1 简介
显示卡(英语:Display Card)简称显卡,也称图形卡(Graphics Card),是个人电脑上以图形处理器(GPU)为核心的扩展卡,用途是提供中央处理器以外的微处理器帮助计算图像信息,并将计算机系统所需要的显示信息进行转换并提供逐行或隔行扫描信号给显示设备,是连接显示器和个人电脑主板的重要组件,是“人机交互”的重要设备之一。显卡有时被称为独立显卡或专用显卡,以强调它们与主板上的集成图形处理器(集成显卡)或中央处理器 (CPU) 的区别。
早期显卡主要用来进行图像显示,其主要应用场景为游戏渲染等领域。而自从深度学习开启21世纪的人工智能热潮之后,显卡也被用来进行计算加速。从此之后,显卡厂商也将显卡的并行计算能力作为衡量显卡性能的标准之一。众多显卡厂商中,其中Nvidia是其中的佼佼者。
为了跟上AI热潮,且我本人对于并行计算也比较感兴趣,因此这里总结下Nvidia显卡架构演进来学习底层硬件结构指导自己。
Nvidia成立于1993年4月,截止2025年,这30年里其发布了众多的显卡型号。每一代显卡都有各自的新特性和新的侧重点,但是总的来说主要分为两种类型架构:早期架构和统一架构。前者因为时间的流逝逐渐被新的显卡型号替代,且不具备太大的参考意义。因此本文主要聚焦统一架构,对于早期架构不会详细描述。
2 早期架构
早期架构并不是一个正式的架构名称,而是为了和后续的统一架构区分。
Nvidia早期架构主要聚焦在提升图形性能,比如提升纹理的处理能力,引入更多硬件加速来提升渲染性能。从刚开始的NV1到典型其市场地位的GeForce256,Nvidia不断提升使得3D Video Game成为了现实。这些早期架构虽然比较简陋,但是正是有这些早期的尝试才有了现如今的辉煌。
2.1 NV1(发布于1995)
NV1 是由 NVIDIA 用了两年研发,于1995年5月发布的显示芯片[1]。它亦是 NVIDIA 自创立起的首款产品。NVIDIA 亦授权 SGS Thomson Microelectronics 生产,芯片型号为 STG2000X B。当时还没有像 Direct3D 的多边形 3D 标准,所以 nVIDIA 使用二次方程纹理贴图作为立体图形的实现方式。它不但拥有完整的 2D/3D 核心,还内置声音处理核心。随后微软在 Windows 95 制订 Direct3D 多边形立体标准,纵使 NV1 的二次方程纹理贴图是出色的技术,但始终不兼容 Direct3D,亦不支持当时还很流行的 Glide,导致该显卡市场上响应不佳。

2.2 RIVA128(发布于1997)
NVIDIA RIVA 128 (1997) 是 NVIDIA 走向成功的关键一步。作为其首款消费级显卡,RIVA 128 并非完美,但它在当时以合理的价格提供了显著的性能提升,特别是对 Direct3D 5.0 的支持使其在游戏中表现出色。它采用 128 位显存接口,在纹理填充率方面表现良好,但缺乏硬件加速的三角形设置引擎是其弱点,在复杂场景中性能会明显下降。尽管如此,RIVA 128 凭借其性价比和相对出色的性能,成功打入市场,为 NVIDIA 赢得了声誉,并为后续 RIVA TNT 等更强大的产品奠定了基础。它标志着 NVIDIA 从一家默默无闻的小公司成长为图形卡市场的重要参与者。

2.3 RIVA TNT(发布于1998)
NVIDIA RIVA TNT (1998) 是 RIVA 128 的继任者,也是 NVIDIA 在图形卡市场取得更大成功的关键。TNT 的核心改进在于其双纹理引擎 (Twin Texel engine),使其能够在每个时钟周期处理两个纹理单元,从而有效地将纹理填充率翻倍,显著提升了游戏性能。这使得 RIVA TNT 在当时成为极具竞争力的产品,赢得了众多游戏玩家的青睐。尽管 RIVA TNT 仍然缺乏硬件加速的三角形设置引擎,这在一定程度上限制了其在复杂 3D 场景中的表现,但凭借其卓越的纹理处理能力和相对较低的价格,它迅速成为市场上的热门选择,进一步巩固了 NVIDIA 在图形卡领域的地位,并为后续的 GeForce 系列铺平了道路。

2.4 GeForce256(发布于1999)
NVIDIA GeForce 256 (1999) 是图形卡发展史上的一个里程碑,通常被认为是“第一款 GPU”。它首次集成了硬件 T&L (Transform and Lighting) 引擎,将顶点转换和光照计算从 CPU 转移到 GPU 处理,极大地提升了 3D 图形的性能。NVIDIA 也正是用这款产品定义了“GPU”一词,强调其作为独立图形处理器的作用。GeForce 256 支持 DirectX 7,拥有出色的单纹理填充率,并引入了立方体环境贴图等先进技术。虽然在多边形处理能力上仍有不足,但 GeForce 256 凭借其革命性的硬件 T&L 设计和卓越的整体性能,迅速成为市场领导者,为现代 GPU 架构奠定了基础,并开启了 NVIDIA 在图形处理器领域的霸主地位。

3 统一架构
NVIDIA 统一架构(Unified Architecture)是 NVIDIA 在 2006 年发布的 GeForce 8 系列显卡中引入的革命性设计。它打破了传统 GPU 中顶点着色器和像素着色器分离的架构,采用统一的着色器单元,可以动态地分配计算资源给任何类型的着色任务。这意味着 GPU 能够更有效地利用其计算能力,不再受限于特定着色器的性能瓶颈。
统一架构还引入了 CUDA (Compute Unified Device Architecture),使 GPU 不仅可以用于图形渲染,还可以用于通用计算。这为 GPU 在科学计算、人工智能等领域开辟了广阔的应用前景。
总而言之,NVIDIA 统一架构通过灵活的资源分配和 CUDA 的引入,极大地提高了 GPU 的效率和通用性,是 GPU 发展史上的一个重要转折点,奠定了现代 GPU 的基础。
3.1 Tesla(2006-2010)
