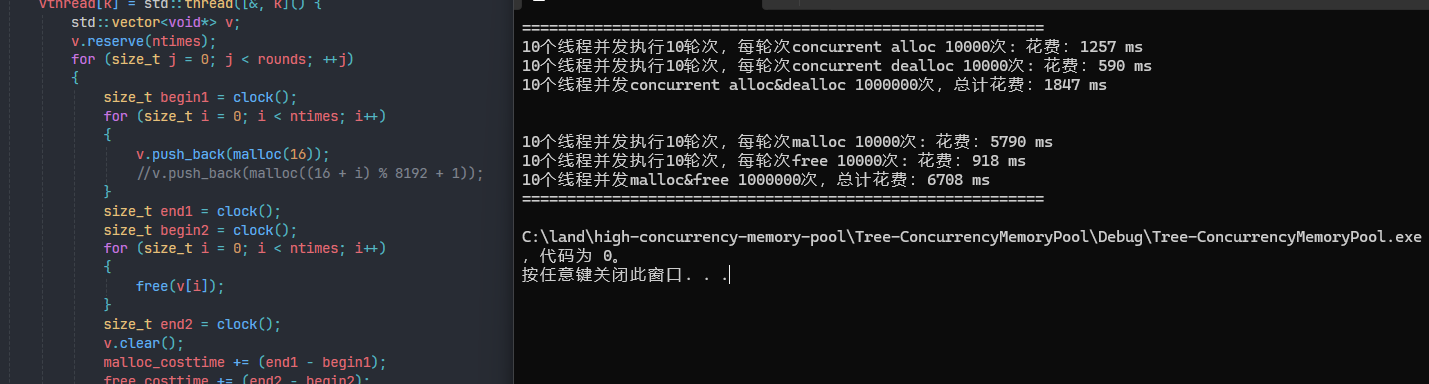
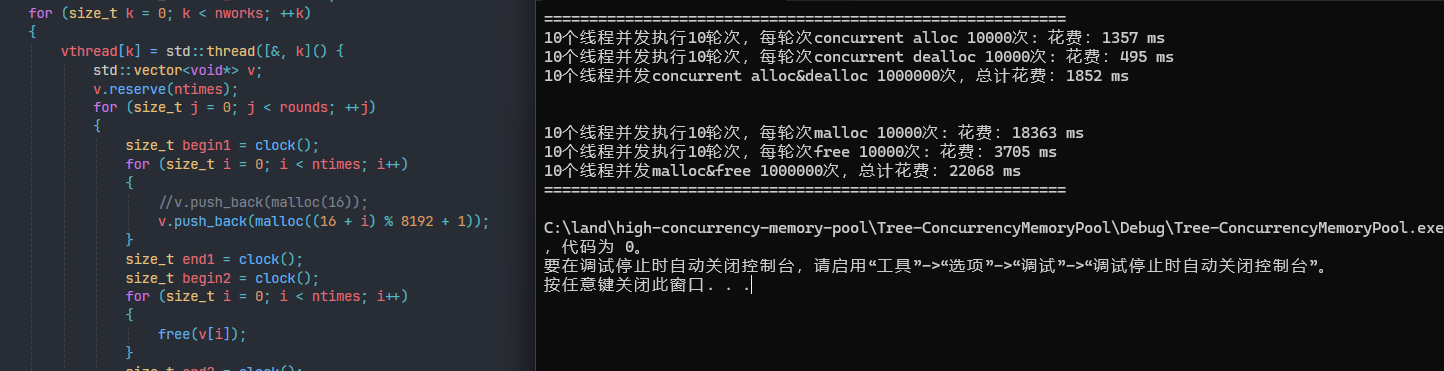
优化后的性能:可以看到已经全方面吊打malloc了。
随机申请的地址:
紧凑申请的地址:
感谢你耐心的看到这里ღ( ´・ᴗ・` )比心,如有哪里有错误请踢一脚作者o(╥﹏╥)o!

给个三连再走嘛~