
TCSVT 2025
创新点
结合图像显著性和视频时空特征进行视频显著性预测。
提出一个多尺度时空特征金字塔(MLSTFPN),能够更好的融合不同级别的特征,解决了显著性检测在多尺度时空特征表示的不足。
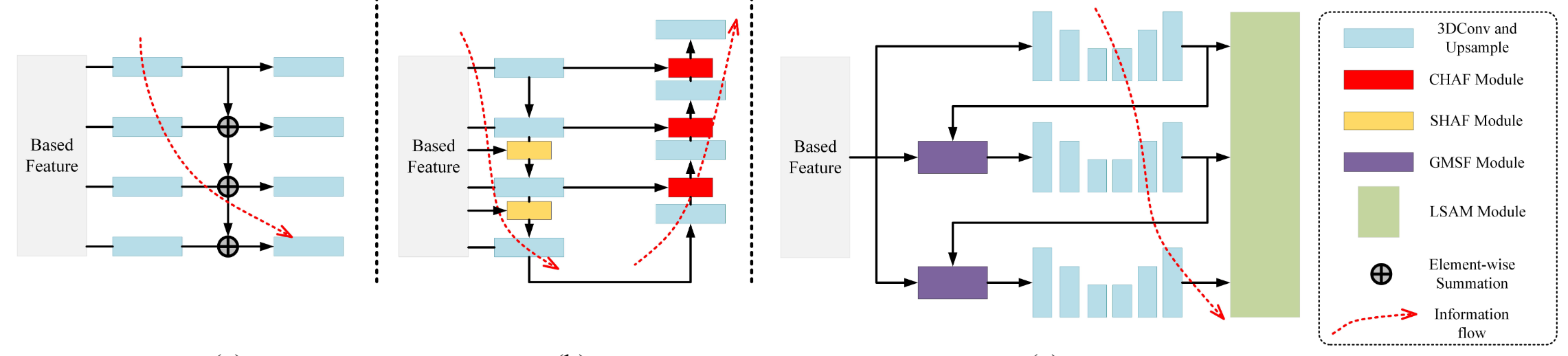
对比MLSTFPN和普通的FPN和BiFPN的区别。
Pipeline
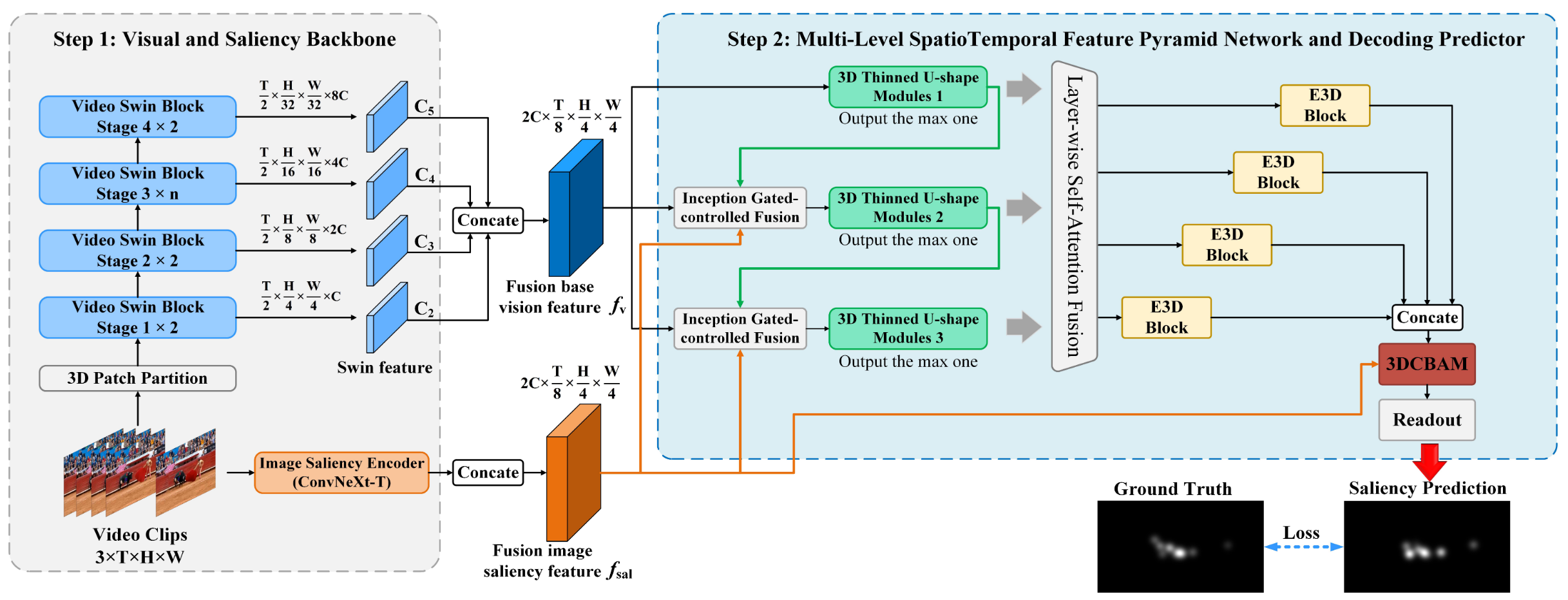
时空语义信息和图片显著性提取
