本文内容主要来源于Learning eBPF,可阅读原文了解更全面的内容。
本文涉及源码也来自于书中对应的github:https://github.com/lizrice/learning-ebpf/
概述
上篇文章主要讲了CO-RE最关键的一环:BTF,了解其如何记录内核中的数据结构和函数信息。本文将介绍如何编写一个插入到内核中的 eBPF 程序。
示例代码使用 C 语言,编译器是 clang, 另外还需要 libbpf 库(提供一些 ebpf 程序常用的宏和函数定义)。
CO-RE eBPF 程序
一个完整的 eBPF 程序分为两个部分:用于实现具体函数功能的kernel 层的代码,文件后缀是 .bpf.c;以及用于控制 ebpf 代码的加载,卸载,生命周期等控制逻辑的用户层代码,文件后缀是.c。我们先主要看下 kernel 层代码如何编写。
下图为代码流程总览,可以看到和常规 C 程序大致相同,只是其中一些函数、结构体定义会有差异,下面将详细讲解每一部分。
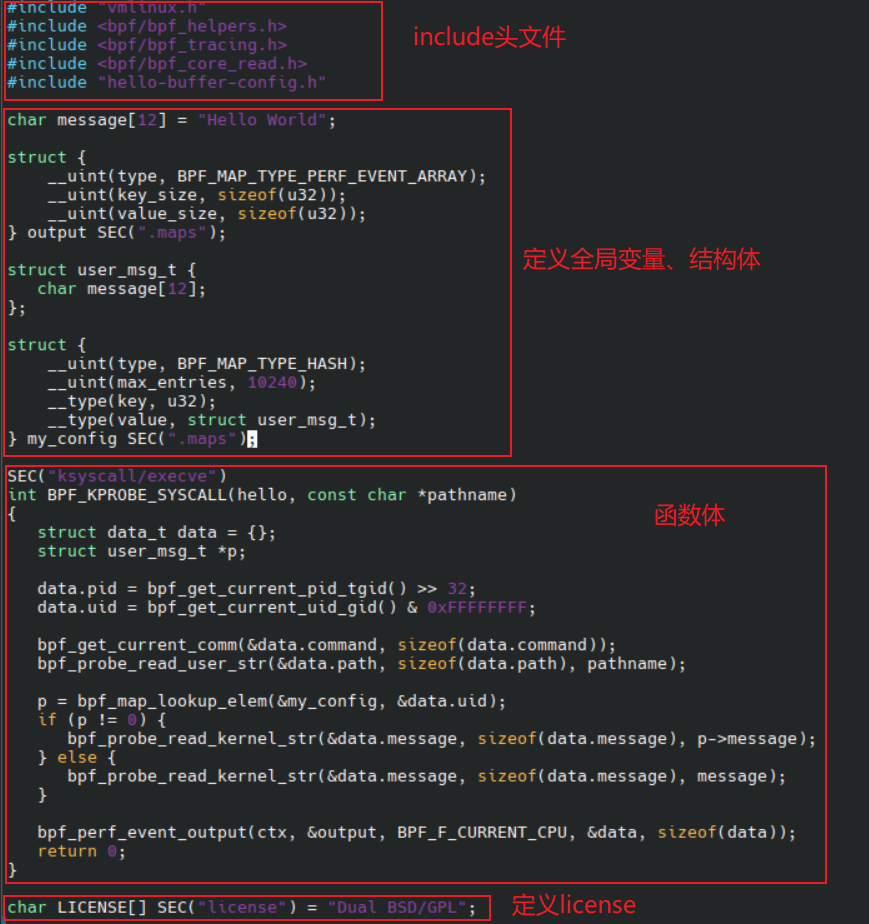
头文件
如常规 C 文件一样,ebpf 程序也需要包含头文件,但与常规 C 程序相比要简单很多。因为内核通用的头文件都已经包含在生成的vmlinux.h了,所以对于需要用到的内核函数,我们只需要包含这一个头文件!此外,就是 bpf 需要用到的一些辅助函数的头文件,以及我们自己实现的头文件。
这里需要注意的是,vmlinux.h 并不会包含#define定义的值,所以如果需要的话需要额外包含,本文不会涉及到此类情况。
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include "hello-buffer-config.h"
定义Maps
这一部分主要是定义我们需要用到的结构体,其中有两个map,第一个是 arrary 类型的 output, 另外一个是 hash 类型的 my_config. 其中会说明map中 key, value 的类型, 大小, map 最多容纳的数量等属性.
