目录标题
- 阶段二:核心技术深入学习
- 阶段三:工具与实践
- 1. 基础概念
- 问题:什么是向量数据库?它与传统关系型数据库的区别是什么?
- 问题:向量数据库的核心数据结构是什么?为什么向量适合用于高维数据?
- 问题:什么是向量索引?常见的向量索引算法有哪些?
- 2. 技术实现
- 问题:向量数据库如何实现高效的相似性搜索?
- 问题:你了解哪些开源的向量数据库?它们的优缺点是什么?
- 问题:向量数据库如何处理大规模数据的存储和查询?
- 3. 应用场景
- 问题:向量数据库在哪些场景下有优势?请举例说明。
- 问题:在推荐系统中,如何使用向量数据库来提高效率?
- 4. 实践经验
- 问题:你是否在实际项目中使用过向量数据库?请分享你的经验。
- 问题:如何处理多模态数据(如图像、文本、音频)的向量化存储和检索?
- HNSW算法
- PQ乘积量化算法
- 步骤 1:分割向量
- 步骤 2:对每个子向量进行量化
- 步骤 3:存储量化结果
- 步骤 4:查询时使用量化结果
- 为什么 PQ 高效?
- 举例说明
- Milvus
- 面试可能的问题

-
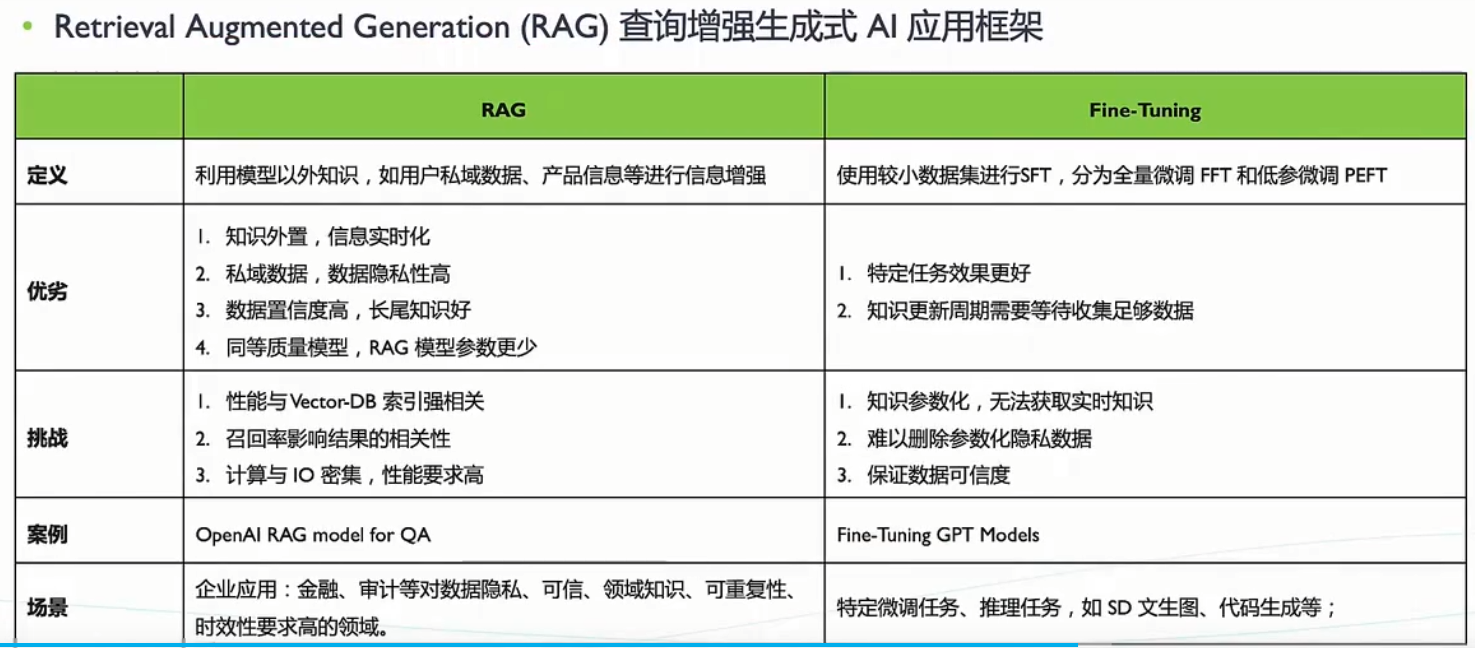
向量检索基础
- 近似最近邻搜索(ANN)原理与算法分类
- 经典算法:IVF(倒排索引)、HNSW(图索引)、PQ(乘积量化)
- 评测指标:召回率、延迟、吞吐量、内存占用
-
数据库与分布式系统基础
- 数据库索引原理(B树、LSM树)
- 分布式存储与计算框架(如Spark、Flink)
阶段二:核心技术深入学习
- 向量数据库核心技术
- 索引结构优化:混合索引(如IVF+HNSW)、层次化索引
- 距离度量:欧氏距离、余弦相似度、自定义度量函数
- 量化技术:标量量化(SQ)、乘积量化(PQ)、4-bit量化(参考HANNS优化)
量化:
-
性能优化与硬件加速
- SIMD指令优化(如AVX-512)
- GPU/NPU加速(如华为NPU在HANNS中的应用)
- 内存与磁盘I/O优化(数据压缩、缓存策略)
-
跨模态检索技术
- 多模态表示学习(CLIP、ALIGN等模型)
- 跨模态对齐(特征映射、对抗学习)
- 分布外(OOD)数据检索优化(参考HANNS-OOD算法)
阶段三:工具与实践
-
主流工具与框架
- 开源库:Faiss(Meta)、Annoy(Spotify)、SCANN(Google)
- 向量数据库:Milvus、Pinecone、Weaviate
- 华为云HANNS算法库(研究其开源实现与技术文档)
-
实践项目
- 复现经典论文(如HNSW、IVFPQ)
- 优化现有算法(如改进量化策略或索引结构)
- 参与Kaggle竞赛(如BigANN Benchmark相关任务)
1. 基础概念
问题:什么是向量数据库?它与传统关系型数据库的区别是什么?
