1. Spark 概述
Spark是什么?
Sprak官方的定义是:Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
用我自己的话来说:Spark是一个分布式计算框架,我们从分布式和计算两个方面来介绍:
什么是分布式?
我们接触到的大部分的在我们的电脑上运行的软件就是一个线程在运行的一个过程,一般就能满足我们的计算需求,我们称这种模式为本地模式,但是当我们有比较大的计算需求的时候怎么办?这时候我们就可以多开一些线程来帮助我们,就在一台电脑上运行多个线程去进行计算,我们称这种模式是伪分布式。如果还是不能满足我们的一些计算要求,我们该怎么办呢,我们就在多台电脑上,都开多个线程去执行我们的任务,我们称这种方式为分布式。
那什么是计算呢?
我们可能认为只有加减乘除才算计算,但是在计算机中不是这样的,就是只要是对数据进行操作就算是计算,包括对数据的导入导出都算是计算。
什么是框架呢?
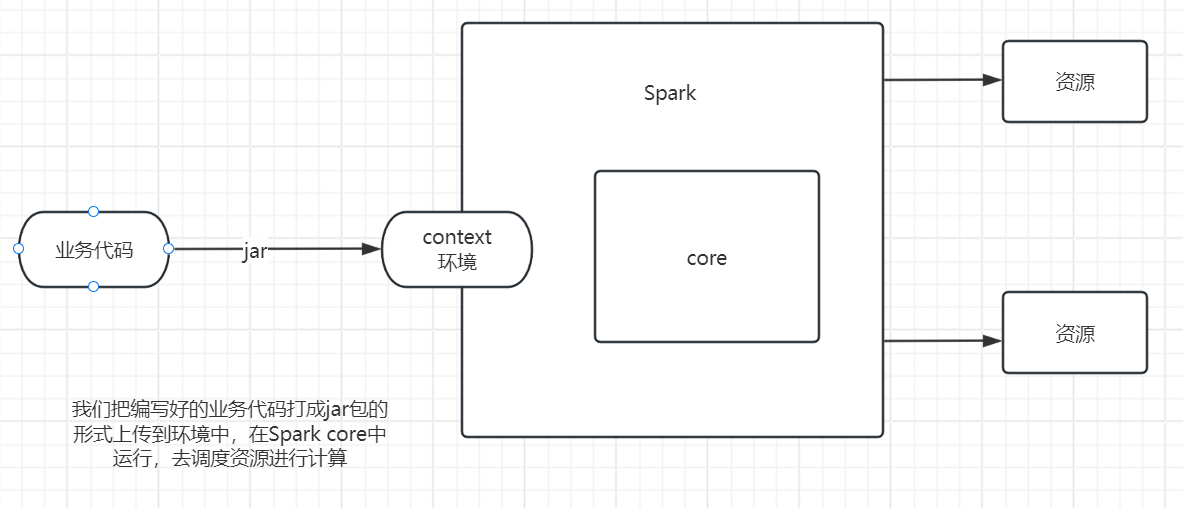
说到框架我们就要和我们常说的另一个名词系统来一起说,我们常说的什么什么系统,就类似小区管理系统,成绩管理系统……等等,这些系统开发完,就不需要我们再进行开发,只需要使用就可以了。