【KWDB 2025 创作者计划】_KWDB应用之实战案例
本文是在完成KWDB数据库安装的情况下的操作篇,关于KWDB的介绍与安装部署,可以查看上一篇博客:
https://blog.itpub.net/70045384/viewspace-3081187/
https://blog.csdn.net/m0_38139250/article/details/147234176
本文更多KWDB的SQL操作参考如下:
https://www.kaiwudb.com/kaiwudb_docs/#/oss_v2.2.0/sql-reference/overview.html
开启并连接KWDB
进入已经按照好kwdb的服务器
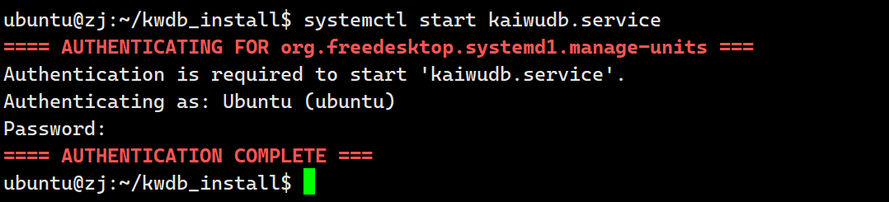
1.启动kwdb
systemctl start kaiwudb.service
输出如下:
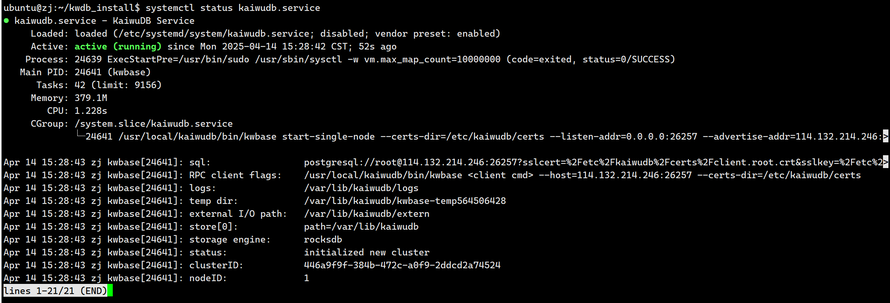
查看状态:
systemctl status kaiwudb.service
输出如下
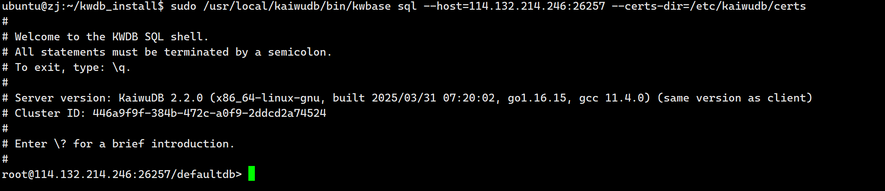
2.登录到命令行的kwdb
执行 add_user.sh 脚本创建数据库用户。如果跳过该步骤,系统将默认使用 root 用户,且无需密码访问数据库。
sudo /usr/local/kaiwudb/bin/kwbase sql --host=114.132.214.246:26257 --certs- dir = /etc/kaiwudb/certs
输出如下:
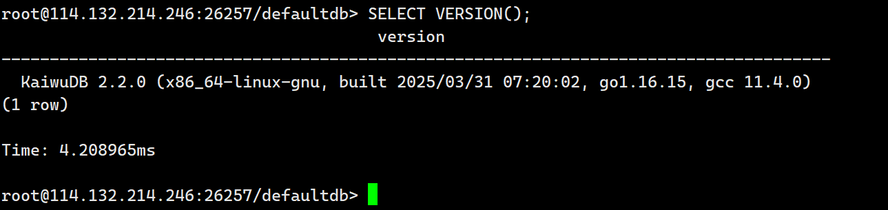
3.查看当前的KWDB版本
SELECT version();
输出如下:
KWDB数据库操作
1.创建数据库
KWDB 时序数据库支持在创建数据库的时候设置数据库的生命周期和分区时间范围。数据库生命周期和分区时间范围的设置与系统的存储空间密切相关。生命周期越长,分区时间范围越大,系统所需的存储空间也越大。有关存储空间的计算公式,参见 预估磁盘使用量。当用户单独指定或者修改数据库内某一时序表的生命周期或分区时间范围时,该配置只适用于该时序表。
生命周期的配置不适用于当前分区。当生命周期的取值小于分区时间范围的取值时,即使数据库的生命周期已到期,由于数据存储在当前分区中,用户仍然可以查询数据。当时间分区的所有数据超过生命周期时间点( now() - retention time)时,系统尝试删除该分区的数据。如果此时用户正在读写该分区的数据,或者系统正在对该分区进行压缩或统计信息处理等操作,系统无法立即删除该分区的数据。系统会在下一次生命周期调度时再次尝试删除数据(默认情况下,每小时调度一次)。
前提条件
用户具有 Admin 角色。默认情况下,root 用户具有 Admin 角色。创建成功后,用户拥有该数据库的全部权限。
语法格式
CREATE TS DATABASE <db_name> [RETENTIONS <keep_duration>] [PARTITION INTERVAL <interval>];

创建一个名为 ts_db_temp 的数据库,并将数据库的生命周期设置为 1年。
CREATE TS DATABASE ts_db_temp RETENTIONS 1Y;
输出如下:

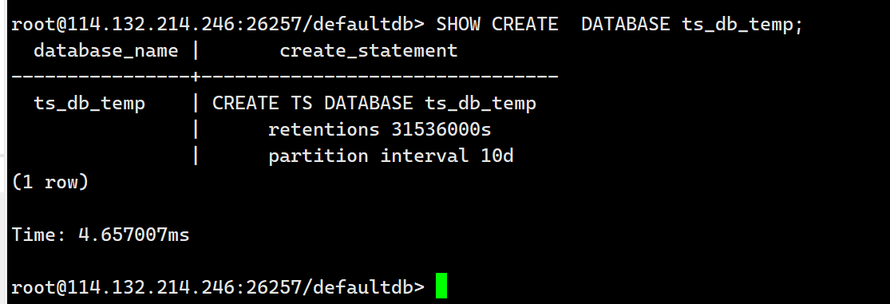
2.查看数据库的建库语句
SHOW CREATE DATABASE ts_db_temp;
输出如下:
3.切换数据库
USE ts_db_temp;
输出如下:
KWDB数据表操作
1.建表操作
语句格式如下
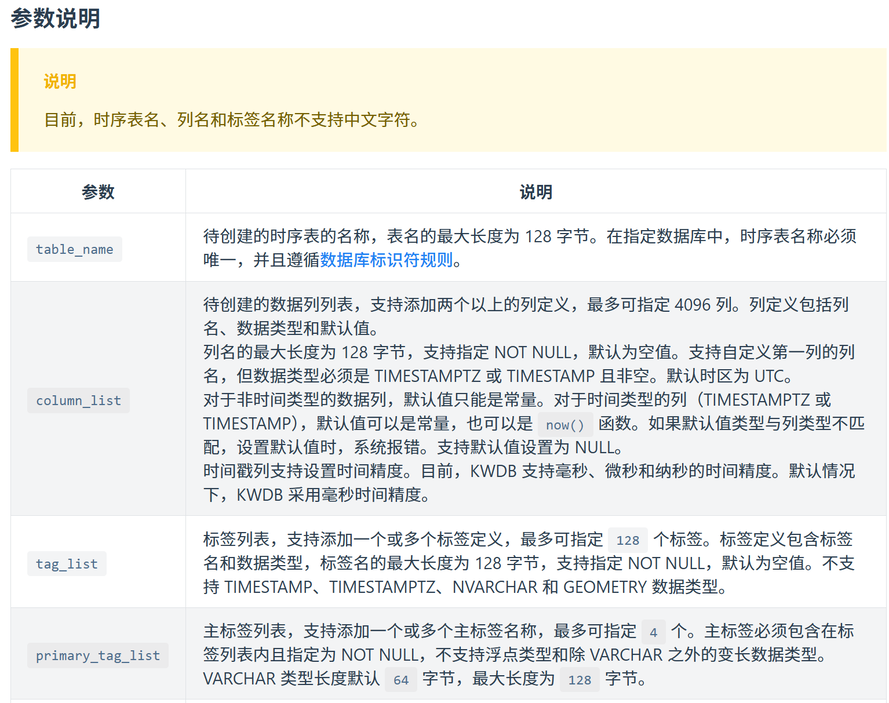
CREATE TABLE <table_name> (<column_list>)
[TAGS|ATTRIBUTES] (<tag_list>)
PRIMARY [TAGS|ATTRIBUTES] (<primary_tag_list>)
[RETENTIONS <keep_duration>]
[ACTIVETIME <active_duration>]
[PARTITION INTERVAL <interval>]
[DICT ENCODING];
参数如下:

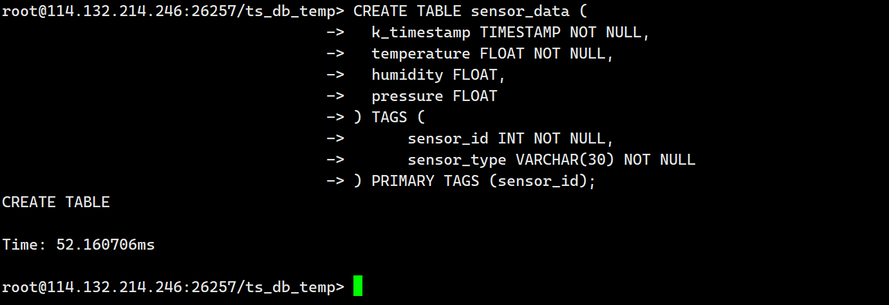
以下示例创建一个名为 sensor_data 的时序表。
- 创建 sensor_data 时序表。
CREATE TABLE sensor_data (k_timestamp TIMESTAMP NOT NULL,temperature FLOAT NOT NULL,humidity FLOAT,pressure FLOAT
) TAGS (sensor_id INT NOT NULL,sensor_type VARCHAR(30) NOT NULL
) PRIMARY TAGS (sensor_id);
输出如下:
