随着大型语言模型(LLMs)的快速发展,高质量数据供给已成为智能系统的关键基础架构。为使人工智能系统能够生成有实际价值的分析结果,它需要获取及时、结构化且相关性高的数据源。
如Crawl4AI这类工具正在革新数据获取与传递机制,使大语言模型能够动态接入多样化数据源,而无需受限于固定API接口的约束。
大语言模型需要高质量、富含上下文的数据来实现语境化推理***(上下文学习)***,这是完成问题回答、内容生成或驱动AI代理等任务的基础。
高效的数据传递机制确保语言模型能够在适当时机获取准确信息,这直接决定了其响应的准确性与实用性。数据传递的速度、质量与结构化程度对于大语言模型输出的实际应用价值具有决定性影响,无论是实时市场分析、新闻摘要、天气预报还是专业领域知识的整合。
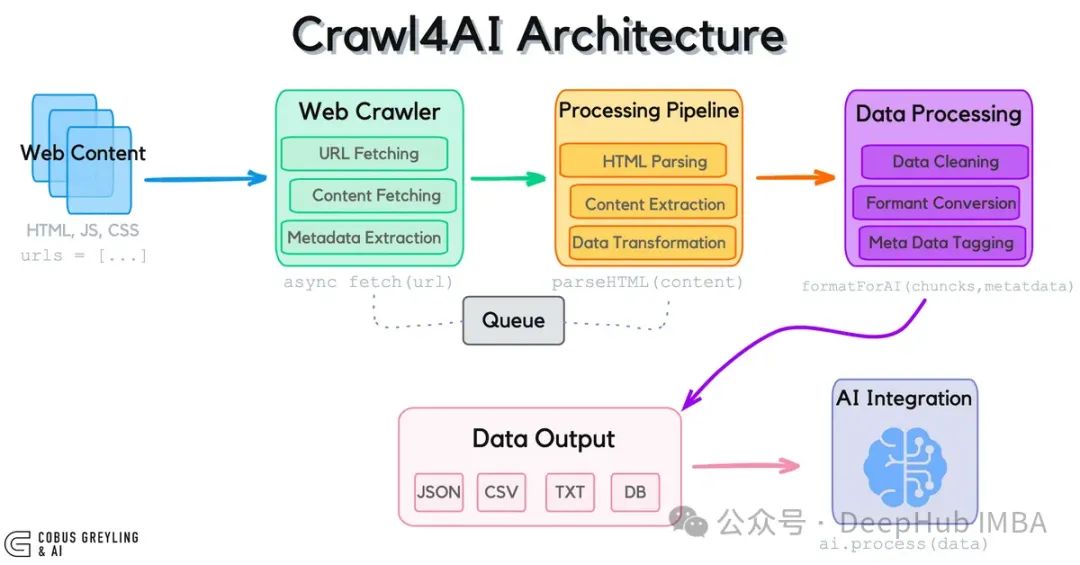
Crawl4AI作为专为大语言模型设计的开源网页爬取工具,能高效提取网页数据并将其转换为JSON、规范化HTML或markdown等结构化格式。这一特性使其成为需要持续获取最新数据而不依赖复杂集成方案的应用场景的理想解决方案。
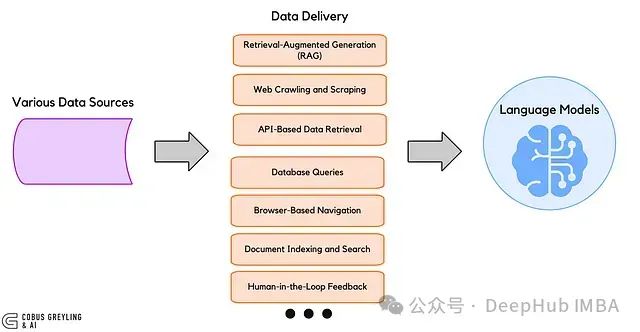
大语言模型数据传递的技术路径
数据可通过多种技术渠道传递至大语言模型:
- API接口:提供结构化数据但受到服务提供商的功能约束与计费限制。
- 数据库集成:适用于预先收集的静态数据集,但在处理动态变化信息时灵活性不足。
- 网页爬取技术:如Crawl4AI能够自主导航网站结构,从目标URL及其子页面中提取实时数据,无需依赖预设API。
- 文档解析:通过处理PDF、CSV或纯文本文件实现离线数据的结构化提取。
网页爬取技术因其适应性强且实现成本低而具有显著优势,特别适合无需复杂编程基础的AI代理应用场景。
Crawl4AI采用基于浏览器的导航方式(通过Playwright框架)或轻量级HTTP请求机制访问公开网页内容,能够模拟人类交互行为以有效应对CAPTCHA验证或动态页面渲染等技术障碍。这为大语言模型提供了实时数据源,支持即时分析或检索增强生成(RAG)等高级应用场景。
数据传递能力的扩展策略
Crawl4AI通过异步架构设计和内存自适应调度系统,能够高效管理数千个URL的并发处理,确保系统吞吐量最大化。其基于FastAPI的后端服务器集成了JWT身份验证机制,支持Docker容器化部署,适用于企业级数据采集需求。
在爬取策略方面,系统支持深度优先(DFS)或广度优先(BFS)的网站遍历模式以获取全面数据,同时也提供基于LXML的轻量级解析方案以提升处理速度,实现资源利用与输出质量的最优平衡。内置的代理轮换功能有效规避访问频率限制,支持全球范围的数据收集。
这些技术特性确保大语言模型能够随着应用需求的增长持续获取高质量数据,适用于从单一聊天机器人到复杂AI代理网络的各类应用场景。
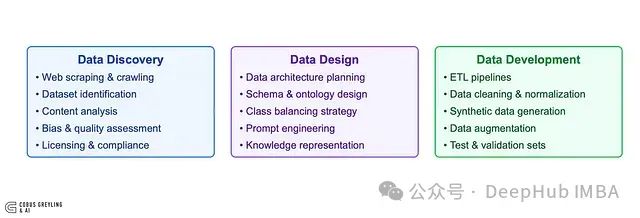
数据管道的发现、设计与开发
除数据传递外,大语言模型还需要精心设计的数据预处理管道:
数据源发现是构建有效数据管道的首要环节。Crawl4AI实现了基于自然语言查询的智能爬虫功能,允许用户通过问题描述自动定位相关网页内容。
数据结构设计对于大语言模型的理解至关重要。Crawl4AI采用启发式markdown生成算法和重叠文本分块技术,有效保留上下文连贯性,提升输出质量。