-
期望答案:
- 向量数据库是一种专门设计用来存储和查询高维向量数据的数据库系统。这些向量通常是由机器学习模型生成的,它们可以表示各种类型的数据,如文本、图像或音频等非结构化数据的特征。向量数据库允许用户高效地执行相似性搜索,这对于推荐系统、图像识别、语音处理等领域非常重要。
- 与传统关系型数据库的区别:
- 数据模型:关系型数据库存储结构化数据(如表),而向量数据库存储高维向量。
- 查询方式:关系型数据库使用SQL进行精确查询,向量数据库支持相似性搜索(如最近邻搜索)。
- 应用场景:关系型数据库适用于事务处理,向量数据库适用于AI、推荐系统、语义搜索等场景。
-
解决的问题
- 检索∶以图搜图场景,如人脸检索、人脸支付、车牌号码检索、相似商品检索等;
- 分析∶以图分析行为,人脸撞库、人脸对比、场景再现等;
问题:向量数据库的核心数据结构是什么?为什么向量适合用于高维数据?
-
期望答案:
- 核心数据结构是向量(高维数组),通常用于表示嵌入(Embedding)。
- 向量适合高维数据的原因:
- 高维向量可以捕捉复杂特征(如图像、文本、音频的语义信息)。
- 通过向量距离(如余弦相似度、欧氏距离)可以量化数据之间的相似性。


-
考察重点: 候选人对向量及其在高维数据处理中的优势的理解。
问题:什么是向量索引?常见的向量索引算法有哪些?
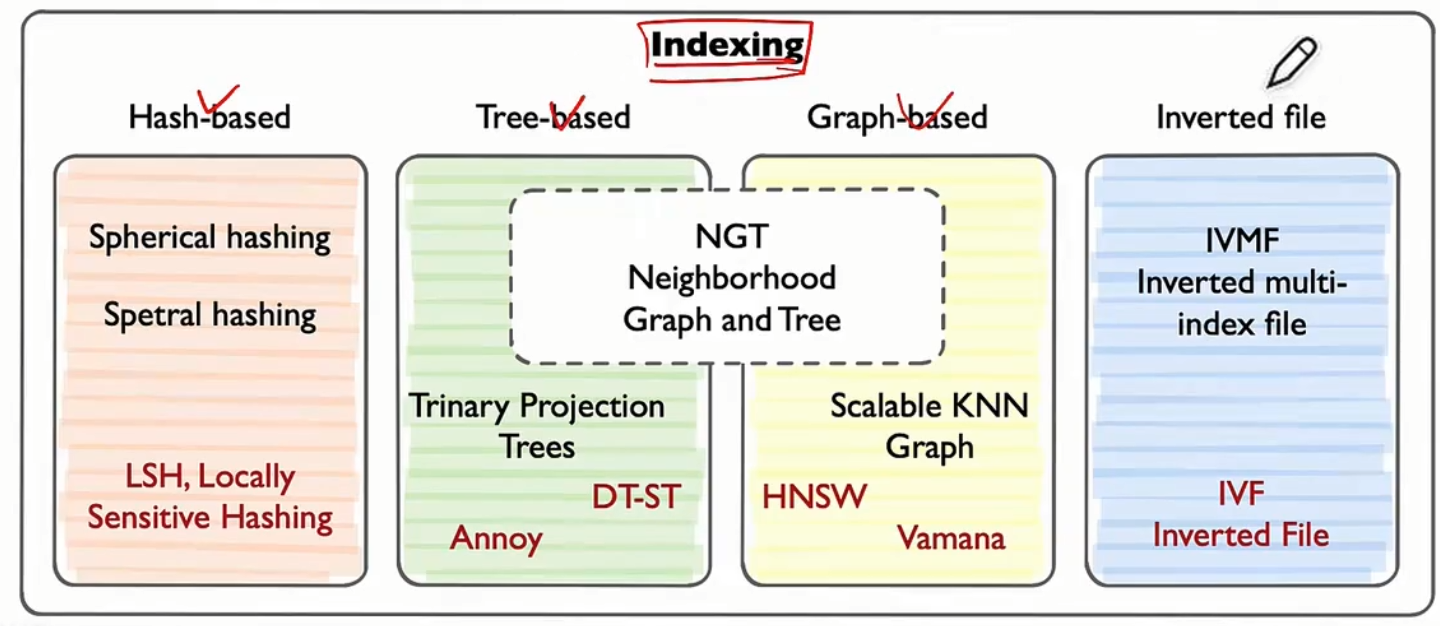
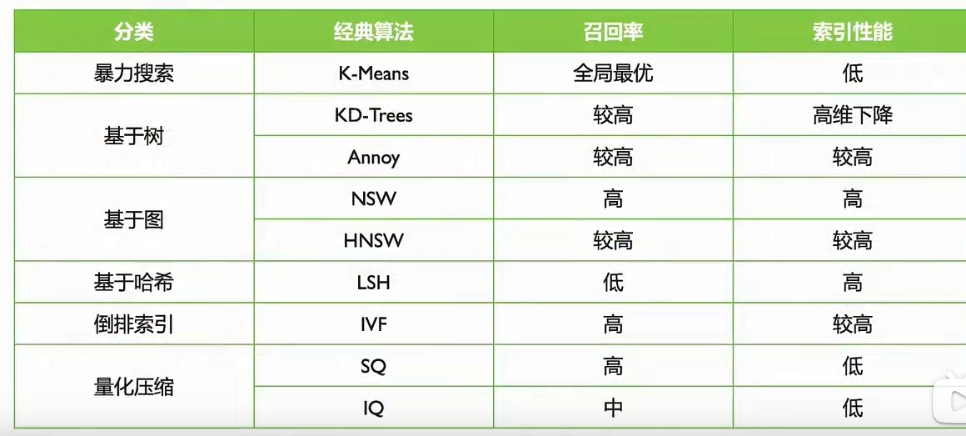
- 期望答案:
- 向量索引是一种数据结构,用于高效地组织和存储向量数据。由于向量通常是高维的(例如,图像、文本或音频的嵌入向量),直接对这些向量进行搜索会非常耗时。因此,向量索引的作用是通过某种方式对向量进行组织,使得搜索过程更加高效。