- 给sensor_data 时序表添加注释信息。
语法格式,注意注释用单引号。
COMMENT ON [DATABASE <database_name> | TABLE <table_name> | COLUMN <column_name> ] IS <comment_text>;
添加注释的语句
COMMENT ON COLUMN sensor_data.k_timestamp IS '时间戳';
COMMENT ON COLUMN sensor_data.temperature IS '温度';
COMMENT ON COLUMN sensor_data.humidity IS '湿度';
COMMENT ON COLUMN sensor_data.pressure IS '压力';
输出如下:
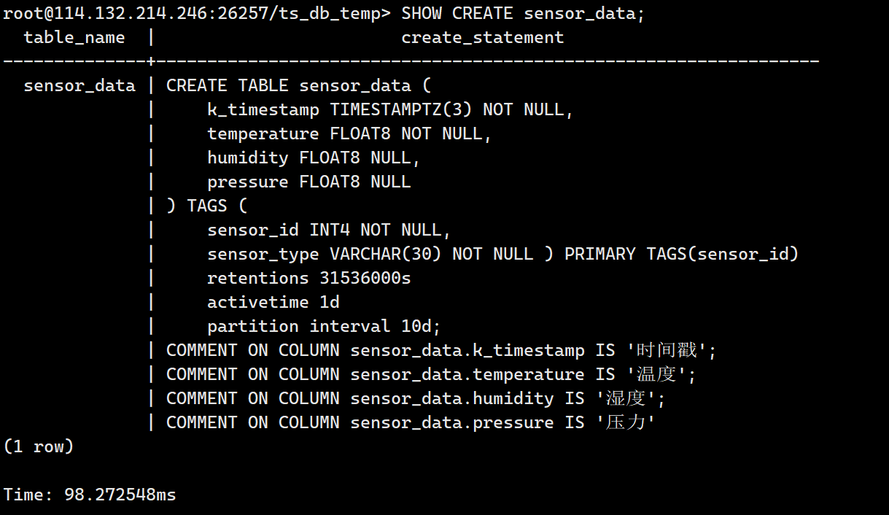
3.查看sensor_data的建表语句
SHOW CREATE sensor_data;
输出如下:
2.插入数据
更多内容参考官网文档
语法如下:
INSERT INTO ts_db_temp. sensor_data VALUES ('2023-07-13 14:06:32.272', 20.0, 0.50, 200, 100,'100数据中心');
输出如下:

基于python生成100条插入语句,包含100和102的两个id,python代码如下:
import random
from datetime import datetime, timedelta
# 定义函数生成时间戳序列
def generate_timestamps(start_time, count):timestamps = []current_time = start_timefor _ in range(count):timestamps.append(current_time.strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]) # 保留到毫秒current_time += timedelta(seconds=10) # 每条记录间隔10秒return timestamps
# 定义温度、湿度和压力的正常范围
def generate_normal_values():temperature = round(random.uniform(18.0, 25.0), 1)humidity = round(random.uniform(0.4, 0.6), 2)pressure = random.randint(190, 210)return temperature, humidity, pressure
# 插入异常值
def generate_abnormal_temperature():return round(random.uniform(30.0, 40.0), 1) if random.random() > 0.5 else round(random.uniform(10.0, 15.0), 1)
# 生成插入语句
def generate_insert_statements(data_center, sensor_id, count, abnormal_count):statements = []timestamps = generate_timestamps(datetime(2023, 7, 13, 14, 6, 32), count)# 随机选择异常值的位置abnormal_indices = random.sample(range(count), abnormal_count)for i in range(count):timestamp = timestamps[i]if i in abnormal_indices:temperature = generate_abnormal_temperature()else:temperature, humidity, pressure = generate_normal_values()humidity = round(random.uniform(0.4, 0.6), 2) if i not in abnormal_indices else round(random.uniform(0.4, 0.6), 2)pressure = random.randint(190, 210) if i not in abnormal_indices else random.randint(190, 210)statement = f"INSERT INTO ts_db_temp.sensor_data VALUES ('{timestamp}', {temperature}, {humidity}, {pressure}, {sensor_id}, '{data_center}');"statements.append(statement)return statements
