文章目录
- 前言
- 一、Constructing MMVP Benchmarks
- 1、CLIP-blind pair
- 二、MMVP-VLM bench
- 1、Model size influence
- 2、correlation between CLIP MLLMs
- 三、Mixture of Features
- 1、Additive MoF Experiment
- 2、Interleaved MoF Experiment
- 总结
前言
在使用多模态大模型时候是否会发现大模型对图像的细节理解很差,比如让他数数,让他识别理解复杂图像,VLLM给出的答案往往有些不尽人意。其实本质来讲还是幻觉问题!!!

paper:https://arxiv.org/abs/2401.06209
一、Constructing MMVP Benchmarks
1、CLIP-blind pair

CLIP相似度大于等于0.95, DiNOv2相似度小于等于0.6 认为是一个CLIP-blind 对,这表明这两张图在语义级别上相似,在像素级别上差距较大。
选出pair对后,人为标出两张图的差异。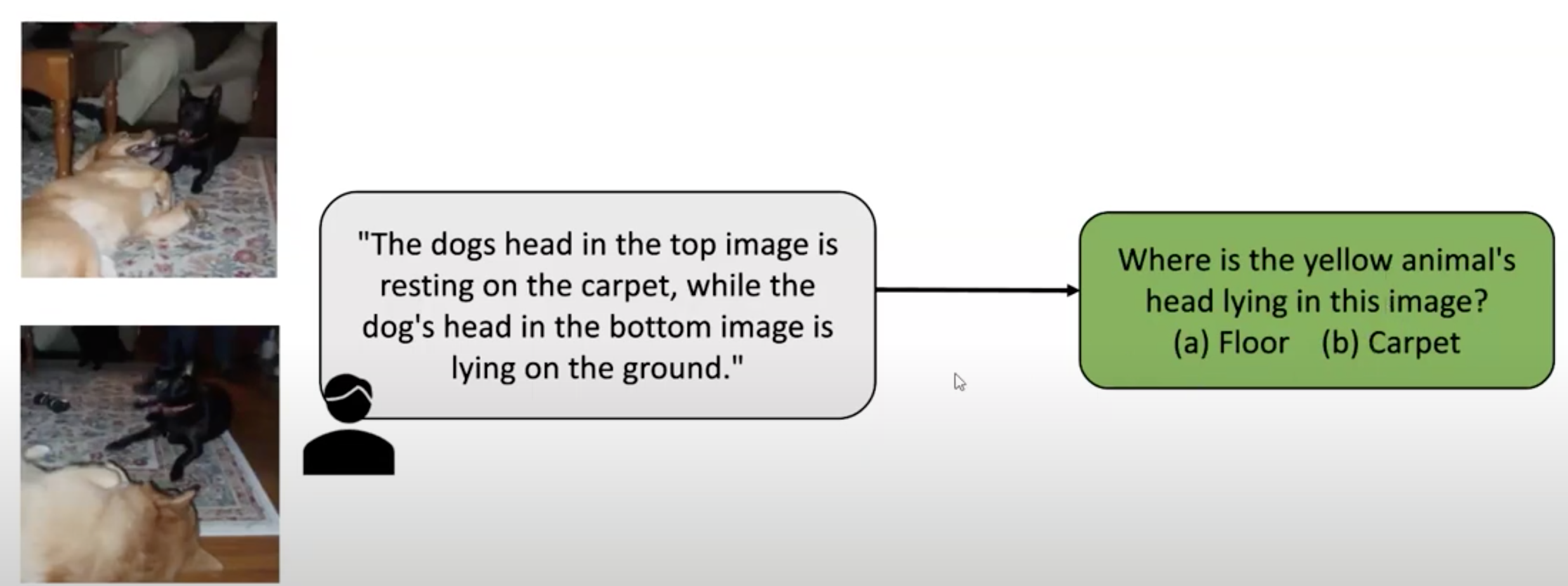
使用大模型对其进行区分,结果如下:
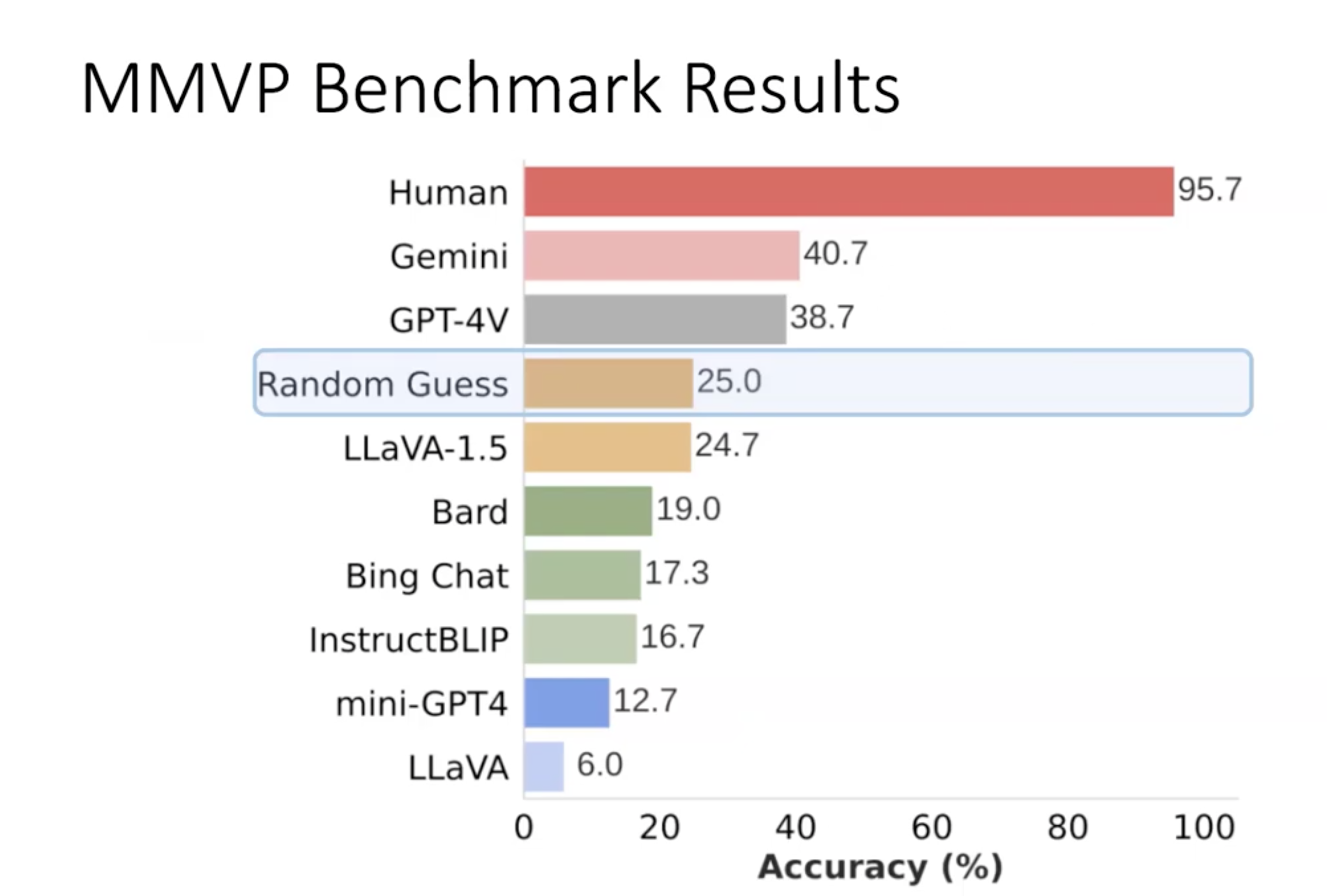
二、MMVP-VLM bench