Tesla 架构发布于 2006 年。Tesla 架构全新的 CUDA 架构,支持使用 C 语言进行 GPU 编程,可以用于通用数据并行计算。Tesla 架构具有 128 个流处理器,带宽高达 86GB/s,标志着 GPU 开始从专用图形处理器转变为通用数据并行处理器。
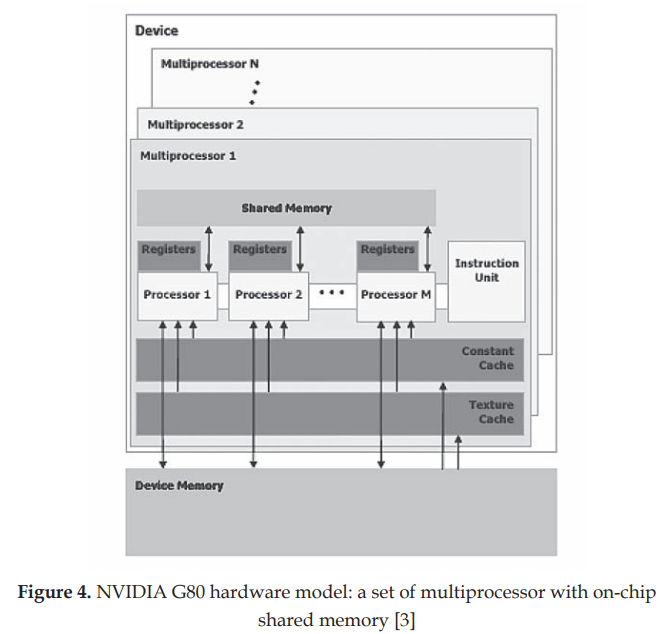
Tesla架构的第一款产品为Nvidia G80。G80 作为 NVIDIA 首款 Tesla 架构的基础,具有以下里程碑式的创新:
- C 语言支持: 首次允许开发者使用熟悉的 C 语言进行 GPU 编程,降低了 GPU 编程的门槛(CUDA)。
- 统一架构: 采用单一、统一的处理器取代了独立的顶点和像素管线,能够灵活执行各种类型的程序(顶点、几何、像素和计算程序)。
- 标量线程处理器: 使用标量线程处理器,简化了编程模型,程序员无需手动管理向量寄存器。
- SIMT 执行模型: 引入单指令多线程 (SIMT) 执行模型,允许多个线程并发执行同一指令,提高了并行效率。
- 线程间通信机制: 提供了共享内存和屏障同步机制,方便线程之间进行数据共享和同步,增强了程序的灵活性。
CUDA 是一种硬件和软件架构,它使 NVIDIA GPU 能够执行使用 C、C++、Fortran、OpenCL、DirectCompute 和其他语言编写的程序。CUDA 程序调用并行内核。内核在一组并行线程上并行执行。程序员或编译器将这些线程组织成线程块和线程块网格。GPU 在并行线程块网格上实例化一个内核程序。线程块中的每个线程执行内核的一个实例,并且在其线程块中具有线程 ID、程序计数器、寄存器、每个线程的私有内存、输入和输出结果。

这些创新使得 G80 不仅在图形处理方面表现出色,也为 GPU 在通用计算领域的应用奠定了坚实的基础,开启了 GPGPU (General-Purpose computing on Graphics Processing Units) 的时代。同时,其全面支持Direct3D 10和DirectX 10 Shader Model 4.0,凭借其内部128位浮点精度、无限长度着色器以及对多重纹理和渲染目标的支持,实现了卓越的图形处理能力。同时,它还集成了NVIDIA Lumenex技术和PureVideo HD技术,分别在图像增强和高清视频处理方面表现出色,并通过SLI技术支持多GPU并行,为用户带来前所未有的视觉体验。
3.2 Fermi(2010-2012)
NVIDIA Fermi 架构是 2010 年发布的一款具有里程碑意义的 GPU 微架构,它标志着 NVIDIA 在 GPU 计算领域的重大突破。作为 Tesla 架构的继任者,Fermi 架构主要应用于 GeForce 400 和 500 系列显卡,以及 Quadro 和 Tesla 系列专业卡,旨在提供卓越的图形性能和强大的并行计算能力。
Fermi 架构的核心在于其对计算的优化。它是 NVIDIA 首个完整的 GPU 计算架构,显著提升了双精度浮点性能,满足了科学计算和工程模拟等领域的需求。它全面兼容 IEEE 754-2008 浮点标准,支持融合乘加运算 (FMA),保证了计算的精度和可靠性。同时,Fermi 架构还引入了 ECC 保护,覆盖从寄存器到 DRAM 的各个环节,提高了数据完整性。
在架构设计上,Fermi 采用了统一寻址模型,简化了内存管理,并实现了所有级别的缓存,提高了数据访问效率。每个流式多处理器 (SM) 最多包含 32 个 CUDA 核心,这些核心能够并行执行大量的线程。此外,Fermi 还采用了可配置的 L1 缓存,允许根据不同的应用场景灵活分配共享内存和 L1 缓存的大小。双 Warp 调度器和双指令分派单元的设计,使得每个 SM 能够并发执行两个 Warp,进一步提升了并行执行效率。
Fermi 架构还特别针对图形处理进行了优化。它包含一个专为曲面细分和位移贴图优化的 PolyMorph 引擎,能够提供更逼真的游戏画面。此外,Fermi 也是 NVIDIA 最早支持 Microsoft Direct3D 12 feature_level 11 渲染 API 的微架构,为新一代游戏和图形应用提供了硬件支持。
尽管 Fermi 架构采用的是 40nm 工艺制造,拥有高达 30 亿个晶体管,但其创新的架构设计和强大的计算能力,为 NVIDIA 在 GPU 领域奠定了坚实的基础。Fermi 架构不仅是一款成功的游戏显卡架构,更是一款重要的 GPU 计算平台,推动了 GPU 在科学研究、人工智能等领域的应用。它以意大利物理学家恩里科·费米的名字命名,也象征着 NVIDIA 在 GPU 技术上的不断创新和突破
总结下来,Fermi架构的关键特性有:
- 计算 GPU: Fermi 是 NVIDIA 首个完整的 GPU 计算架构。
- 双精度浮点性能: 在单芯片上提供高水平的双精度浮点性能。
- IEEE 754-2008 标准: 兼容 IEEE 754-2008 浮点标准,包括融合乘加运算 (FMA)。
- ECC 保护: 提供从寄存器到 DRAM 的 ECC 保护。
- 统一寻址: 具有直接的线性寻址模型,并在所有级别进行缓存。
- CUDA 核心: 每个流式多处理器 (SM) 最多包含 32 个 CUDA 核心。
- 可配置的缓存: 每个 SM 的 L1 缓存可配置为支持共享内存以及本地和全局内存操作的缓存。64 KB 内存可以配置为 48 KB 共享内存 + 16 KB L1 缓存,或 16 KB 共享内存 + 48 KB L1 缓存。
- 双 Warp 调度器: 每个 SM 具有两个 Warp 调度器和两个指令分派单元,允许并发执行两个 Warp。
- 多线程: 多个线程被分组到最多包含 1,536 个线程的线程块中。
- PolyMorph 引擎: Fermi 架构包含一个 PolyMorph 引擎,专为曲面细分和位移贴图优化。