预先训练的视频Video Swin Transformer和Convnext分别用作语义编码器和图像显着性提取的骨干。
先用VSIT进行多尺度的时空特征提取,然后经过一个融合模块得到视觉特征fv。
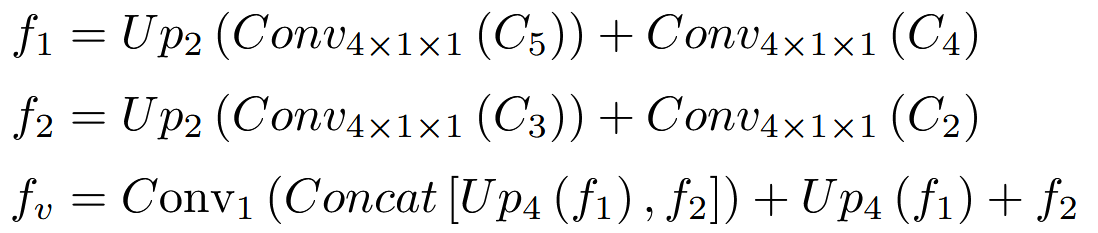
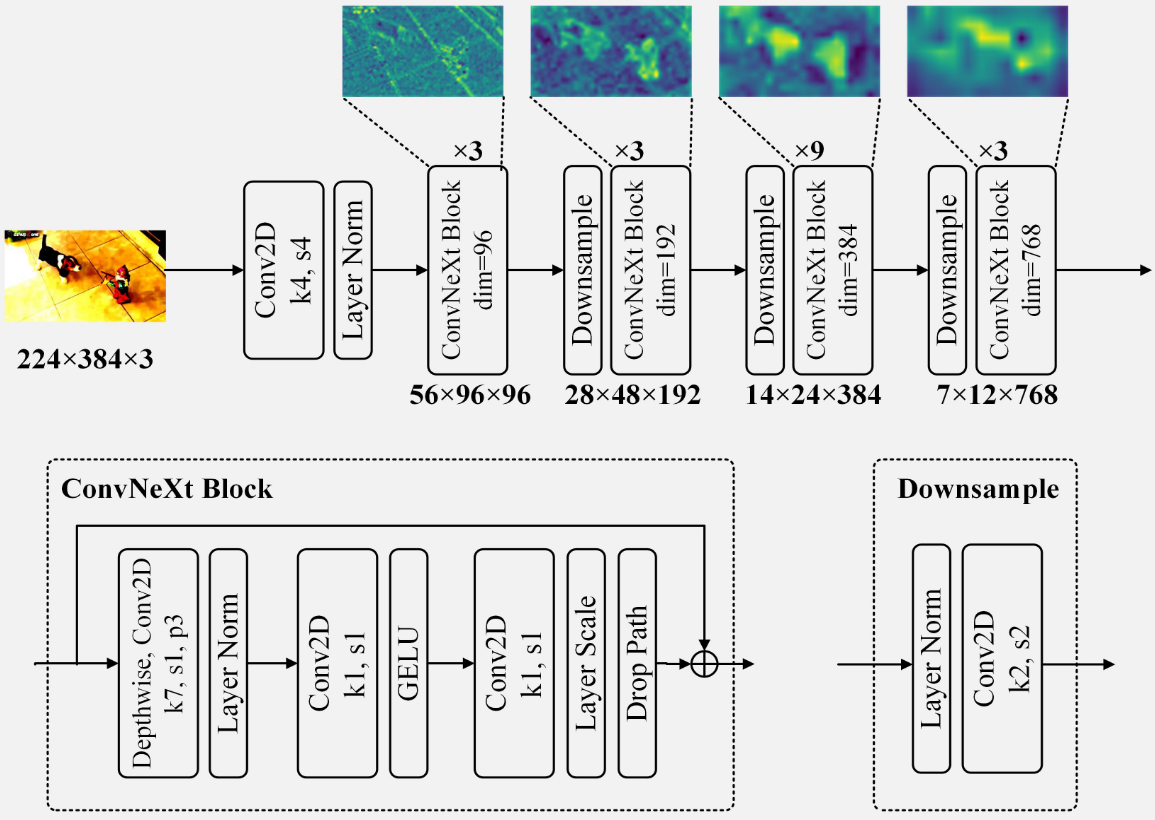

用ConvNeXt获取静态图像显著性,得到与上面相同尺度的输出。