管道开发需要适应性强的工具支持。Crawl4AI提供的命令行界面和编程接口简化了从原型设计到生产部署的全流程,实现与AI工作流的无缝集成。
数据来源的多样性包括社交媒体、新闻网站、专业论坛和电子商务平台等。Crawl4AI对PDF文档、图像内容和iframe嵌入式资源的处理能力,确保大语言模型不仅限于纯文本信息,从而丰富其知识库的维度和深度。
AI代理网页导航的技术优势
相较于传统的基于API的数据检索方式,Crawl4AI基于浏览器的网页导航技术提供了显著优势:
Crawl4AI能够从任何公开URL实时提取数据,特别适合处理突发新闻或热点话题等时效性内容;其无API依赖的设计避免了供应商限制和访问频率限制,模拟人类用户自然访问网站;系统支持的深度爬取功能能够有效发现嵌套内容(如产品详情页或博客存档),增强上下文理解;内置的JavaScript渲染和弹窗、广告等干扰元素移除功能确保获取的数据清晰有效;直接输出LLM兼容的结构化JSON或markdown格式,简化了检索增强生成(RAG)或模型微调的工作流程。
例如,用于市场趋势分析的AI代理可利用Crawl4AI导航财经新闻网站,提取关键文章,并将内容结构化处理后直接提供给大语言模型进行实时分析,无需等待API更新周期。
Crawl4AI的安装与使用指南
下面是Crawl4AI的完整安装和基本使用流程:
首先,创建专用的Python虚拟环境:
python3 -m venv crawl
激活创建的虚拟环境:
source crawl/bin/activate
安装Crawl4AI软件包:
pip install -U crawl4ai
运行安装后的配置程序:
crawl4ai-setup
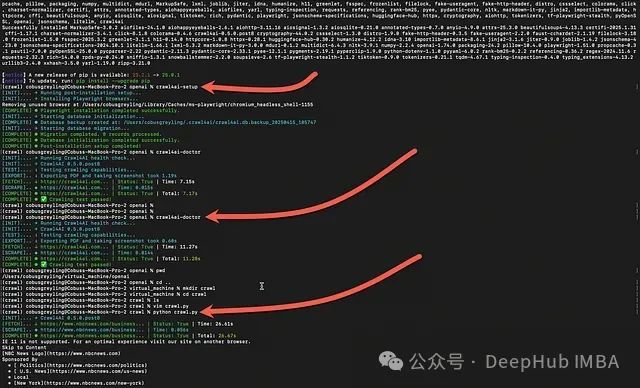
验证安装是否成功:
crawl4ai-doctor
终端执行结果如下图所示:
使用文本编辑器创建Python示例脚本,定义目标URL并实现基本爬取功能:
import asyncio
from crawl4ai import * async def main(): async with AsyncWebCrawler() as crawler: result = await crawler.arun( url="https://www.nbcnews.com/business", ) print(result.markdown) if __name__ == "__main__": asyncio.run(main())
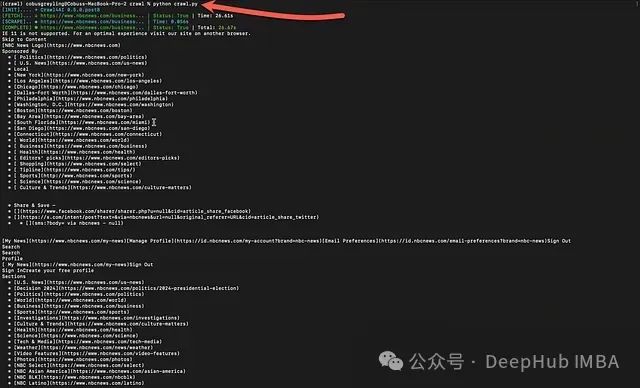
以下是从命令行运行Python文件的执行结果,使用命令
python crawl.py
:
总结
Crawl4AI作为专为大语言模型设计的开源网页数据采集工具,通过突破传统API限制,实现了对实时网页数据的高效获取与结构化处理。其异步架构和浏览器导航技术能够处理动态内容、应对验证机制,并支持多种输出格式。无论是RAG应用、市场分析还是新闻聚合,Crawl4AI都为大语言模型提供了可靠的实时数据通道,简化了从数据获取到AI应用的整个工作流程,是AI系统获取开放网络信息的理想解决方案。
项目地址:https://avoid.overfit.cn/post/93e116b0fdd44751a6870b295dbc9921
Cobus Greyling