研究人员辨识出CLIP无法识别的图像对(CLIP-blind pairs)之后,他们梳理了一些系统性的视觉模式,这些模式往往会让CLIP视觉编码器产生误解。
他们参考了MMVP基准测试中的问题和选项。通过这些问题,把图像中难以捉摸的视觉模式转换成了更加清晰、易于归类的基于语言的描述。
研究人员总结出的9种视觉模式如下:

1、Model size influence
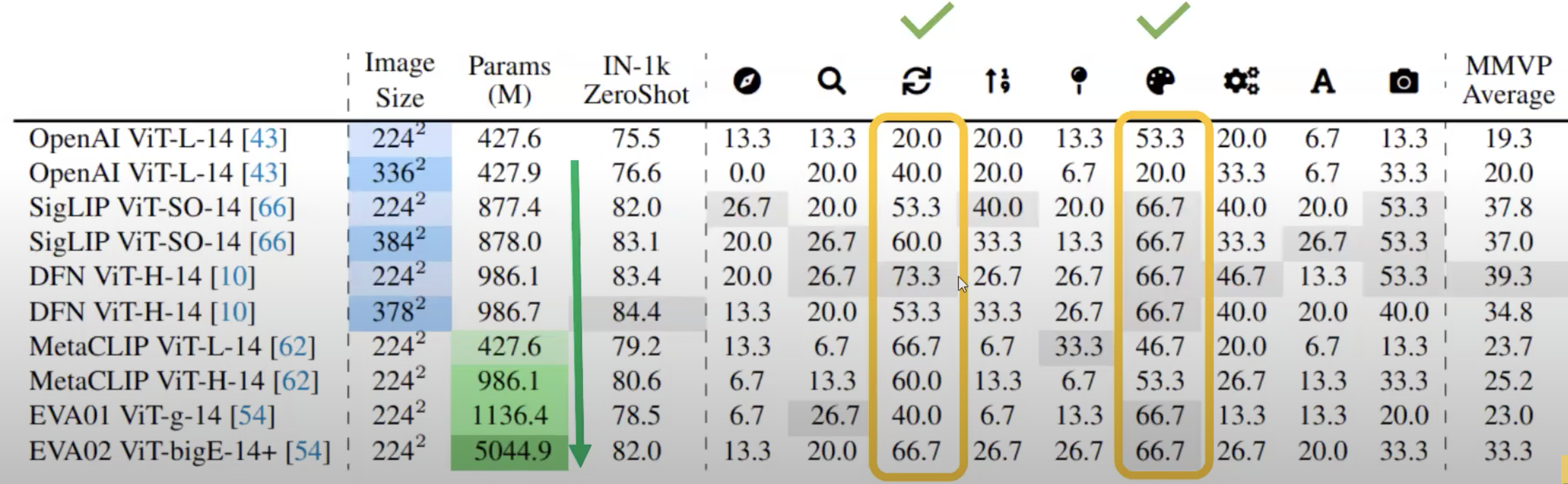
通过测试模型在这些类别上的效果,有以下几个结论:
1)文章表示,扩大model size可以提升3、9两个大类
2)更大图像的分辨率展现了较小的提升
3)当对网络进行成倍缩放时,提升较小
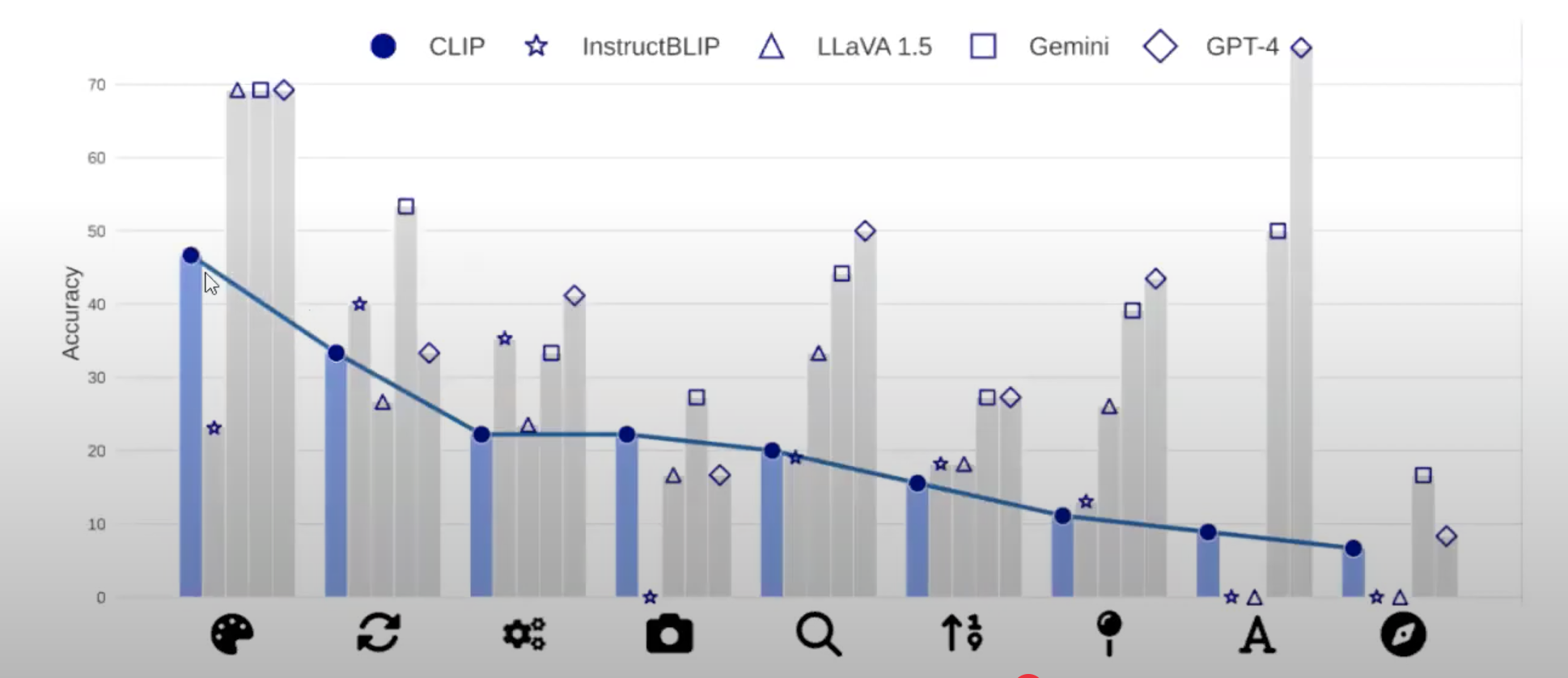
2、correlation between CLIP MLLMs
作者同样在测试了CLIP在MMVP-VLM上的相关性,结论如下:
如果CLIP在在MMVP-VLM表现的比较差,MLLM也是