没说怎么从多个尺度特征图融合得到fsal,合理怀疑也用的上面那个融合方式。
多尺度时空特征金字塔
视频编码器对视频显着性预测任务表现出较弱的偏见。换句话说,获得的多尺度融合视觉特征fv过于概括,涵盖了包括深层语义,中层纹理和形状以及浅层位置边缘信息。作为显着预测,这些信息缺乏强大的代表性意义。
融合视频时空特征和图片显著性信息,得到的增强多尺度时空特征能更好地代表不同尺度上的显着区域,在最终预测结果中起着至关重要的作用。
3DTUM
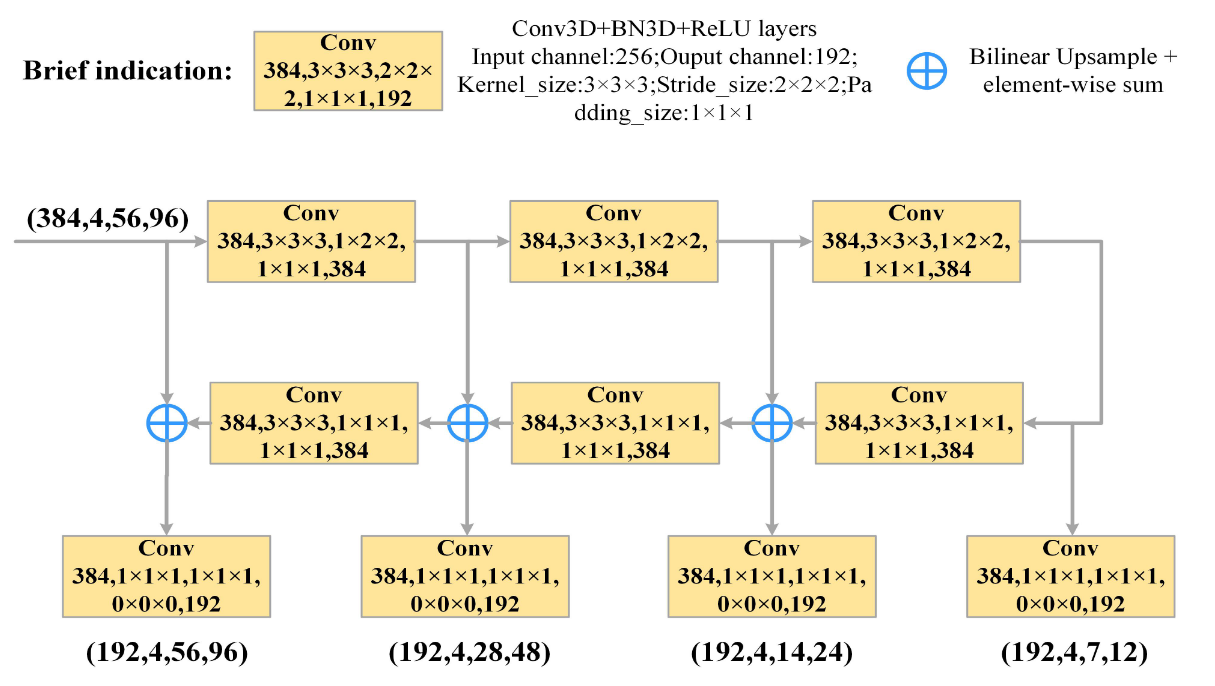
一种稀疏化、轻量化的3D U-Net结构。
特点是多尺度输出,每层输出的特征用于捕捉不同粒度的显著性目标。
IGCF
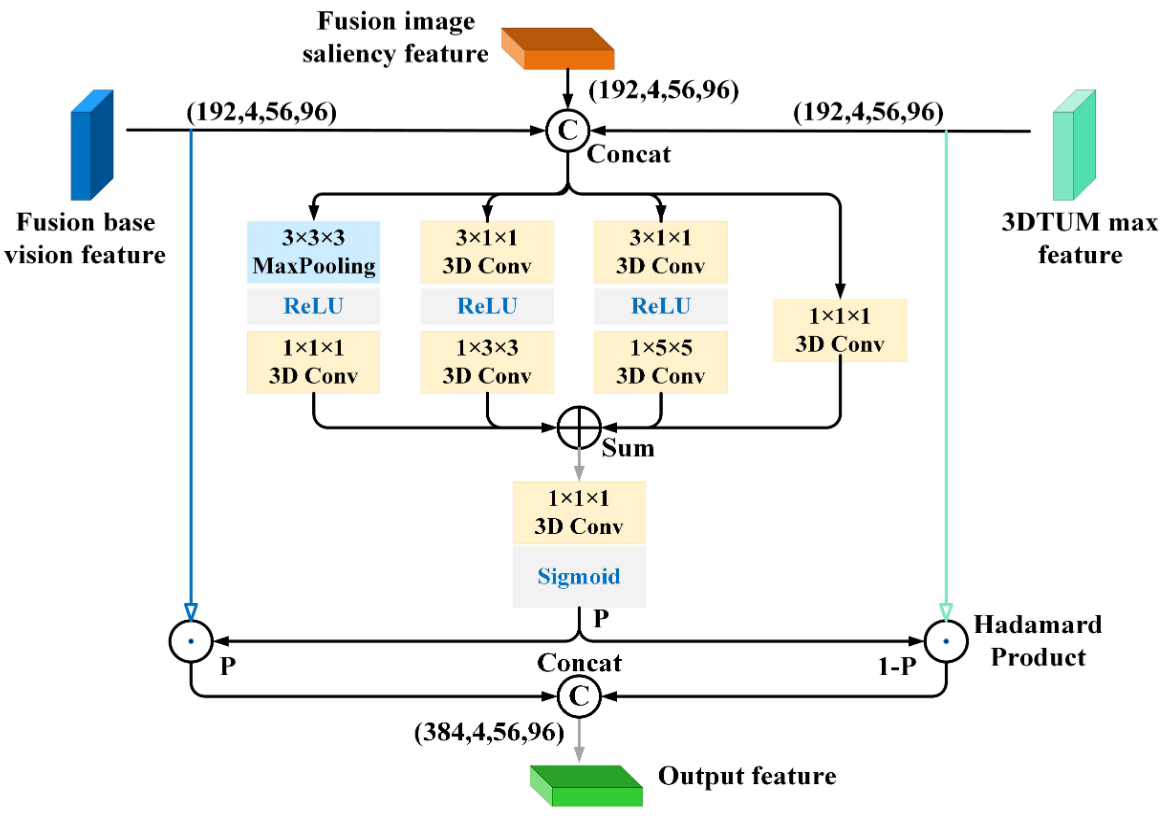
需要融合的信息:图片显著性信息,视频语义信息,增强的视频显著性信息,差别过大,简单的线性融合无法取得很好的效果。设计了一个融合模块IGCF在不同来源或不同尺度的特征之间建立选择性融合机制,有效提升多源信息协同建模的能力。