3.2.1 Fermi Architecture Overview
首款基于 Fermi 的 GPU 拥有高达 512 个 CUDA 核心,由 30 亿个晶体管实现。每个 CUDA 核心在一个时钟周期内为一个线程执行一个浮点或整数指令。这 512 个 CUDA 核心被组织成 16 个 SM(流式多处理器),每个 SM 包含 32 个核心。该 GPU 具有六个 64 位内存分区,构成一个 384 位内存接口,最多支持总计 6 GB 的 GDDR5 DRAM 内存。主机接口通过 PCI-Express 将 GPU 连接到 CPU。GigaThread 全局调度器将线程块分发到 SM 线程调度器。
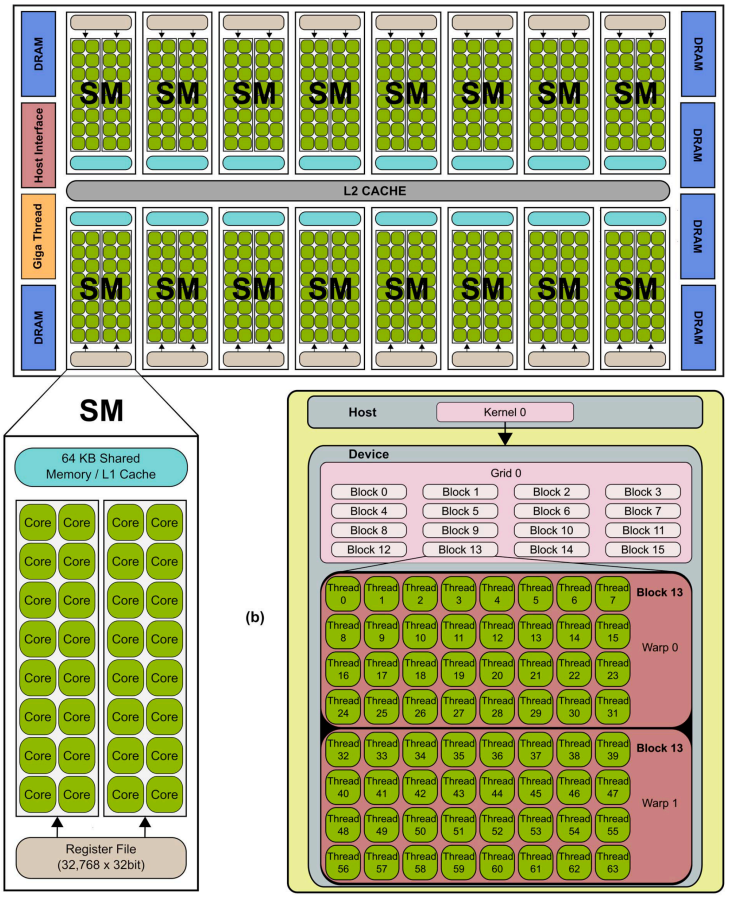
3.2.2 Stream Multiprocessor(SM)
每个 SM 具有 32 个 CUDA 处理器,比之前的 SM 设计增加了四倍。每个 CUDA 处理器都有一个完全流水线的整数算术逻辑单元 (ALU) 和浮点单元 (FPU)。之前的 GPU 使用 IEEE 754-1985 浮点运算。Fermi 架构实现了新的 IEEE 754-2008 浮点标准,为单精度和双精度算术运算提供了融合乘加 (FMA) 指令。FMA 通过在单个最终舍入步骤中完成乘法和加法,而不在加法中损失精度,从而改进了乘加 (MAD) 指令。FMA 比单独执行操作更准确。GT200 实现了双精度 FMA。
在 GT200 中,整数 ALU 的乘法运算精度限制为 24 位;因此,整数算术运算需要多指令仿真序列。在 Fermi 中,新设计的整数 ALU 支持所有指令的完整 32 位精度,与标准编程语言要求一致。整数 ALU 也经过优化,可以有效地支持 64 位和扩展精度运算。支持各种指令,包括布尔运算。
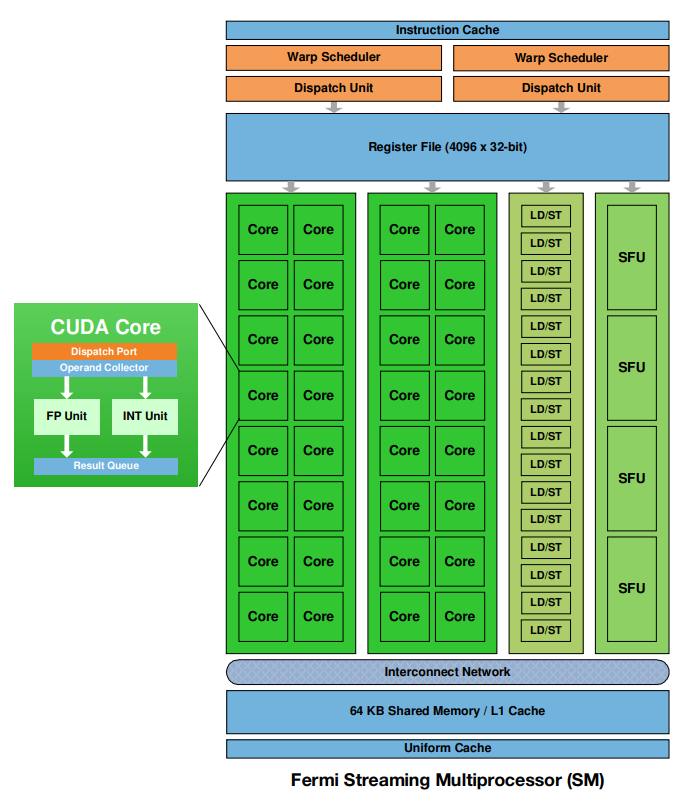
SM中除了CUDA核心,还有其他负责数据传输和特殊运算的单元:
- Warp 调度器(Warp Schedulers): 每个 SM 有两个 Warp 调度器。每个调度器从其准备就绪的 Warps 中选择一个 Warp 执行。 双 Warp 调度器允许每个时钟周期从两个不同的 Warps 发出两条指令。 这种双重调度能力提高了 SM 的吞吐量,并有助于隐藏延迟。
- 分派单元(Dispatch Units): 与 Warp 调度器配对,每个 SM 有两个分派单元。 每个分派单元负责将 Warp 调度器选择的指令分派给 CUDA 核心或其他执行单元。 两个分派单元允许每个时钟周期分派两条指令,从而提高指令吞吐量。
- 寄存器文件(Register File): 用于存储线程的局部变量和临时数据。 Fermi 架构具有较大的寄存器文件,为每个 SM 提供更多的寄存器。 增加的寄存器数量减少了对全局内存的访问,提高了性能。
- 加载/存储单元(LD/ST Units): 负责从内存加载数据和将数据存储到内存。 Fermi 架构具有专用的加载/存储单元,以高效地处理内存访问操作。 这些单元支持各种内存访问模式,包括对齐和非对齐的访问。
- 特殊功能单元(SFU): 用于执行特殊功能指令,如三角函数、指数函数和对数函数。 Fermi 架构具有专用的 SFU,以加速这些计算密集型操作。 SFU 允许 GPU 高效地执行复杂的数学计算,这对于图形渲染和科学计算至关重要。
3.3 Kepler(2012-2014)
3.3.1 Kepler Overview
NVIDIA Kepler 架构是继 Fermi 架构之后,于 2012 年推出的 GPU 微架构。它主要应用于 GeForce 600、700 系列显卡,以及 Quadro 和 Tesla 系列专业卡。Kepler 架构在能效比和计算能力上都取得了显著的进步,旨在提供更出色的图形性能和更强大的并行计算能力。
Kepler 架构的核心改进在于其对能效的优化。相较于 Fermi,Kepler 采用了更先进的 28nm 工艺制造,降低了功耗和发热量。它引入了动态超频技术 GPU Boost,能够根据负载自动调整 GPU 的频率,在保证性能的同时降低功耗。此外,Kepler 还采用了更高效的 SMX (Streaming Multiprocessor eXtreme) 设计,取代了 Fermi 架构的 SM。
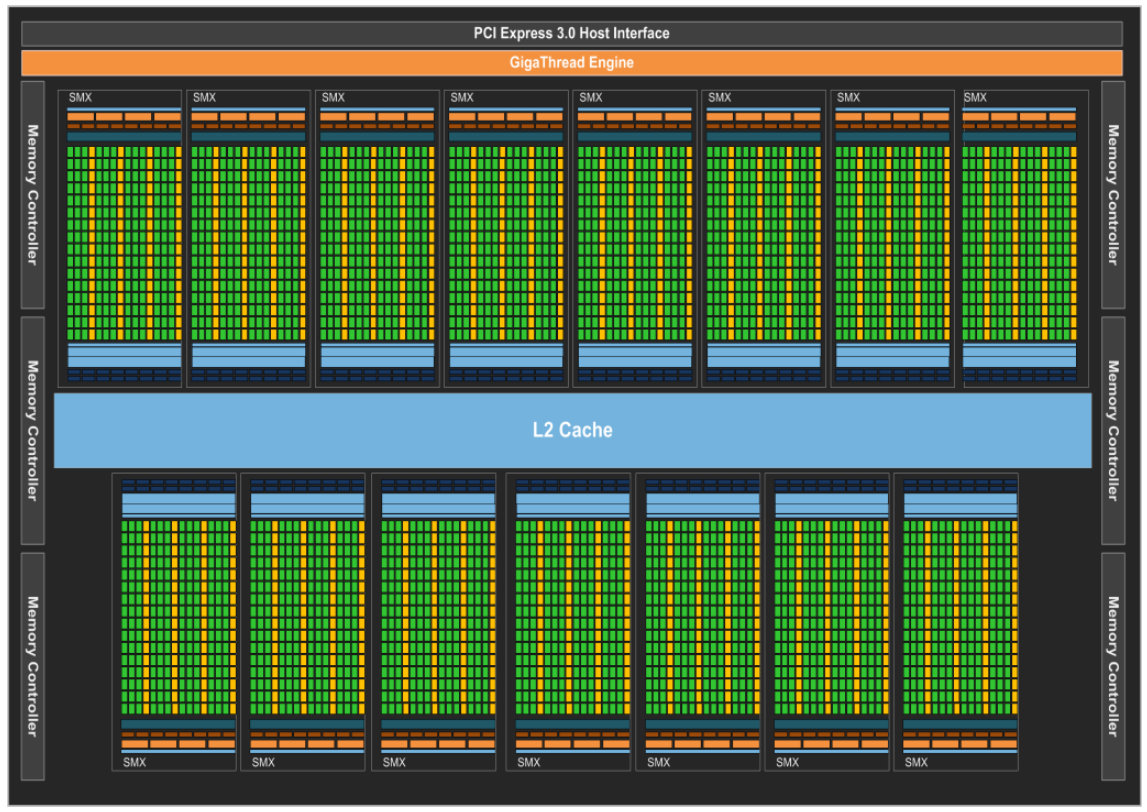
Kepler 架构还增强了图形处理能力。它支持 TXAA 抗锯齿技术,能够提供更平滑的游戏画面。此外,Kepler 还支持 NVIDIA 的 NVENC 视频编码器,能够加速视频编码过程,提高视频编辑和流媒体应用的效率。
在计算方面,Kepler 架构提升了单精度浮点性能,但降低了双精度浮点性能。这是因为 NVIDIA 将 Kepler 架构定位为主要面向游戏和图形应用,而这些应用对单精度浮点性能的需求更高。对于需要高双精度浮点性能的应用,NVIDIA 提供了 Tesla 系列专业卡,这些卡采用了 Kepler 架构的特殊版本,保留了较高的双精度浮点性能。
总的来说,Kepler 架构是一款成功的 GPU 微架构,它在能效比、图形性能和计算能力上都取得了显著的进步。它为 NVIDIA 在 GPU 领域保持领先地位奠定了坚实的基础,并推动了 GPU 在游戏、图形、人工智能等领域的应用。
3.3.2 Streaming Multiprocessor (SMX)
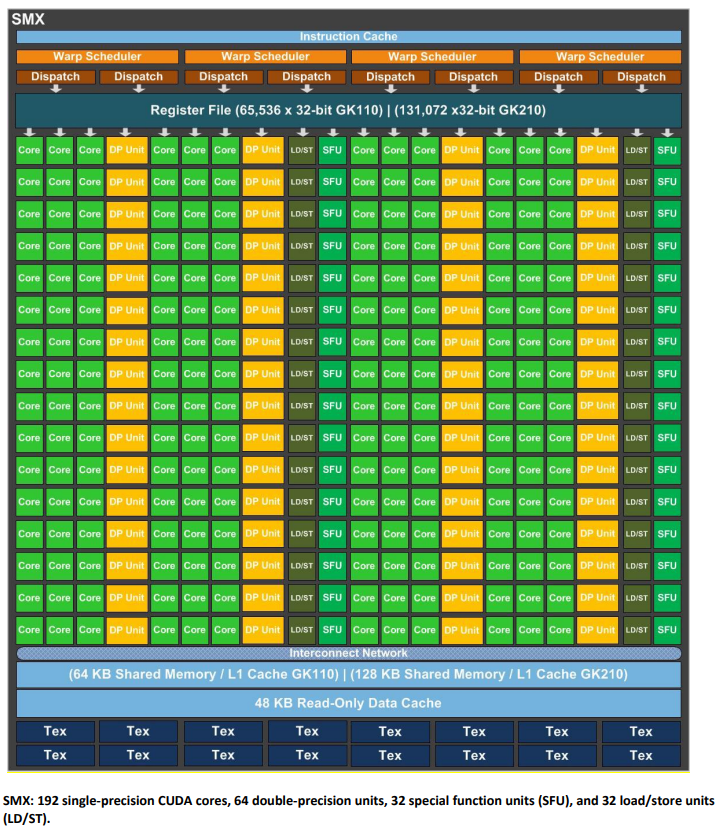
SMX 单元拥有 192 个单精度 CUDA 核心,每个核心都具备完整的浮点和整数运算单元,并保留了 Fermi 架构引入的 IEEE 754-2008 标准的单精度和双精度运算,包括 FMA 操作。Kepler 的设计目标之一是显著提升双精度性能,这对于高性能计算至关重要。此外,它还保留了用于快速近似超越运算的特殊功能单元 (SFU),数量是 Fermi GF110 SM 的 8 倍。与 GK104 SMX 单元类似,GK110/210 SMX 单元中的核心使用主 GPU 时钟,而非之前的 2 倍 Shader 时钟。Kepler 的重点是每瓦性能,因此选择使用更多的核心以较低的 GPU 时钟运行,从而优化功耗,即使这意味着增加了一些面积成本。