# 主函数
if __name__ == "__main__":# 生成100数据中心的数据data_center_100 = generate_insert_statements("100数据中心", 100, 50, random.randint(1, 2))# 生成102数据中心的数据data_center_102 = generate_insert_statements("102数据中心", 102, 50, random.randint(1, 2))# 合并结果all_statements = data_center_100 + data_center_102# 输出到文件或打印with open("insert_statements.sql", "w",encoding="UTF8") as f:for statement in all_statements:f.write(statement + "\n")print("SQL插入语句已生成并保存到 insert_statements.sql 文件中!")
生成的内容如下:
把代码复制到KWDB的客户端,并执行
输出如下:
3.查询数据
查看100的数据
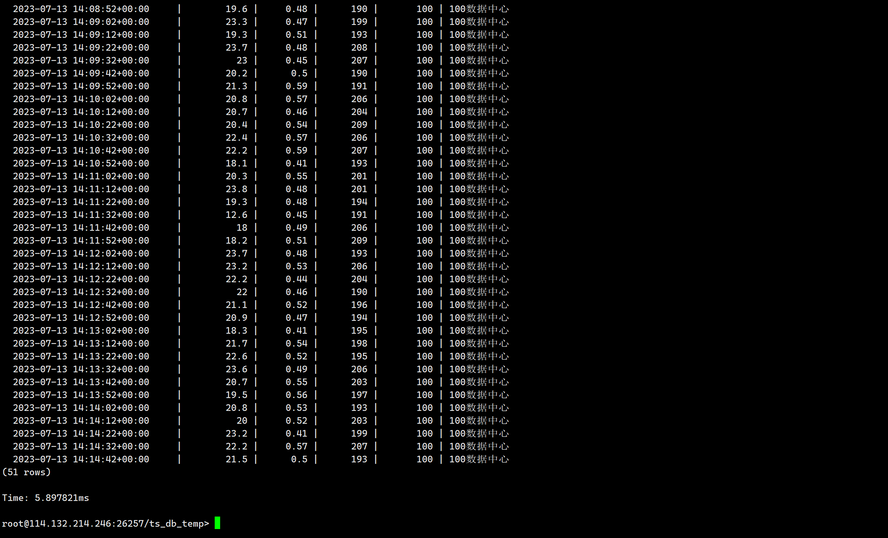
SELECT * FROM ts_db_temp.sensor_data WHERE sensor_id=100;
输出如下:
查看101的数据
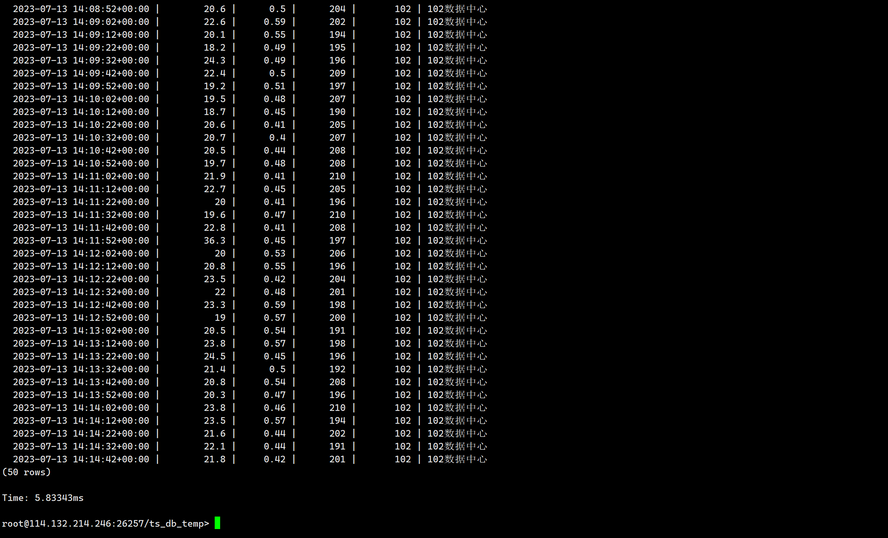
SELECT * FROM ts_db_temp.sensor_data WHERE sensor_id=102;
输出如下:
4.删除数据
DELETE FROM ts_db_temp.sensor_data WHERE k_timestamp in ('2023-07-13 14:14:02', '2023-07-13 14:15:42');
输出如下:

5.复杂查询
对sensor_id为100的进行按照k_timestamp进行排序
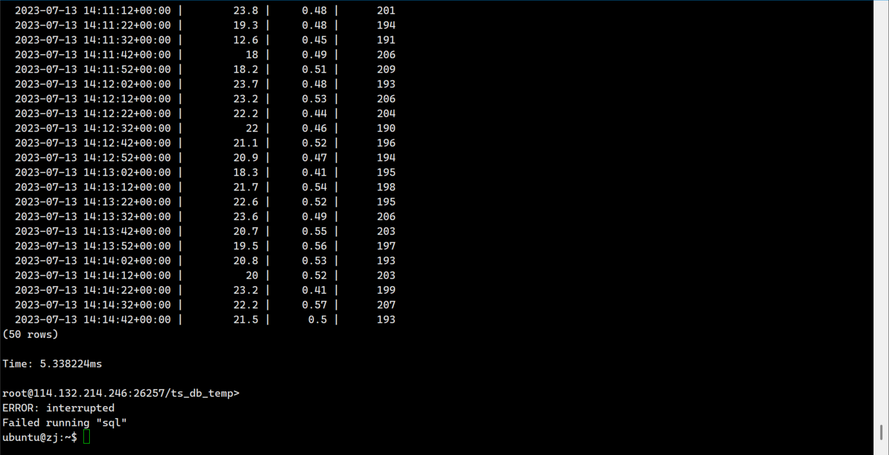
SELECT k_timestamp,temperature,humidity,pressure FROM ts_db_temp.sensor_data WHERE sensor_id=100 ORDER BY k_timestamp;
输出如下:
2023-07-13 14:14:22+00:00 | 23.2 | 0.41 | 199
2023-07-13 14:14:32+00:00 | 22.2 | 0.57 | 207
2023-07-13 14:14:42+00:00 | 21.5 | 0.5 | 193
(50 rows)
Time: 5.338224ms
按照temperature进行分组,并统计每个temperature出现的次数,然后按照temperature排序
SELECT temperature,count(temperature) FROM ts_db_temp.sensor_data WHERE sensor_id=100 GROUP BY temperature ORDER BY temperature;
输出如下:
root@114.132.214.246:26257/ts_db_temp> SELECT temperature,count(temperature) FROM ts_db_temp.sensor_data WHERE sensor_id=100 GROUP BY temperature ORDER BY temperature;
temperature | count
--------------±-------
12.6 | 118 | 118.1 | 118.2 | 118.3 | 118.5 | 118.9 | 2...24.9 | 125 | 1
(37 rows)
Time: 6.048762ms
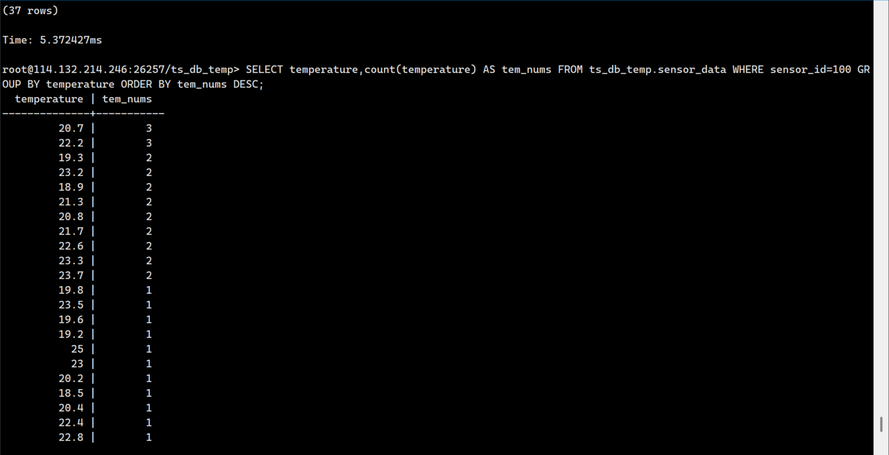
按照temperature进行分组,并统计每个temperature出现的次数,然后按照temperature 出现的次数降序排序
SELECT temperature,count(temperature) AS tem_nums FROM ts_db_temp.sensor_data WHERE sensor_id=100 GROUP BY temperature ORDER BY tem_nums DESC;
输出如下:
Python操作KWDB数据库
基于编程语言访问操作KWDB数据库的方法可以参考如下:
https://www.kaiwudb.com/kaiwudb_docs/#/development/overview.html
1.安装Python依赖
Psycopg 是PostgreSQL 数据库适配器,专为 Python 编程语言而设计。Psycopg 完全遵循 Python DB API 2.0 规范,支持线程安全,允许多个线程共享同一连接,特别适合高并发和多线程的应用场景。