- 常见算法:
-
HNSW(Hierarchical Navigable Small World):基于图的索引,构建一个多层图结构,支持高效近似最近邻搜索。

-
IVF(Inverted File):将向量聚类,并在每个聚类中建立索引。
-
FAISS(Facebook AI Similarity Search):基于量化和分层的索引库。
-
KD-Tree:将向量空间递归地划分为二叉树结构。
-
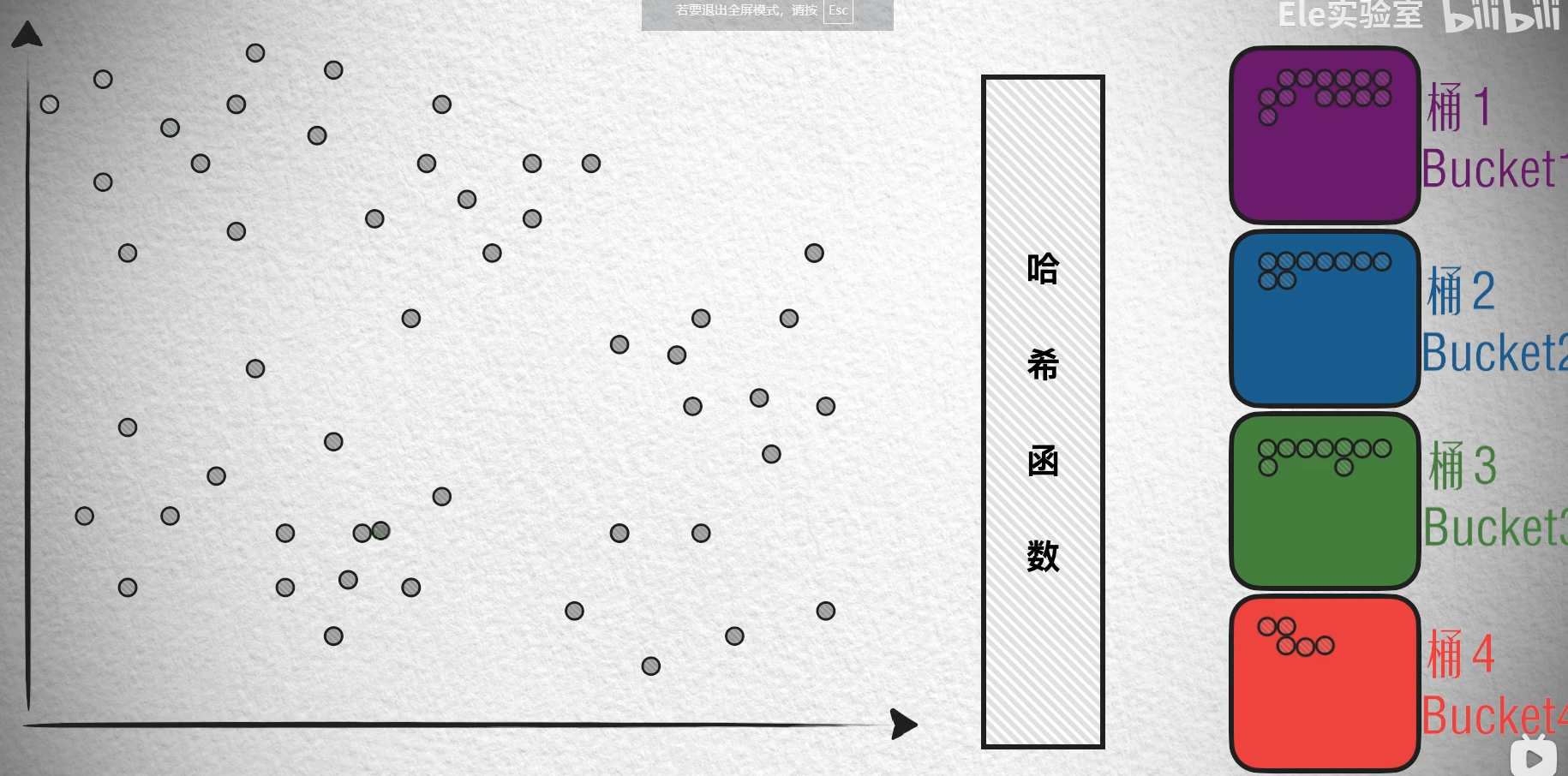
LSH(局部敏感哈希):通过哈希函数将相似的向量映射到同一个桶中。
-
- 考察重点: 候选人对向量索引技术的了解,以及对常用算法的熟悉程度。

2. 技术实现
问题:向量数据库如何实现高效的相似性搜索?
- 期望答案:
- 使用近似最近邻搜索(ANN)算法(ANN 是一类用于在高维空间中快速找到与查询向量最相似的向量的算法。),在保证精度的同时提高搜索效率。
- 常见技术:
- 基于图的算法: 如 HNSW(Hierarchical Navigable Small World)。
- 基于树的算法: 如 KD-Tree、Ball Tree。
- 基于量化的算法: 如 PQ(Product Quantization)、IVF(Inverted File)。
- 基于哈希的算法: 如 LSH(Locality-Sensitive Hashing位置敏感哈希)。
视频链接:b站
- 考察重点: 候选人对ANN算法及其优化技术的理解。
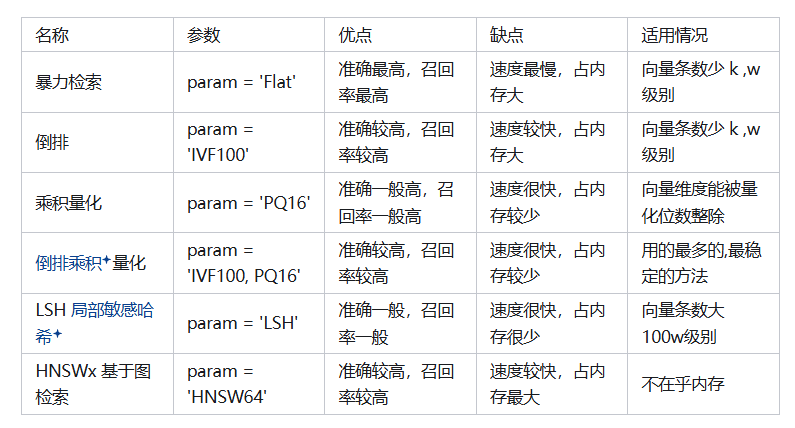
问题:你了解哪些开源的向量数据库?它们的优缺点是什么?
- 期望答案:
- Milvus: 支持分布式部署,功能丰富,但配置复杂。
- Weaviate: 集成语义搜索和AI模型,适合文本数据,但社区较小。
- FAISS: 高效的向量搜索库,但需要自行搭建数据库功能。
- Pinecone: 托管服务,易于使用,但成本较高。
- 考察重点: 候选人对主流向量数据库的了解及其优缺点分析。
问题:向量数据库如何处理大规模数据的存储和查询?
- 期望答案:
- 使用分布式存储(如对象存储、分布式文件系统)扩展存储容量。
- 通过分片(Sharding)和并行计算加速查询。
- 利用索引优化(如HNSW、IVF)减少搜索范围。
- 考察重点: 候选人对大规模数据处理技术的理解。
3. 应用场景
问题:向量数据库在哪些场景下有优势?请举例说明。
- 期望答案:
- 推荐系统: 通过用户和物品的向量表示进行相似性推荐。
- 语义搜索: 将文本转换为向量,支持自然语言查询。
- 图像检索: 通过图像特征向量进行相似图像搜索。
- 异常检测: 通过向量距离识别异常数据。
- 考察重点: 候选人对向量数据库在实际应用中的理解。
问题:在推荐系统中,如何使用向量数据库来提高效率?
- 期望答案:
- 将用户和物品表示为向量(如通过矩阵分解或深度学习模型)。
- 使用向量数据库存储和索引这些向量。
- 通过相似性搜索快速找到与用户兴趣匹配的物品。
- 考察重点: 候选人对推荐系统与向量数据库结合的应用能力。
4. 实践经验
问题:你是否在实际项目中使用过向量数据库?请分享你的经验。
- 期望答案:
- 描述具体项目背景(如推荐系统、语义搜索)。
- 说明使用的向量数据库(如Milvus、FAISS)及其选型原因。
- 分享遇到的挑战(如性能优化、数据规模)及解决方案。
- 考察重点: 候选人的实际项目经验及问题解决能力。
问题:如何处理多模态数据(如图像、文本、音频)的向量化存储和检索?
- 期望答案:
- 使用多模态模型(如CLIP、UniT)将不同模态数据映射到同一向量空间。
- 在向量数据库中统一存储这些向量。
- 通过相似性搜索实现跨模态检索。
- 考察重点: 候选人对多模态数据处理及向量数据库应用的理解。
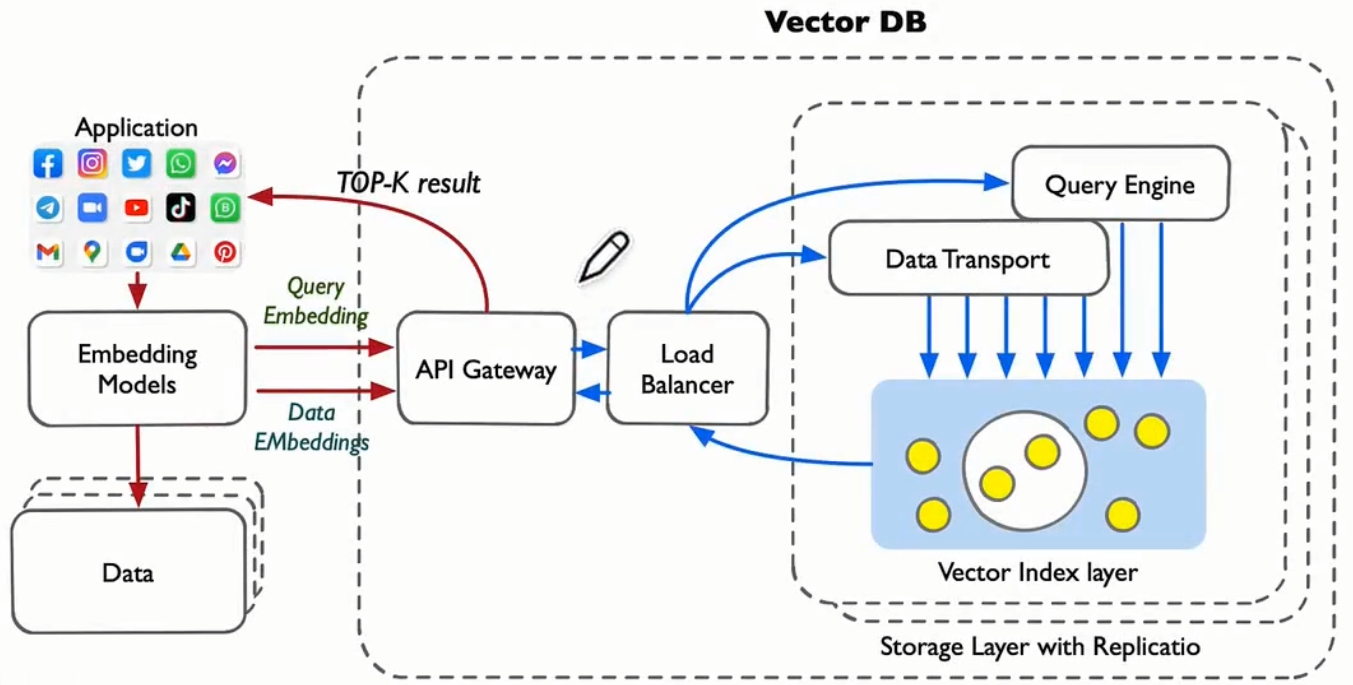
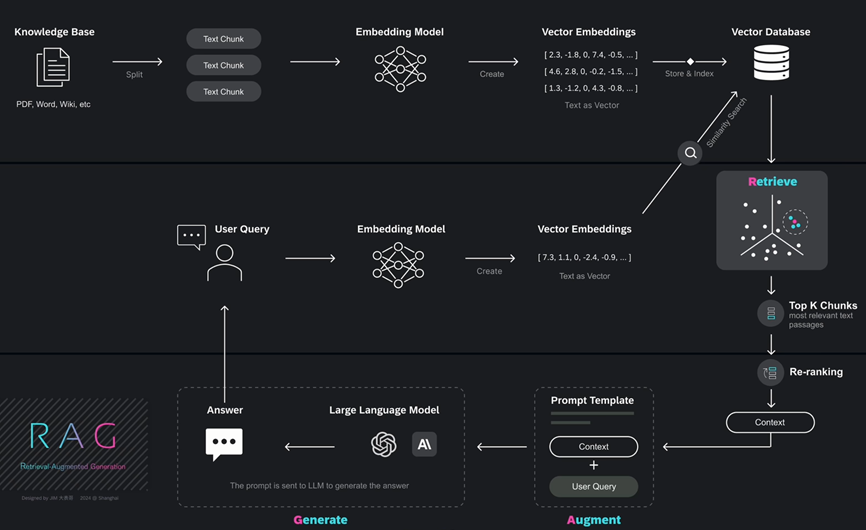
大模型遇到向量检索
- LLM应用离不开Prompt Engine,提示工程离不开向量检索