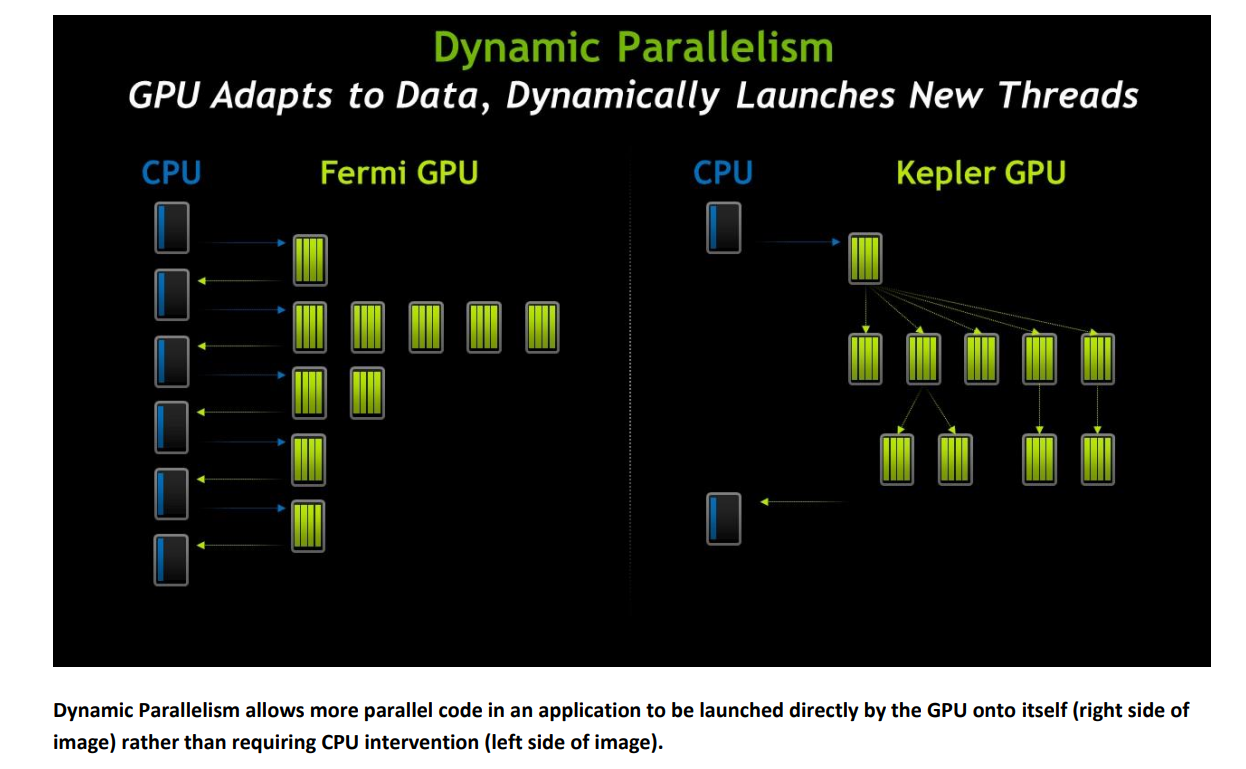
3.3.3 Dynamic Parallelism
Kepler 架构引入的动态并行(Dynamic Parallelism)是一项重要的创新,它极大地提升了 GPU 的灵活性和效率。在之前的 GPU 架构中,GPU 只能由 CPU 发起 kernel 函数,并且 kernel 函数的执行是静态的,无法在 GPU 内部动态地启动新的 kernel 函数。这意味着所有的任务调度和同步都必须由 CPU 来完成,限制了 GPU 的并行能力和效率。
动态并行的核心思想是允许 GPU 在执行 kernel 函数的过程中,动态地启动新的 kernel 函数,而无需 CPU 的干预。这意味着 GPU 可以根据实际的计算需求,自主地进行任务调度和同步,从而更好地利用 GPU 的并行计算资源。
3.4 Maxwell(2014-2016)
3.4.1 Maxwell Architecture Overview
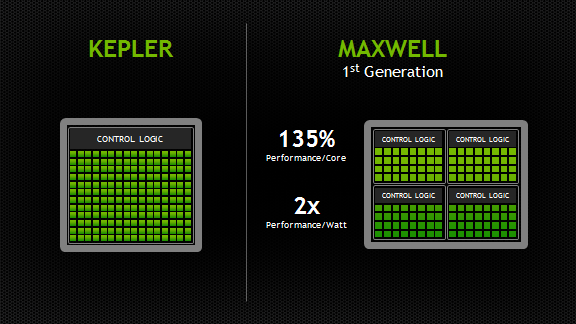
Maxwell 架构作为 NVIDIA 在 Kepler 之后推出的 GPU 微架构,其核心目标是显著提升能效比,并在图形性能和功能上进行优化。与 Kepler 相比,Maxwell 的主要新特性和区别体现在以下几个方面:
- SM 设计的重大改进: Maxwell 架构重新设计了流式多处理器 (SM),将其划分为更小的处理单元,每个单元包含更少的 CUDA 核心。这种设计使得 Maxwell 能够更精细地控制功耗,并更好地利用 GPU 的并行计算资源。具体来说,Maxwell 的 SM 包含 128 个 CUDA 核心,分为 4 个独立的调度器和 4 个 32 核心的处理块,而 Kepler 的 SMX 则包含 192 个 CUDA 核心。
- 能效比的显著提升: 通过对 SM 设计的优化和寄存器文件的改进,Maxwell 架构在能效比上实现了显著的提升。这意味着在相同功耗下,Maxwell 能够提供更高的性能。
- 图形性能和功能的改进: Maxwell 架构支持 NVIDIA 的 VXGI (Voxel Global Illumination) 技术,能够提供更逼真的光照效果。此外,Maxwell 还支持多帧采样抗锯齿 (MFAA) 技术,能够以较低的性能代价提供高质量的抗锯齿效果。
- 视频编码的改进: Maxwell 架构引入了新的 NVENC 视频编码器,能够提供更高的编码效率和更好的视频质量。此外,Maxwell 架构还支持 HDCP 2.2,能够播放受保护的 4K 内容。
- L2 缓存的改进: 在 Maxwell 架构的 GM20x 版本中,NVIDIA 增加了 L2 缓存的容量,提高了显存带宽,从而进一步提升了性能。
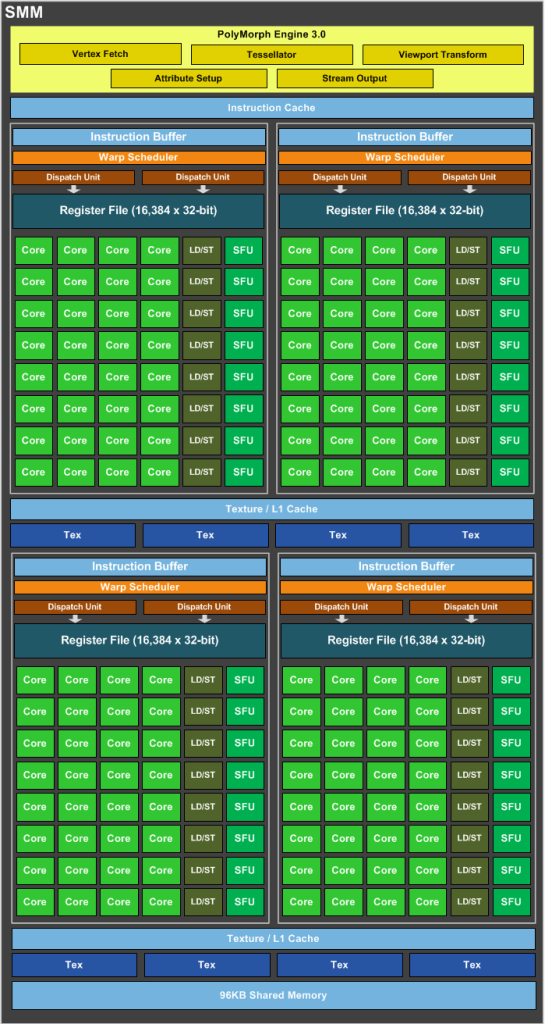
3.4.2 SMM: The Maxwell Multiprocessor
Maxwell 架构能效表现的核心在于其流式多处理器,即 SMM。Maxwell 的全新数据路径组织和改进的指令调度器,每个 CUDA 核心提供的性能提升超过 40%,整体效率是 Kepler GK104 的两倍。新的 SMM 包含了第一代 Maxwell 的所有架构优势,包括控制逻辑分区、工作负载平衡、时钟门控粒度、指令调度、每个时钟周期发出的指令数量等方面的改进。SMM 采用基于象限的设计,包含四个 32 核处理块,每个块都有一个专用的 warp 调度器,能够每个时钟周期分派两条指令。每个 SMM 提供八个纹理单元、一个多形引擎(用于图形的几何处理),以及专用的寄存器文件和共享内存。
3.5 Pascal (2016-2017)
3.5.1 Pascal Architecture Overview
Pascal 架构是 NVIDIA 在 Maxwell 之后推出的 GPU 微架构,主要应用于 GeForce 10 系列和 Tesla P100 等显卡。Pascal 架构在性能、能效和功能方面都实现了显著的提升。以下是 Pascal 架构的一些新特性:
- 16nm FinFET 工艺: Pascal 架构采用了 16nm FinFET 制造工艺,相比 Maxwell 的 28nm 工艺,晶体管密度更高,功耗更低,从而提高了性能和能效。
- SM 设计的改进: Pascal 架构的 SM 包含 64-128 个 CUDA 核心 (取决于 GP100 还是 GP104 芯片),改进了 SM 的调度器和指令分派机制,提高了 SM 的效率。引入了并发指令调度技术,允许 SM 同时执行多个独立的指令,从而进一步提高了性能。
- HBM2 和 GDDR5X 显存: Pascal 架构采用了 HBM2 和 GDDR5X 两种显存技术。HBM2 具有更高的带宽和更低的功耗,主要应用于 Tesla P100 等高性能计算卡。GDDR5X 则具有更高的频率和更大的容量,主要应用于 GeForce 10 系列显卡。
- NVLink 互联技术: Pascal 架构引入了 NVLink 技术,能够提供更高的带宽和更低的延迟,主要应用于 Tesla P100 等高性能计算卡,用于连接多个 GPU 和 CPU。
- FP16 计算支持: Pascal 架构支持 FP16 (半精度浮点数) 计算,能够加速深度学习的训练和推理。
- CUDA 8.0: Pascal 架构支持 CUDA 8.0,提供了更丰富的 API 和工具,方便开发者进行 GPU 编程.