KaiwuDB 支持用户通过 Psycopg 3 连接数据库,并执行创建、插入和查询操作。本示例演示了如何通过 Psycopg 3 驱动连接和使用 KaiwuDB。
本示例使用的 Python 版本为 Python 3.12。
pip3 install "psycopg[binary]"
输出如下:
Installing collected packages: tzdata, typing-extensions, psycopg-binary, psycopg
Successfully installed psycopg-3.2.6 psycopg-binary-3.2.6 typing-extensions-4.13.2 tzdata-2025.2
创建名为 example-psycopg3-app.ipynb 文件
2.KWDB数据库设置密码
Python连接KWDB数据库时,需要指定密码,现在给KWDB设置密码。
1)root 用户登录 defaultdb 数据库。
2)root 用户创建用户并为用户设置密码。
以下示例创建 user1 用户,并为 user1 用户设置密码。
CREATE USER user1 WITH PASSWORD '11aa!!AA';
3)给user1用户配置基于密码的认证参数。
授权的语法格式如图所示
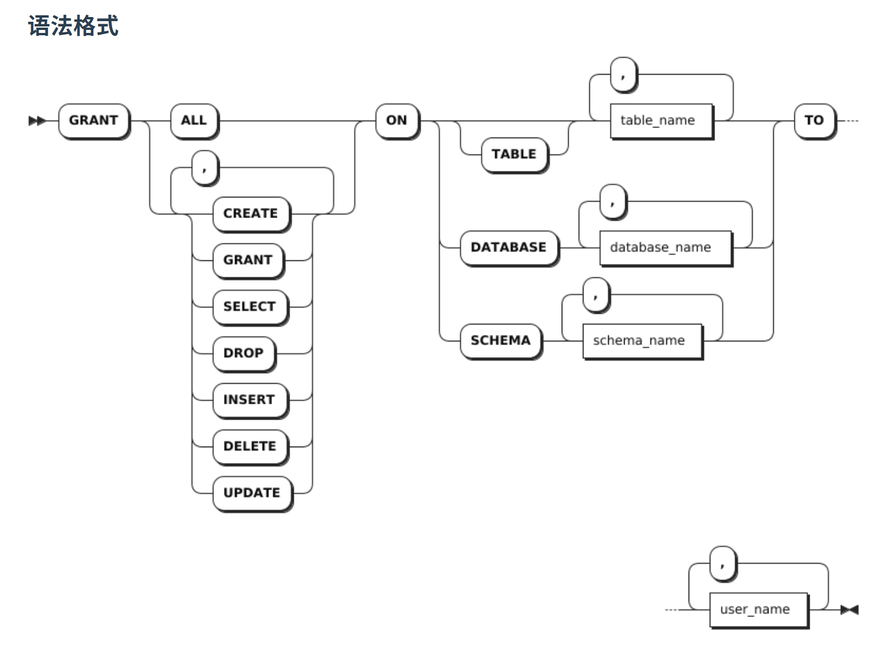
以下示例允许 user1 用户使用密码登录 ts_db_temp 数据库。
GRANT ALL ON DATABASE ts_db_temp, defaultdb TO user1;
输出如下:

查看数据库权限
SHOW GRANTS ON DATABASE ts_db_temp;
以下示例允许 user1 用户使用密码访问 ts_db_temp 数据库的sensor_data表。
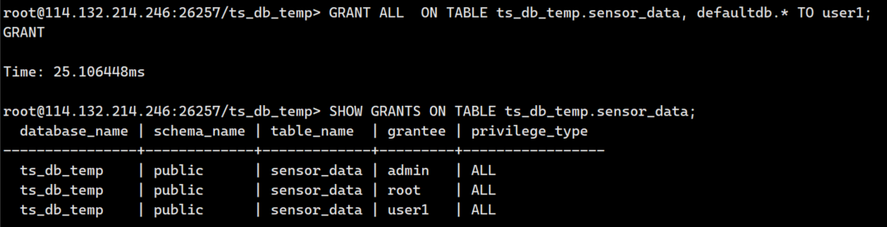
GRANT ALL ON TABLE ts_db_temp.sensor_data, defaultdb.* TO user1;
查看 sensor_data表的权限:
SHOW GRANTS ON TABLE ts_db_temp.sensor_data;
输出如下:
3.Python连接KWDB数据库
python代码如下:
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import psycopg
def main():con=Nonecur=None# 指定数据库url user1是用户名 11aa!!AA是密码url = "postgresql://user1:11aa!!AA@114.132.214.246:26257/ts_db_temp"# for secure connection mode# url = "postgresql://root@127.0.0.1:26257/defaultdb"# url += "?sslrootcert=D:\\Tools\\test\\example-app-c\\example-app-cpp\\ca.crt"# url += "&sslcert=D:\\Tools\\test\\example-app-c\\example-app-cpp\\client.root.crt"# url += "&sslkey=D:\\Tools\\test\\example-app-c\\example-app-cpp\\client.root.key"print(url)try:# 连接数据库con = psycopg.connect(url, autocommit=True)print(" 连接数据库 Connected!")cur = con.cursor()except psycopg.Error as e:# 连接数据库失败print(f"连接 Kaiwudb 失败: {e}")# 建表语句# Failed to create db/table: only users with the admin role are allowed to CREATE DATABASE# sql_db = "CREATE DATABASE IF NOT EXISTS ts_db_temp"# sql_table = "CREATE TABLE IF NOT EXISTS ts_db_temp.table1 \# (k_timestamp timestamp NOT NULL, \# voltage double, \# current double, \# temperature double \# ) TAGS ( \# number int NOT NULL) \# PRIMARY TAGS(number) \# ACTIVETIME 3h"# try:# cur.execute(sql_db)# cur.execute(sql_table)# except psycopg.Error as e:# print(f"Failed to create db/table: {e}")# 