struct {__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);__uint(key_size, sizeof(u32));__uint(value_size, sizeof(u32));
} output SEC(".maps");struct user_msg_t {char message[12];
};struct {__uint(type, BPF_MAP_TYPE_HASH);__uint(max_entries, 10240);__type(key, u32);__type(value, struct user_msg_t);
} my_config SEC(".maps");
和我们之前见到的 C 程序不同的是, 每个结构体中都用宏定义来描述其类型, 属性. 如 __uint, __type 等. 这些宏定义在 bpf_helpers.h 中, 如下所示:
#define __uint(name, val) int (*name)[val]
#define __type(name, val) typeof(val) *name
#define __array(name, val) typeof(val) *name[]
使用这些宏定义会有更好的可读性.
eBPF 程序段 (Sections)
libbpf 要求 eBPF 程序需要用 SEC() 宏来定义其程序类型, 如:
SEC("kprobe")
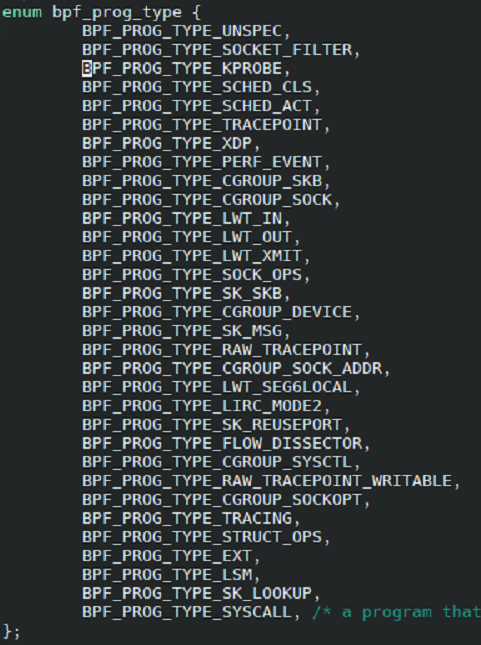
这将会在程序最终编译生成的 elf 对象中保留一个名为 kprobe 的 section, 以便 libbpf 知道应该将这个程序加载为 BPF_PROG_TYPE_KPROBE 类型. eBPF 程序的类型定义在 include/uapi/linux/bpf.h 中, 如下图所示.
我们可以看到一些 kernel 中常见的一些机制, 如kprobe, tracepoint, perf event, cgroup 等.
eBPF 程序都可以附加在这些功能上, 用来捕获内核中程序的运行状况.
还可以用 SEC() 来指名我们需要将 eBPF 程序附加在什么事件上, 然后 libbpf 会自动帮我们处理, 而不用我们在函数中设定. 例如: 如果我们需要在 arm64 架构中, 将 eBPF 程序附加在 execve 系统调用的 kprobe 上, 只需要这样:
SEC("kprobe/__arm64_sys_execve")
当然, 这需要我们熟悉当前架构的系统调用函数名, libbpf 对此做了优化, 我们只需要用 ksyscall section, libbpf 就会自动找到当前架构对应的系统调用, 如:
SEC("ksyscall/execve")
eBPF 函数代码
接下来我们看实际函数功能代码
SEC("ksyscall/execve")
int BPF_KPROBE_SYSCALL(hello, const char *pathname)
{struct data_t data = {}; //用来保存最终要输出的信息struct user_msg_t *p; //保存commanddata.pid = bpf_get_current_pid_tgid() >> 32; //获取触发ebpf程序的piddata.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF; //获取触发ebpf程序的uidbpf_get_current_comm(&data.command, sizeof(data.command)); //获取当前commandbpf_probe_read_user_str(&data.path, sizeof(data.path), pathname); //获取当前执行程序的路径p = bpf_map_lookup_elem(&my_config, &data.uid); //从my_config map中寻找uid对应的messageif (p != 0) {/*如果map中有对应的值,则输出map中的message*/bpf_probe_read_kernel_str(&data.message, sizeof(data.message), p->message);} else {/*否则输出默认值: hello world*/bpf_probe_read_kernel_str(&data.message, sizeof(data.message), message); }/*将结果输出到perf buffer缓冲区中*/bpf_perf_event_output(ctx, &output, BPF_F_CURRENT_CPU, &data, sizeof(data)); return 0;
}
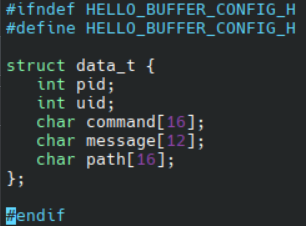
data_t 定义在 hello-buffer-config.h 中, 如图:
注意: eBPF 对于代码有严格的检查, 以防止其损坏内核的稳定性. 因此 eBPF 程序中是不能直接用常规方式访问内存的, (x = p->y这种当然是不允许的) , 需要通过BPF 辅助函数, 如 bpf_probe_read_*() 函数家族.
(当然, 还有一个非常重要的原因是, 为了支持 CO-RE, 内存访问相关的代码很可能由于内核版本的不同而需要重定位, 因为有些结构体成员有变动)
另外, 对于连续的指针访问, 如 d = a->b->c->d , 我们可以用如下方式:
bpf_core_read(&b, 8, &a->b)
bpf_core_read(&c, 8, &b->c)
bpf_core_read(&d, 8, &c->d)
但是, libbpf 对此封装了更好用的宏:
d = BPF_CORE_READ(a, b, c, d);
编译 eBPF 程序
接下来我们介绍如何编写 Makefile, 以及需要添加那些选项, 以便我们可以编译出适合 CO-RE/libbpf 的 ebpf 程序.
调试信息
我们需要给编译器传入 -g 标签, 以便最终生成的二进制文件中包含调试信息, (当然, 最重要的是包含了 BTF 信息). 然而, -g 选项会同时包含 DWARF 调试信息, 这部分对于 eBPF 程序来说是不需要的, 可以去除这部分信息来减小最终生成对象的大小
llvm-strip -g <object file>
优化选项
需要将编译器优化选项设置为 -O2 (或更高的优化等级), 这样最终生成的 BPF 字节码才能通过 eBPF 验证程序. 例如: 如果没有 -O2 选项的话, Clang 编译器处理辅助函数的调用代码时, 会默认生成 output callx <register>, 但是 eBPF 程序时不支持直接从寄存器调用函数地址的.
目标架构
如果要使用 libbpf 中定义的一些宏, 我们需要在编译时指定目标机器的架构. 因为一些函数或结构体是和体系架构强相关的. 例如我们程序中用到的 BPF_KPROBE_SYSCALL 中, 需要传入一个 pt_regs 类型的参数, 就需要读取包含 CPU 寄存器的内容, 必须要知道程序运行在哪个体系架构中. 部分代码截图如图所示:
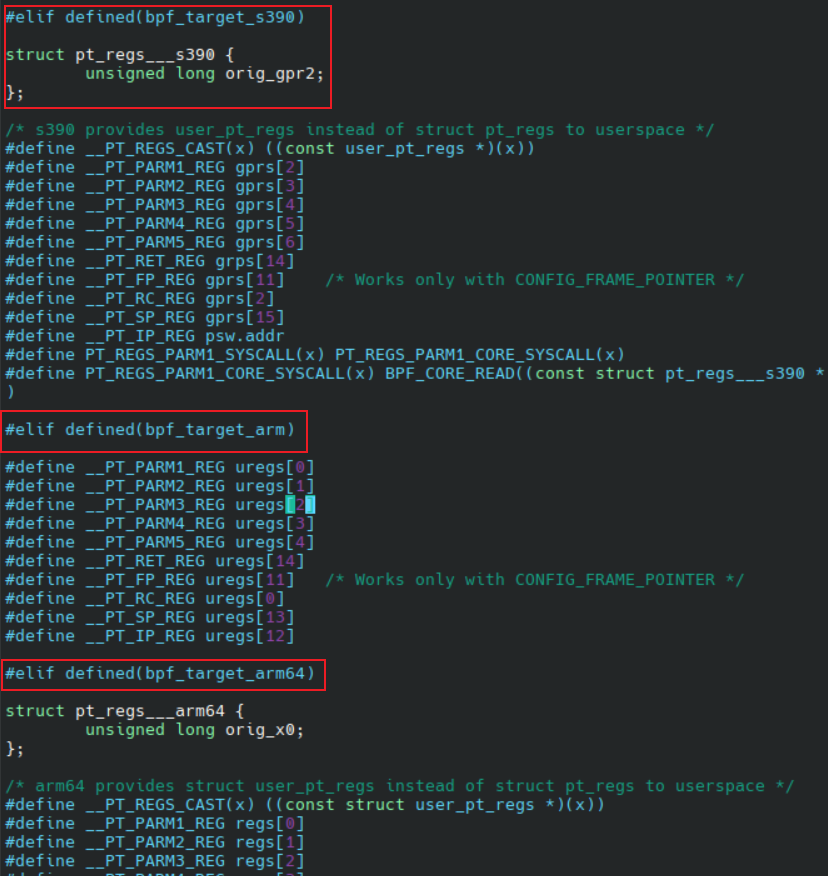
此外, 及时没有使用任何宏, 也仍然需要用架构特定代码来访问寄存器信息, 所以 CO-RE 实际上应该是 (compile once per architecture, run everywhere)