- 统一内存 (Unified Memory): CPU 和 GPU 可以访问主系统内存和显卡上的内存,这要归功于一种称为“页面迁移引擎”的技术。
- 动态负载平衡调度系统: 允许调度程序动态调整分配给多个任务的 GPU 数量,确保 GPU 保持工作饱和状态,除非没有更多可以安全地分配以进行分配的工作。
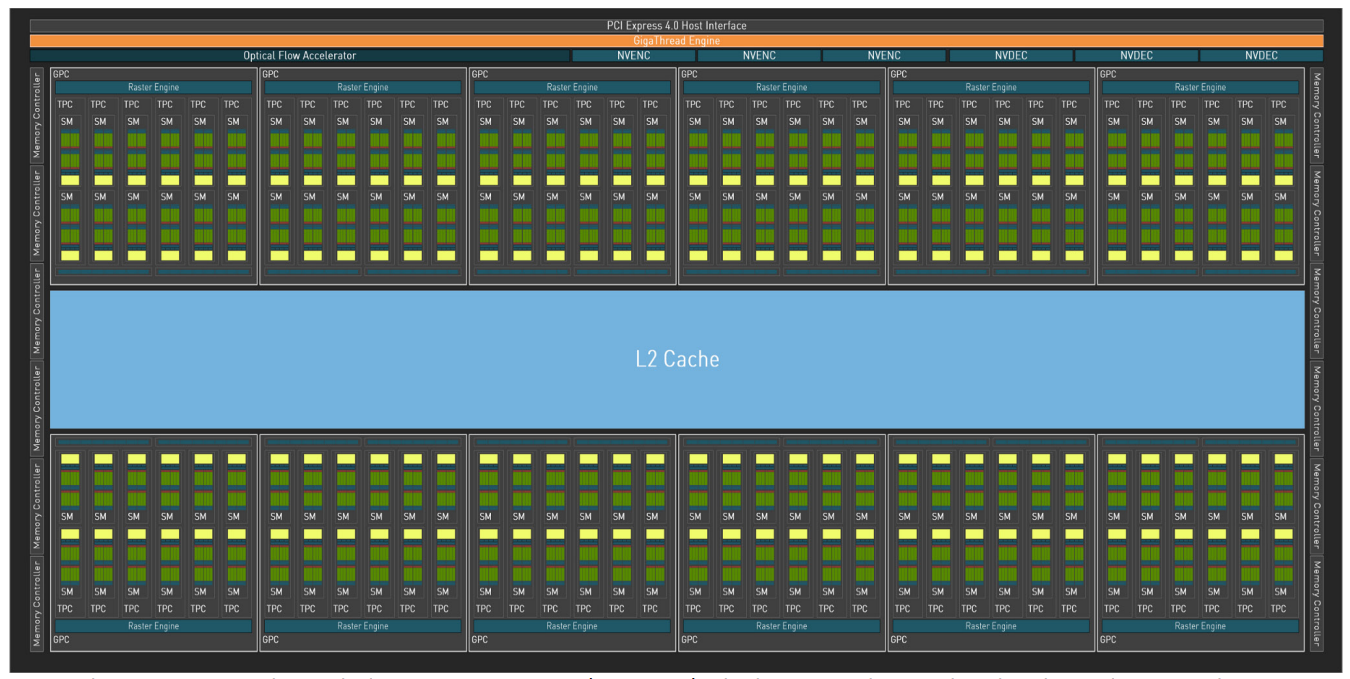
总的来说,Pascal 架构在制造工艺、SM 设计、显存技术、互联技术和计算能力等方面都进行了重大改进,为深度学习、高性能计算和游戏等领域带来了革命性的变革。(下图是GP100的架构图,其他类型的架构类似区别是不同的CUDA核心和SM数量)

3.5.2 Stream Multiprocessor
Pascal 架构的 SM (Streaming Multiprocessor) 相比于前代 Maxwell 架构的 SM,主要区别体现在以下几个方面:
- CUDA 核心数量: Pascal 架构的 SM 中 CUDA 核心的数量取决于具体的芯片型号。在 GP100 芯片中,每个 SM 包含 64 个 CUDA 核心,而在 GP104 芯片中,每个 SM 包含 128 个 CUDA 核心。相比之下,Maxwell 架构的 GM204 芯片中,每个 SM 包含 128 个 CUDA 核心。
- 调度器和指令分派机制的改进: Pascal 架构改进了 SM 的调度器和指令分派机制,提高了 SM 的效率。Pascal 架构引入了并发指令调度 (Concurrent Instruction Scheduling) 技术,允许 SM 同时执行多个独立的指令,从而进一步提高了性能。
- FP16 计算支持: Pascal 架构的 SM 支持 FP16 (半精度浮点数) 计算,能够加速深度学习的训练和推理。Maxwell 架构的 SM 则不支持 FP16 计算。
- 统一内存 (Unified Memory): CPU 和 GPU 可以访问主系统内存和显卡上的内存,这要归功于一种称为“页面迁移引擎”的技术。
- 动态负载平衡调度系统: 允许调度程序动态调整分配给多个任务的 GPU 数量,确保 GPU 保持工作饱和状态,除非没有更多可以安全地分配以进行分配的工作。
总的来说,Pascal 架构的 SM 在调度器和指令分派机制、FP16 计算支持和 CUDA 8.0 支持等方面都进行了改进,从而提高了性能和效率。
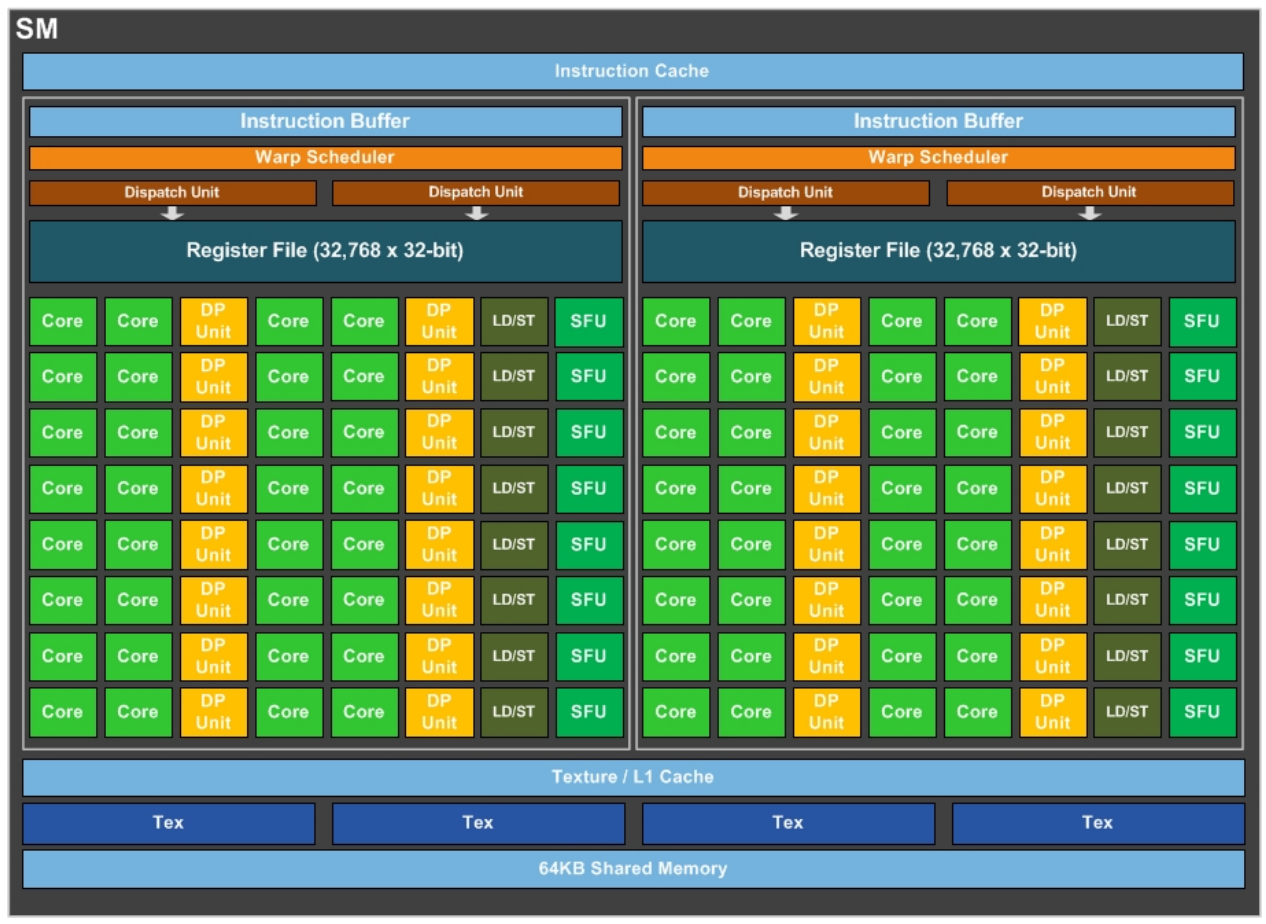
图上的黄色部分DPUnit为双精度运算单元。
3.6 Volta (2017-2018)
3.6.1 Volta Architecture Overview
Volta 架构是 NVIDIA 在 Pascal 架构之后推出的 GPU 微架构,主要应用于 Tesla V100 等高性能计算卡。Volta 架构在深度学习性能方面实现了显著的提升,为人工智能领域带来了新的突破。 Volta 架构的核心目标是加速深度学习的训练和推理。为了实现这一目标,Volta 架构在 SM (Streaming Multiprocessor) 设计、显存技术、互联技术和计算能力等方面都进行了重大改进。
Volta 架构的 SM 包含 640 个 CUDA 核心和 80 个 Tensor 核心。Tensor 核心是 Volta 架构中新增的专门用于加速深度学习计算的硬件单元。每个 Tensor 核心能够执行混合精度浮点运算 (FP16 和 FP32),从而加速深度学习模型的训练和推理。
在显存技术方面,Volta 架构采用了 HBM2 (High Bandwidth Memory 2) 显存,能够提供更高的带宽和更低的功耗。
在互联技术方面,Volta 架构引入了 NVLink 2.0 技术,能够提供更高的带宽和更低的延迟。NVLink 2.0 技术主要应用于 Tesla V100 等高性能计算卡,用于连接多个 GPU 和 CPU。
在计算能力方面,Volta 架构支持 CUDA 9.0,提供了更丰富的 API 和工具,方便开发者进行 GPU 编程。此外,Volta 架构还支持独立线程调度 (Independent Thread Scheduling),能够提高 GPU 的利用率。
Volta 架构的主要特点包括:
- Tensor 核心: Volta 架构中新增的专门用于加速深度学习计算的硬件单元,能够执行混合精度浮点运算 (FP16 和 FP32)。
- HBM2 显存: 能够提供更高的带宽和更低的功耗。
- NVLink 2.0 技术: 能够提供更高的带宽和更低的延迟。
- CUDA 9.0: 提供了更丰富的 API 和工具,方便开发者进行 GPU 编程。
- 独立线程调度: 能够提高 GPU 的利用率。

3.6.2 Volta Streaming Multiprocessor
Volta 架构的 SM (Streaming Multiprocessor) 单元的组成是其核心创新之一,尤其是在深度学习性能方面。与之前的 Pascal 架构相比,Volta 的 SM 单元进行了重大改进。以下是 Volta SM 单元的主要组成部分:
- CUDA 核心 (CUDA Cores): Volta 架构的 SM 包含 640 个 CUDA 核心。这些核心用于执行传统的浮点和整数运算,是 GPU 通用计算的基础。
- Tensor 核心 (Tensor Cores): 这是 Volta 架构中最显著的创新。每个 SM 包含 8 个 Tensor 核心。 Tensor 核心专门设计用于加速深度学习中的矩阵乘法运算,尤其是在训练神经网络时。 Tensor 核心能够高效地执行混合精度浮点运算 (FP16 乘法和 FP32 累加),从而显著提高深度学习模型的训练速度。
- L1 Cache 和共享内存 (Shared Memory): Volta 架构的 SM 共享一个统一的 128KB L1 Cache 和共享内存。 这个统一的内存池可以灵活地配置为 L1 Cache 或共享内存,以适应不同的工作负载。 L1 Cache 用于缓存常用的数据,减少对全局内存的访问,提高性能。 共享内存允许 SM 中的线程共享数据,实现高效的线程间通信。