插入数据sql_insert = "INSERT INTO ts_db_temp.sensor_data VALUES ('2023-07-14 14:14:42.000', 21.8, 0.42, 201, 102, '102数据中心');"try:cur.execute(sql_insert)except psycopg.Error as e:print(f"Failed to insert data: {e}")sql_seclet = "SELECT * from ts_db_temp.sensor_data"try:cur.execute(sql_seclet)rows = cur.fetchall()for row in rows:print(f"k_timestamp: {row[0]}, temperature: {row[1]}, humidity: {row[2]}, pressure: {row[3]}, sensor_id: {row[4]}, sensor_type: {row[5]}")except psycopg.Error as e:print(f"Failed to insert data: {e}")cur.close()con.close()return
if __name__ == "__main__":main()
输出如下:

实战案例Python读取KWDB数据库,并完成时序数据预测
Python已经完成的KWDB数据库的连接测试,下面进行一个案例模拟:
生成1000条插入输入数据,要求包含100数据中心,时间戳以每小时粒度生成一条数据,其中每间隔7天,当天的温度出现5-8次的异常值,
生成数据的Python代码如下:
import random
from datetime import datetime, timedelta
# 定义函数生成时间戳序列
def generate_timestamps(start_time, count):timestamps = []current_time = start_timefor _ in range(count):timestamps.append(current_time.strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]) # 保留到毫秒current_time += timedelta(hours=1) # 每条记录间隔1小时return timestamps
# 定义温度、湿度和压力的正常范围
def generate_normal_values():temperature = round(random.uniform(18.0, 25.0), 1)humidity = round(random.uniform(0.4, 0.6), 2)pressure = random.randint(190, 210)return temperature, humidity, pressure
# 插入异常值
def generate_abnormal_temperature():return round(random.uniform(30.0, 40.0), 1) if random.random() > 0.5 else round(random.uniform(10.0, 15.0), 1)
# 主函数
if __name__ == "__main__":# 初始参数start_time = datetime(2023, 7, 13, 14, 0, 0) # 起始时间total_records = 1000 # 总记录数sensor_id = 100data_center = "100数据中心"# 生成时间戳timestamps = generate_timestamps(start_time, total_records)# 初始化结果列表insert_statements = []# 遍历时间戳并生成数据for i, timestamp in enumerate(timestamps):# 判断是否是每隔7天的当天is_seventh_day = (start_time + timedelta(hours=i)).day % 7 == 0if is_seventh_day:# 每隔7天的当天,随机生成5-8次异常值abnormal_count = random.randint(5, 8)if i % 24 < abnormal_count: # 前 abnormal_count 条为异常值temperature = generate_abnormal_temperature()else:temperature, humidity, pressure = generate_normal_values()else:# 正常值temperature, humidity, pressure = generate_normal_values()# 构造插入语句statement = (f"INSERT INTO ts_db_temp.sensor_data VALUES ('{timestamp}', {temperature}, {humidity}, {pressure}, "f"{sensor_id}, '{data_center}');")insert_statements.append(statement)# 输出到文件或打印with open("insert_statements.sql", "w",encoding="UTF8") as f:for statement in insert_statements:f.write(statement + "\n")print("SQL插入语句已生成并保存到 insert_statements.sql 文件中!")