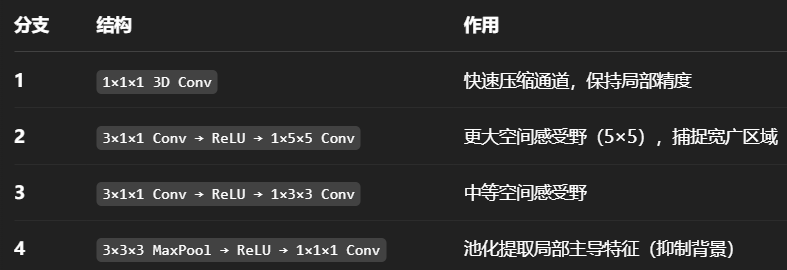
将融合特征经过不同的路线,分别模拟不同的感受野情况,并融合得到一个多尺度混合特征图。
融合结果再经过sigmoid得到一个掩码P,用于门控制,判断哪些区域是重要的,进行特征融合
LSAF
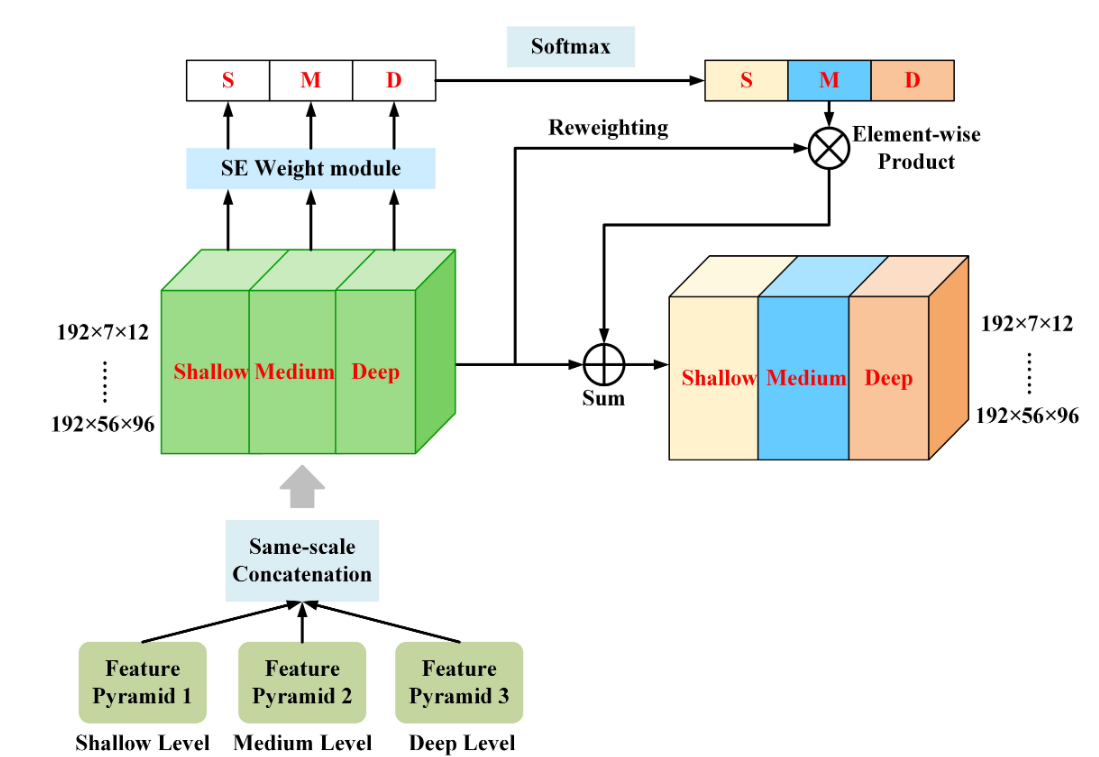
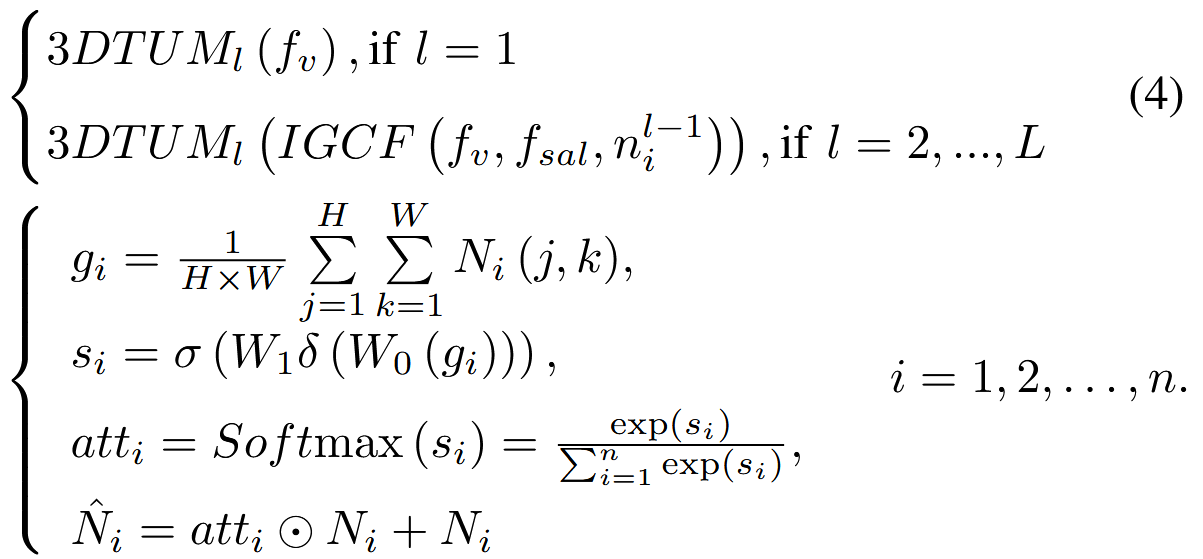