- 纹理单元 (Texture Units): Volta 架构的 SM 仍然包含纹理单元,用于执行纹理过滤等操作。 虽然 Volta 架构主要关注深度学习,但它仍然保留了对传统图形应用的支持。
- 调度器 (Schedulers) 和分派单元 (Dispatch Units): Volta 架构的 SM 包含多个调度器和分派单元,用于管理和分配线程的执行。 这些调度器和分派单元能够高效地利用 SM 中的各个单元,实现高吞吐量。

3.7 Turing (2018-2020)
3.7.1 Turing Architecture Overview
图灵 (Turing) 架构是 NVIDIA 在 Volta 架构之后推出的 GPU 微架构。 它主要应用于 GeForce RTX 20 系列和 Quadro RTX 系列显卡。 图灵架构在游戏和专业可视化领域引入了多项创新技术,例如光线追踪和深度学习超采样 (DLSS)。
图灵架构的核心目标是实现实时光线追踪和 AI 增强图形。 为了实现这些目标,图灵架构在 SM (Streaming Multiprocessor) 设计、显存技术、光线追踪单元和 AI 核心等方面都进行了重大改进。
图灵架构的 SM 包含 CUDA 核心、Tensor 核心和 RT 核心 (光线追踪核心)。 CUDA 核心用于执行传统的浮点和整数运算。 Tensor 核心用于加速深度学习计算。 RT 核心则专门用于加速光线追踪计算。
在显存技术方面,图灵架构采用了 GDDR6 显存,能够提供更高的带宽和更低的功耗。
图灵架构的主要特点包括:
- RT 核心 (Ray Tracing Cores): 图灵架构中新增的专门用于加速光线追踪计算的硬件单元。 RT 核心能够加速光线与三角形的相交测试,从而实现实时光线追踪。
- Tensor 核心 (Tensor Cores): 图灵架构的 Tensor 核心经过改进,能够更高效地执行深度学习计算。 Tensor 核心主要用于加速 DLSS (Deep Learning Super-Sampling) 等 AI 增强图形技术。
- GDDR6 显存: 能够提供更高的带宽和更低的功耗。
- Mesh Shading: 一种新的几何处理技术,能够提高复杂场景的渲染效率。
- 可变速率着色 (Variable Rate Shading, VRS): 一种新的着色技术,能够根据图像内容调整着色速率,从而提高性能。
- NVIDIA NGX: 一种新的神经网络图形框架,能够简化 AI 增强图形技术的开发。
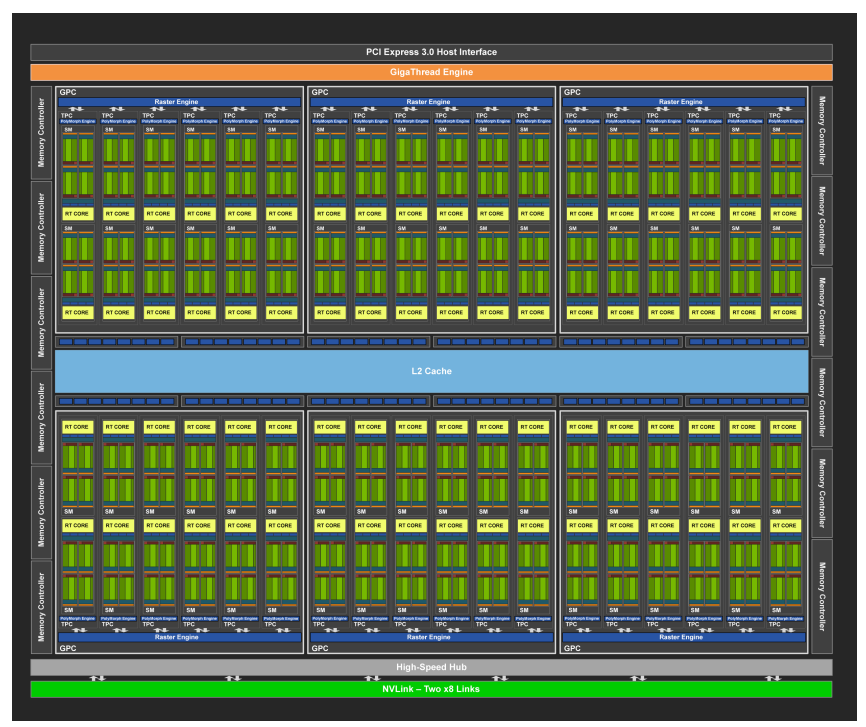
3.7.2 Turing Streaming Multiprocessor
图灵 (Turing) 架构的 SM (Streaming Multiprocessor) 单元在设计上借鉴了 Volta GV100 架构的许多特性,并进行了改进。主要特点:
- 数量和组成: 每个 TPC (Texture Processing Cluster) 包含两个 SM。 每个 SM 包含 64 个 FP32 核心 (用于浮点运算) 和 64 个 INT32 核心 (用于整数运算)。 相比之下,Pascal GP10x GPU 每个 TPC 只有一个 SM,每个 SM 有 128 个 FP32 核心。
- 并行执行: 图灵 SM 支持 FP32 和 INT32 操作的并行执行,以及类似于 Volta GV100 GPU 的独立线程调度。
- 专用核心: 每个图灵 SM 还包含 8 个混合精度图灵 Tensor 核心 (用于加速深度学习) 和 1 个 RT 核心 (用于加速光线追踪)。
- 处理块: 图灵 SM 被划分为四个处理块,每个块包含 16 个 FP32 核心、16 个 INT32 核心、2 个 Tensor 核心、1 个 warp 调度器和 1 个分派单元。
- 缓存: 每个处理块包含一个新的 L0 指令缓存和一个 64 KB 寄存器文件。 四个处理块共享一个组合的 96 KB L1 数据缓存/共享内存。
- 内存分配: 对于传统的图形工作负载,96 KB L1/共享内存被划分为 64 KB 的专用图形着色器 RAM 和 32 KB 的纹理缓存和寄存器文件溢出区域。 对于计算工作负载,可以将 96 KB 划分为 32 KB 共享内存和 64 KB L1 缓存,或 64 KB 共享内存和 32 KB L1 缓存。
- 执行数据路径: 图灵架构对核心执行数据路径进行了重大改进。 它在每个 CUDA 核心旁边增加了一个并行的执行单元,用于并行执行整数运算等非浮点运算指令,从而提高了效率
3.8 Ampere (2020-2022)
3.8.1 Ampere Architecture Overview
Ampere 架构是 NVIDIA 在 Turing 架构之后推出的 GPU 微架构。 它主要应用于 GeForce RTX 30 系列显卡和 NVIDIA A100 等数据中心 GPU。 Ampere 架构在游戏、专业可视化和数据中心等领域都实现了显著的性能提升。
Ampere 架构的核心目标是提高 GPU 的计算效率和性能,尤其是在人工智能和高性能计算方面。 为了实现这些目标,Ampere 架构在 SM (Streaming Multiprocessor) 设计、显存技术、Tensor 核心和互联技术等方面都进行了重大改进。
Ampere 架构的 SM 在 Turing 架构的基础上进行了重新设计,提高了 FP32 和 INT32 的吞吐量。 Ampere 架构的 SM 包含更多的 CUDA 核心,能够提供更高的计算性能。
在显存技术方面,Ampere 架构采用了 GDDR6X 显存 (在 GeForce RTX 3080 和 RTX 3090 上) 和 HBM2e 显存 (在 NVIDIA A100 上),能够提供更高的带宽和更低的功耗。
Ampere 架构的主要特点包括:
- 第二代 RT 核心 (2nd Generation Ray Tracing Cores): Ampere 架构的 RT 核心在第一代的基础上进行了改进,能够提供更高的光线追踪性能。
- 第三代 Tensor 核心 (3rd Generation Tensor Cores): Ampere 架构的 Tensor 核心在第二代的基础上进行了改进,能够更高效地执行深度学习计算。 Ampere 架构的 Tensor 核心支持稀疏性 (sparsity),能够进一步提高深度学习模型的训练和推理速度。
- GDDR6X 显存: 能够提供更高的带宽和更低的功耗 (仅限部分型号)。
- HBM2e 显存: 能够提供更高的带宽和更低的功耗 (仅限部分型号)。
- PCIe 4.0: 支持 PCIe 4.0,能够提供更高的带宽。
- NVLink 3.0: Ampere 架构引入了 NVLink 3.0 技术,能够提供更高的带宽和更低的延迟 (仅限部分型号)。
- 多实例 GPU (Multi-Instance GPU, MIG): Ampere 架构支持 MIG 技术,可以将一个 GPU 划分为多个独立的 GPU 实例,从而提高 GPU 的利用率 (仅限部分型号)。
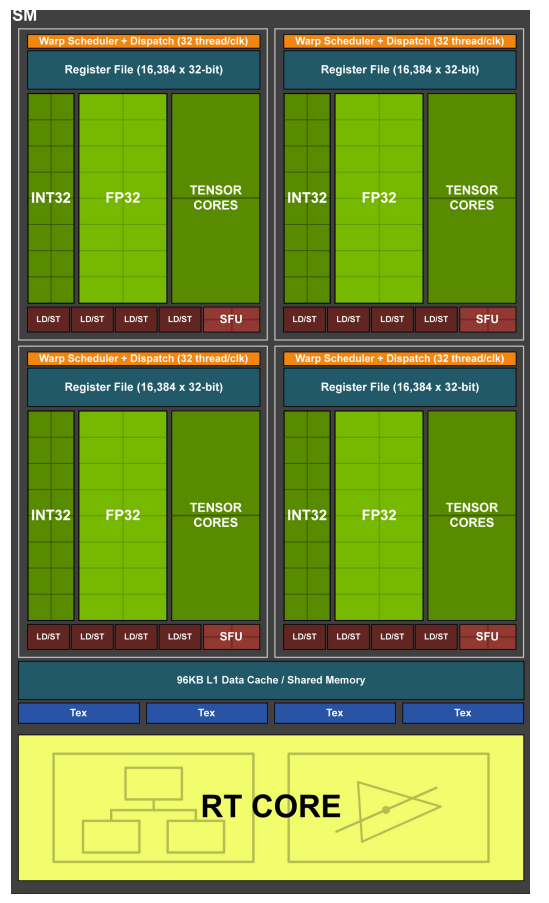
3.8.2 Ampere Streaming Multiprocessor
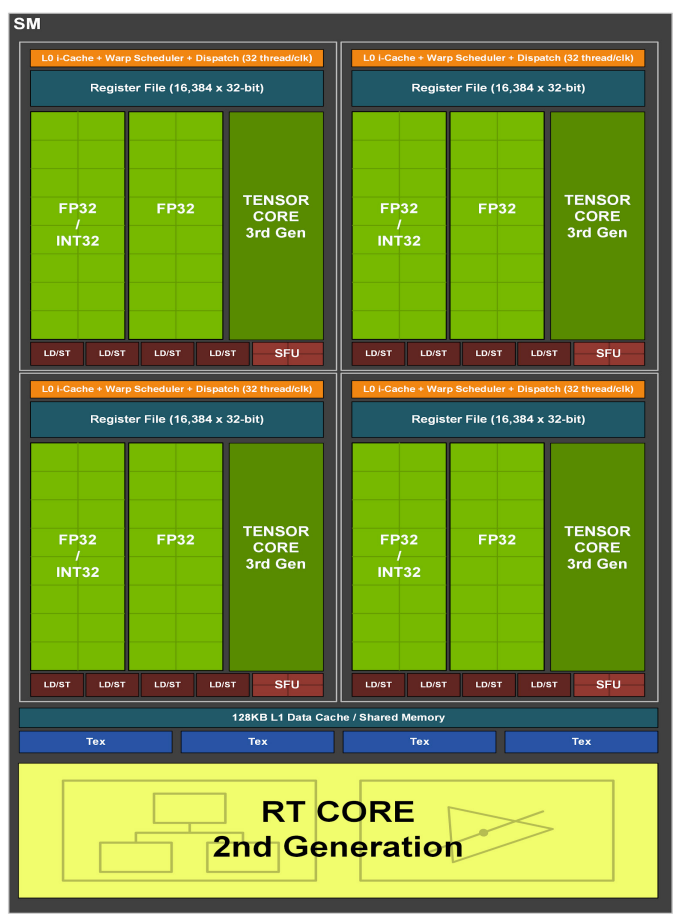
Ampere 架构对 SM 进行了重大改进,使其在性能和效率方面都得到了提升。与 Turing 架构相比,Ampere SM 的主要变化包括:
- 更高的 FP32 吞吐量:
- 在 Turing 架构中,SM 包含独立的 FP32 (浮点) 和 INT32 (整数) 单元。Ampere 架构将 FP32 的吞吐量翻倍。
- Ampere SM 中的每个分区都包含 16 个 FP32 CUDA 核心,这些核心可以并行执行 FP32 运算。这意味着 Ampere 架构在处理图形和计算任务时,可以更快地完成浮点运算。
- 独立的 FP32 和 INT32 数据路径:与 Turing 架构类似,Ampere 架构也保留了独立的 FP32 和 INT32 数据路径,允许并行执行浮点和整数运算。这对于现代着色器和计算工作负载非常重要,因为它们通常需要混合使用浮点和整数运算。
- 改进的 Tensor 核心:
- Ampere 架构配备了第三代 Tensor 核心,与 Turing 架构的第二代 Tensor 核心相比,性能得到了显著提升。
- 第三代 Tensor 核心支持稀疏性 (Sparsity),这是一种利用神经网络中零值数据的技术,可以进一步提高深度学习模型的训练和推理速度。
- 更大的 L1 缓存:Ampere 架构的 L1 缓存容量更大,可以减少对全局内存的访问,提高性能。
- 统一的共享内存和 L1 缓存: 与 Turing 架构类似,Ampere 架构也采用了统一的共享内存和 L1 缓存,可以灵活地配置以适应不同的工作负载。
3.9 Ada Lovelace (2022-至今)
3.9.1 Ada Lovelace Architecture Overview
Ada Lovelace 架构是 NVIDIA 在 Ampere 架构之后推出的最新一代 GPU 微架构。 它主要应用于 GeForce RTX 40 系列显卡。 Ada Lovelace 架构在游戏、专业可视化和人工智能等领域都带来了显著的性能提升和创新技术。
Ada Lovelace 架构的核心目标是实现更高的性能和效率,并提供更逼真的图形效果。 为了实现这些目标,Ada Lovelace 架构在 SM (Streaming Multiprocessor) 设计、显存技术、光线追踪单元和 AI 核心等方面都进行了重大改进。
Ada Lovelace 架构的主要特点包括:
- 第三代 RT 核心 (3rd Generation Ray Tracing Cores): Ada Lovelace 架构的 RT 核心在第二代的基础上进行了改进,能够提供更高的光线追踪性能。 新的 RT 核心引入了 Displaced Micro-Meshes 和 Opacity Micromaps 等技术,可以更高效地处理复杂的光线追踪场景。
- 第四代 Tensor 核心 (4th Generation Tensor Cores): Ada Lovelace 架构的 Tensor 核心在第三代的基础上进行了改进,能够更高效地执行深度学习计算。 新的 Tensor 核心支持 FP8 数据类型,可以进一步提高深度学习模型的训练和推理速度。
- DLSS 3 (Deep Learning Super Sampling 3): Ada Lovelace 架构引入了 DLSS 3 技术,它利用 AI 生成额外的帧,从而显著提高游戏性能。 DLSS 3 结合了 DLSS Super Resolution、DLSS Frame Generation 和 NVIDIA Reflex 等技术,可以提供更流畅、更逼真的游戏体验。
- Shader Execution Reordering (SER): Ada Lovelace 架构引入了 SER 技术,可以动态地重新排序着色器工作负载,从而提高 GPU 的利用率和性能。
- AV1 编码器: Ada Lovelace 架构集成了 AV1 编码器,可以提供更高的视频编码效率。
3.9.2 Ada Lovelace Streaming Multiprocessor
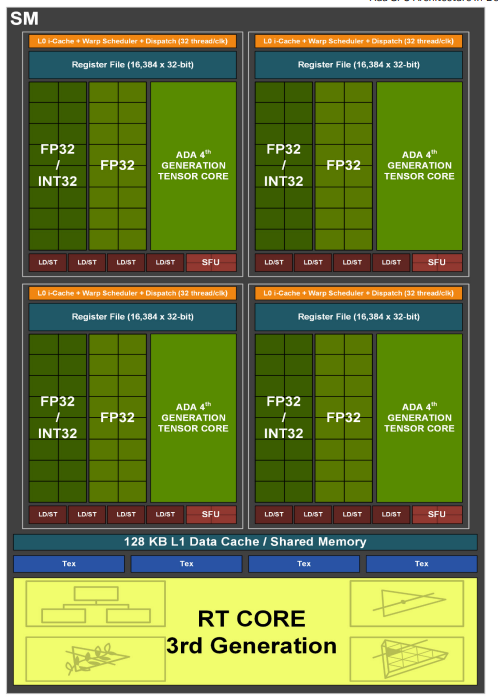
Ada Lovelace 架构的 SM 在 Ampere 架构的基础上进行了显著的改进,旨在提高性能、效率和光线追踪能力。
主要改进和特点:
- 更高的时钟频率和效率: Ada Lovelace 架构的 SM 旨在以更高的时钟频率运行,从而提高整体性能。此外,架构改进旨在提高每个时钟周期的指令吞吐量,从而提高效率。
- 第三代 RT Cores: Ada Lovelace 架构包含第三代 RT Cores,与之前的架构相比,光线追踪性能得到了显著提升。这些 RT Cores 包含新的硬件单元,可以加速光线三角形相交测试和光线追踪计算。