生成的插入语句部分如下
– 正常数据
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-13 14:00:00.000’, 20.0, 0.50, 200, 100, ‘100数据中心’);
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-13 15:00:00.000’, 21.5, 0.55, 201, 100, ‘100数据中心’);
– 第7天的异常数据
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-20 00:00:00.000’, 35.0, 0.50, 200, 100, ‘100数据中心’); – 异常值
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-20 01:00:00.000’, 10.0, 0.50, 200, 100, ‘100数据中心’); – 异常值
…
– 第14天的正常数据
INSERT INTO ts_db_temp.sensor_data VALUES (‘2023-07-27 14:00:00.000’, 22.0, 0.45, 205, 100, ‘100数据中心’);
…
安装python的依赖库
pip install pandas matplotlib statsmodels -i https://pypi.tuna.tsinghua.edu.cn/simple
输出如下:
Successfully installed contourpy-1.3.1 cycler-0.12.1 fonttools-4.57.0 kiwisolver-1.4.8 matplotlib-3.10.1 numpy-2.2.4 packaging-24.2 pandas-2.2.3 patsy-1.0.1 pillow-11.2.1 pyparsing-3.2.3 python-dateutil-2.9.0.post0 pytz-2025.2 scipy-1.15.2 six-1.17.0 statsmodels-0.14.4
把数据插入到KWDB中,然后用Python读取,并进行时间预测,如下:
首先连接数据库
import psycopg
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
con=None
cur=None
# 指定数据库url user1是用户名 11aa!!AA是密码
url = "postgresql://user1:11aa!!AA@114.132.214.246:26257/ts_db_temp"
try:# 连接数据库con = psycopg.connect(url, autocommit=True)print(" 连接数据库 Connected!")cur = con.cursor()
except psycopg.Error as e:# 连接数据库失败print(f"连接 Kaiwudb 失败: {e}")
# 数据库查询代码
sql_select = "SELECT * FROM ts_db_temp.sensor_data"
输出如下:
连接数据库 Connected!
df=None
# 数据库查询代码
try:# 假设已经建立数据库连接 conn 和游标 curcur.execute(sql_select)rows = cur.fetchall()# 将查询结果转换为 Pandas DataFramedf = pd.DataFrame(rows, columns=["k_timestamp", "temperature", "humidity", "pressure", "sensor_id", "sensor_type"])# 确保时间戳列为 datetime 类型df["k_timestamp"] = pd.to_datetime(df["k_timestamp"])# 设置时间戳为索引df.set_index("k_timestamp", inplace=True)print("数据加载成功!")
except psycopg.Error as e:print(f"Failed to fetch data: {e}")
df
输出如下:
数据加载成功!