Ni表示来自不同三个3DTUM中有相同分辨率的特征。
先做全局池化,压缩空间维度。然后经过两个非线性映射得到重要性分数,经过softmax得到注意力分数,用于加权优化原始特征。
解码器
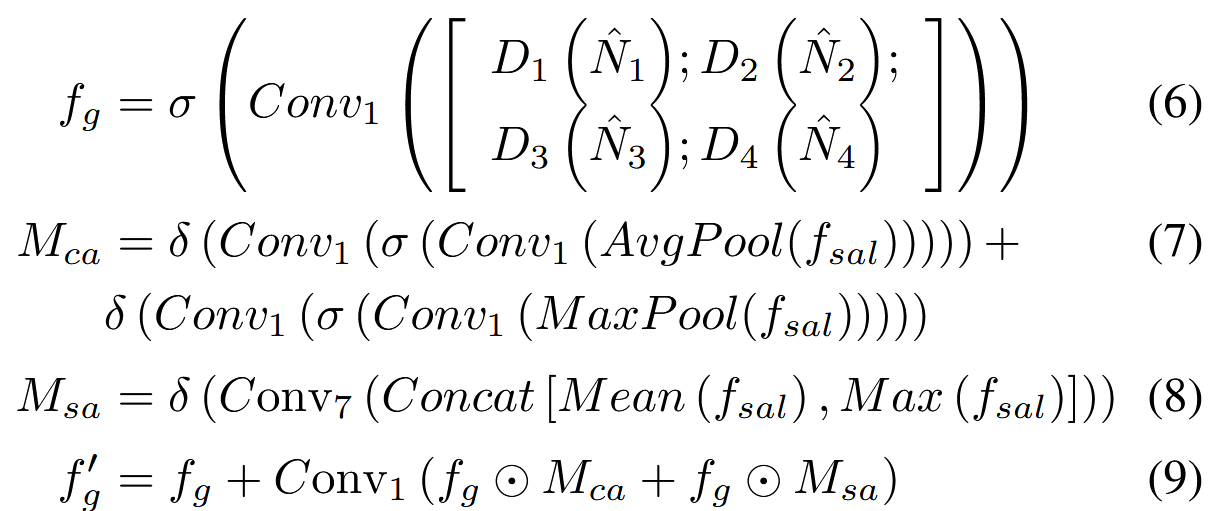
LSAF输出的四个分辨率的特征分别经过上采样和解码操作,进行拼接。
公式7和8分别利用fsal计算通道注意力和空间注意力。
用通道和空间注意力图指导拼接特征进行融合。
最后用一个Readout模块输出最后预测的显著图。