- 本质语义搜索,从海量数据中找到匹配的内容拼接提示词
- 向量数据库对输入数据Embedding后,使用向量化计算为大模型提供高效的数据存储和查询支撑;
Vector-DB提供存储、记忆能力,大模型提供问题处理和分析能力
- 大模型与Vector-DB深度融合应用为通用人工智能(AGl )的实现提供了可靠路径;
- 大模型新一代AlI处理器,提供数据处理能力;Vector-DB提供Memory存储能力。
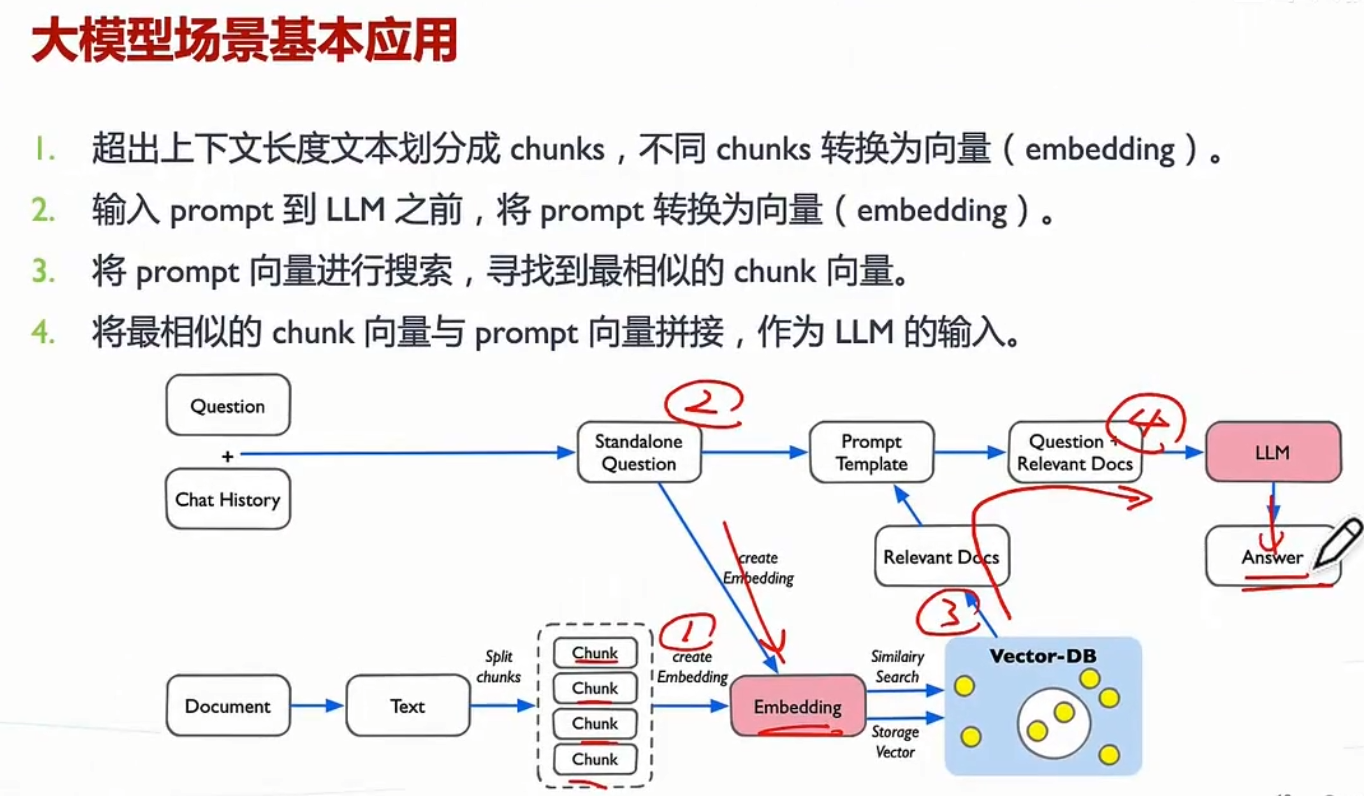

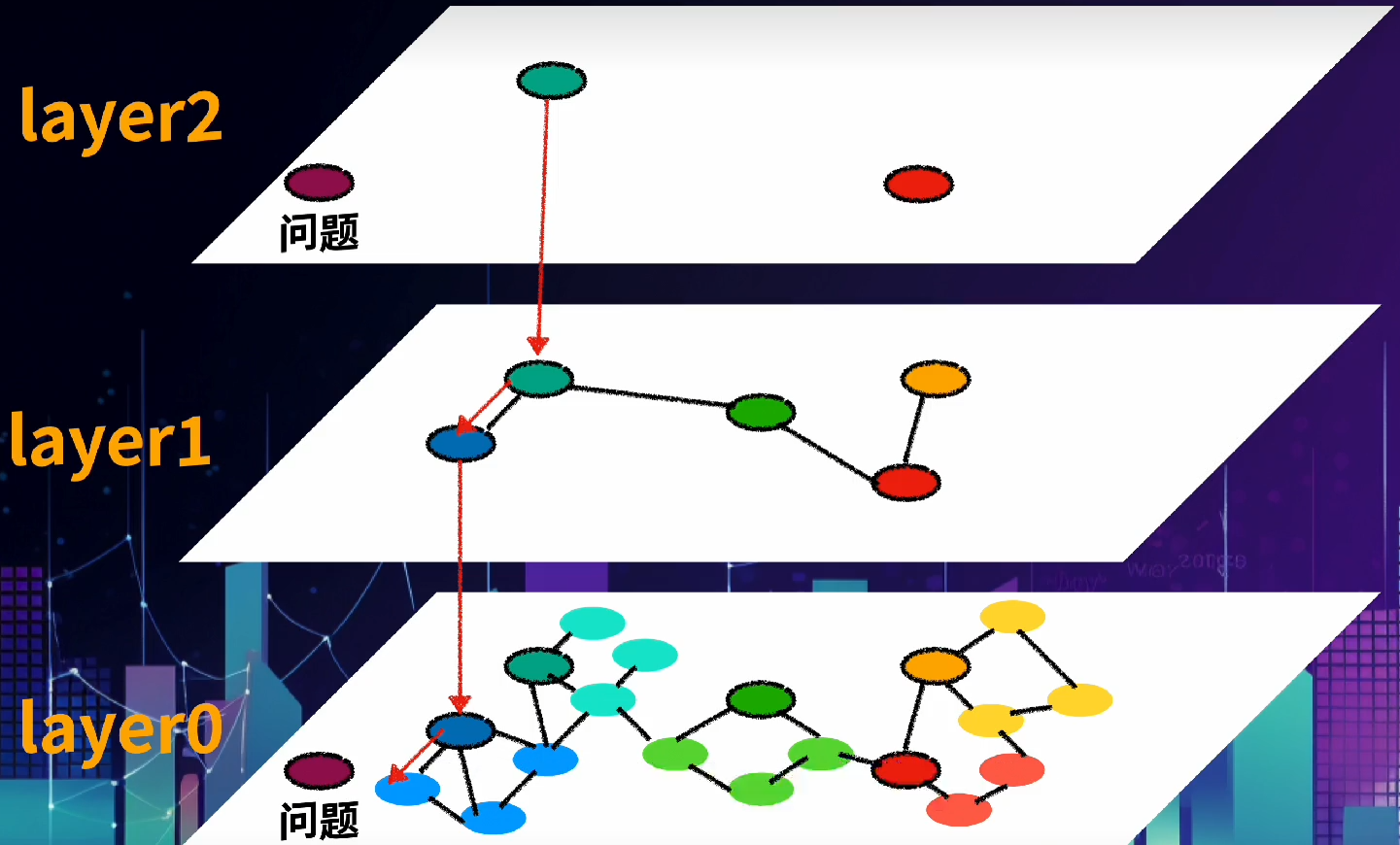
HNSW算法
b站视频
(从上往下看)
构图准则:

视频:b站
通过长连接快速导航,然后通过短连接实现精细化搜索。
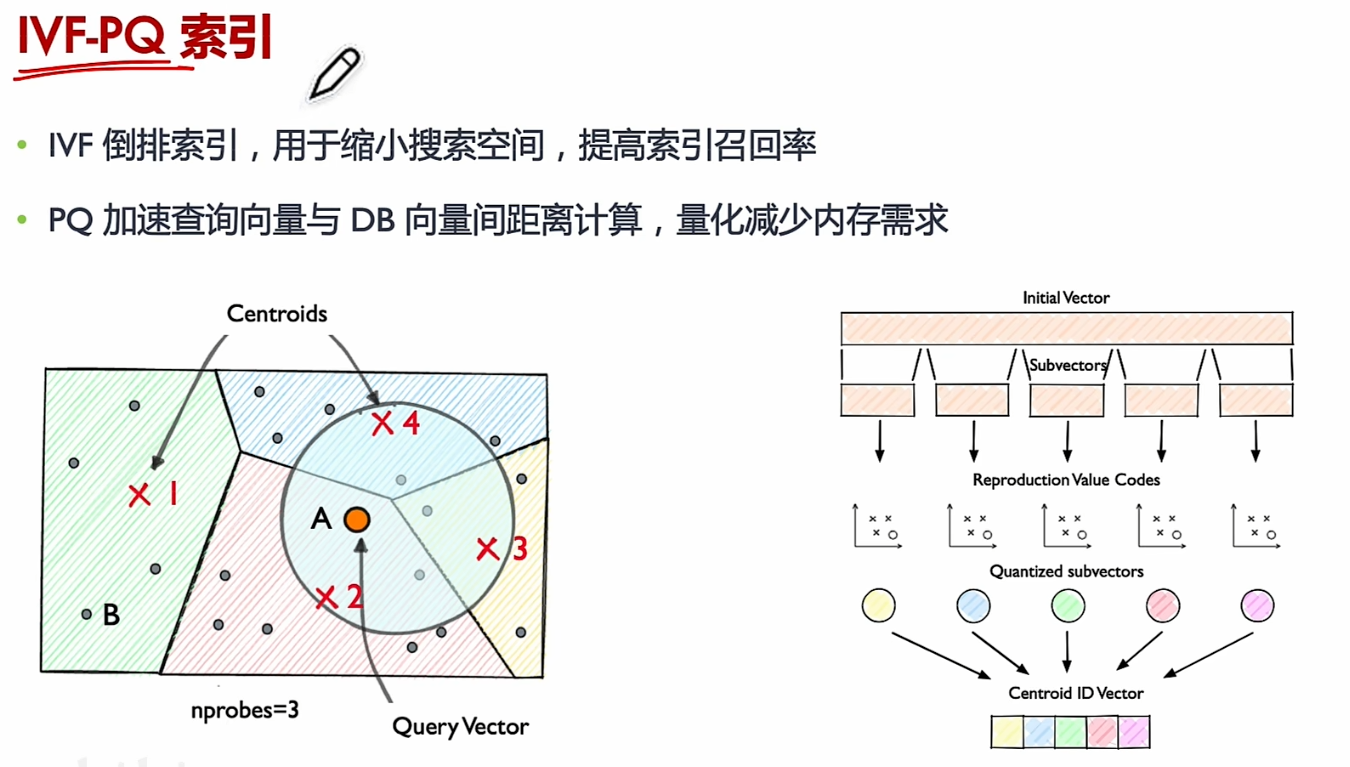
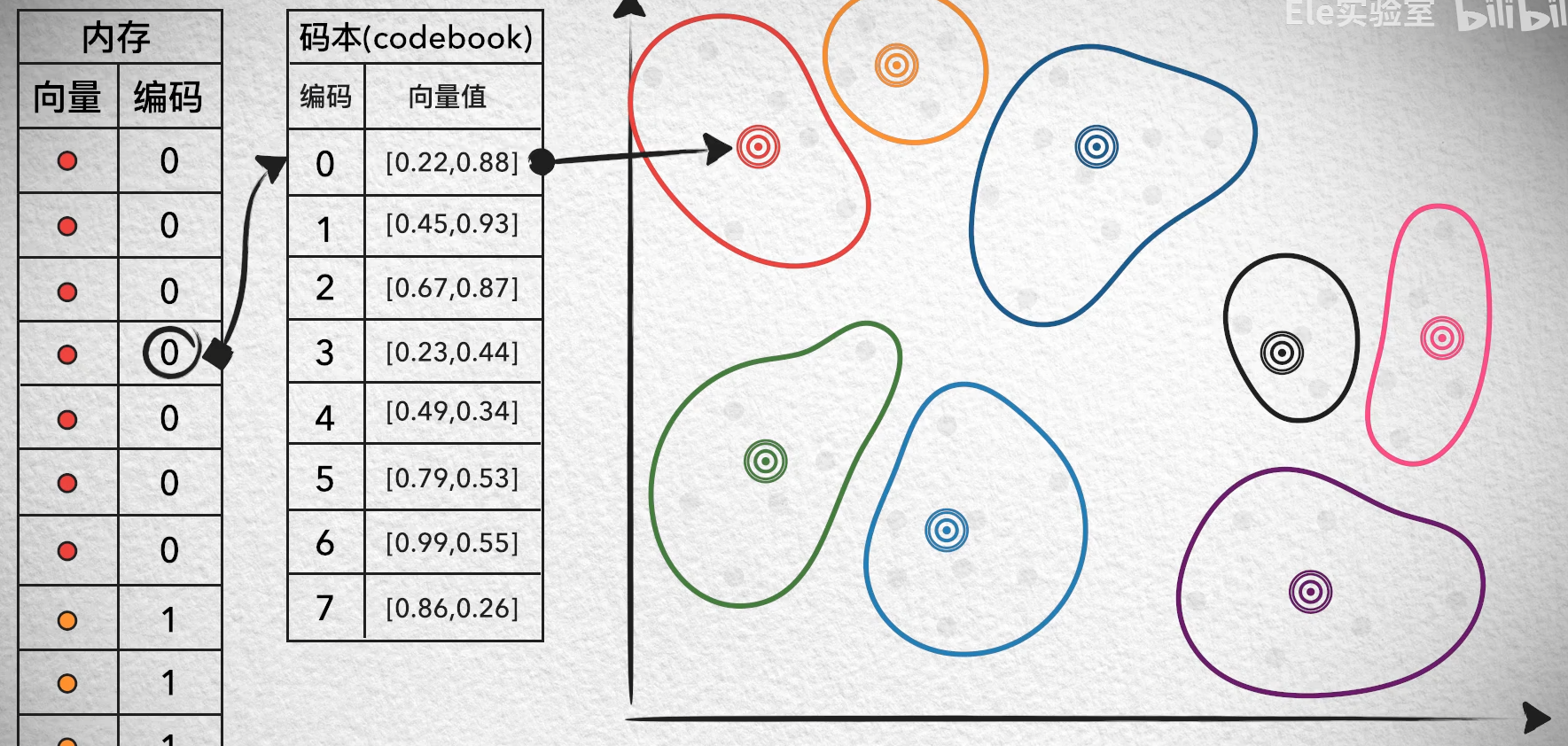
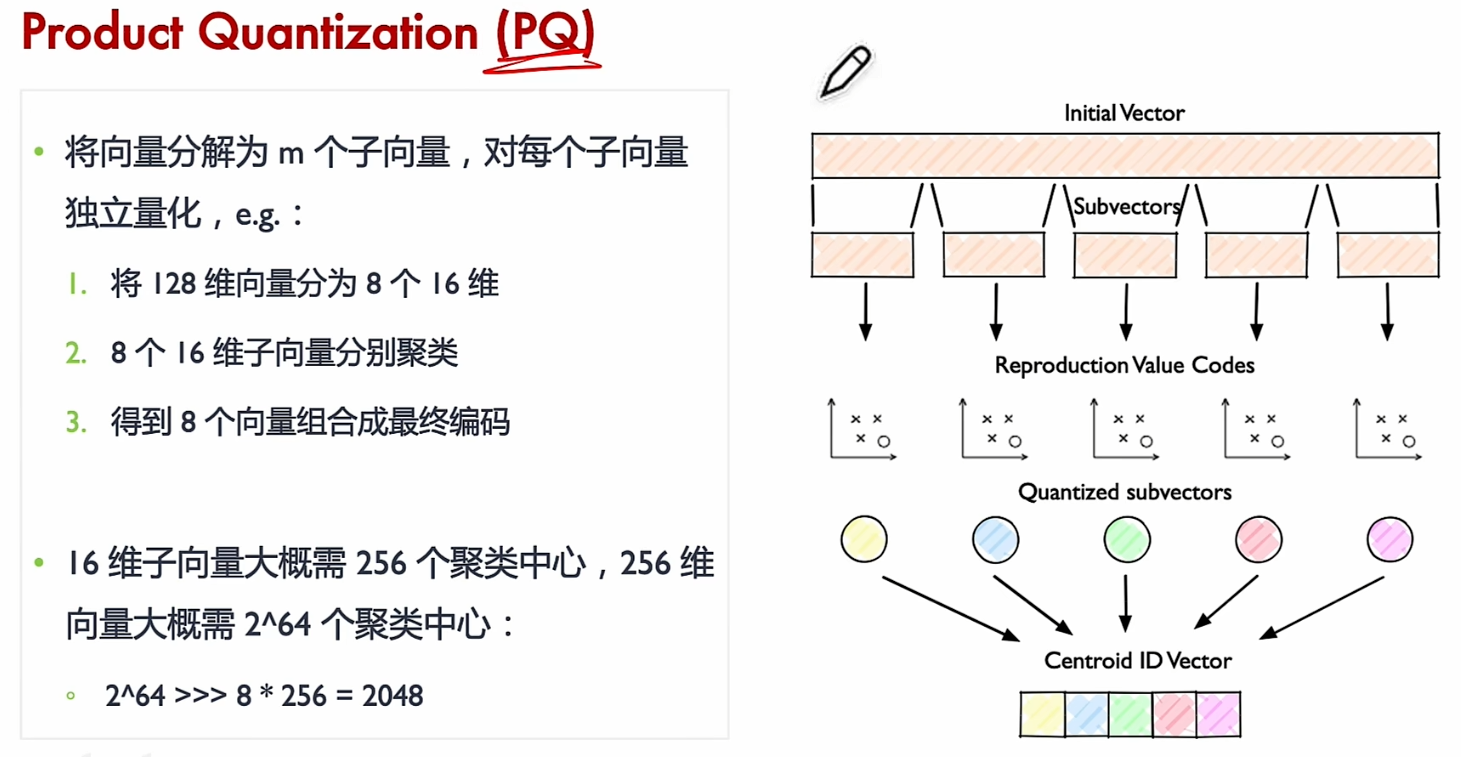
PQ乘积量化算法
乘积量化(Product Quantization, PQ) 是一种用于高效压缩和检索高维向量数据的算法。