异常与窗口检测
# 异常检测函数
def detect_anomalies_zscore(data, threshold=3):mean = data.mean() # 计算数据的平均值std = data.std() # 计算数据的标准差anomalies = data[(data - mean).abs() > threshold * std] # 找出与平均值差异超过阈值倍标准差的点return anomalies # 返回异常值
def detect_anomalies_rolling(data, window=24, threshold=2):rolling_mean = data.rolling(window=window).mean() # 计算滚动窗口的平均值rolling_std = data.rolling(window=window).std() # 计算滚动窗口的标准差anomalies = data[(data - rolling_mean).abs() > threshold * rolling_std] # 找出偏离滚动均值超过阈值倍标准差的值return anomalies # 返回异常值
检测与查看异常值
# 检测异常值
df["anomaly_zscore"] = detect_anomalies_zscore(df["temperature"])
df["anomaly_rolling"] = detect_anomalies_rolling(df["temperature"])
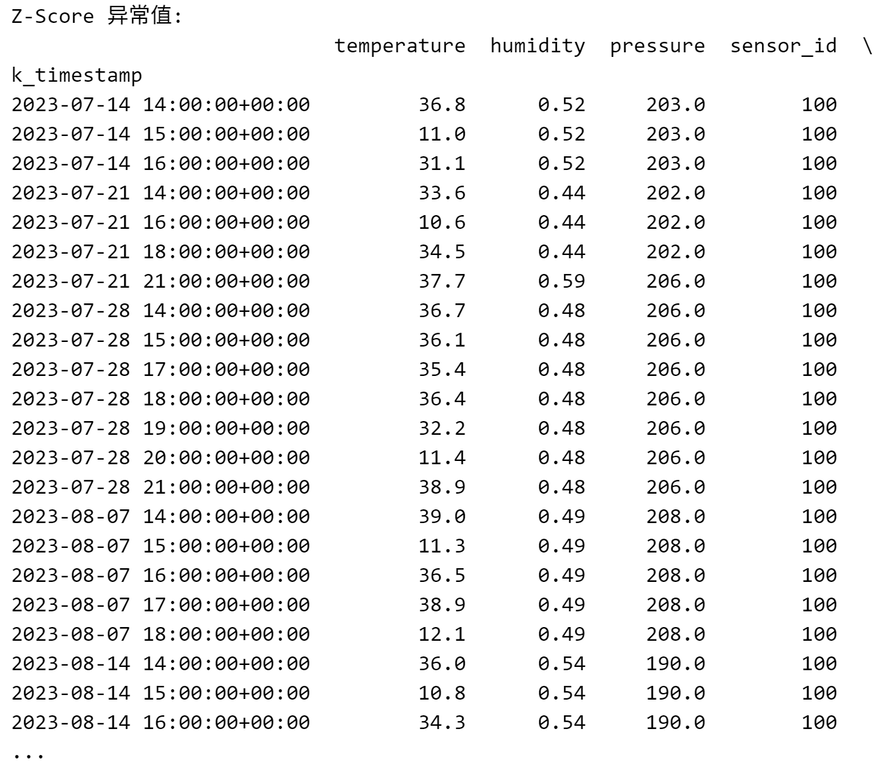
# 查看异常值
print("Z-Score 异常值:")
print(df[df["anomaly_zscore"].notnull()])
print("\n滚动窗口异常值:")
print(df[df["anomaly_rolling"].notnull()])
输出如下:
划分训练集与测试集
# 时间序列预测
temperature_series = df["temperature"]
train_size = int(len(temperature_series) * 0.8)
train, test = temperature_series[:train_size], temperature_series[train_size:]
查看训练集train
输出如下:
查看测试集
test
输出如下:
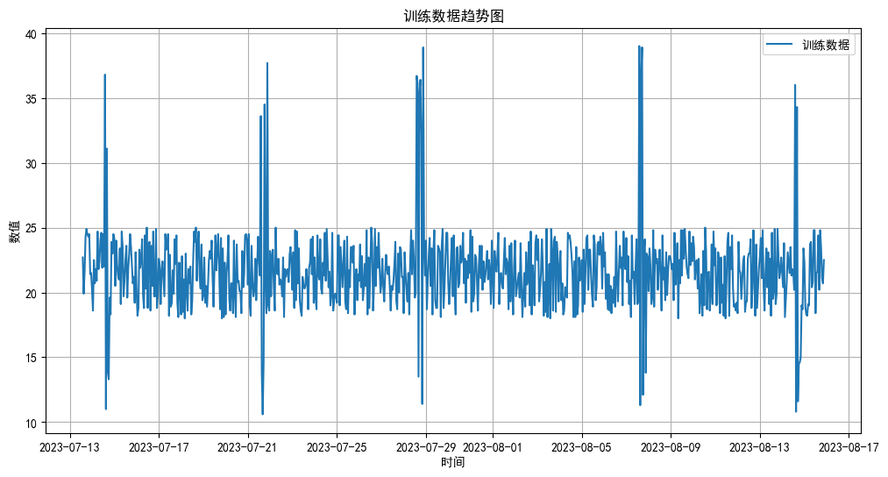
对训练数据进行可视化操作
# 训练数据可视化
# 设置中文显示和负数显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(12, 6))
plt.plot(train, label='训练数据')