E3D解码模块和Readout模块都没有给出流程图,都是借鉴别人的。
损失函数
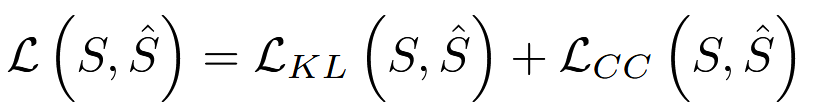
使用KL差异和线性相关系数计算总体损失。
具体计算公式如下:
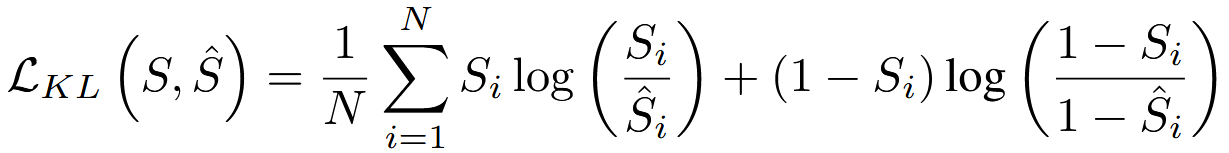
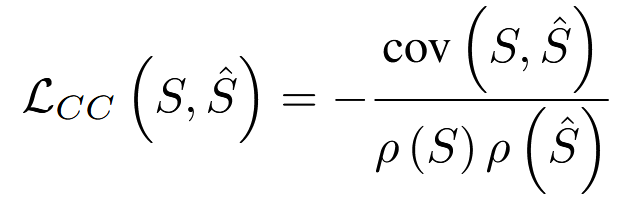 COV表示协方差,ρ表示标准偏差算子。