而框架,就是我们说的分布式存储框架(HDFS)、分布式计算框架(Spark)……等等,这些框架只是完成了核心的功能,还需要我们去编写一定量的代码去使用这个框架,就是像是我们要计算一个班级的平均分,要是使用一个系统,我们直接把成绩导入,他自动给我们算出来,但是我们要是使用一个框架,就需要我们去编写一个计算平均成绩的jar去交给框架去执行。
分布计算框架
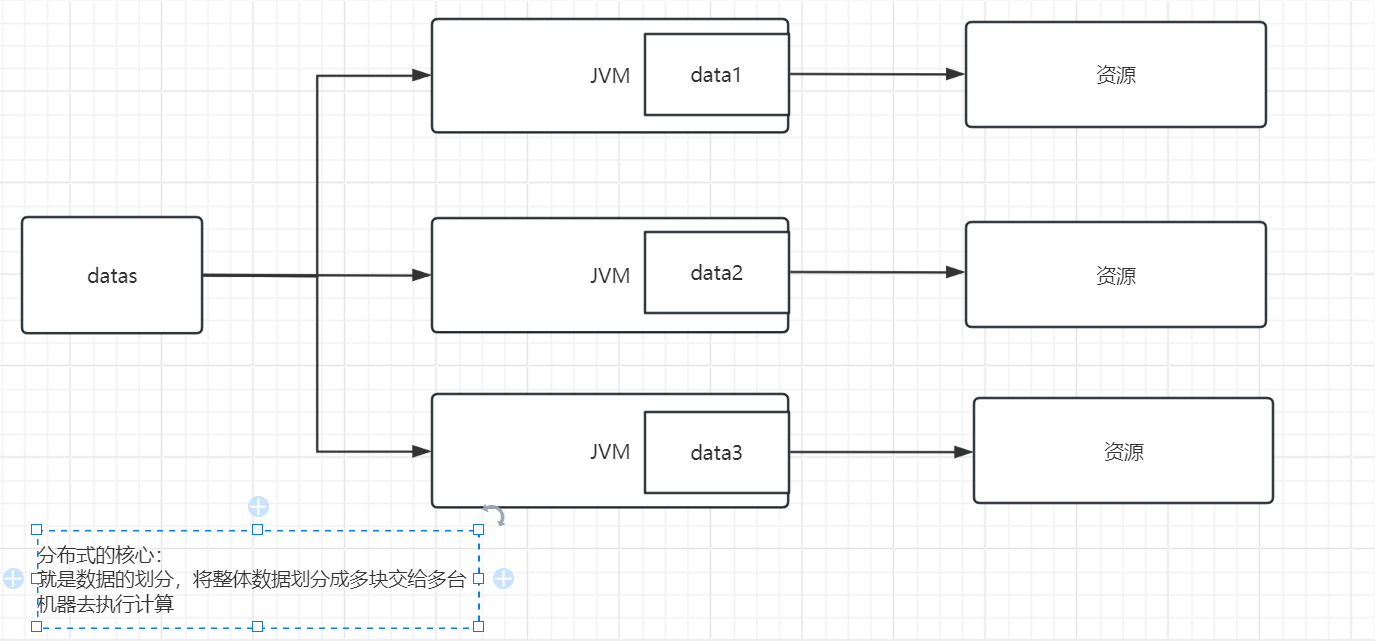
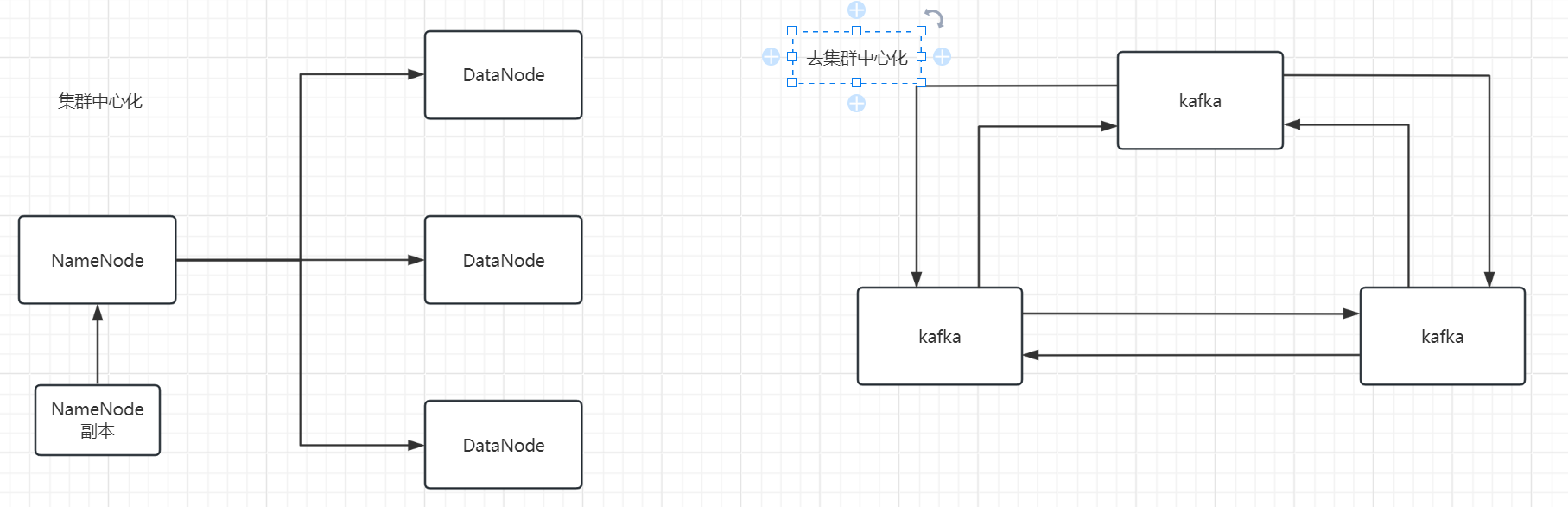
集群分类
提到分布式就不得不提集群,集群分为两种:一种是集群中心化,另一种是集群去中心化
集群中心化的代表就是HDFS:
NameNode管理DataNode,NameNode就是领导,DataNode就是干活的工人,一旦NameNode挂掉了,DataNode就无法干活了。
去集群中心化的代表就是kafka:
就是每一个人都是可以当领导的,只不过为了统一管理随机选出来一个先当领导,当这个挂了的时候,就会选出另一个来,这就是去集群中心化。
Spark执行计算逻辑过程
Spark与MapReduce框架
先说结论, Spark是基于MapReduce框架开发的。
Spark是基于MapReduce的一种使用Scala的语言开发的。
| MapReduce | Spark | |