PQ 的核心思想是将高维向量分成若干个子向量(就像将图片分成小块),然后对每个子向量进行独立的量化(压缩)。具体步骤如下:
步骤 1:分割向量
- 假设你有一个 128 维的向量,直接处理它会很复杂。
- 将这个向量分成 m m m 个子向量,比如 m = 8 m=8 m=8,每个子向量就是 16 维。
步骤 2:对每个子向量进行量化
- 对每个 16 维的子向量,使用 K-Means 聚类算法生成一个码本(Codebook)。
- 码本是一个包含 k k k 个“代表向量”的集合,比如 k = 256 k=256 k=256。
- 每个子向量会被映射到码本中与其最接近的代表向量。
- 这样,每个子向量就可以用一个索引(0 到 255)来表示,而不是原始的 16 维数据。
步骤 3:存储量化结果
- 每个子向量被压缩成一个索引(比如一个 8 位的整数)。
- 整个 128 维向量就被压缩成 m m m 个索引,比如 8 个 8 位整数,总共 64 位。
步骤 4:查询时使用量化结果
- 当需要查询与某个向量最相似的向量时:
- 将查询向量也分割成 m m m 个子向量。
- 对每个子向量,计算它与码本中所有代表向量的距离。
- 使用这些距离来快速找到最相似的向量。
为什么 PQ 高效?
- 存储高效: 原始的高维向量被压缩成少量索引,大大减少了存储空间。
- 计算高效: 查询时只需要计算子向量与码本的距离,而不是整个高维向量。
- 搜索快速: 通过预先计算的距离表,可以快速找到最相似的向量。
举例说明
假设我们有一个 128 维的向量,将其分成 8 个子向量,每个子向量 16 维:
- 对每个子向量,使用 K-Means 生成一个包含 256 个代表向量的码本。
- 将每个子向量映射到码本中最接近的代表向量,并用一个 8 位整数表示。
- 最终,整个 128 维向量被压缩成 8 个 8 位整数,总共 64 位。
- 查询时,通过计算子向量与码本的距离,快速找到最相似的向量。
Milvus
Milvus是一个开源向量数据库项目,旨在解决非结构化数据(如图像、视频、音频等)的相似度搜索问题。它通过将这些数据转换为向量,并利用高效的索引算法来实现快速的相似性搜索。
面试可能的问题
- K-Means算法的步骤?

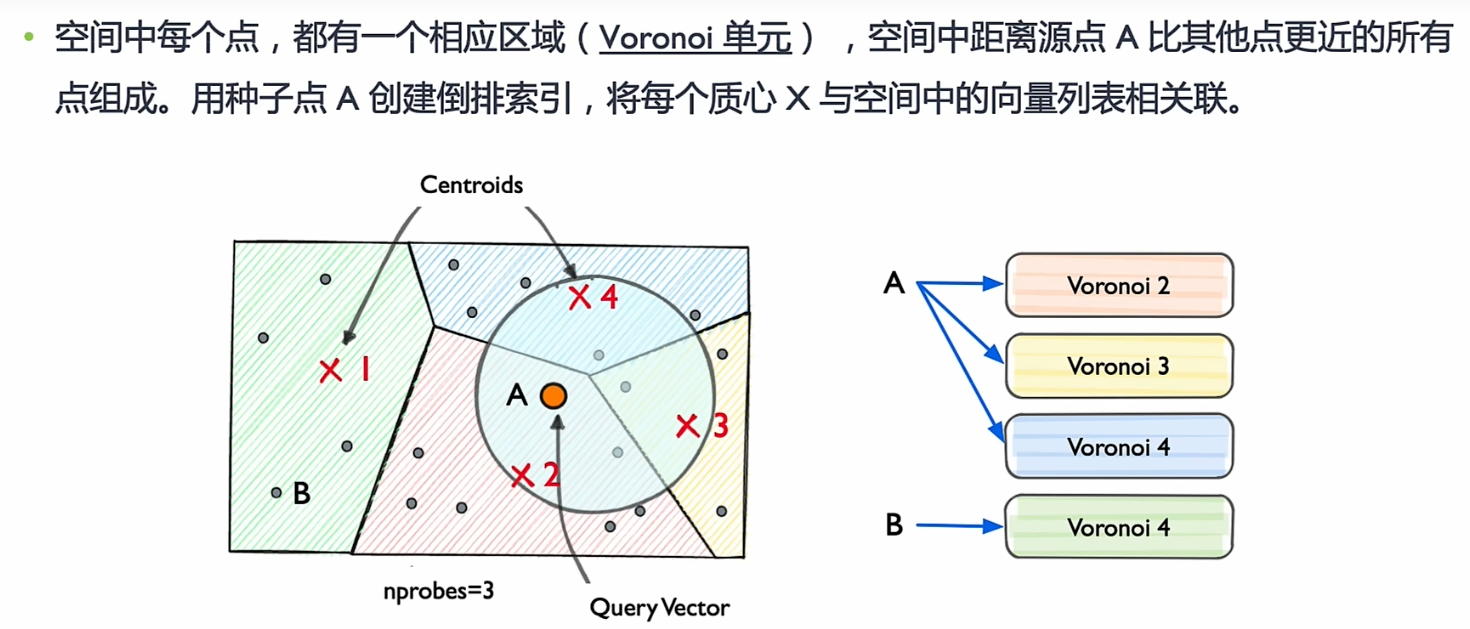
- 倒排索引算法IVF。
为每个向量规定一个置信区域,区域所在的类别即认为该向量属于该类别。