COV表示协方差,ρ表示标准偏差算子。
实验
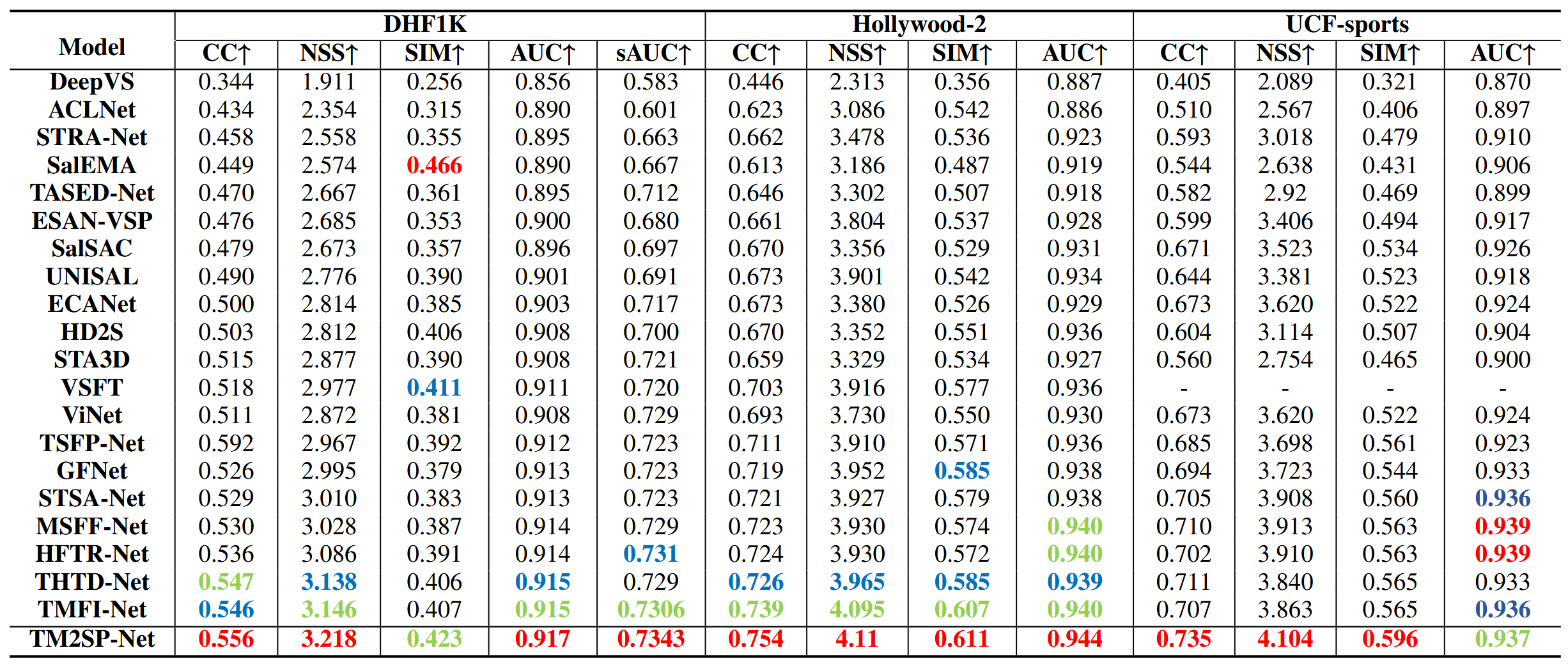
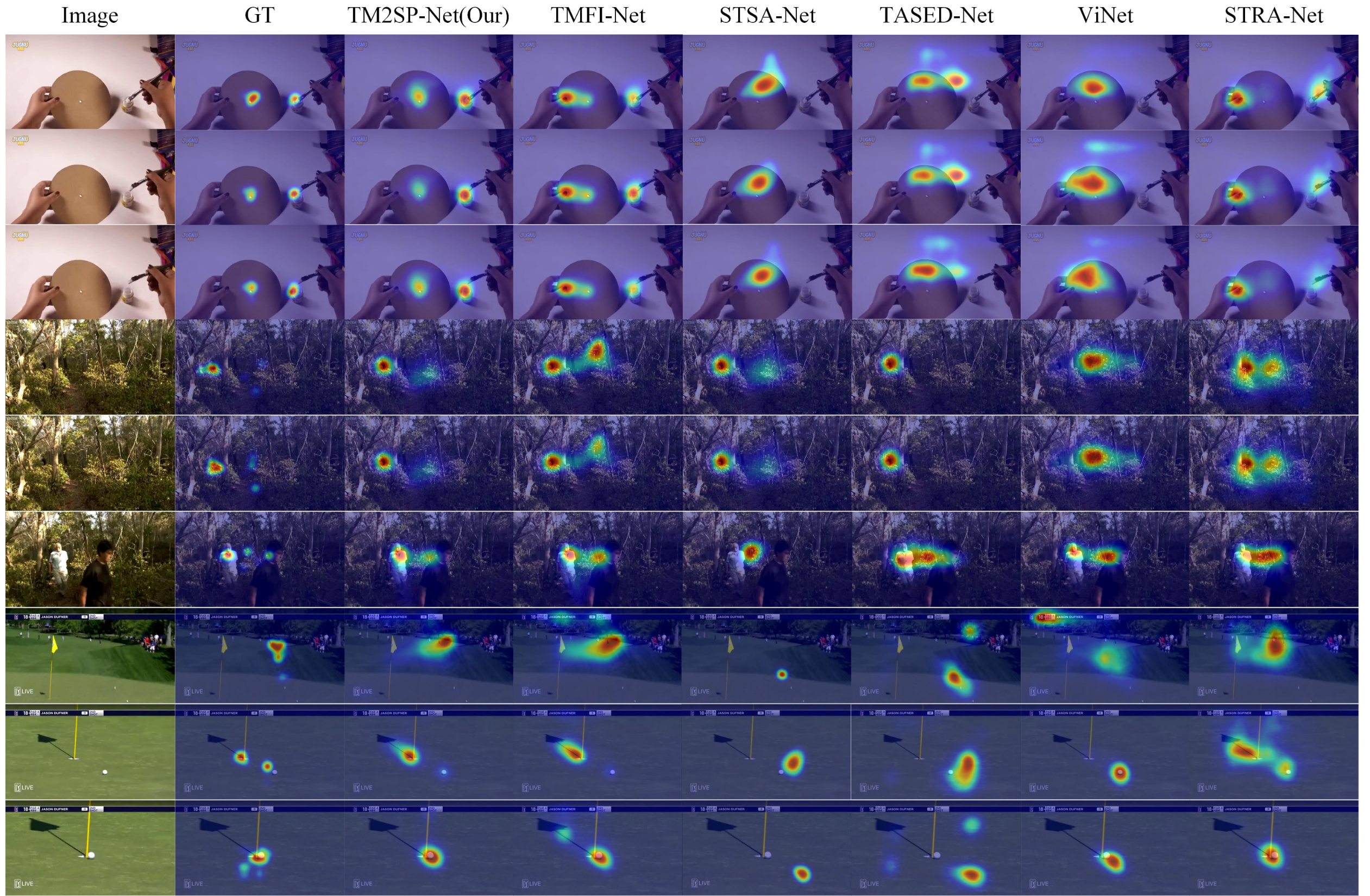
模型在各数据集上定性和定量的实验。
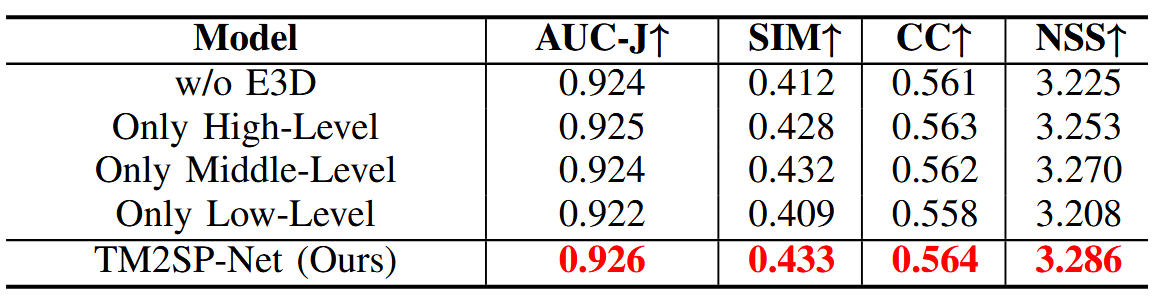
各模块的消融实验。
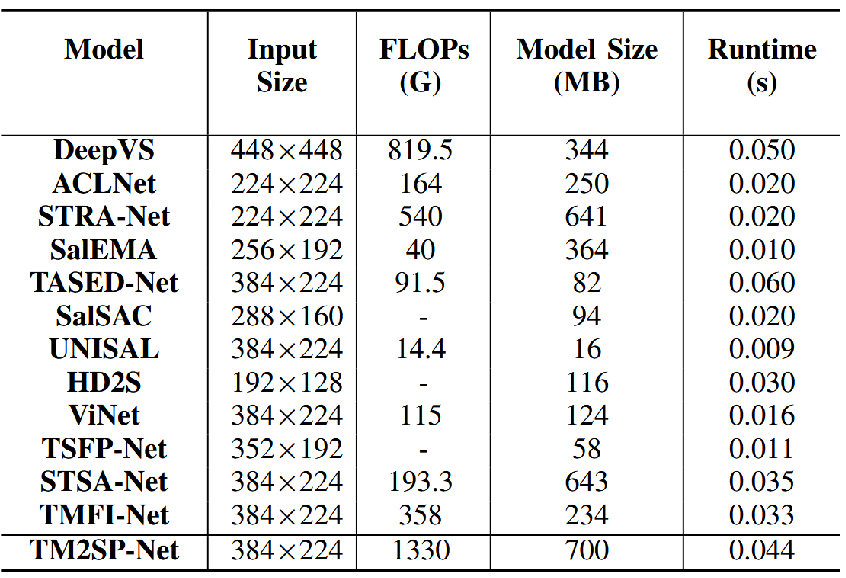
与其他模型在模型大小以及运行时间上的对比。