plt.title('训练数据趋势图')
plt.xlabel('时间')
plt.ylabel('数值')
plt.legend()
plt.grid(True)
plt.show()
输出如下:
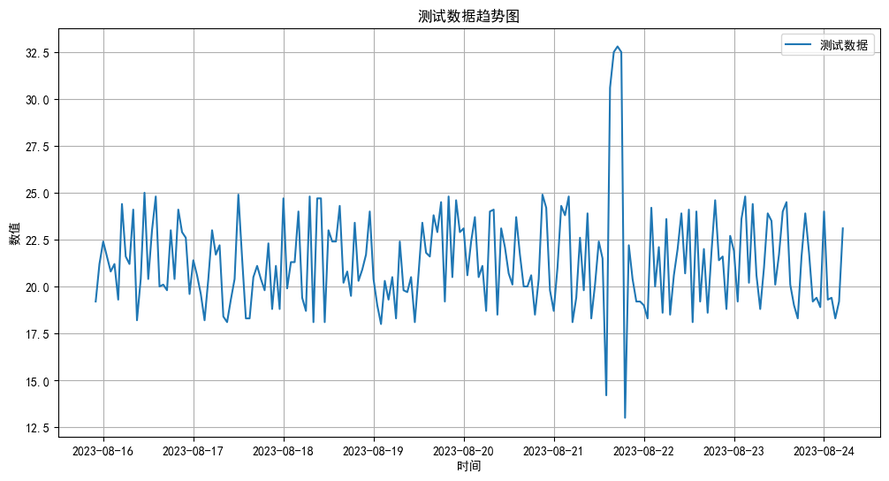
对测试集进行可视化操作
# 训练数据可视化
# 设置中文显示和负数显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(12, 6))
plt.plot(test, label='测试数据')
plt.title('测试数据趋势图')
plt.xlabel('时间')
plt.ylabel('数值')
plt.legend()
plt.grid(True)
plt.show()
输出如下:
查看季节性分解
# 方案2:季节性分解
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df["temperature"], model='additive', period=24)
result.plot()
# 可以看到存在季节性
输出如下:
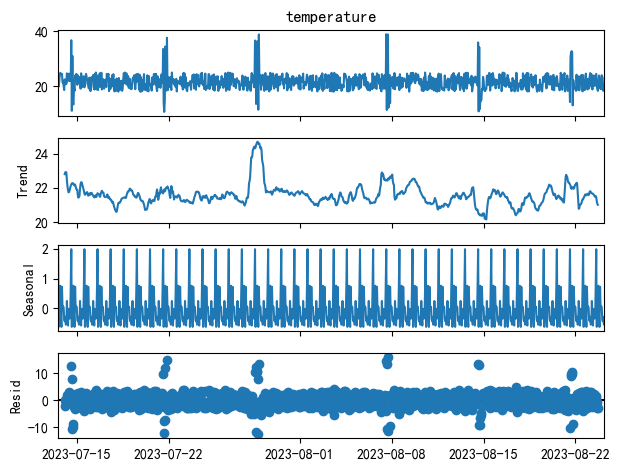
使用季节性算法
from statsmodels.tsa.statespace.sarimax import SARIMAX
# (p,d,q)为非季节性参数,(P,D,Q,24)为季节性参数
model = SARIMAX(train.asfreq('h'), order=(1,1,1), seasonal_order=(1,1,1,24))
model_fit = model.fit()
预测未来值
预测未来值
forecast_steps = len(test)
forecast = model_fit.forecast(steps=forecast_steps)
查看预测结果
# 可视化预测结果
plt.figure(figsize=(12, 6))
plt.plot(test.index, test, label="实际值")
plt.plot(test.index, forecast, label="预测值", color="red")
plt.title("温度预测")
plt.xlabel("时间")
plt.ylabel("温度")
plt.legend()
plt.show()
输出如下:
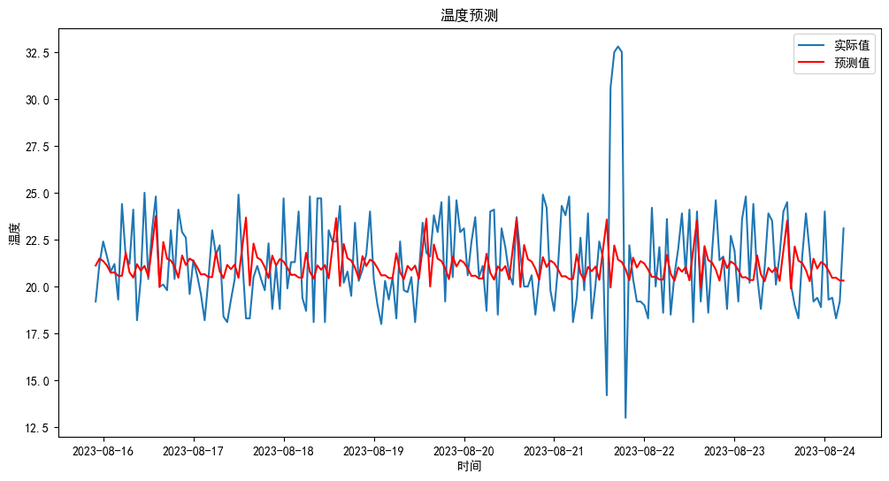
到此基于Python针对KWDB中的时序数据的完整预测过程已经完成,进一步的优化步骤,这里不再拓展
打完收工,感谢你看到这了,这个博客花了很久,未来在使用过程中,再进一步分享。