Makefile
Makefile 中编译 ebpf 内核部分的程序如下所示:
%.bpf.o: %.bpf.c vmlinux.h# 使用clang编译BPF程序clang \-target bpf \ # 指定目标为BPF-D __TARGET_ARCH_$(ARCH) \ # 定义目标架构-Wall \ # 启用所有警告-O2 -g \ # O2优化等级,添加调试信息-o $@ -c $< # 输出目标文件和编译# 去除DWARF调试信息(减小文件大小)llvm-strip -g $@
object 文件中的 BTF 信息
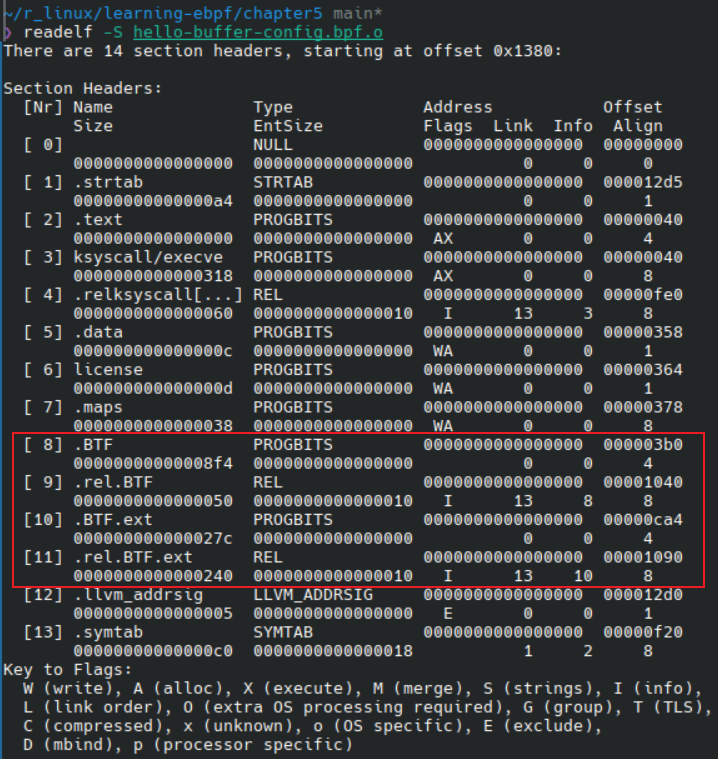
可以通过 readelf 工具来查看 object 文件中的信息.
如下图所示, readelf -S 可以查看 object 文件中的 section, 红框部分可以看到, 已经包含了我们所需要的 BTF 信息.
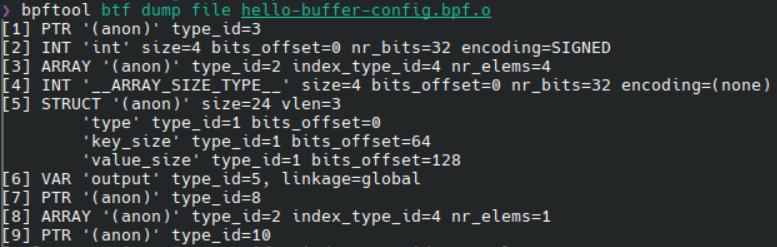
然后, 可以用 bpftool 来查看文件中包含的所有 BTF 信息, 和之前看到的一样
BPF 重定位
libbpf 需要在 eBPF 程序运行时能根据不同的内核数据结构来做适配, 因此需要在编译过程中生成 BPF CO-RE 重定位信息.
通过指令 bpftool -d prog load hello-buffer-config.bpf.o /sys/fs/bpf/hello 可以查看加载 BPF 程序时的重定位过程, 其中与重定位有关的部分如下:

可以看到, 在程序的 BTF 信息中, pt_regs BTF id 为 22, 在 vmlinux 中找到了对应的结构体, id 为7. 不过, 由于我这里编译和运行是在同一个机器上, 所以不管是数据还是指令, 其修正的 offset 都是 0 .
在上述示例中, 我们是手动将 eBPF 程序加载进内核中的, 这当然不是一个好方法, 后续我们将写用户空间的程序, 来让其完成 eBPF 程序的加载工作. 另外还有一些其他的工作要做, 例如错误处理, 控制程序生命周期等.