- 第四代 Tensor Cores: Ada Lovelace 架构包含第四代 Tensor Cores,与之前的架构相比,AI 性能得到了显著提升。这些 Tensor Cores 支持新的数据类型和技术,例如 FP8,可以加速深度学习训练和推理。
- Shader Execution Reordering (SER): SER 是一种新的技术,可以动态地重新排序着色器工作负载,从而提高 GPU 的利用率和性能。SER 可以通过减少着色器核心的停顿时间来提高效率。
- Displaced Micro-Meshes: Ada Lovelace 架构引入了 Displaced Micro-Meshes,这是一种新的几何图形表示方法,可以更有效地表示复杂场景中的细节。Displaced Micro-Meshes 可以与光线追踪技术结合使用,以实现更逼真的渲染效果。
3.10 Blackwell (2024-)
3.10.1 Blackwell Architecture Overview
NVIDIA Blackwell 架构是 NVIDIA 最新发布的 GPU 架构,旨在为加速计算、人工智能和数据分析提供前所未有的性能。 它被认为是 NVIDIA 有史以来最强大的芯片,并有望在各个行业带来革命性的变化。
主要特点和创新:
- 双芯片设计: Blackwell 架构采用双芯片设计,将两个独立的 GPU 芯片互连为一个统一的 GPU。 这种设计可以有效地提高 GPU 的计算能力和内存带宽。
- 下一代 Tensor Cores: Blackwell 架构配备了下一代 Tensor Cores,与之前的架构相比,AI 性能得到了显著提升。 新的 Tensor Cores 支持 FP4 和 FP6 等新的数据类型,可以进一步提高深度学习模型的训练和推理速度。
- Transformer Engine: Blackwell 架构引入了 Transformer Engine,专门用于加速 Transformer 模型的训练和推理。 Transformer 模型是自然语言处理领域最流行的模型之一,Transformer Engine 可以显著提高这些模型的性能。
- NVLink 5: Blackwell 架构支持 NVLink 5 互连技术,可以提供更高的带宽和更低的延迟。 NVLink 5 可以将多个 Blackwell GPU 连接在一起,以构建更大规模的计算系统。
- 保密计算: Blackwell 架构支持保密计算,可以在保护数据隐私的同时进行计算。 保密计算对于金融、医疗保健等敏感数据处理领域非常重要。
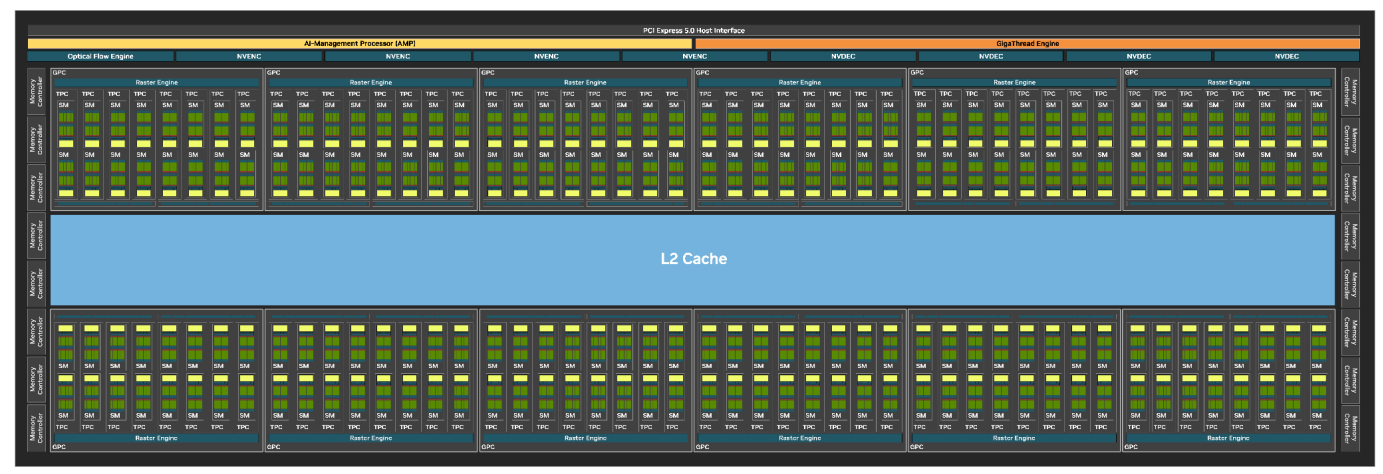
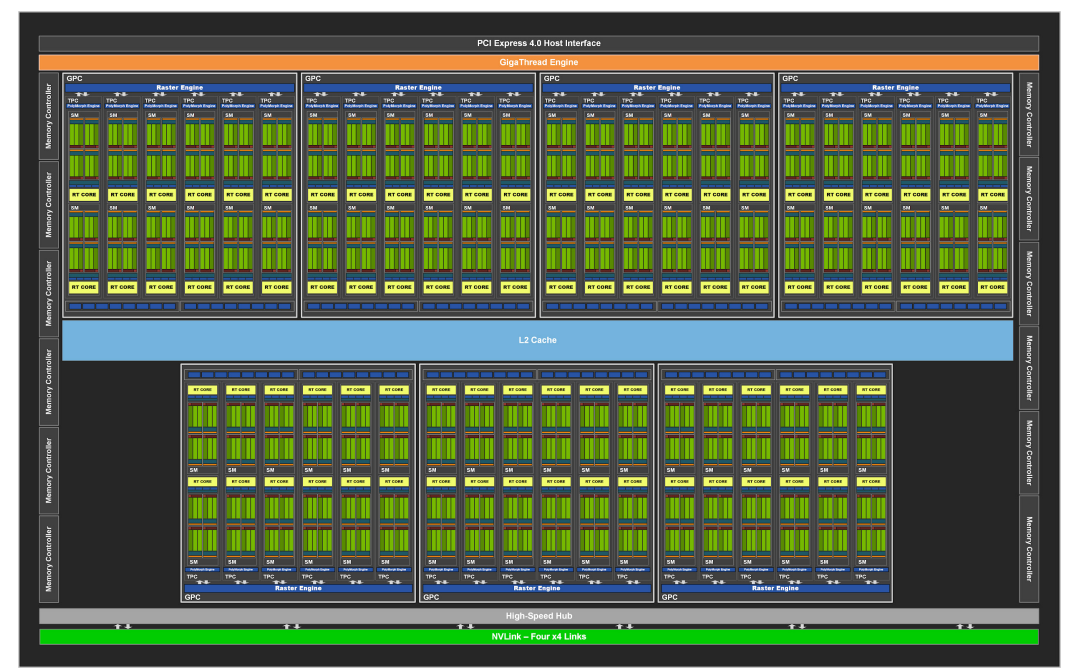
3.10.2 Blackwell Streaming Architecture

Blackwell 架构 SM 的主要特点:
- SM 数量: 每个完整的 GB202 芯片包含 192 个 SM。
- CUDA 核心: 每个 SM 包含 128 个 CUDA 核心。
- RT 核心: 每个 SM 包含 1 个 Blackwell 第四代 RT 核心。
- Tensor 核心: 每个 SM 包含 4 个 Blackwell 第五代 Tensor 核心。
- 纹理单元: 每个 SM 包含 4 个纹理单元。
- 寄存器文件: 每个 SM 包含 256 KB 的寄存器文件。
- L1/共享内存: 每个 SM 包含 128 KB 的 L1/共享内存,可以根据图形和计算工作负载的需求配置不同的内存大小。
- INT32 整数运算: Blackwell 架构中的 INT32 整数运算数量是 Ada 架构的两倍,通过将它们与 FP32 核心完全统一来实现。 但是,在任何给定的时钟周期内,统一的核心只能作为 FP32 或 INT32 核心运行。
4 参考文献
- Nvidia-NV1
- Nvidai-GeForce256
- Nvidia-架构
- Nvidia GPU架构梳理
- NVIDIA GPU 核心与架构演进史
- Impact analysis of conditional and loop statements for the NVIDIA G80 architecture
- GPU Architecture: the Fermi’s example
- Whitepaper NVIDIA’s Next Generation CUDATM Compute Architecture: Fermi
- List of Fermi series GeForce GPUs
- Whitepaper NVIDIA’s Next Generation CUDATM Compute Architecture: Kepler TM GK110/210
- Maxwell: The Most Advanced CUDA GPU Ever Made
- Whitepaper NVIDIA Tesla P100 The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World’s Fastest GPU
- NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD’S MOST ADVANCED DATA CENTER GPU
- NVIDIA TURING GPU ARCHITECTURE Graphics Reinvented
- NVIDIA TURING GPU ARCHITECTURE
- NVIDIA AMPERE GA102 GPU ARCHITECTURE Second-Generation RTX
- NVIDIA ADA GPU ARCHITECTURE Designed to deliver outstanding gaming and creating, professional graphics, AI, and compute performance.
- NVIDIA RTX BLACKWELL GPU ARCHITECTURE Built for Neural Rendering