| 开发语言 | java,不适合大数据 | Scala,适合处理大数据 |
| 处理方式 | 单一的计算 不考虑迭代 | 优化计算过程,计算过程中结果可以放在内存中 |
、
Spark内置模块
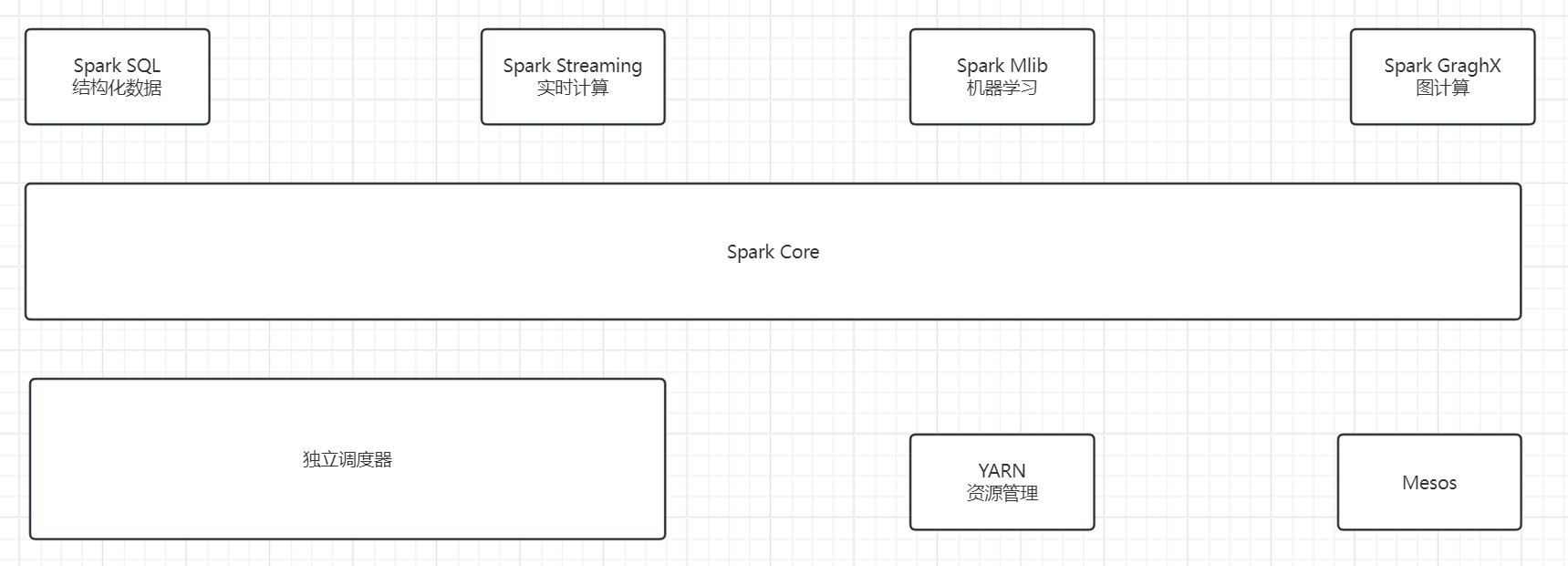
Spark Core:Sprak的核心,所有Spark的基本功能,包括任务调度、内存管理、错误与恢复、与系统交互等。
Spark SQL:可以使用SQL和Hive的HQL可以用来查询结构化数据的数据包。
Spark Streaming:是Spark进行流式计算的组件。
Spark Mlib:提供机器学习功能的程序库。
Spark Graphx:主要用于图形并行计算和图挖掘系统的组件。
Spark 特点
1)快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高校处理数据流。计算的中间结果是存在与内存中的。
2)易用:Spark,支持Java、Python和Scala的API,支持80种高级算法。
3)通用:Spark提供了统一的解决方案
4)兼容性:Spark可以与其他产品做融合,比如Spark可以使用Hadoop的Yarn和Apache Mesos作为他的资源管理器和调度器,并且可以处理所有的Hadoop支持的数据,包括HDFS,HBase等。