三、Mixture of Features
针对上述实验,作者提出混合视觉特征来提升MLLM的视觉感知,提出以下两个方法
1)Additive MoF
2)Interleaved MoF
1、Additive MoF Experiment
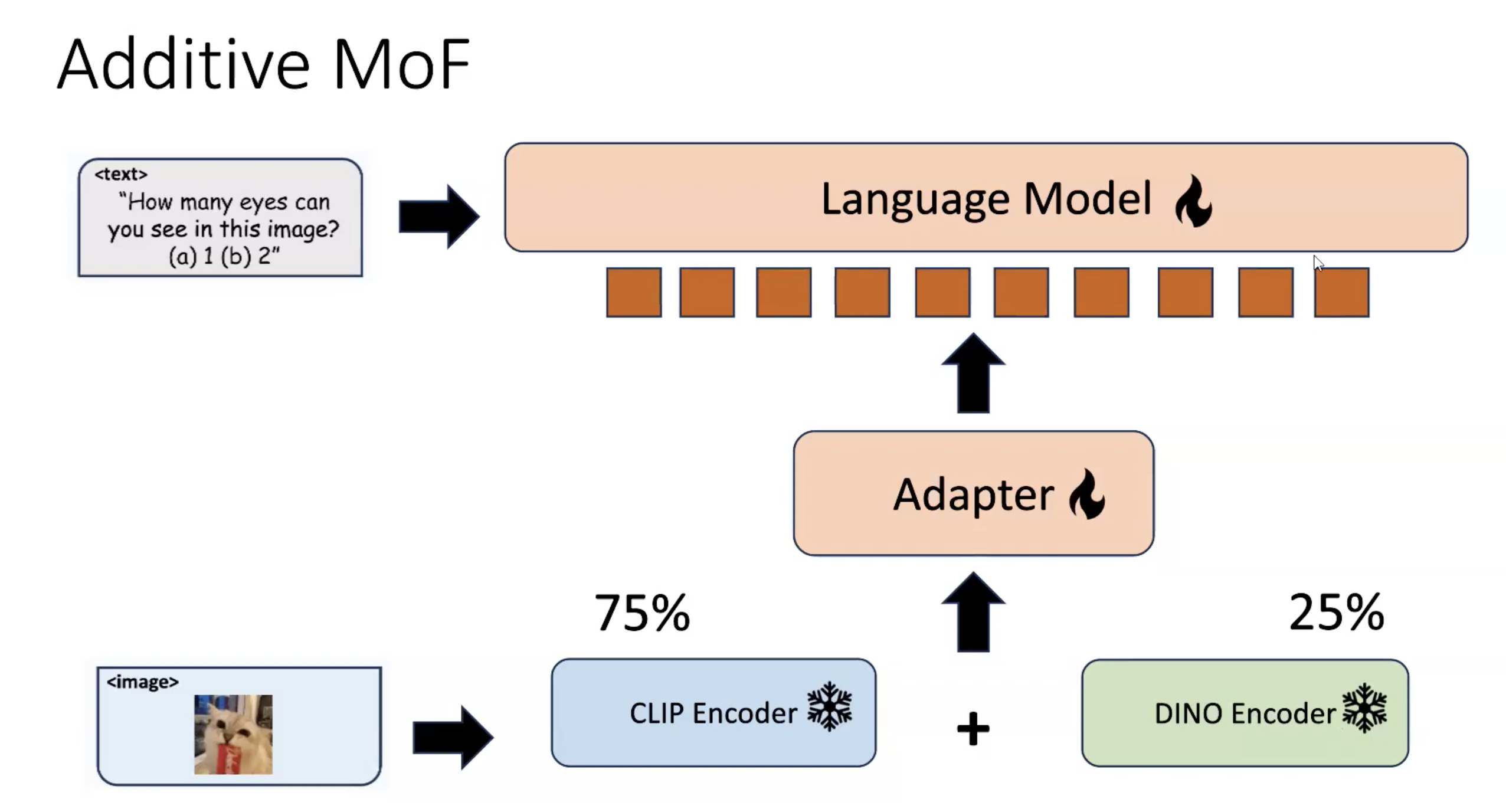
实验参数设置如下:

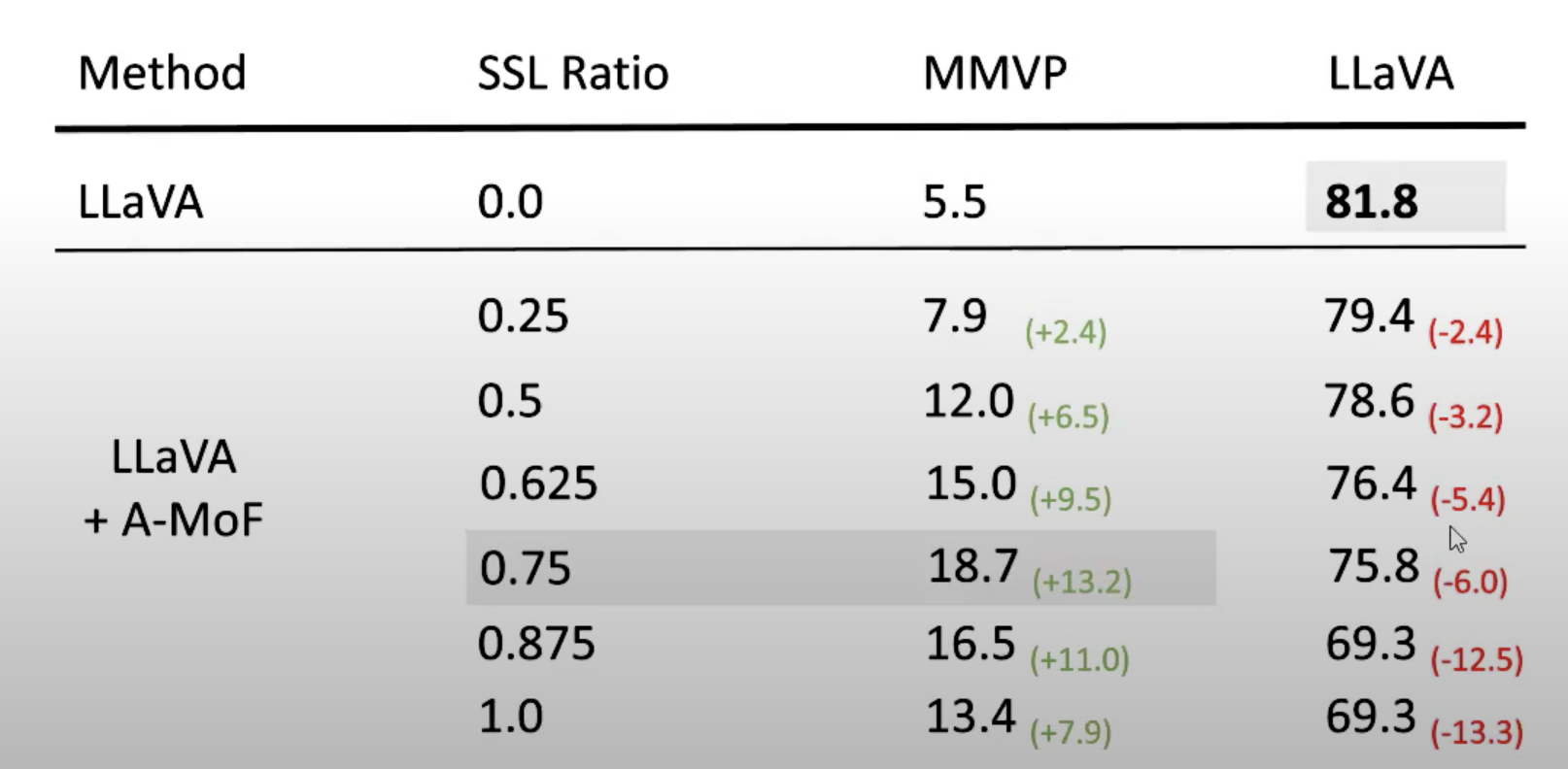
结果如下:
2、Interleaved MoF Experiment
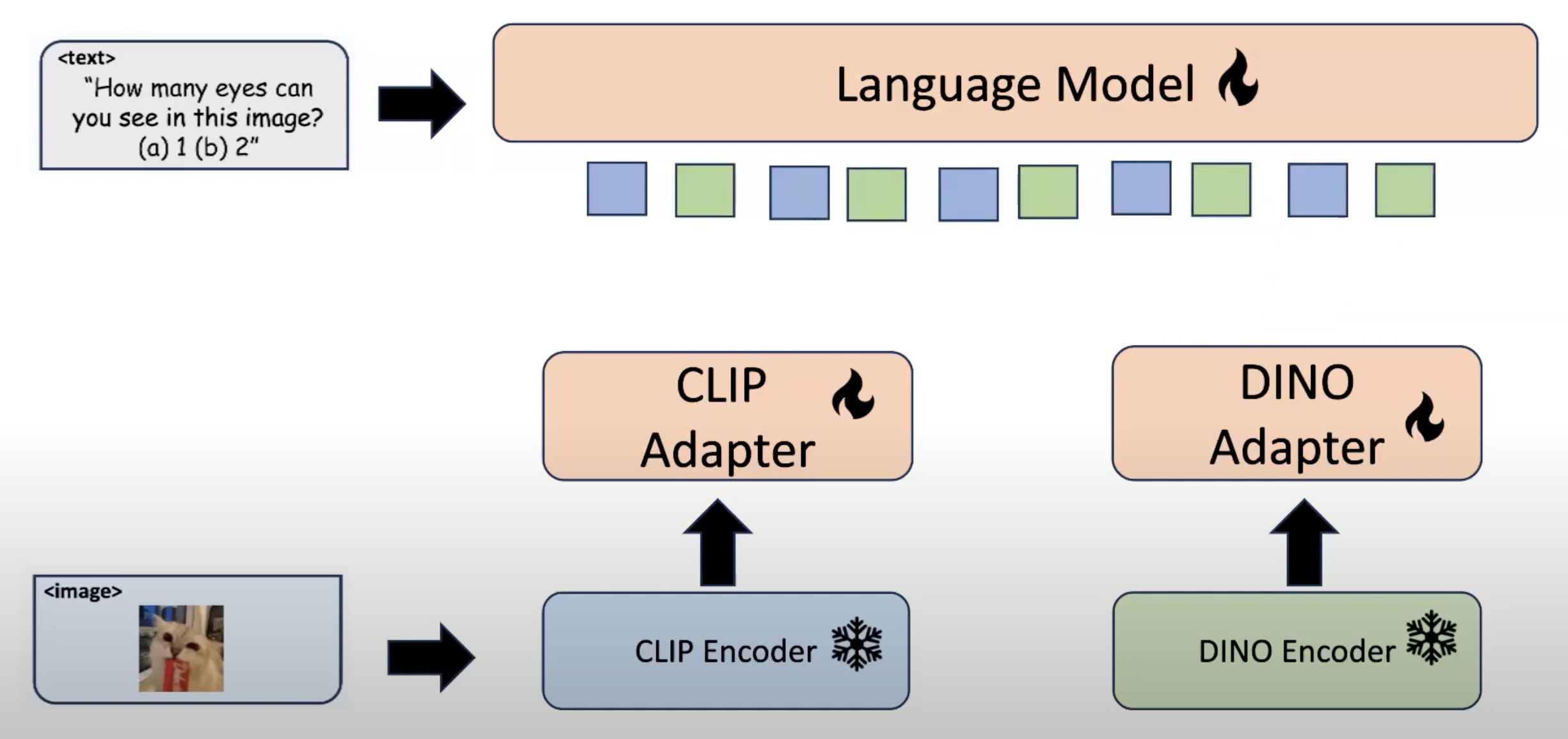
interleaved方式将两个特征向量交叉拼接。结论如下:
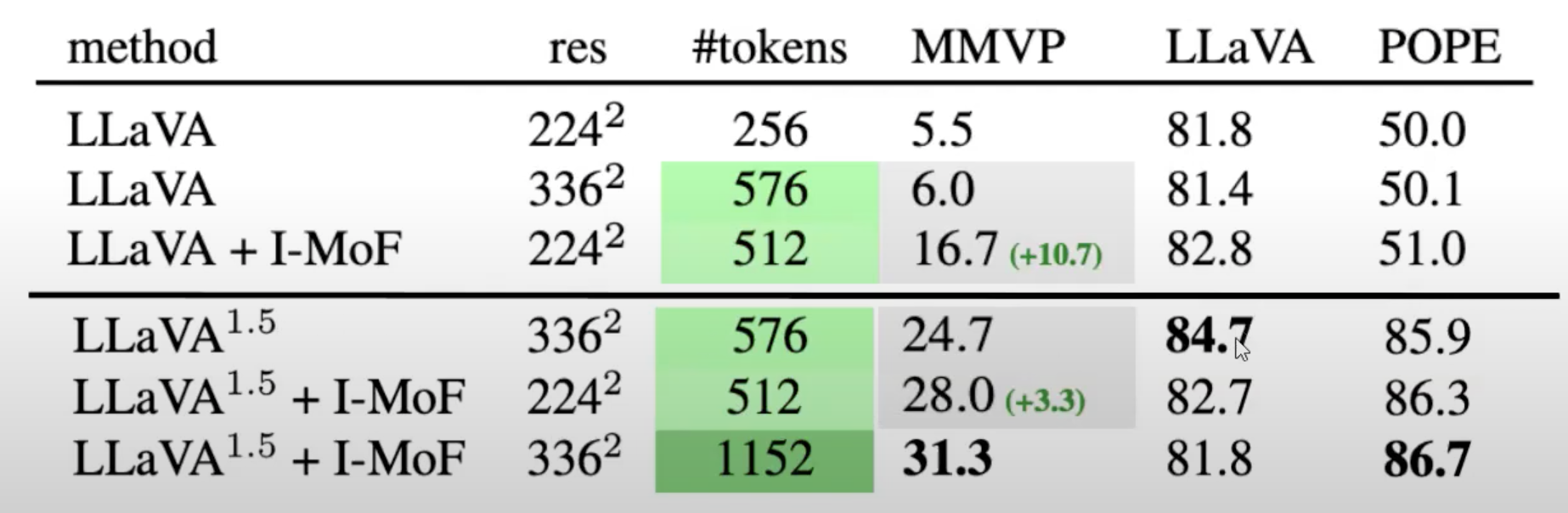
1)I-MoF在其它指标上有很小的改变
2)在MMVP上有显著的增长
总结
总体来说,本文还是给MLLM的视觉端提出了一些新思考,不过仍有些点需要注意,如下:
